- 尚硅谷大数据技术-教程-学习路线-笔记汇总表【课程资料下载】
- 视频地址:尚硅谷大数据Flink1.17实战教程从入门到精通_哔哩哔哩_bilibili
- 尚硅谷大数据Flink1.17实战教程-笔记01【Flink概述、Flink快速上手】
- 尚硅谷大数据Flink1.17实战教程-笔记02【Flink部署】
- 尚硅谷大数据Flink1.17实战教程-笔记03【】
- 尚硅谷大数据Flink1.17实战教程-笔记04【】
- 尚硅谷大数据Flink1.17实战教程-笔记05【】
- 尚硅谷大数据Flink1.17实战教程-笔记06【】
- 尚硅谷大数据Flink1.17实战教程-笔记07【】
- 尚硅谷大数据Flink1.17实战教程-笔记08【】
- 尚硅谷大数据Flink1.17实战教程-笔记09【】
- 尚硅谷大数据Flink1.17实战教程-笔记10【】
- 尚硅谷大数据Flink1.17实战教程-笔记11【】
目录
基础篇
第01章-Flink概述
P001【001_课程介绍】09:18
第1章 Flink概述
P002【002_Flink概述_Flink是什么】14:13
P003【003_Flink概述_Flink发展历史&特点】08:14
P004【004_Flink概述_与SparkStreaming的区别&应用场景&分层API】12:50
第2章 Flink快速上手
P005【005_Flink快速上手_创建Maven工程&导入依赖】03:49
P006【006_Flink快速上手_批处理实现WordCount】18:00
P007【007_Flink快速上手_流处理实现WordCount_编码】13:13
P008【008_Flink快速上手_流处理实现WordCount_演示&对比】06:03
P009【009_Flink快速上手_流处理实现WordCount_无界流_编码】13:57
P010【010_Flink快速上手_流处理实现WordCount_无界流_演示&对比】05:14
本套教程基于Flink新版1.17进行讲解,共分四大篇章:基础篇、核心篇、高阶篇、SQL篇。教程通过动画讲解、实战案例演示,带你掌握Flink构建可靠、高效的数据处理应用。
基础篇
P001【001_课程介绍】09:18
谁在用Flink?答:腾讯、华为、滴滴、阿里巴巴、快手、亚马逊等大厂都在用。

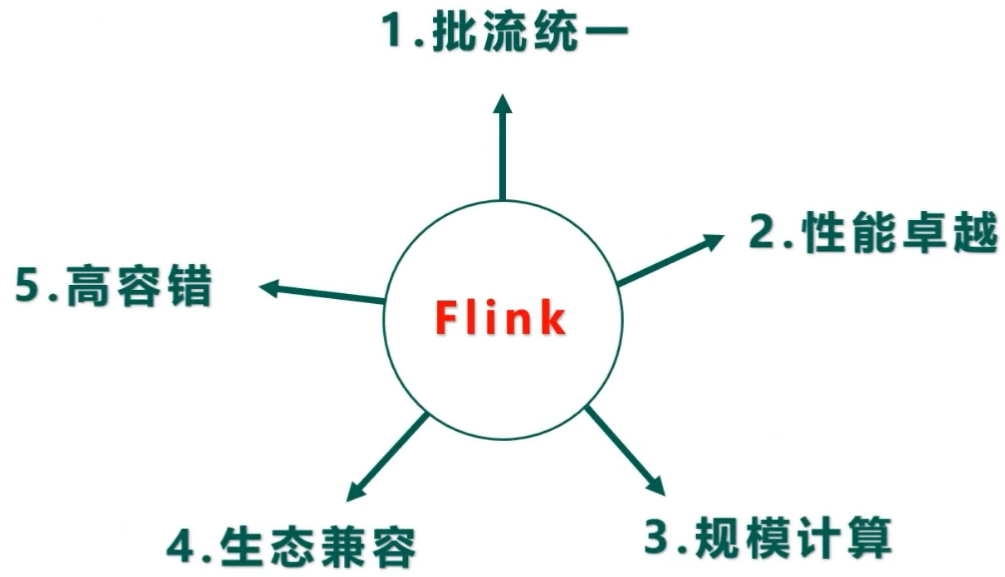
Flink特点
- 批流统一
- 同一套代码,可以跑流也可以跑批
- 同一个SQL,可以跑流也可以跑批
- 性能卓越
- 高吞吐
- 低时延
- 规模计算
- 支持水平扩展架构
- 支持超大状态与增量检查点机制
- 大公司使用情况:
- 每天处理数万亿的事件
- 应用维护几TB大小的状态
- 应用在数千个CPU核心上运行
- 生态兼容
- 支持与Yarn集成
- 支持与Kubernetes集成
- 支持单机模式运行
- 高容错
- 故障自动重试
- 一致性检查点
- 保证故障场景下精确一次的状态一致性
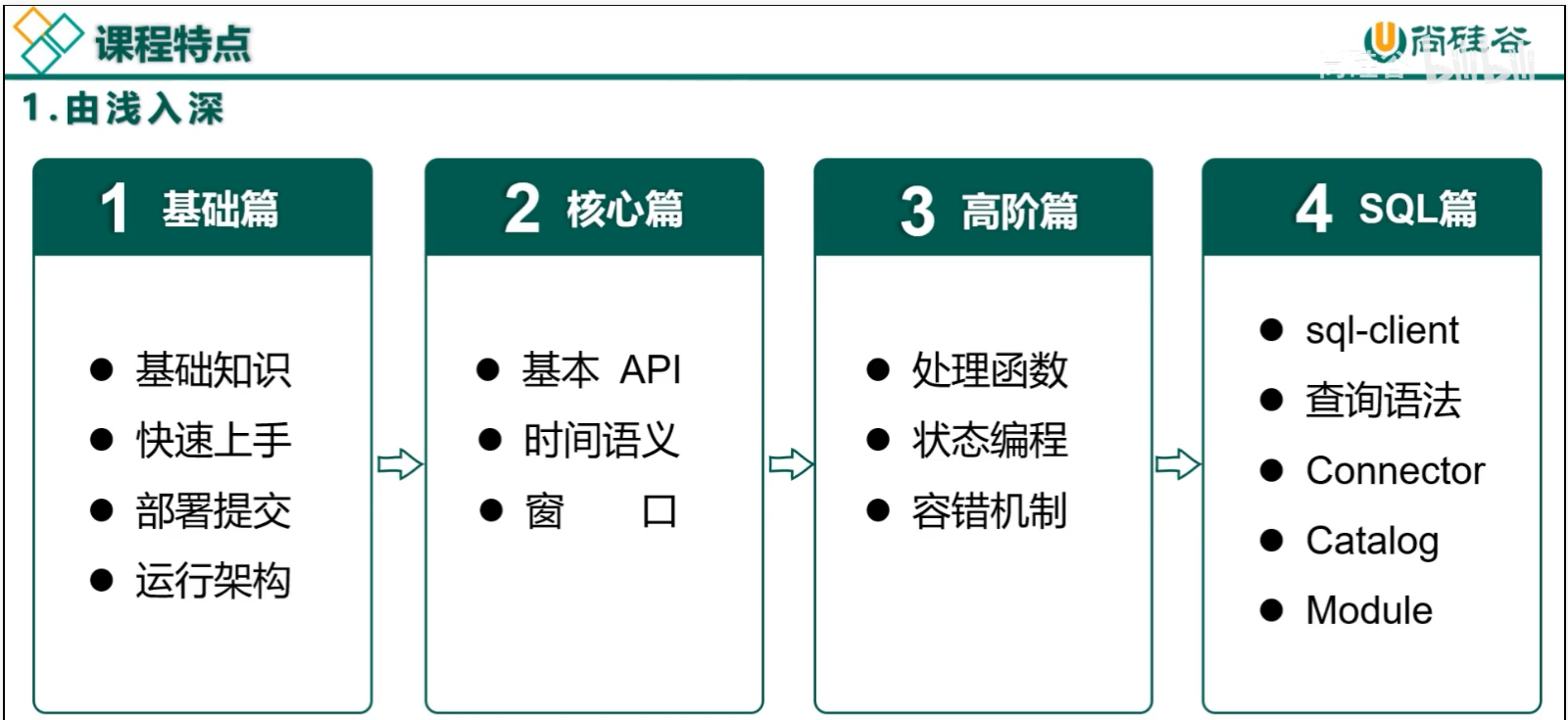
课程特点
- 由浅入深
- 动图讲解重难点
- 全新版本
- 内容详实




第01章-Flink概述
P002【002_Flink概述_Flink是什么】14:13
Flink的官网主页地址:https://flink.apache.org/
Flink核心目标,是“数据流上的有状态计算”(Stateful Computations over Data Streams)。
具体说明:Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
P003【003_Flink概述_Flink发展历史&特点】08:14
我们处理数据的目标是:低延迟、高吞吐、结果的准确性和良好的容错性。
Flink主要特点如下:
- 高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
- 结果的准确性。Flink提供了事件时间(event-time)和处理时间(processing-time)语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
- 精确一次(exactly-once)的状态一致性保证。
- 可以连接到最常用的外部系统,如Kafka、Hive、JDBC、HDFS、Redis等。
- 高可用。本身高可用的设置,加上与K8s,YARN和Mesos的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink能做到以极少的停机时间7×24全天候运行。
P004【004_Flink概述_与SparkStreaming的区别&应用场景&分层API】12:50
表 Flink 和 Streaming 对比 Flink
Streaming
计算模型
流计算
微批处理
时间语义
事件时间、处理时间
处理时间
窗口
多、灵活
少、不灵活(窗口必须是批次的整数倍)
状态
有
没有
流式SQL
有
没有
第02章-Flink快速上手
P005【005_Flink快速上手_创建Maven工程&导入依赖】03:49
<properties>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>P006【006_Flink快速上手_批处理实现WordCount】18:00
ctrl + p:查看传参方式。

hello flink
hello world
hello java
package com.atguigu.wc;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* TODO DataSet API 实现 wordCount
*/
public class WordCountBatchDemo {
public static void main(String[] args) throws Exception {
// TODO 1.创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// TODO 2.读取文件:从文件中读取
DataSource<String> lineDS = env.readTextFile("input/word.txt");
// TODO 3.切分、转换(word, 1)
FlatMapOperator<String, Tuple2<String, Integer>> wordAndOne = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// TODO 3.1 按照空格切分单词
String[] words = value.split(" ");
// TODO 3.2 将单词转换为(word, 1)格式
for (String word : words) {
Tuple2<String, Integer> wordTuple2 = Tuple2.of(word, 1);
// TODO 3.3 使用Collector向下游发送数据
out.collect(wordTuple2);
}
}
});
// TODO 4.按照word分组
UnsortedGrouping<Tuple2<String, Integer>> wordAndOneGroupBy = wordAndOne.groupBy(0);
// TODO 5.各分组内聚合
AggregateOperator<Tuple2<String, Integer>> sum = wordAndOneGroupBy.sum(1); //1是位置,表示第二个元素
// TODO 6.输出
sum.print();
}
}P007【007_Flink快速上手_流处理实现WordCount_编码】13:13
2.2.2 流处理

package com.atguigu.wc;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* TODO DataStream实现Wordcount:读文件(有界流)
*
*/
public class WordCountStreamDemo {
public static void main(String[] args) throws Exception {
// TODO 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO 2.读取数据:从文件读
DataStreamSource<String> lineDS = env.readTextFile("input/word.txt");
// TODO 3.处理数据: 切分、转换、分组、聚合
// TODO 3.1 切分、转换
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOneDS = lineDS //<输入类型, 输出类型>
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// 按照 空格 切分
String[] words = value.split(" ");
for (String word : words) {
// 转换成 二元组 (word,1)
Tuple2<String, Integer> wordsAndOne = Tuple2.of(word, 1);
// 通过 采集器 向下游发送数据
out.collect(wordsAndOne);
}
}
});
// TODO 3.2 分组
KeyedStream<Tuple2<String, Integer>, String> wordAndOneKS = wordAndOneDS.keyBy(
new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
}
);
// TODO 3.3 聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> sumDS = wordAndOneKS.sum(1);
// TODO 4.输出数据
sumDS.print();
// TODO 5.执行:类似 sparkstreaming最后 ssc.start()
env.execute();
}
}
/**
* 接口 A,里面有一个方法a()
* 1、正常实现接口步骤:
* <p>
* 1.1 定义一个class B 实现 接口A、方法a()
* 1.2 创建B的对象: B b = new B()
* <p>
* <p>
* 2、接口的匿名实现类:
* new A(){
* a(){
* <p>
* }
* }
*/P008【008_Flink快速上手_流处理实现WordCount_演示&对比】06:03
主要观察与批处理程序 BatchWordCount 的不同:
- 创建执行环境的不同,流处理程序使用的是 StreamExecutionEnvironment。
- 转换处理之后,得到的数据对象类型不同。
- 分组操作调用的是 keyBy 方法,可以传入一个匿名函数作为键选择器(KeySelector), 指定当前分组的 key 是什么。
- 代码末尾需要调用 env 的 execute 方法,开始执行任务。

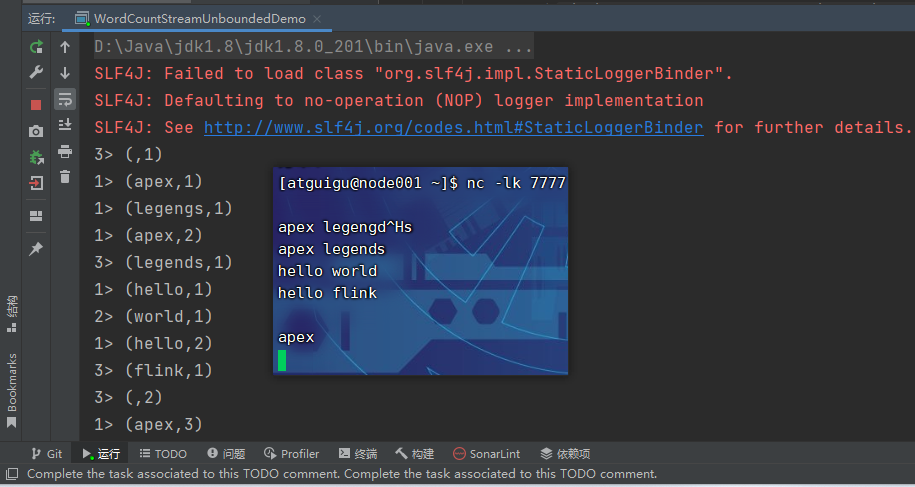
P009【009_Flink快速上手_流处理实现WordCount_无界流_编码】13:57
2)读取 socket 文本流
在实际的生产环境中,真正的数据流其实是无界的,有开始却没有结束,这就要求我们需要持续地处理捕获的数据。为了模拟这种场景,可以监听 socket 端口,然后向该端口不断地发送数据。
[atguigu@node001 ~]$ sudo yum install -y netcat
[atguigu@node001 ~]$ nc -lk 7777

package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* TODO DataStream实现Wordcount:读socket(无界流)
*
*/
public class WordCountStreamUnboundedDemo {
public static void main(String[] args) throws Exception {
// TODO 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// IDEA运行时,也可以看到webui,一般用于本地测试
// 需要引入一个依赖 flink-runtime-web
// 在idea运行,不指定并行度,默认就是 电脑的 线程数
// StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(3);
// TODO 2. 读取数据: socket
DataStreamSource<String> socketDS = env.socketTextStream("node001", 7777);
// TODO 3. 处理数据: 切换、转换、分组、聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDS
.flatMap(
(String value, Collector<Tuple2<String, Integer>> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
)
.setParallelism(2)
.returns(Types.TUPLE(Types.STRING, Types.INT))
// .returns(new TypeHint<Tuple2<String, Integer>>() {})
.keyBy(value -> value.f0)
.sum(1);
// TODO 4. 输出
sum.print();
// TODO 5. 执行
env.execute();
}
}
/**
* 并行度的优先级:
* 代码:算子 > 代码:env > 提交时指定 > 配置文件
*/