来源:投稿 作者:橡皮
编辑:学姐

论文链接:https://arxiv.org/abs/2303.13843
0.背景:
最近,文本到图像生成通过将视觉-语言预训练模型与扩散模型相结合,取得了巨大的成功。这些突破也使得强大的视觉-语言预训练模型在文本生成三维内容中产生了深远的影响。最近,几种文本生成3D的方法已经表明,将来自差分3D模型的渲染视图与来自预先训练的扩散模型的学习到的文本到图像分布相匹配,可以获得显著的结果。
然而,文本描述通常是用于期望的目标3D模型或2D图像的抽象规范。尽管拥有强大的扩散模型,例如stable diffusion,它已经在数十亿的文本图像对上进行了训练,但从文本中生成不同视点的几何相干图像仍然是一个挑战。
在给定包含多个对象的文本的情况下,扩散模型可能会产生不准确的结果,导致对象丢失或语义混乱,有时即使使用简单的多对象文本,稳定扩散也无法保持对象身份和几何一致性。这显然与NeRF中体积渲染的本质相矛盾,导致了障碍引导崩溃,尤其是在从多对象文本中渲染复杂场景时。
因此,这自然提出了一个问题:是否可以从3D场景生成的扩散模型的不可知分布中准确地学习和组合多对象文本中的所有概念。

1.主要贡献:
通过将可编辑的3D布局与多个局部NeRF集成,以精确关联特定结构的文本引导,来解决多物体3D场景生成中的引导崩溃问题
通过引入全局MLP来校准全局场景颜色和不同级别的文本引导,以在学习单个实体的全局一致性的同时保持对象的身份,从而解决全局一致性和遮挡问题。
全面评估了我们提出的方法在各种多对象场景中的有效性,展示了其以合成方式生成3D场景并提供灵活编辑功能的能力。
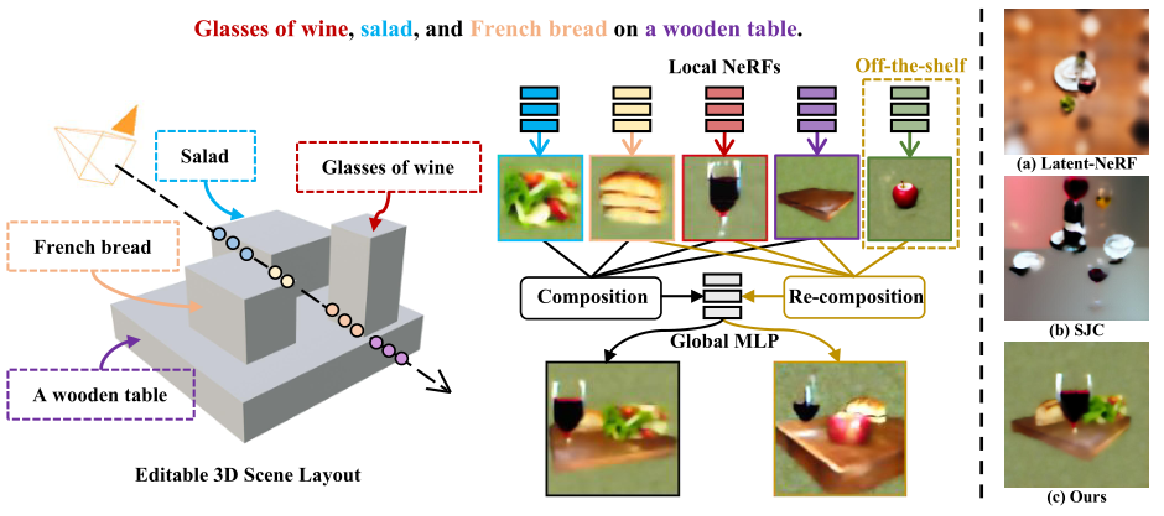
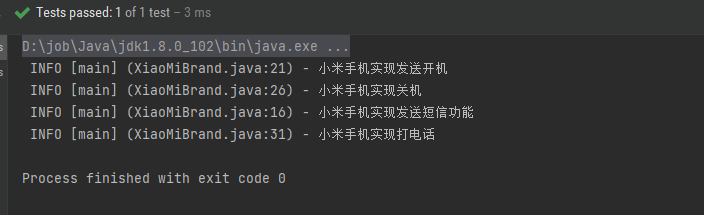
2.网络介绍: CompoNeRF
由三部分组成:
-
可编辑的3D场景布局通过3D框和文本提示配置场景表示;
-
场景渲染包括全局校准和合成过程;
-
联合优化将全局和局部文本指导应用于全局和局部渲染视图。
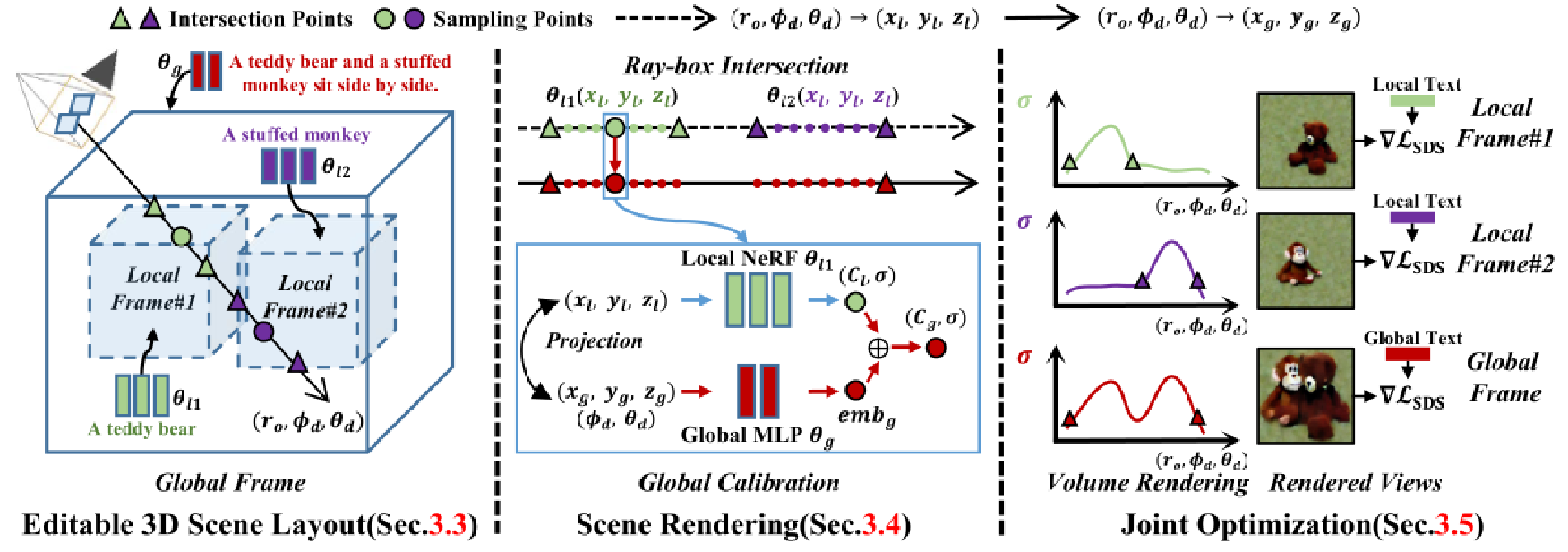
3.1方法细节:概述
上图展示了pipeline,由三个主要组件组成:包括基于多对象文本的可编辑3D场景布局(第3.3节),合成所有局部NeRF预测的场景渲染pipeline(第3.4节),以及局部和全局表示模型的联合优化(第3.5节),提出的可编辑3D场景布局通过将其分解为一组局部帧来表示场景的全局帧,其中每个局部帧由局部NeRF、3D边界框和相应的局部文本提示参数化。
例如,文本提示“一只泰迪熊和一只毛绒猴子并排坐着”被解释为是一个3D场景布局。整个3D布局,即场景帧,由两个3D边界框组成,即局部帧#1和#2,并带有特定的局部文本提示,即“泰迪熊”和“毛绒猴子”。

3.2方法细节:先验知识

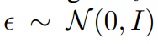
生成噪声图像。然后,扩散模型φ预测采样噪声
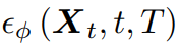
给定噪声图像 、噪声水平t和可选文本提示T。
特别是SDS根据预测噪声和添加噪声之间的差来计算梯度,
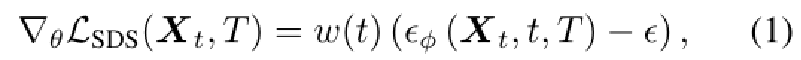
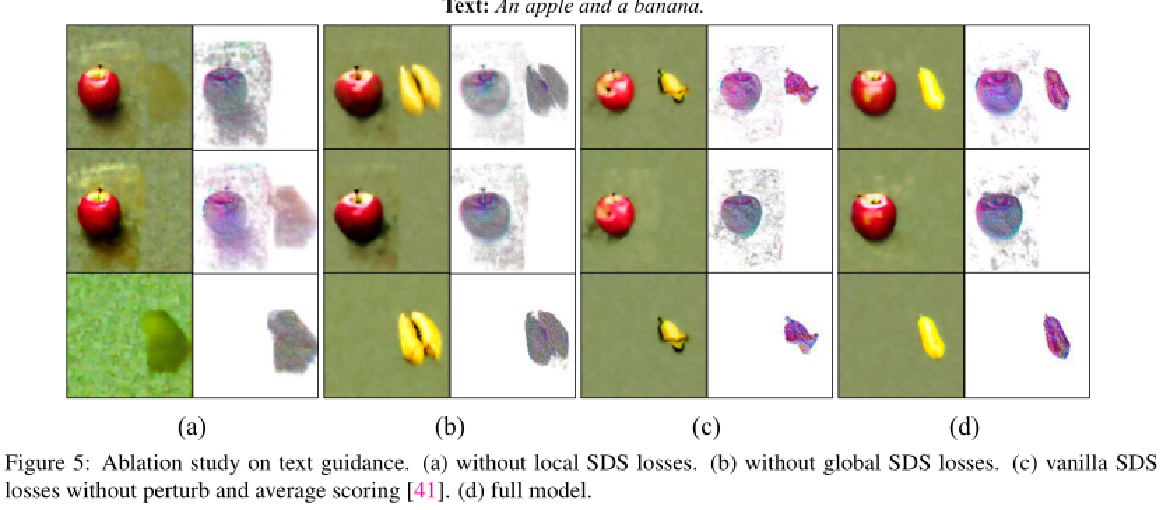
其中w(t)是加权函数。在所有渲染视图上生成的梯度方向用于更新θ,以生成与扩散先验下的条件文本提示相匹配的图像。我们还遵循SJC将扰动和平均评分应用于SDS过程。
3.3方法细节:可编辑3D场景布局

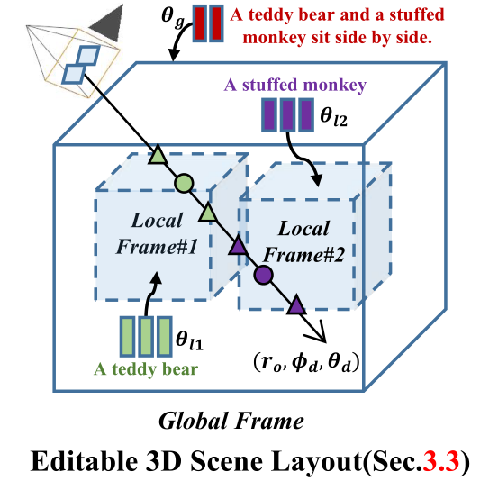
此外,如下图所示,3D场景布局中的每个组件都可以用其他经过训练的本地NeRF替换或重新合成,与仅使用文本提示相比,这对于灵活的用户版本更友好。

3.4方法细节:场景渲染pipeline

注意,首先使用局部帧的盒尺度将采样点的坐标投影到归一化坐标中,以使每个局部NeRF能够学习尺度无关的表示。全局坐标中局部框架的边界框b可以通过(b−p)/s转换为规范边界框。考虑到渲染效率,我们只计算有效点,与框进行交互,并将所有空点设置为恒定的背景色。


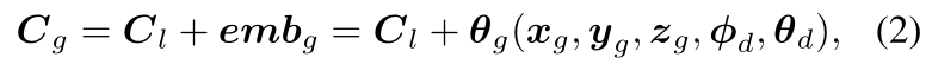

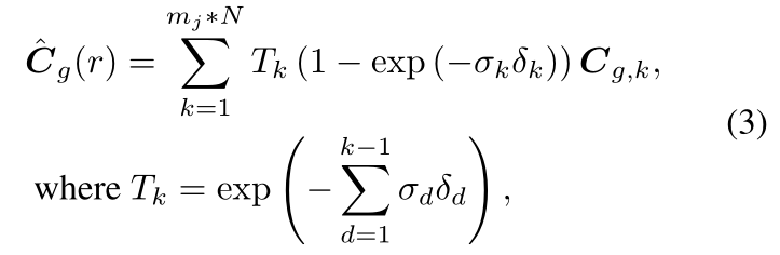
其中,δ是相邻采样点之间的距离。 对于每个局部NeRF ,我们还通过,

事实上,与场景相比,每个局部帧只有少量的命中光线。尽管部分光线被跳过,但我们观察到,在保持较短渲染时间的同时,准确地表示每个对象就足够了。
3.5方法细节:联合优化

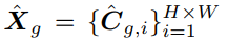

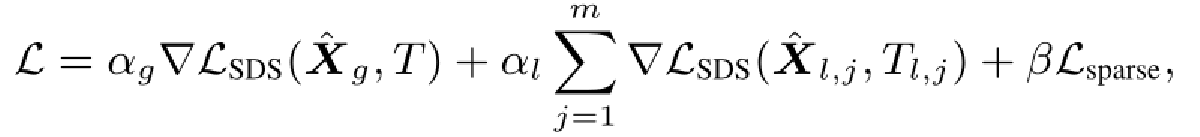

4.实验结果:






关注下方《学姐带你玩AI》🚀🚀🚀
回复“CVPR”获取顶会必读论文合集
码字不易,欢迎大家点赞评论收藏!