String, StringBuffer, StringBuilder区别
第一点是可变性。String不可变,String Buffer和StringBuider可变。这是因为String被final修饰,每次操作都生成新的对象。StringBuffer和StringBuilder的父类AbstractStringBuilder没有被final修饰。
第二点是线程安全。String和StringBuffer是线程安全的,因为String被final修饰,StringBuffer所有的方法都用了synchronized。StringBuilder是线程不安全的。因此单线程时使用StringBuilder,性能较好,多线程时使用StringBuffer,线程安全。
为什么静态方法不能调用非静态方法和变量?
静态方法是属于类,在类加载时就会分配内存,可以通过类名去直接访问。
非静态成员属于类的对象,只有该对象实例化之后才存在,通过类的对象去访问。
异常类型

Throwable下面有两个直接子类,Error和Exception。
Error是严重的系统错误,无法被应用程序捕获和处理,例如内存溢出或者堆栈溢出。
Exception的子类有RuntimeException和其他Exception。
RuntimeException通常不需要在方法的声明中显式地捕获或声明抛出,例如空指针异常,算数异常等等。
其他Exception也称Checked Exception,这些异常通常需要在方法的声明中显式地捕获或声明抛出,例如IOException,SQLException等等。
捕获: try...catch,一般用在调用处,能让代码继续往下运行。
抛出: throw throws,在方法中,出现异常了,方法就没有继续运行下去的意义了,采取抛出处理让该方法结束运行并告诉调用者出现了问题。
字节流与字符流区别?
适用场景:字符流适合文本文件,字节流适合图片视频音频。因为字符流能自动处理文件编码,确保正确解析文件中的字符,并且字符流读取非文本文件时,可能会将某些特定的字节序列视为文件的结尾,导致数据丢失。
缓冲:字节流不使用缓冲,字符流将频繁访问的资源放入内存。
字节流是InputStream、OutputStream。字符流是Reader、Writer。
ArrayList扩容机制
ArrayList每次扩容是原来的1.5倍。因为扩容时,会将老数组中的元素重新拷贝一份到新的数组中,因此扩容代价比较高,我们要尽量避免数组扩容,尽可能地在创建ArrayList对象时指定其容量。
是否线程安全?如何线程安全地操作ArrayList?
ArrayList线程安全的操作方法
-
Vector。List list = new ArrayList(),替换为List arrayList = new Vector<>()。使用了synchronized关键字,效率较低。
-
JUC中的CopyOnWriteArrayList。CopyOnWriteArrayList<String> list =new CopyOnWriteArrayList<String>() 。写数据时将原来array复制到新的array,修改后,将引用指向新数组,任何可变的操作(add、set、remove等)都通过ReentrantLock 控制并发,读数据时不用加锁,适用于读多写少的并发场景。
- Collections.synchronizedList(list)。方法都加了synchronized修饰。加锁的对象是当前SynchronizedCollection实例,适用于将现有的非线程安全的 List 转换为线程安全的情况。
LinkedList线程安全的操作方法
JUC中的ConcurrentLinkedQueue和Collections.synchronizedList(List)。
HashMap、TreeMap、LinkedHashMap的区别?
相同点
- 都属于Map;
- Map 主要用于存储键(key)值(value)对,根据键得到值,因此键不允许键重复,但允许值重复。
- 都是线程不安全的
不同点
JDK7与JDK8的HashMap区别

HashMap为什么线程不安全?
为什么HashMap会出现死循环
- HashMap死循环只发生在JDK1.7版本中主要原因:头插法 +链表 +多线程并发 +扩容累加到一起就会形成死循环。
- 多线程下:建议采用ConcurrentHashMap替代。
- JDK1.8中,HashMap改成尾插法,解决了链表死循环的问题。
HashMap系列--保证线程安全的方法
线程安全Map的三种方法
HashTable,Map<String, Object> map = new Hashtable<>(),synchronized修饰get/put方法,性能差。
Collections.synchronizedMap,Map<String,Object> map =Collections.synchronizedMap(new HashMap<String, Object>()),所有方法都使用synchronized修饰,性能差。
JUC中的ConcurrentHashMap,Map<String, Object> map = new ConcurrentHashMap<>(),每次只给一个桶(数组项)加锁,性能好。
ConcurrentHashMap的原理
JDK8原理概述
JDK8中ConcurrentHashMap结构基本上和HashMap一样,采用了HashMap(数组 + 链表 + 红黑树) + synchronized + CAS + node 的实现方式来设计。读操作使用volatile,写操作使用synchronized 和CAS。
CAS:在判断数组中当前位置为null的时候,使用CAS把这个新的Node写入数组中对应的位置。
synchronized :当数组中的指定位置不为空时,通过加锁来添加这个节点进入数组或者红黑树。
JDK8中采用的是Node(放弃了Segment,一个Node对应一个桶)。Node:保存key,value及key的hash值的数据结构。其中value和next都用volatile修饰,保证并发的可见性。
class Node<K,V>implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
//... 省略部分代码
}JDK7原理概述
在JDK1.7中ConcurrentHashMap采用了HashMap + ReentrantLock + Segment的方式实现。
ConcurrentHashMap中的分段锁称为Segment,它类似于HashMap的结构,即:内部拥有一个Entry数组,数组中的每个元素又是一个链表,同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。
ConcurrentHashMap的内部结构图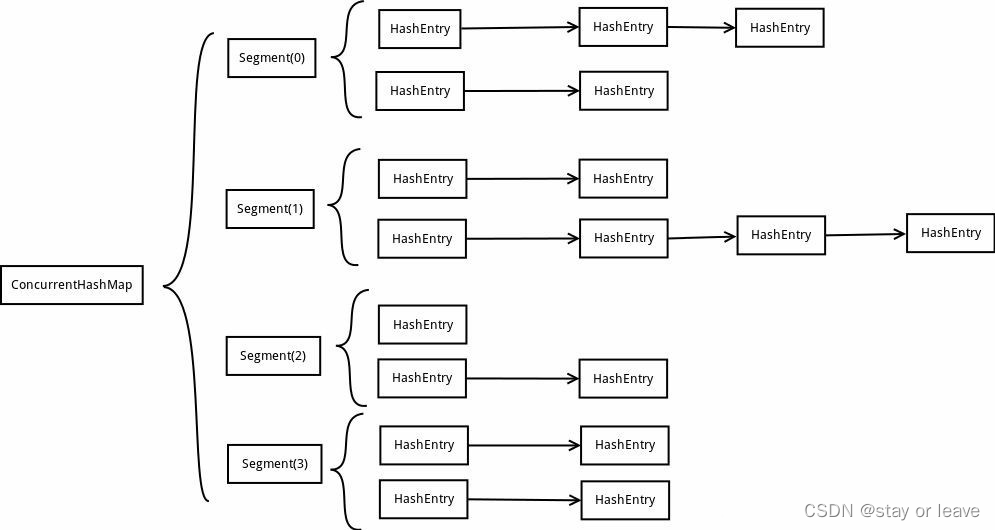
JDK 7中的ConcurrentHashMap使用分段锁实现并发控制,每个段内部有独立的锁和哈希表。JDK 8中的ConcurrentHashMap摒弃了Segment概念,引入了分段锁和锁分段技术,将哈希表分成多个区块,每个区块可以独立访问。JDK 8还引入了CAS操作和volatile关键字来实现更高效的并发控制。
HashMap的底层原理
HashMap 是 Java 中常用的数据结构,用于存储键值对。它的底层原理是基于哈希表(Hash Table)。
在 HashMap 内部,它使用一个数组(Array)来存储数据。当我们将键值对存储到 HashMap 中时,HashMap 首先会根据键的哈希码(hash code)计算出在数组中的索引位置。哈希码是根据键的对象生成的一个整数值,用于快速定位该键值对在数组中的位置。
当多个键通过哈希函数计算得到相同的索引位置时,就发生了哈希碰撞(hash collision)。为了解决碰撞问题,HashMap 使用链表(Linked List)或红黑树(Red-Black Tree)来存储具有相同索引位置的键值对。链表适用于碰撞较少的情况,而红黑树则用于处理碰撞较多的情况,以提高查询效率。
当我们需要从 HashMap 中获取值时,HashMap 会根据键的哈希码找到对应的索引位置,并在链表或红黑树中进行查找。这样,HashMap 可以在平均情况下以接近 O(1) 的时间复杂度实现键值对的存取操作。
需要注意的是,HashMap 的性能取决于哈希函数的质量以及负载因子(load factor)。负载因子是一个衡量哈希表空间利用率的参数,当哈希表中的元素个数达到负载因子与数组长度的乘积时,会触发扩容操作,以保持较低的碰撞概率和较高的性能。
总结来说,HashMap 的底层原理是基于哈希表,利用哈希码和数组索引来存储和获取键值对,并使用链表或红黑树来解决哈希碰撞问题。
hash冲突的4种解决方案?
链地址法
对于相同的哈希值,使用链表进行连接。(HashMap使用此法)
优点
处理冲突简单,无堆积现象。即非同义词决不会发生冲突,因此平均查找长度较短;
适合总数经常变化的情况。(因为拉链法中各链表上的结点空间是动态申请的)
占空间小。装填因子可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计
删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。
缺点
查询时效率较低。(存储是动态的,查询时跳转需要更多的时间)
在key-value可以预知,以及没有后续增改操作时候,开放定址法性能优于链地址法。
不容易序列化
再哈希法
提供多个哈希函数,如果第一个哈希函数计算出来的key的哈希值冲突了,则使用第二个哈希函数计算key的哈希值。
优点 不易产生聚集
缺点 增加了计算时间
建立公共溢出区
将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
开放定址法
当关键字key的哈希地址p =H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,若p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。
开放定址法有三种方式:线性探测再散列,线性探测再散列,伪随机探测再散列。
优点:
容易序列化
若可预知数据总数,可以创建完美哈希数列
缺点:
占空间很大。(开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间)
删除节点很麻烦。不能简单地将被删结点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
HashMap扩容的原理
扩容时机
- 首次调用put方法时,HashMap会发现table为空然后调用resize方法进行初始化。
- 非首次调用put方法时,若HashMap发现size大于threshold(阈值)(当前数组的大小乘以加载因子的值),则会调用resize方法进行扩容。
- 链表长度大于8 且数组长度小于64 会进行扩容。(链表长度大于8 且数组长度大于等于64,会转化为红黑树)。
resize()扩容过程
- 判断旧数组容量是否已经达到最大(2^30)了,若达到则修改阈值为Integer的最大值(2^31 - 1),以后就不会扩容了。若没达到,则修改数组大小为原来的2倍。
- 以新数组大小创建新的数组,将数据转移到新的数组里。
- 不一定所有的节点都要换位置。比如:原数组大小为16,扩容后为32。若原来有hash值为1和17两个数据,他们对16取余都是1,在同一个桶里;扩容后,1对32取余仍然是1,而17对32取余却成了17,需要换个位置。
SingleDateFormat--线程安全的操作方法(有实例)
SingleDateFormat线程不安全的原因
SingleDateFormat类内部有个Calendar对象引用,Calendar用于存储日期信息,如果SimpleDateFormat是多个线程之间共享的, 那么多个线程可以同时访问和修改Calendar对象的状态。就会出现线程安全问题。
解决方案
1、每调用一次方法就会创建一个SimpleDateFormat对象,但每调用一次方法就会创建一个SimpleDateFormat对象。
2、方法加synchronized,不过性能差。
3、使用ThreadLocal,这种方式推荐。
4、如果是JDK8的应用,可以使用Instant代替Date,LocalDateTime代替Calendar,DateTimeFormatter(所有字段都是final类型)代替Simpledateformatter。
线程池有哪些参数?
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)1、corePoolSize
线程池的核心线程数
即便是线程池里没有任何任务,也会有corePoolSize个线程在候着等任务。
2、maximumPoolSize
最大线程数。
超过此数量,会触发拒绝策略。
3、keepAliveTime
线程的存活时间。
当线程池里的线程数大于corePoolSize时,如果等了keepAliveTime时长还没有任务可执行,则线程退出。
4、unit
指定keepAliveTime的单位
比如:秒:TimeUnit.SECONDS。
5、workQueue
一个阻塞队列,提交的任务将会被放到这个队列里。
6、threadFactory
线程工厂,用来创建线程
主要是为了给线程起名字,默认工厂的线程名字:pool-1-thread-3。
7、handler
拒绝策略
当线程池里线程被耗尽,且队列也满了的时候会调用。
默认拒绝策略为AbortPolicy。即:不执行此任务,而且抛出一个运行时异常
线程池使用步骤?
1:创建一个线程池对象,控制要创建几个线程对象。
2:实现线程,新建一个类实现Runnable或者Callable接口。
3:使用submit或者execute提交线程调用。submit有返回值,返回值是future对象,可以获取执行结果。execute无返回值。
4:使用shutdown方法关闭线程池。
线程池的工作流程

CPU密集与IO密集的场景如何设置线程池参数?
如果任务被阻塞的时间少于执行时间,即这些任务是计算密集型的,则程序所需线程数将随之减少,但最少也不应低于处理器的核心数。核心线程数 = CPU核数 + 1
如果任务被阻塞的时间大于执行时间,即该任务是IO密集型的,我们就需要创建比处理器核心数大几倍数量的线程。例如,如果任务有50%的时间处于阻塞状态,则程序所需线程数为处理器可用核心数的两倍。核心线程数 = CPU核数 * 2 + 1
线程池的阻塞队列(BlockingQueue)
ArrayBlockingQueue
基于数组的FIFO队列;有界;创建时必须指定大小;入队和出队共用一个可重入锁。默认使用非公平锁。
LinkedBlockingQueue
默认大小的LinkedBlockingQueue将导致所有 corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程不会超过 corePoolSize。(因此,maximumPoolSize 的值也就无效了)。使用无界队列的好处是可以避免任务因为队列满而被拒绝或阻塞,因此当每个任务相互独立且任务数量较大时,适合使用无界队列。
常见线程池种类
FixedThreadPool(固定线程池)
固定线程池是一种固定大小的线程池,其中线程数量是预先指定的。当有新任务提交时,如果线程池中有空闲线程,则立即执行;如果线程池中没有空闲线程,则任务进入等待队列,直到有线程可用。固定线程池适用于需要限制并发线程数量的场景,如服务器请求处理、并发任务数量可预知的情况。
SingleThreadExecutor(单线程池)
单线程池是只有一个工作线程的线程池,所有任务按照顺序执行,每个任务都在前一个任务执行完成后开始执行。适用于需要按照顺序串行执行任务的场景,如消息队列的消费者、数据库事务处理等。
ScheduledThreadPool(定时线程池)
定时线程池用于执行延迟任务或定时任务,可以指定任务的延迟时间或固定的执行间隔。定时线程池会根据任务的执行时间自动调度线程,保证任务按照预定的时间顺序执行。适用于需要定时执行任务的场景,如定时任务调度、定时数据备份等。
CachedThreadPool(缓存线程池)
缓存线程池根据需要创建线程,如果有空闲线程,则复用空闲线程执行任务;如果没有空闲线程,则创建新线程。当线程空闲时间超过指定的时间(例如60秒),则被终止并从线程池中移除。缓存线程池适用于任务数量不确定、任务执行时间短暂、需要快速响应的场景。
进程的三种创建方式
1、继承Thread类的方式进行实现:
定义一个MyThread继承Thread类
在MyThread类中重写run()方法
创建MyThread类对象
启动线程
public class MyThread extends Thread {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println("MyThread线程方法执行" + i);
}
}
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.start();
}
}问题.run()方法和start()的区别
run():封装线程执行的代码,直接调用,相当于普通方法的调用,并没有开启线程
start():启动线程;然后由JVM调用此线程的run()方法
2、方式2:实现Runnable接口
定义一个类MyRunnable实现Runnable接口
在MyRunnable类中重写run()方法
创建MyRunnable类的对象
创建Thread类的对象,把MyRunnable对象作为构造方法的参数
启动线程
public class MyRunnable implements Runnable{
@Override
public void run() {
for (int i=0;i<10;i++){
System.out.println("线程方法执行"+i);
}
}
public static void main(String[] args) {
//创建了一个参数对象
MyRunnable myRunnable = new MyRunnable();
//创建了一个线程对象,并把参数传递给这个线程
//在线程启动后,执行的就是参数里面的run方法
Thread thread = new Thread(myRunnable);
//run方法
thread.start();
}
}3、方式3:Callble和Future(可以获取返回结果)
定义一个类MyCallable实现Callable接口
在MyCallable类中重写call()方法
创建MyCallable类的对象
创建Future的实现类FutureTask对象,把MyCallable对象作为构造方法的参数
创建Thread类的对象,把FutureTask对象作为构造方法的参数
启动线程
public class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
for (int i=0;i<100;i++){
System.out.println("MyCallable运行次数"+i);
}
//返回值就是表示线程运行之后的结果
return "你好";
}
public static void main(String[] args) {
//线程开启之后需要执行里面的call方法
MyCallable myCallable = new MyCallable();
//可以获取线程执行完毕之后的结果,也可以作为参数传递给Thread对象
FutureTask<String> futureTask = new FutureTask<String>(myCallable);
//创建线程对象
Thread thread = new Thread(futureTask);
//开启线程
thread.start();
try {
//获取返回结果
String s = futureTask.get();
System.out.println(s);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}调用get方法,就可以获取线程结束之后的结果,必须在线程结束之后才能获取否则只能死等线程
ReentrantLock和synchronized锁
ReentrantLock

对象实例、类信息、常量、静态变量分别在运行时数据区的哪个位置?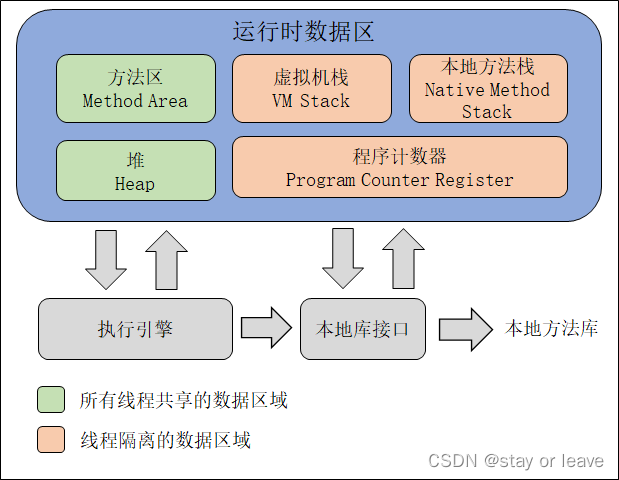
各区域的数据
以JDK8为例:
- 堆:对象实例、String常量池、基本类型常量池
- 方法区:类信息、静态变量
- 虚拟机栈:临时变量(方法内的变量)
- 元空间:类常量池、运行时常量池