此笔记为尚硅谷MySQL高级篇部分内容
目录
一、主从复制概述
1、如何提升数据库并发能力
2、主从复制的作用
二、主从复制的原理
1、原理剖析
2、复制的基本原则
三、一主一从架构搭建
1、准备工作
2、主机配置文件
3、从机配置文件
4、主机:建立账户并授权
5、从机:配置需要复制的主机
6、测试
7、停止主从同步
8、后续
四、同步数据一致性问题
1、理解主从延迟问题
2、主从延迟问题原因
3、如何减少主从延迟
4、如何解决一致性问题
方法 1:异步复制
方法 2 :半同步复制
方法 3:组复制
五、知识延伸
一、主从复制概述
1、如何提升数据库并发能力
在实际工作中,我们常常将
Redis作为缓存与MySQL配合来使用,当有请求的时候,首先会从缓存中进行查找,如果存在就直接取出。如果不存在再访问数据库,这样就提升了读取的效率,也减少了对后端数据库的访问压力。Redis的缓存架构是高并发架构中非常重要的一环。

此外,一般应用对数据库而言都是“ 读多写少 ”,也就说对数据库读取数据的压力比较大,有一个思路就是采用数据库集群的方案,做 主从架构 、进行 读写分离 ,这样同样可以提升数据库的并发处理能力。但并不是所有的应用都需要对数据库进行主从架构的设置,毕竟设置架构本身是有成本的。
如果我们的目的在于提升数据库高并发访问的效率,那么首先考虑的是如何 优化SQL和索引 ,这种方式简单有效;其次才是采用 缓存的策略 ,比如使用 Redis将热点数据保存在内存数据库中,提升读取的效率;最后才是对数据库采用 主从架构 ,进行读写分离。
2、主从复制的作用
主从同步设计不仅可以提高数据库的吞吐量,还有以下 3 个方面的作用。
第 1 个作用:读写分离。我们可以通过主从复制的方式来同步数据,然后通过读写分离提高数据库并发处理能力
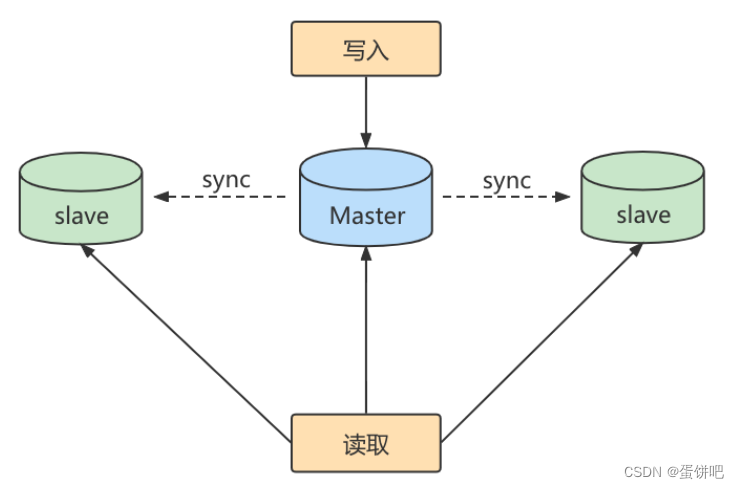
第 2 个作用就是数据备份。我们通过主从复制将主库上的数据复制到了从库上,相当于是一种热备份机制,也就是在主库正常运行的情况下进行的备份,不会影响到服务。
第 3 个作用是具有高可用性。数据备份实际上是一种冗余的机制,通过这种冗余的方式可以换取数据库的高可用性,也就是当服务器出现
故障或宕机的情况下,可以切换到从服务器上,保证服务的正常运行。
二、主从复制的原理
Slave会从Master读取binlog来进行数据同步。
1、原理剖析
三个线程
实际上主从同步的原理就是基于 binlog 进行数据同步的。在主从复制过程中,会基于 3 个线程 来操作,一个主库线程,两个从库线程。

二进制日志转储线程 (Binlog dump thread)是一个主库线程。当从库线程连接的时候, 主库可以将二进制日志发送给从库,当主库读取事件(Event)的时候,会在 Binlog 上 加锁 ,读取完成之后,再将锁释放掉。
从库 I/O 线程 会连接到主库,向主库发送请求更新 Binlog。这时从库的 I/O 线程就可以读取到主库的二进制日志转储线程发送的 Binlog 更新部分,并且拷贝到本地的中继日志 (Relay log)。
从库 SQL 线程 会读取从库中的中继日志,并且执行日志中的事件,将从库中的数据与主库保持同步。
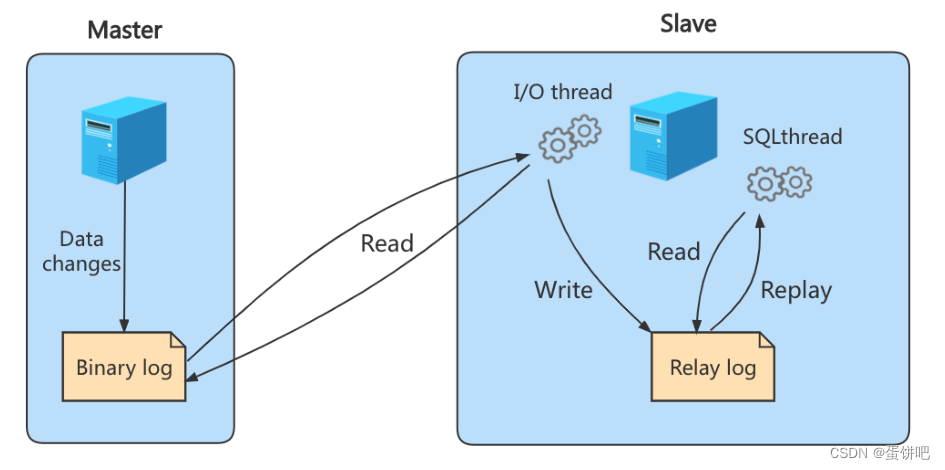
复制三步骤
步骤1: Master 将写操作记录到二进制日志( binlog )。
步骤2: Slave 将 Master 的binary log events拷贝到它的中继日志( relay log );
步骤3: Slave 重做中继日志中的事件,将改变应用到自己的数据库中。 MySQL复制是异步的且串行化的,而且重启后从 接入点 开始复制。
复制的问题
复制的最大问题: 延时
2、复制的基本原则
- 每个 Slave 只有一个 Master
- 每个 Slave 只能有一个唯一的服务器ID
- 每个 Master 可以有多个 Slave
三、一主一从架构搭建
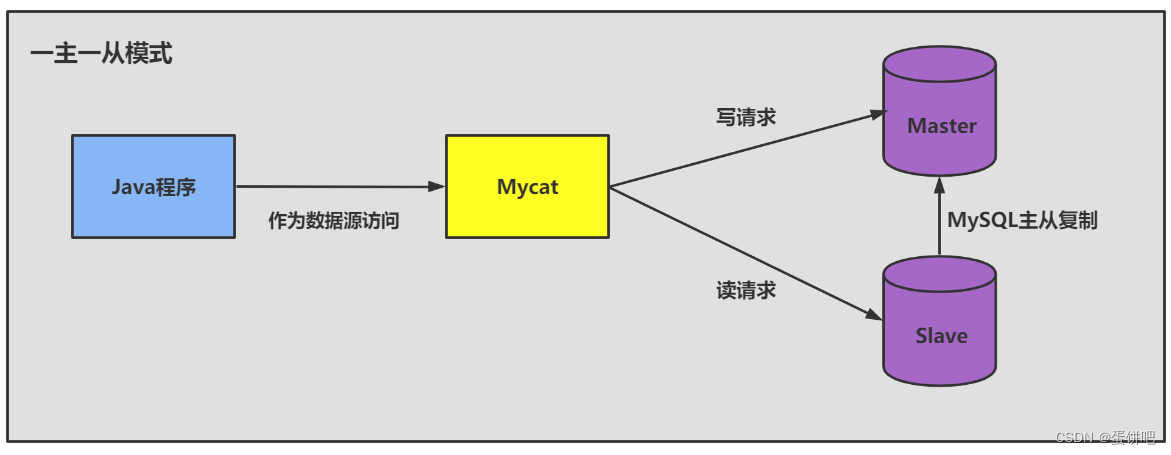
一台 主机 用于处理所有 写请求 ,一台 从机 负责所有 读请求 ,架构图如下:
1、准备工作

修改MySQL Server 的UUID方式:
vim /var/lib/mysql/auto.cnf
systemctl restart mysqld2、主机配置文件
建议mysql版本一致且后台以服务运行,主从所有配置项都配置在 [mysqld] 节点下,且都是小写字母。具体参数配置如下:
- 必选
#[必须]主服务器唯一ID
server-id=1
#[必须]启用二进制日志,指名路径。比如:自己本地的路径/log/mysqlbin
log-bin=atguigu-bin- 可选
#[可选] 0(默认)表示读写(主机),1表示只读(从机)
read-only=0
#设置日志文件保留的时长,单位是秒
binlog_expire_logs_seconds=6000
#控制单个二进制日志大小。此参数的最大和默认值是1GB
max_binlog_size=200M
#[可选]设置不要复制的数据库
binlog-ignore-db=test
#[可选]设置需要复制的数据库,默认全部记录。比如:binlog-do-db=atguigu_master_slave
binlog-do-db=需要复制的主数据库名字
#[可选]设置binlog格式
binlog_format=STATEMENTbinlog格式设置:
格式1: STATEMENT模式 (基于SQL语句的复制(statement-based replication, SBR))
binlog_format=STATEMENT
②ROW模式(基于行的复制(row-based replication, RBR))

③MIXED模式(混合模式复制(mixed-based replication, MBR))
binlog_format=MIXED
3、从机配置文件
要求主从所有配置项都配置在my.cnf的[mysqld]栏位下,且都是小写字母。
- 必选
#[必须]从服务器唯一ID server-id=2 - 可选
#[可选]启用中继日志 relay-log=mysql-relay重启后台mysql服务,使配置生效。
注意:主从机都关闭防火墙
service iptables stop #CentOS 6
systemctl stop firewalld.service #CentOS 7
4、主机:建立账户并授权
#在主机MySQL里执行授权主从复制的命令
GRANT REPLICATION SLAVE ON *.* TO 'slave1'@'从机器数据库IP' IDENTIFIED BY 'abc123';
#5.5,5.7注意:如果使用的是MySQL8,需要如下的方式建立账户,并授权slave:
CREATE USER 'slave1'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE ON *.* TO 'slave1'@'%';
#此语句必须执行。否则见下面。
ALTER USER 'slave1'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
flush privileges;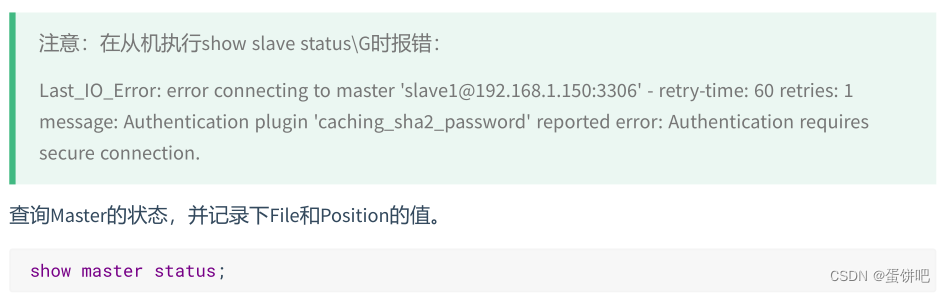
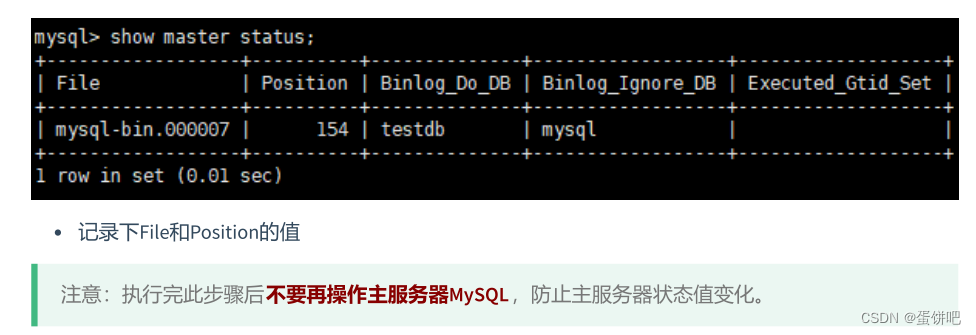
5、从机:配置需要复制的主机
步骤1:从机上复制主机的命令
CHANGE MASTER TO
MASTER_HOST='主机的IP地址',
MASTER_USER='主机用户名',
MASTER_PASSWORD='主机用户名的密码',
MASTER_LOG_FILE='mysql-bin.具体数字',
MASTER_LOG_POS=具体值;
步骤2:
#启动slave同步
START SLAVE;
如果报错:

可以执行如下操作,删除之前的relay_log信息。然后重新执行 CHANGE MASTER TO 语句即可。
mysql> reset slave; #删除SLAVE数据库的relaylog日志文件,并重新启用新的relaylog文件接着,查看同步状态:
SHOW SLAVE STATUS\G;
上面两个参数都是Yes,则说明主从配置成功!


6、测试
主机新建库、新建表、insert记录,从机复制:
CREATE DATABASE atguigu_master_slave;
CREATE TABLE mytbl(id INT,NAME VARCHAR(16));
INSERT INTO mytbl VALUES(1, 'zhang3');
INSERT INTO mytbl VALUES(2,@@hostname);7、停止主从同步
- 停止主从同步命令:
stop slave;- 如何重新配置主从
如果停止从服务器复制功能,再使用需要重新配置主从。否则会报错如下:

重新配置主从,需要在从机上执行:
stop slave;
reset master; #删除Master中所有的binglog文件,并将日志索引文件清空,重新开始所有新的日志文件(慎用)8、后续
搭建主从复制:双主双从
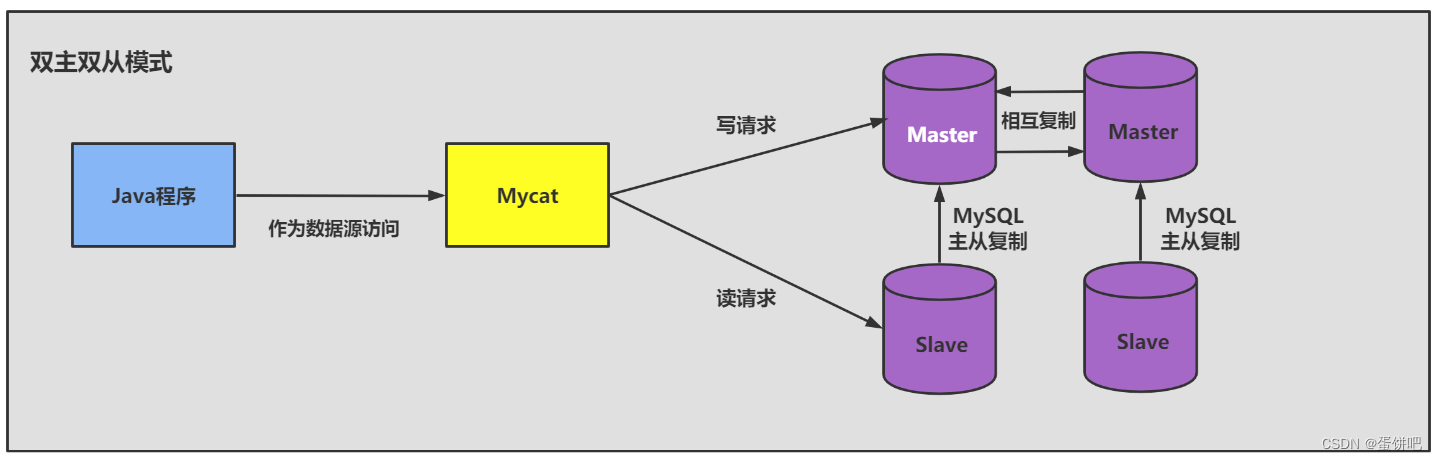

四、同步数据一致性问题
主从同步的要求:
读库和写库的数据一致(最终一致);
写数据必须写到写库;
读数据必须到读库(不一定);
1、理解主从延迟问题
进行主从同步的内容是二进制日志,它是一个文件,在进行 网络传输 的过程中就一定会 存在主从延迟(比如 500ms),这样就可能造成用户在从库上读取的数据不是最新的数据,也就是主从同步中的 数据不一致性 问题。

2、主从延迟问题原因
在网络正常的时候,日志从主库传给从库所需的时间是很短的,即T 2 - T 1 的值是非常小的。即,网络正常情况下,主备延迟的主要来源是备库接收完binlog和执行完这个事务之间的时间差。
主备延迟最直接的表现是,从库消费中继日志(relay log)的速度,比主库生产binlog的速度要慢。
造成原因:
1、从库的机器性能比主库要差
2、从库的压力大
3、大事务的执行

3、如何减少主从延迟
若想要减少主从延迟的时间,可以采取下面的办法:
1. 降低多线程大事务并发的概率,优化业务逻辑
2. 优化SQL,避免慢SQL, 减少批量操作 ,建议写脚本以update-sleep这样的形式完成。
3. 提高从库机器的配置 ,减少主库写binlog和从库读binlog的效率差。
4. 尽量采用 短的链路 ,也就是主库和从库服务器的距离尽量要短,提升端口带宽,减少binlog传输的网络延时。
5. 实时性要求的业务读强制走主库,从库只做灾备,备份。
4、如何解决一致性问题
如果操作的数据存储在同一个数据库中,那么对数据进行更新的时候,可以对记录加写锁,这样在读取的时候就不会发生数据不一致的情况。但这时从库的作用就是 备份 ,并没有起到 读写分离 ,分担主库读压力 的作用。
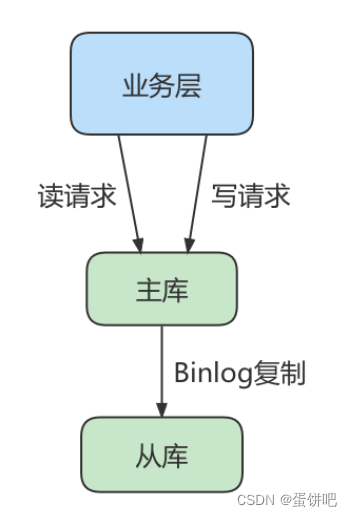
读写分离情况下,解决主从同步中数据不一致的问题, 就是解决主从之间 数据复制方式 的问题,如果按照数据一致性 从弱到强 来进行划分,有以下 3 种复制方式。
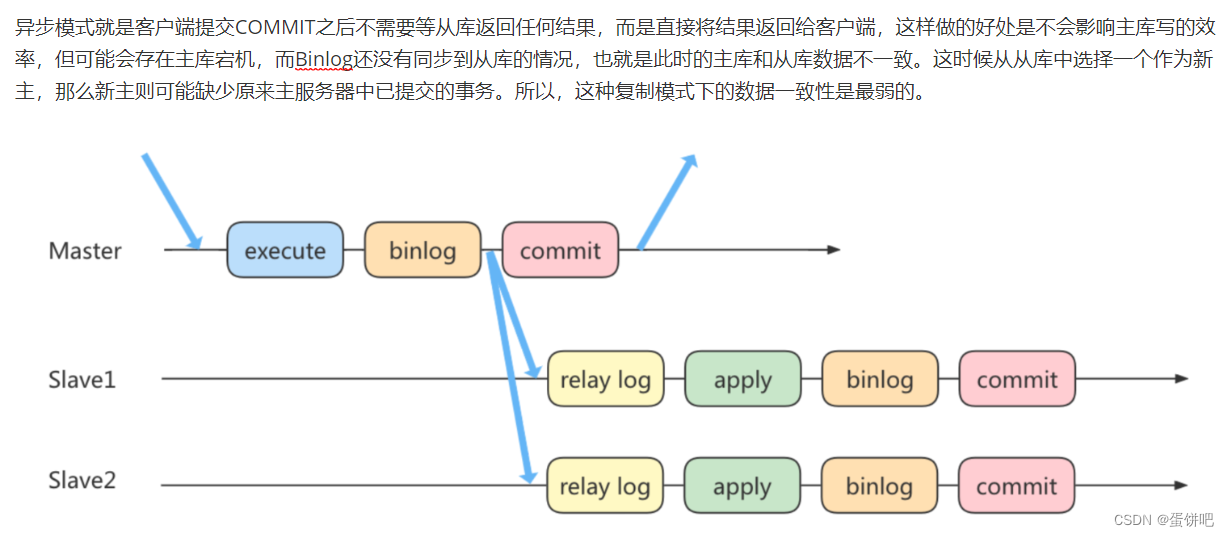
方法 1:异步复制
方法 2 :半同步复制

方法 3:组复制

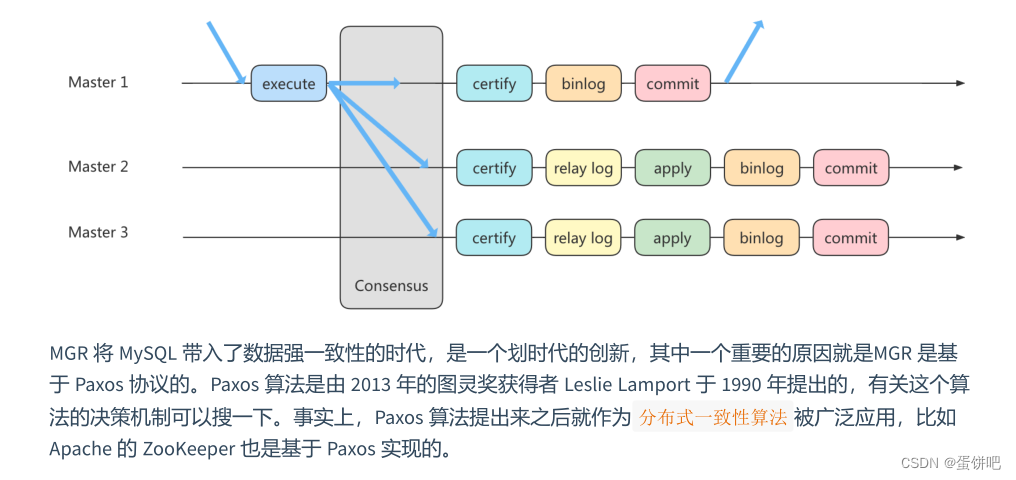
MGR 是如何工作的

五、知识延伸





主备切换:

高级篇笔记PDF自取
链接:https://pan.baidu.com/s/1pVqrTwIZFoED77i-EFmw6g?pwd=3333
提取码:3333