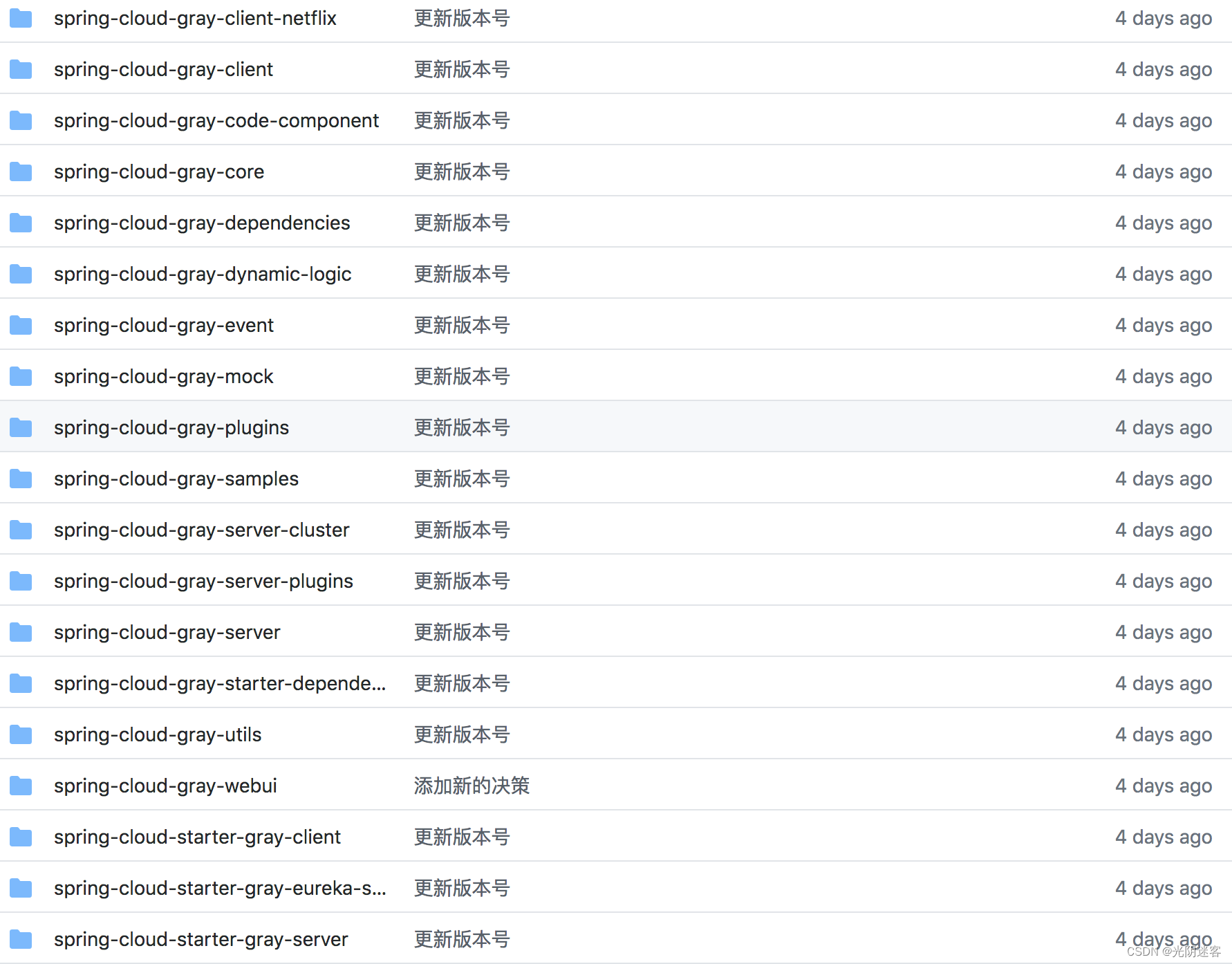
爬虫基础知识
一、爬虫的概念
模拟浏览器,发送请求,获取响应
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端(主要指浏览器)发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
- 原则上,只要是客户端(浏览器)能做的事情,爬虫都能够做
- 爬虫也只能获取客户端(浏览器)所展示出来的数据
二、爬虫的作用
爬虫在互联网世界中有很多的作用,比如:
- 数据采集
- 抓取微博评论(机器学习舆情监控)
- 抓取招聘网站的招聘信息(数据分析、挖掘)
- 新浪滚动新闻
- 百度新闻网站
- 软件测试
- 爬虫之自动化测试
- 虫师
- 12306抢票
- 网站上的投票
- 投票网
- 网络安全
- 短信轰炸
- 注册页面1
- 注册页面2
- 注册页面3
- web漏洞扫描
- 短信轰炸
三、爬虫的分类
1、根据被爬取网站的数量不同,可以分为:
- 通用爬虫,如 搜索引擎
- 聚焦爬虫,如12306抢票,或专门抓取某一个(某一类)网站数据
2、根据是否以获取数据为目的,可以分为:
- 功能性爬虫,给你喜欢的明星投票、点赞
- 数据增量爬虫,比如招聘信息
3、根据url地址和对应的页面内容是否改变,数据增量爬虫可以分为:
- 基于url地址变化、内容也随之变化的数据增量爬虫
- url地址不变、内容变化的数据增量爬虫
 四、爬虫的流程
四、爬虫的流程
爬虫的基本流程如图所示
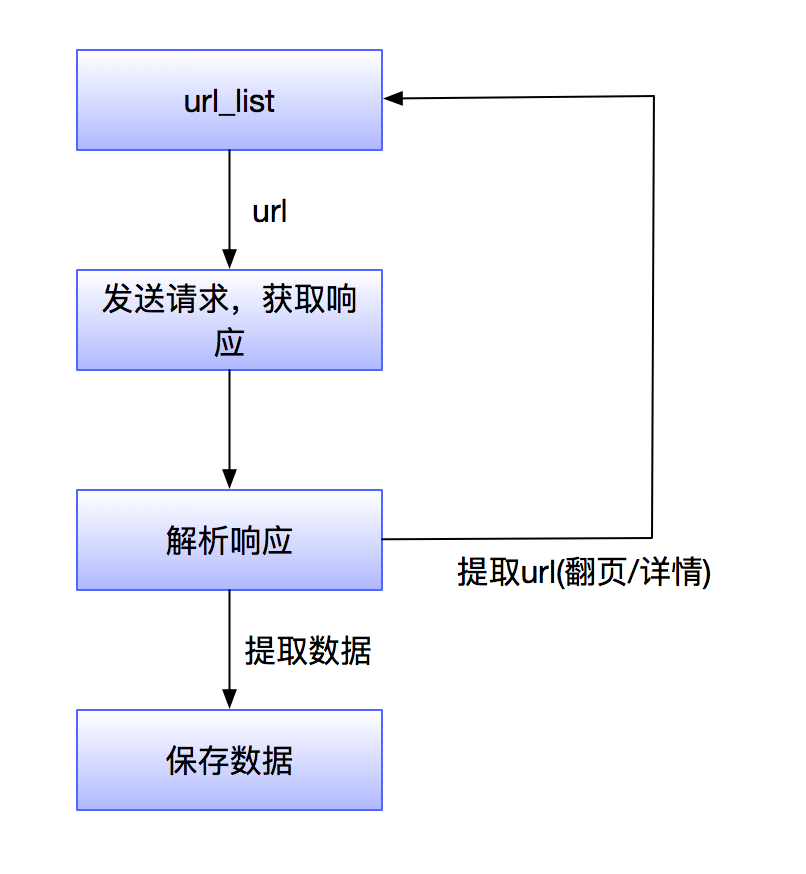
- 获取一个url
- 向url发送请求,并获取响应(需要http协议)
- 如果从响应中提取url,则继续发送请求获取响应
- 如果从响应中提取数据,则将数据进行保存