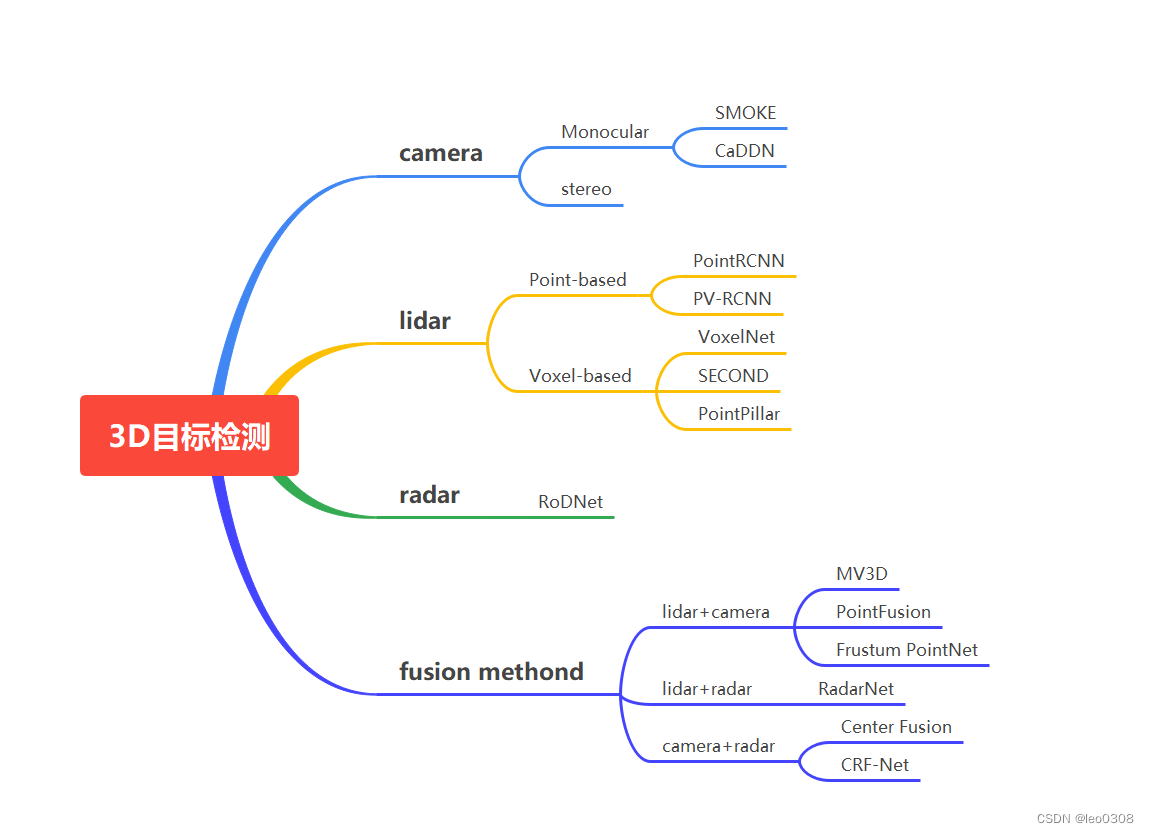
3D目标检测最主要的应用领域是自动驾驶,主流用的传感器是camera和lidar, 一般车上也会配备很多radar, 但是在检测中一般很少用到radar。
除了特斯拉坚决不用lidar, 只基于纯视觉做自动驾驶感知, 大多数的自动驾驶感知主传感器都是lidar, 然后加几个camera作为辅助。
最近也有一些研究开始在感知中采用radar, 但是一般也只是作为辅助。 然而radar的发展还是很快的, 特别是4D毫米波雷达出现, 未来没准能取代lidar。
1 单模态方法
单模态方式是指只采用单一传感器, 一般是lidar, camera。也有少数采用radar, 但基本处于非常低级的实验阶段, 不具备实用性。
1.1 camera
基于camera的2D检测是非常成熟的,深度学习在这个领域也是大放异彩。 但是在3D检测中, camera却面临巨大的挑战, 其中一个最大的难点是单目的camera没法测量深度,这对3D目标检测是致命的影响, 对应到自动驾驶场景就是, 你检测到前面有个目标, 但你不知道目标离你多远。当然这个问题也不是完全无解, 一般有这么2种方法解决:
- 1 采用单目估计深度。单目估计深度本质上是一个病态问题, 所以别指望会估的多准。
- 2 增加摄像头,2个及以上摄像头就可以估计深度。 这个方案会比单目好很多, 起码理论上也靠谱很多。 但是系统复杂度也高, 多个摄像头还涉及到定标, 校正, 实际用起来效果可能也不是那么理想。
这一类的方法非常多, 可以参考我的两外2篇博客:
[1] 单目3D目标检测网络CaDDN解读
[2] 单目3D目标检测网络SMOKE解读
1.2 lidar
基于lidar做3D目标检测应该说是自动驾驶感知中最主流的一种方法了。 在所有的单模态方法中效果也是最好的, 而且是领先很多的那种。 以KITTI数据集中的Car为例, 基于lidar的方法mAP可以做到80以上的有很多, 但是基于单目图像一般只能做到20左右。
1.3 radar
基于radar做3D目标检测的工作很少, 已有的少量工作基本处于玩具的转态。
但是随着4D radar的发展, 这方面的工作应该会逐渐多起来。
2 多模态方法
每个传感器都有各自的优劣, 比如lidar虽好,也有几个不小的缺点:极端天气环境下性能急剧下降,价格贵;另外机械式激光雷达不抗造,没法通过车规, 半固态会好一点, 有些产品已经能通过车规,纯固态是一个理想的方式, 目前正在朝这个方向大力发展。 这是激光雷达的3宗罪。摄像头更不必说了, 天气稍微差一点更是没法工作。 radar作用距离远也抗恶劣天气, 并且不是很贵, 但就是分辨率太差了, 不是一般的差。4D radar的出现或许会改变这一局面。
所以主流的多模态融合方法是lidar + camera, 加上radar的, 一般也就是个打酱油的角色。
2.1 lidar + camera
典型工作有:
1 MV3D
Multi-view 3d object detection network for autonomous driving
2 PointFusion
3 Frustum PointNet
2.2 camera + radar
1 CRF-Net
2 CenterFusion
参考我的另一篇博客: CenterFusion解读
2.3 lidar + radar
1 RadarNet
2.3 lidar + camera + radar
3 参考
[1] CenterFusion: Center-based Radar and Camera Fusion for 3D Object Detection


![[附源码]JAVA毕业设计南京传媒学院门户网(系统+LW)](https://img-blog.csdnimg.cn/06c151110388412fb57e4e87ceecf716.png)



![[黑马程序员C++笔记]P174-P184模板-类模板](https://img-blog.csdnimg.cn/3d109177853942a1b24cbb88727ec928.png)