介绍
索引就是用来加速SQL查询的
由于索引也是需要存储成索引文件的,因此对索引的使用也会涉及磁盘I/O操作。如果索引创建过多,使用不当,会造成SQL查询时,进行大量无用的磁盘I/O操作,降低了SQL的查询效率,适得其反。
分类
索引是创建在表上的,是对数据库表中一列或者多列的值进行排序的一种结果。索引的核心是提高查询的速度!
物理上(聚集(聚簇)索引&非聚集索引)/逻辑上(…)
1、**普通(二级)**索引:没有任何限制条件,可以给任何类型的字段创建普通索引(创建新表&已创建表,数量是不限的,一张表的一次sql查询只能用一个索引
2、唯一性索引:使用UNIQUE修饰的字段,值不能够重复,主键索引就隶属于唯一性索引
3、主键索引:使用Primary Key修饰的字段会自动创建索引(MyISAM, InnoDB)
4、单列索引:在一个字段上创建索引
5、多列索引:在表的多个字段上创建索引 (uid+cid,多列索引必须使用到第一个列,才能用到多列索引,否则索引用不上)
6、全文索引:使用FULLTEXT参数可以设置全文索引,只支持CHAR,VARCHAR和TEXT类型的字段上,常用于数据量较大的字符串类型上,可以提高查询速度(线上项目支持专门的搜索功能,给后台服务器增加专门的搜索引擎支持快速高效的搜索 elasticsearch 简称es 以及 C++开源的搜索引擎 搜狗的workflow)
例子1
在 student 表上 name列创建一个名为 nameidx的 索引:
create index nameidx on student(name);
查看表信息

查询时就用到索引了

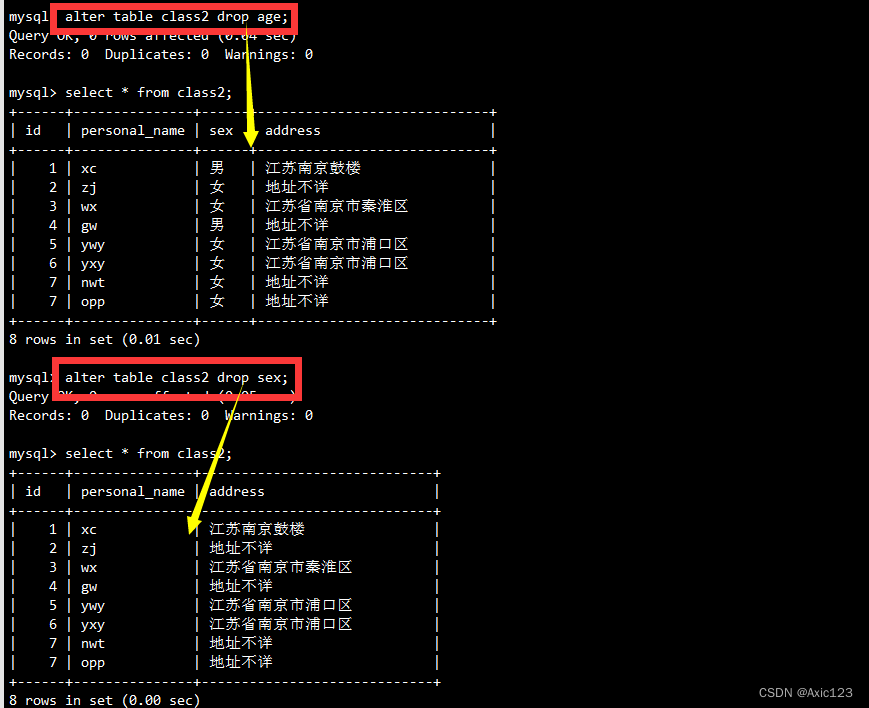
删除 t_user表中 名为 pwdidx 的索引:
drop index pwdidx on t_user;
相关要点
-
可以给经常作为过滤条件的字段加索引;
-
字符串列创建索引时,尽量规定索引长度,而不能让索引长度
key_len过长; -
索引字段涉及类型强转,函数调用,表达式计算时,索引失效,即:


没发生强转就用到了索引:

例子3:select * 回表问题
当建立某列的普通(二级)索引树的时其会存储对应的主键列,查询索引列和主键列直接在二级索引树获取(InnoDB才可以),如果查询其他列数据则需要拿着主键列去回表查询:

Using index代表直接二级索引树上获得数据,而NULL代表发生了回表扫描。
如果要使用对多个列进行查询,也可以试图采用联合(多列)索引:
create index age_name_id on student(age,name);
explain select * from student where age = 20 order by name;

但是多列索引第一列必须要匹配,否则第二列用不上,例如: