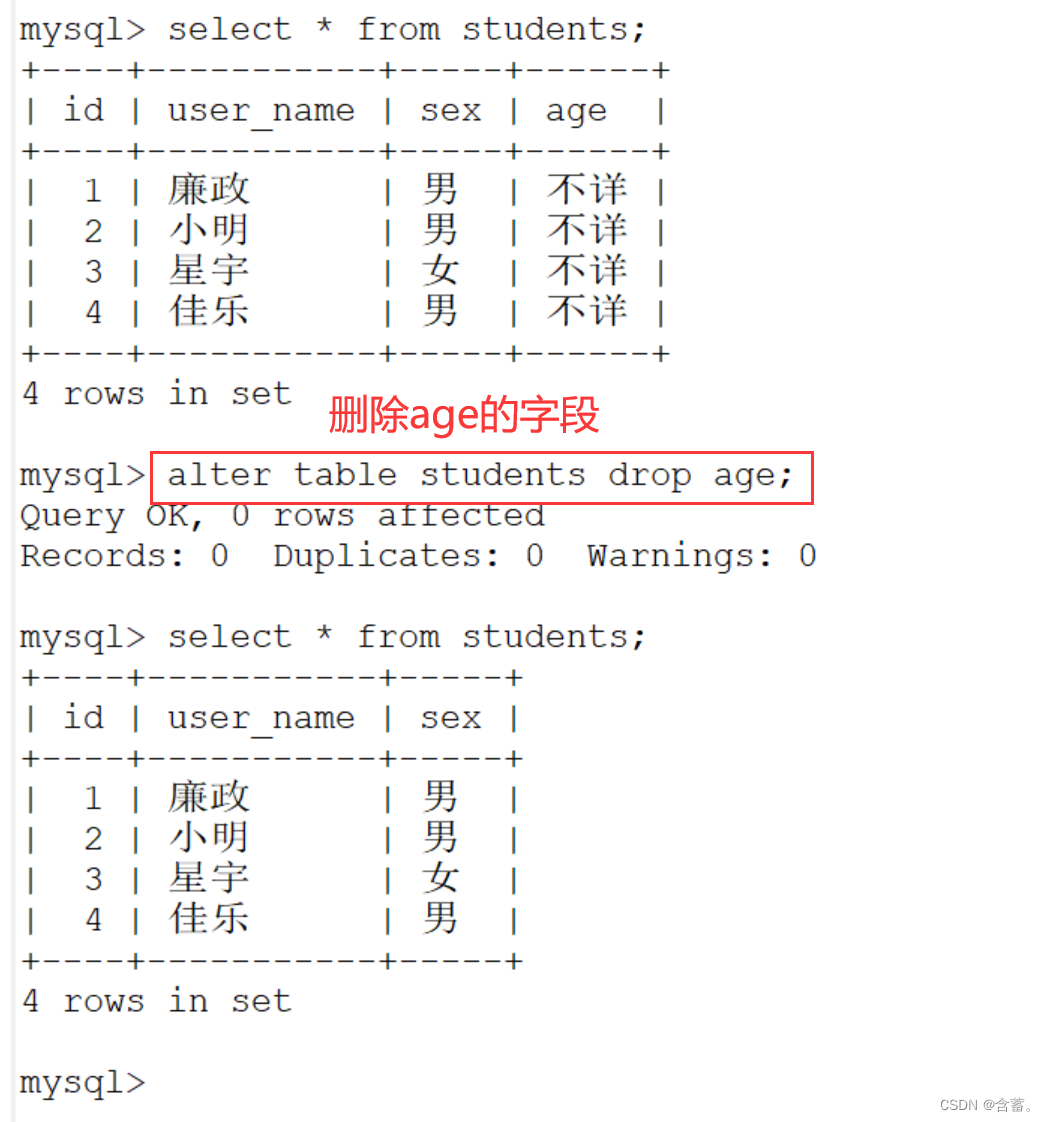
目录
- 数分
- 分布式
- Apache ZooKeeper
- Apache Hadoop
- Shell 命令选项
- 数据仓库
- Hive
数分
数据分析的目的是把隐藏在数据背后的信息集中和提炼出来,总结出所研究
对象的内在规律,帮助管理者进行有效的判断和决策。
目的:提炼信息,找出规律,辅助决策
作用:现状分析、原因分析、预测分析
分析步骤:明确分析目的-数据收集-数据预处理-数据分析-展示-报告撰写
数据收集:公开、数据库、爬虫、市场调查
报告撰写:要有明确的结论、建议或解决方案
大数据5V特征:数据量大、种类多、价值密度低、增长速度快、数据质量低
分布式
- 分布式:一个硬件或者组件,其组件分布在不同的计算机上,彼此之间仅仅通过网络消息传递进行通信
一群独立计算机集合起来共同对外提供服务,但是对于系统用户来说,就像是一台计算机在提供服务一样 - 分布式:分布式应用和服务( Dubbo)、分布式数据存储(Apache Hadoop HDFS)、分布式计算(Apache Hadoop MapReduce)
- 分布式(distributed)是指在多台不同的服务器中部署不同的服务模块,通过远程调用协同工作,对外提供服务。
- 集群(cluster)是指在多台不同的服务器中部署相同应用或服务模块,构成一个集群,通过负载均衡设备对外提供服务。
Apache ZooKeeper
ZooKeeper 本质上是一个分布式的小文件存储系统。提供基于类似于文件系
统的目录树方式的数据存储,并且可以对树中的节点进行有效管理。从而用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理
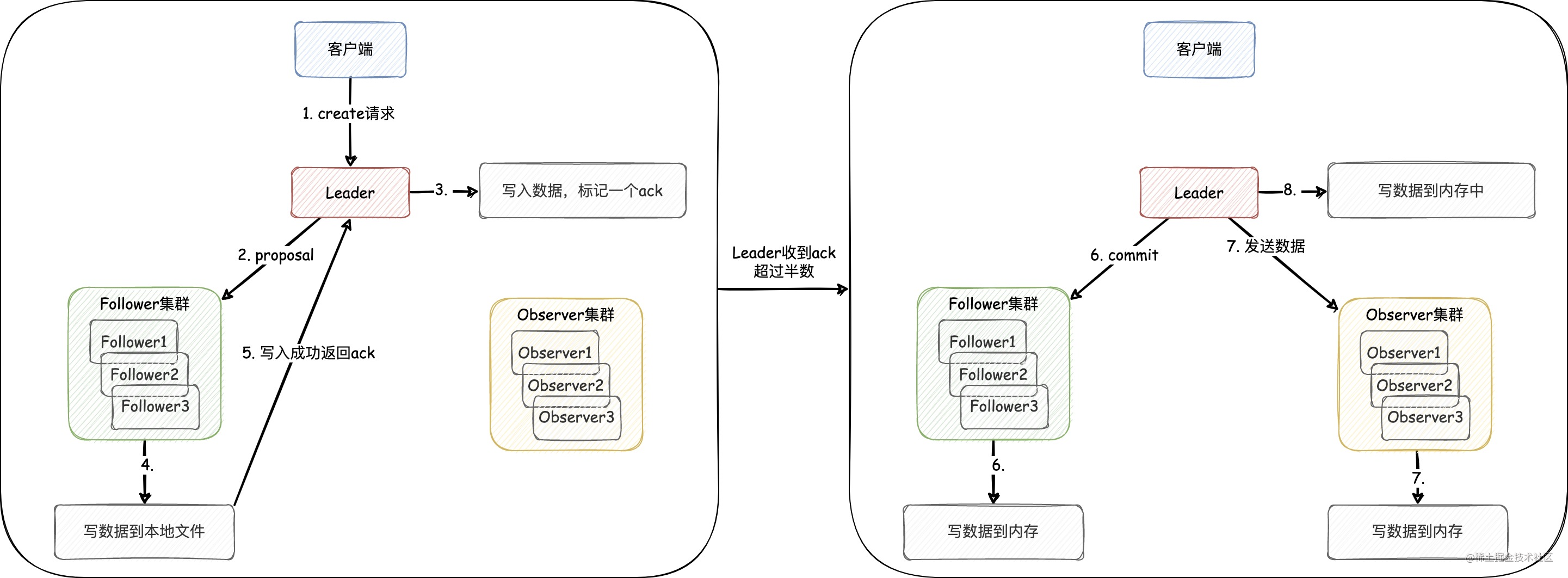
ZooKeeper 集群角色:
- Leader(事务请求(写操作)的唯一调度和处理者)
- Follower(处理客户端非事务(读操作)请求)
- Observer(观察 Zookeeper 集群的最新状态,对于非事务请求可以进行独立处理,对于事务请求,则会转发给 Leader)
Apache Hadoop
Hadoop 指 Apache 这款开源框架,它的核心组件有:
- HDFS(分布式文件系统):解决海量数据存储
- YARN(作业调度和集群资源管理的框架):解决资源任务调
- MAPREDUCE(分布式运算编程框架):解决海量数据计算
HADOOP 集群具体来说包含两个集群:HDFS 集群和 YARN 集群,两者逻辑上分离,但物理上常在一起。
- HDFS 集群负责海量数据的存储,集群中的角色主要有:
NameNode、DataNode、SecondaryNameNode - YARN 集群负责海量数据运算时的资源调度,集群中的角色主要有:
ResourceManager、NodeManager
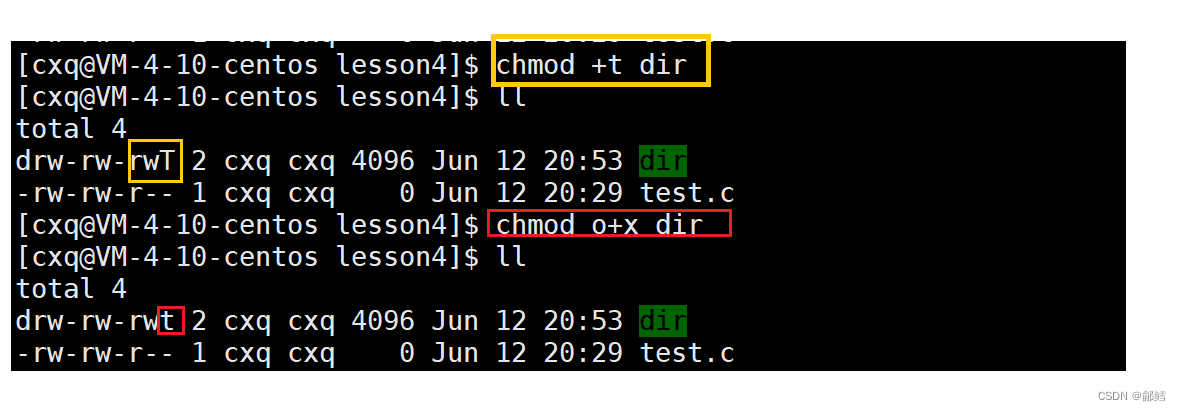
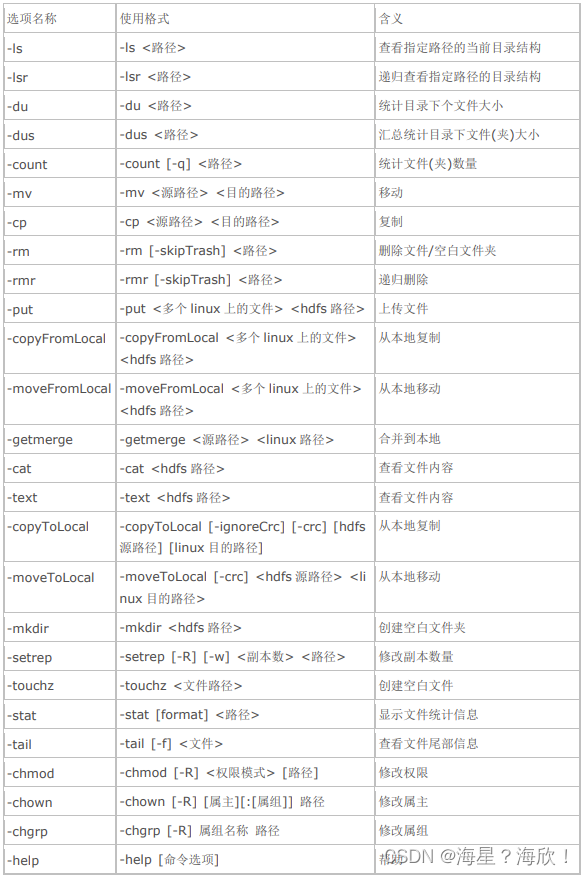
Shell 命令选项
数据仓库
数据仓库是面向主题的(Subject-Oriented )、集成的(Integrated)、非
易失的(Non-Volatile)和时变的(Time-Variant )数据集合,用以支持管理
决策。
数据仓库,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、
为了决策需要而产生的,它决不是所谓的“大型数据库”。
Hive
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为
一张数据库表,并提供类 SQL 查询功能。
本质是将 SQL 转换为 MapReduce 程序。
主要用途:用来做离线数据分析,比直接用 MapReduce 开发效率更高。
Hive组件:
- 用户接口:包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line
interface)为 shell 命令行;JDBC/ODBC 是 Hive 的 JAVA 实现,与传统数据库JDBC 类似;WebGUI 是通过浏览器访问 Hive。 - 元数据存储:通常是存储在关系数据库如 mysql/derby 中
- 解释器、编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分
析、编译、优化以及查询计划的生成。
Hive 利用 HDFS 存储数据,利用 MapReduce 查询分析数据。