Redis支持多种数据结构,每种数据结构都有其特定的用途。下面对Redis支持的主要数据结构进行详细阐述:

一、字符串(String)
字符串是Redis最基本的数据结构,可以存储一个字符串或者二进制数据,例如图片、序
列化对象等。Redis中的字符串是动态字符串,内部结构实现类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。字符串的最大长度是512M。
字符串是Redis中最基本的数据结构之一,它的底层数据结构被称为简单动态字符串(Simple Dynamic String,SDS)。SDS使用了预分配空间和惰性空间释放等技术,可以在实现高效字符串操作的同时,减少内存的碎片化。
SDS的结构如下所示:
struct sdshdr {
int len; // 已使用空间的长度
int free; // 可用空间的长度
char buf[]; // 字节数组
};+---------+------+------+------+------+------+------+------+------+------+
| Header | 'R' | 'e' | 'd' | 'i' | 's' | '\0' | '3' | '.' | '0' |
+---------+------+------+------+------+------+------+------+------+------+
| len=6 | 'r' | 'd' | 'b' | ':' | '0' | '\0' | '\0' |
+---------+------+------+------+------+------+------+------+------+------+
| free=0 | R | e | d | i | s | - | 1 | -
+---------+------+------+------+------+------+------+------+------+------+其中,len表示字符串已经使用的长度,free表示还有多少空间可以用来添加新的字符。buf则是存储字符串的字节数组。
SDS使用了一些技巧来提高性能。例如,在进行字符串扩容时,它会尝试预分配比实际需要更多的空间,以减少内存重分配的次数。此外,SDS还会尽可能地复用已分配的空间,以减少内存碎片。
应用场景:
Redis中的字符串是最基本的数据类型,可以存储任何形式的文本数据,如JSON、HTML、XML、二进制图片等等。字符串在Redis中也是最常用的数据类型之一,常用于缓存数据、计数器、排行榜、存储用户信息等场景。
基本操作:
1、设置字符串:使用SET命令可以将一个字符串设置到Redis中。
SET key value其中,key表示字符串的键名,value表示字符串的值。
2、获取字符串:使用GET命令可以从Redis中获取一个字符串。
GET key其中,key表示字符串的键名,返回值为对应的字符串。
3、修改字符串:使用SET命令可以修改Redis中已有的字符串。
SET key value其中,key表示字符串的键名,value表示新的字符串值。
4、删除字符串:使用DEL命令可以从Redis中删除一个字符串。
DEL key其中,key表示字符串的键名。
5、获取字符串长度:使用STRLEN命令可以获取一个字符串的长度。
STRLEN key其中,key表示字符串的键名,返回值为对应字符串的长度。
6、自增或自减操作:使用INCR或DECR命令可以对一个存储整数的字符串进行自增或自减操作。
INCR key
DECR key其中,key表示字符串的键名,返回值为自增或自减后的值。
7、批量设置字符串:使用MSET命令可以同时设置多个字符串。
MSET key1 value1 key2 value2 ...其中,key表示字符串的键名,value表示字符串的值,可以设置多个键值对。
8、批量获取字符串:使用MGET命令可以同时获取多个字符串。
MGET key1 key2 ...其中,key表示字符串的键名,可以获取多个键对应的值。
字符串是Redis中最基本的数据类型,除了上述基本操作,还可以使用各种其他命令对字符串进行操作,例如追加字符串、设置过期时间等。可以根据具体的使用场景和需求,结合Redis提供的命令进行灵活使用。
二、列表(List)
列表是一个双向链表,可以支持在头部和尾部进行插入和删除操作。列表可以用来实现栈和队
列等数据结构。Redis的列表数据结构采用了双向链表实现,每个节点包含一个指向前驱节点和后继节点的指针,以及一个字符串类型的值。同时,列表还包含了一个指向头节点和尾节点的指针,以便快速地进行元素的添加、删除等操作。以下是Redis列表数据结构的结构图:
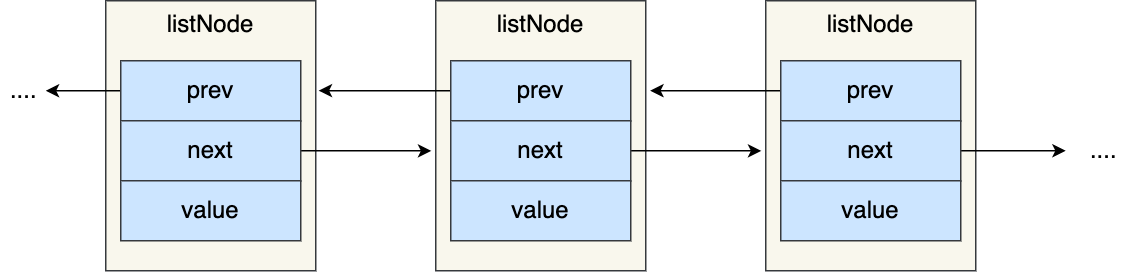
typedef struct listNode {
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
} listNode;在Redis的列表数据结构中,链表节点有两种类型:普通节点和quicklist节点。普通节点用于保存小于64字节的字符串值,而quicklist节点则用于保存大于等于64字节的字符串值或者多个小字符串值。quicklist节点实际上是一个由多个小型ziplist构成的列表,这样能够减少空间的浪费。
应用场景:
- 作为队列使用:列表数据结构支持在列表的两端进行元素的添加和删除操作,因此可以将其作为队列使用。在生产者消费者模型中,生产者将任务添加到队列中,而消费者则从队列中获取任务进行处理,从而实现任务的异步处理。
- 作为栈使用:与队列相似,列表数据结构同样支持在列表两端进行元素的添加和删除操作,因此可以将其作为栈使用。在Web开发中,可以利用Redis的列表数据结构保存用户的浏览历史记录,并且能够快速地获取最近浏览的历史记录。
- 保存关系型数据:在NoSQL数据库中,列表数据结构可以用来保存关系型数据。例如,在社交网络中,可以将关注列表和粉丝列表使用列表数据结构进行存储,从而快速地实现社交网络中的关注、粉丝等功能。
常用操作:
1、LPush(左侧插入元素):将一个或多个元素插入到列表的左侧,如果列表不存在,则创建一个新的列表。
lpush key value1 [value2 ... valuen]
2、RPush(右侧插入元素):将一个或多个元素插入到列表的右侧,如果列表不存在,则创建一个新的列表。
rpush key value1 [value2 ... valuen]3、LPop(左侧删除元素):删除并返回列表左侧的第一个元素。
lpop key4、RPop(右侧删除元素):删除并返回列表右侧的第一个元素。
rpop key5、LIndex(获取元素):获取列表中索引位置为index的元素,索引从0开始,负数表示从列表末尾开始计算。
lindex key index6、LRange(获取范围元素):获取列表中索引位置从start到end的元素,start和end都是0-based,负数表示从列表末尾开始计算。
lrange key start end7、LLen(获取列表长度):获取列表中元素的数量。
llen key8、LRem(删除指定数量的元素):从列表中删除与value相等的元素,count表示删除的个数,如果为0表示删除所有匹配的元素,如果为负数表示从列表末尾开始计算。
lrem key count value9、LTrim(修剪列表):只保留列表中从start到end之间的元素,其余的元素都将被删除,start和end都是0-based,负数表示从列表末尾开始计算。
ltrim key start end上述操作是Redis列表中的基本操作,还有一些高级操作比如BLPop、BRPop、BRPopLPush等可以满足更多特定的需求。
三、集合(Set)
Set 集合是一个无序的、不允许重复元素的集合,它的底层数据结构使用了「哈希表(Hash Table)」和「跳跃表(Skip List)」的结合体,也就是所谓的「哈希表+跳跃表」。
在 Redis 中,集合类型有两种实现方式:
intset
hashtable其中,intset 只能存储整型数据,而 hashtable 可以存储任意类型的数据。但是,由于 intset 存储的是连续的整数,因此在存储数值较小、数量较少的集合时,intset 的性能会更好。
对于使用 hashtable 存储的集合来说,其底层数据结构是由一个哈希表和多个链表(或者跳跃表)组成的。其中,哈希表用于存储集合中的元素,链表或跳跃表用于解决哈希冲突。
在 Redis 4.0 之前,Set 集合使用的是哈希表来存储元素,但是在 Redis 4.0 之后,为了提高 Set 集合的查询性能,引入了跳跃表,用于优化有序集合和集合的有序操作。
在 Redis 中,哈希表是一种常用的数据结构,它由一个数组和一些链表(或跳跃表)组成。数组中的每个元素都指向一个链表(或跳跃表),而链表(或跳跃表)则用于解决哈希冲突。当向哈希表中添加元素时,根据元素的哈希值,将元素添加到数组中的相应位置。
在 Set 集合中,每个元素的值作为键存储在哈希表中,而哈希表中的值则都被设置为 NULL。由于哈希表不允许重复键值,因此 Set 集合可以去重。
另外,在 Redis 4.0 中,引入了跳跃表用于优化有序集合和集合的有序操作。跳跃表是一种有序数据结构,它可以快速地进行插入、删除和查找操作,时间复杂度为 O(log n)。在 Set 集合中,跳跃表主要用于优化一些有序操作,例如求交集、并集、差集等操作。
使用场景
- 去重:Set能够存储唯一值,因此常用于去重场景。例如统计网站的UV(Unique Visitor)数量,可以将每个用户的IP地址存储在Set中,然后通过Set的元素数量来统计UV。
- 集合运算:Set支持并、交、差等集合运算操作,常用于实现共同关注、好友推荐等功能。例如,假设有两个用户A和B,他们的关注列表分别为Set A和Set B,那么A和B共同关注的用户可以通过Set A和Set B的交集来计算。
- 排序:Set支持按照元素的大小排序,因此可以将一些带权重的数据存储在Set中,例如用户的积分,然后按照积分大小对用户进行排序。
常用操作
1、添加元素
使用SADD命令向Set中添加元素,如果添加的元素已经存在,则不会重复添加。
SADD key member [member ...]示例:
127.0.0.1:6379> SADD myset "hello"
(integer) 1
127.0.0.1:6379> SADD myset "world"
(integer) 1
127.0.0.1:6379> SADD myset "hello"
(integer) 0
2、获取元素
使用SMEMBERS命令获取Set中的所有元素,返回一个包含所有元素的列表。
SMEMBERS key示例:
127.0.0.1:6379> SADD myset "hello"
(integer) 1
127.0.0.1:6379> SADD myset "world"
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "hello"
2) "world"
3、判断元素是否存在
使用SISMEMBER命令判断元素是否存在于Set中,如果存在返回1,否则返回0。
SISMEMBER key member示例:
127.0.0.1:6379> SADD myset "hello"
(integer) 1
127.0.0.1:6379> SISMEMBER myset "hello"
(integer) 1
127.0.0.1:6379> SISMEMBER myset "world"
(integer) 0
4、获取集合中元素的数量
使用SCARD命令获取Set中元素的数量。
SCARD key示例:
127.0.0.1:6379> SADD myset "hello"
(integer) 1
127.0.0.1:6379> SADD myset "world"
(integer) 1
127.0.0.1:6379> SCARD myset
(integer) 2
5、集合运算
使用SUNION、SINTER、SDIFF命令对Set进行集合运算,分别表示并集、交集、差集。
SUNION key [key ...]
SINTER key [key ...]
SDIFF key [key ...]示例:
127.0.0.1:6379> SADD set1 "hello"
(integer) 1
127.0.0.1:6379> SADD set1 "world"
(integer) 1
127.0.0.1:6379> SADD set2 "world"
(integer) 1
127.0.0.1:6379> SADD set2 "redis"
(integer) 1
127.0四、散列(Hash)
在 Redis 中,散列(Hash)是一种特殊的键值对集合,它们是一个字符串类型的 field 和 value 的映射表。Hash 类型非常适合存储对象。比如,一个用户对象可以用一个 Hash 类型来表示,Hash 的 field 可以是用户对象的属性,value 则是属性的值。
Redis 中的 Hash 底层数据结构是一个叫做 ziplist 的双向链表或者 hashtable。ziplist 是一个紧凑的双向链表,可以在内存中快速地进行插入、删除、更新等操作。而 hashtable 是一种基于拉链法的哈希表,可以在内存中快速地进行查找操作。
当 Hash 中的键值对数量较少且每个键值对的键和值都比较短时,Redis 会使用 ziplist 作为底层数据结构。ziplist 的优点是占用的空间比 hashtable 小,缺点是查询和更新速度较慢。
当 Hash 中的键值对数量较多或者键和值比较长时,Redis 会使用 hashtable 作为底层数据结构。hashtable 的优点是查询和更新速度较快,缺点是占用的空间比 ziplist 大。
在 Redis 中,可以使用 HSET 命令往散列中添加键值对,使用 HGET 命令获取散列中指定键的值,使用 HGETALL 命令获取散列中所有键值对的键和值等。由于 Hash 的底层数据结构的特殊性,这些操作的时间复杂度为 O(1)。
常用操作
1、设置散列键值对:使用命令 HSET 可以向散列中添加一个键值对,如果键已经存在,则会将其值覆盖。
HSET key field value2、获取散列键值对:使用命令 HGET 可以获取散列中指定键的值。
HGET key field3、获取散列所有键值对:使用命令 HGETALL 可以获取散列中所有的键值对。
HGETALL key4、删除散列键值对:使用命令 HDEL 可以删除散列中的一个或多个键值对。
HDEL key field [field ...]5、获取散列所有键或所有值:使用命令 HKEYS 或 HVALS 可以获取散列中所有的键或所有的值。
HKEYS key
HVALS key使用场景
- 用户信息存储:可以使用散列类型来存储用户的个人信息,每个用户对应一个散列,其中键是字段名,值是字段值。
- 商品信息存储:可以使用散列类型来存储商品的相关信息,每个商品对应一个散列,其中键是属性名,值是属性值。
- 计数器:可以使用散列类型来实现计数器功能,其中键是计数器的名称,值是计数器的值。
- 缓存:可以使用散列类型来实现缓存功能,将需要缓存的数据存储在散列中,使用键作为缓存的标识,值作为缓存的内容。
五、有序集合(Sorted Set)
Redis 中有序集合(Sorted Set)的底层数据结构是跳跃表(Skip List)和哈希表(Hash Table)的组合。
在 Redis 中,每个有序集合都对应了一个跳跃表和一个哈希表。其中,跳跃表用来维护有序集合的元素顺序,而哈希表则用来存储元素的值和它们在跳跃表中的位置。
跳跃表是一种随机化数据结构,可以用来实现有序集合和字典等数据结构。跳跃表通过对链表进行随机化扩展,使得其查找、插入和删除操作的时间复杂度都能够达到 O(log n),并且相比于平衡树等其他数据结构,跳跃表的实现简单,运行效率高。
具体来说,跳跃表由多个层级组成,每个层级包含一个链表。链表中的每个节点都包含一个元素值和一个指向下一层节点的指针,以及一个指向相同层级的下一个节点的指针。对于每个节点,其在每个层级的高度都是随机决定的,并且越高层的节点数越少。这样就能够保证跳跃表中的元素顺序是有序的,并且查询、插入和删除操作的时间复杂度都为 O(log n)。
在 Redis 的有序集合中,每个元素都包含一个值和一个分数(Score),分数用来对元素进行排序。Redis 的有序集合支持多个元素具有相同分数的情况,因此每个元素的值都必须是唯一的,但分数可以重复。
常用操作
1、添加元素
可以使用 ZADD 命令添加元素到有序集合中,并指定每个元素的分数,如果元素已经存在,则更新分数。
ZADD key score1 member1 [score2 member2]例如:
ZADD myzset 10 "redis"这将在名为 myzset 的有序集合中添加一个值为 "redis",分数为 10 的元素。
2、获取元素
可以使用 ZRANGE 命令获取指定范围内的元素,可以按照分数从小到大排序或从大到小排序。
ZRANGE key start stop [WITHSCORES]例如:
ZRANGE myzset 0 -1 WITHSCORES这将返回 myzset 中的所有元素以及它们的分数。
3、获取元素数量
可以使用 ZCARD 命令获取有序集合中元素的数量。
ZCARD key例如:
ZCARD myzset
4、获取元素排名
可以使用 ZRANK 命令获取指定元素在有序集合中的排名,排名从 0 开始,按照分数从小到大排序。
ZRANK key member例如:
ZRANK myzset "redis"
5、获取元素分数
可以使用 ZSCORE 命令获取指定元素在有序集合中的分数。
ZSCORE key member例如:
ZSCORE myzset "redis"使用场景
1、排行榜
可以使用有序集合存储用户的得分和排名,使用 ZADD 命令添加用户得分,使用 ZREVRANGE 命令按照分数从高到低获取排行榜。
2、计数器
可以使用有序集合存储计数器的值,使用 ZINCRBY 命令增加计数器的值,使用 ZSCORE 命令获取计数器的值。
3、排序
可以使用有序集合存储需要排序的数据,使用 ZADD 命令添加数据,使用 ZRANGE 命令按照分数从小到大排序获取数据。













![P19[6-7]编码器接口(硬)](https://img-blog.csdnimg.cn/badbbe3e886245289d9949ef48d20b24.png)
