前沿:本博文分享了2023 中国无锡举办的VALSE 中与目标跟踪相关的Poster。
1. Weakly Alignment-Free RGBT Salient Object Detection With Deep Correlation Network
IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 31, 20
摘要:RGBT显著性目标检测(salient object detection, SOD)关注于一对可见和热红外图像的共同的显著性区域。现存的方法在对齐的RGBT图像对上执行,但是被捕获的图像对总不是对齐的,且对齐图像对需要大量的人工代价。
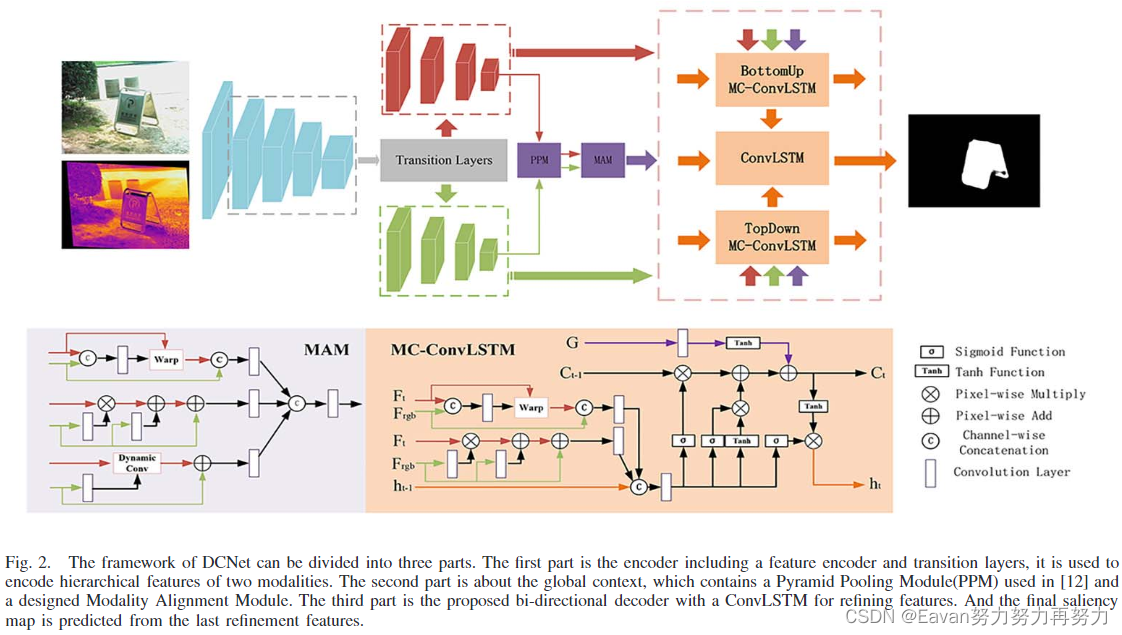
为了处理这个问题,本文提出一个新颖的深度相关网络(DCNet),探索RGB和热红外两种模态的相关性用于弱对齐自由(weakly alignment-free) RGBT SOD。具体地,DCNet由一个1. 基于空间放射变换的模态对齐模块、2. 逐特征对齐变换、3. 动态卷积组成,来实现两种模态强相关性的建模。此外,提出双向解码模型,其结合了从粗到细和从细到粗的过程,以更好地增强特征。具体地,通过添加模态对齐模块前两个元素和一个全局上下文增强模块设计了一个模态相关ConvLSTM,用于以自上而下和按钮向上的方式解码层次特征。
在3个公开数据集上的实验结果表明本文方法实现了remarkable performance.
Contribution:
- 提出了一个新任务——弱对齐自由(weakly alignment-free) RGBT SOD,以缓解RGBT SOD中需要大量人工代价的问题并有效节约了时间;
- 提出了一个新方法——从空间、特征、语义层次考虑模态间的相关性,实现了更有效的表达;
- 设计了一个新模块——modality alignment module (MAM)处理两个模态的空间不对齐问题,并提出一个双向解码器让网络具有信息选择和抑制的能力。

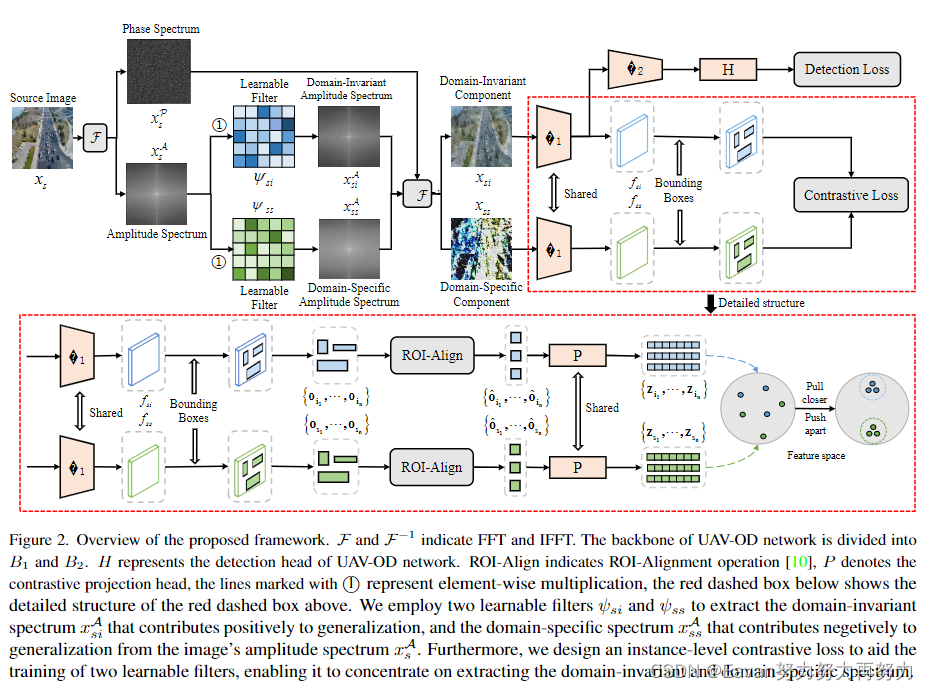
2. Generalized UAV object detection via frequency domain disentanglement
通过频域解耦的广义无人机目标检测, CVPR, 2023
摘要:部署无人机目标检测(UAV-OD)网络在复杂且未见过的实际场景中,泛化能力由于domain shift将会降低。
为了解决该问题,本文提出了频域解耦方法来提升UAV-OD的泛化能力。具体地,先验证了图像中不同波段的光谱对无人机泛化能力有不同的影响。基于此,设计了2个可学习的滤波器来提取域不变谱和域特定谱。前者可用于训练UAV-OD网络并提升泛化能力。此外,设计了一个实例级对比损失来指导网络训练,该损失使网络集中于提取域不变光谱和域特定谱,以实现更好地解耦结果。
在3个未见过目标域上的实验结果展示本方法比baseline和SOTA算法具有更好的泛化能力。
Contribution:
- 提供了一个新的视角提升UAV-OD网络在未见过目标域上的泛化能力。这是第一个通过频域解耦学习泛化的UAV-OD;
- 基于频域解耦,提出了新的框架,利用可学习的滤波器提取域不变谱和域特定谱,并设计了一个实例级对比损失指导解耦过程;
- 在3个未见过目标域上的实验结果展示本方法比baseline和SOTA算法具有更好的泛化能力。

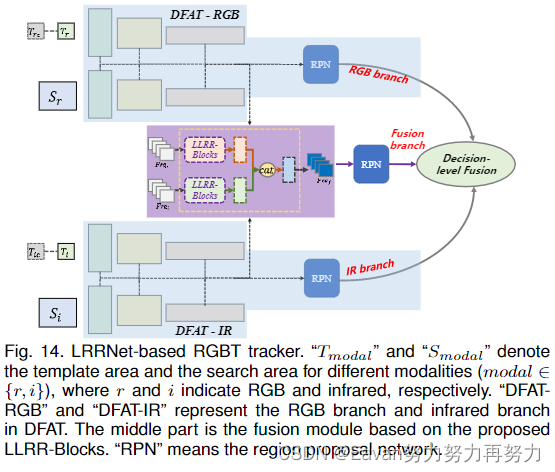
3. LRRNet: A Novel representation learning guided fusion network for infrared and visible images
江南大学人工智能与计算机学院吴小俊教授团队, 2023, TPAMI
摘要:基于混合模型的深度学习已经在图像混合任务中实现了很好的效果,这是因为网络结构在混合过程中扮演了一种重要的角色。但是一般来说,很难指定一个好的融合架构,因此,融合网络的设计仍然是一门魔法,而不是科学。
为了解决这个问题,我们将混合任务数学化,建立最优解和网络架构之间的连接。该种方法提出了一种构建轻量级融合网络的新方法,通过试验和测试策略避免了耗时的经验网络设计。具体地,采用了一个可学习的表达方式用于混合任务,其中混合网络架构的构建由最优化算法指导。低秩表达(low-rank representation, LRR)目标是可学习模型的基础。解决方案的核心 矩阵乘法 被转化为卷积运算,优化的迭代过程被一个特殊的前馈网络所取代。基于该网络架构,一个端到端的轻量级混合网络被构建以混合热红外和可见光图像。它的成功训练得益于一个细节到语义信息损失函数(a detail-to-semantic information loss function),该函数保留了图像细节并增强源图像的显著特征。
Contribution:
- 提出了一个新的网络设计方法用于图像混合任务。由一个可学习表达模型指导,网络架构的设计有了清晰的目标;
- 提出可学习表达模型用于图像分解,产生轻量化的混合多模态图像网络;
- 提出a detail-to-semantic information loss function,包括了4种级别的损失,pixel level, shallow level, middle feature level, deep feature level;
- 实验结果表明提出的方法比SOTA混合方法效果更好。


4. GRM: Generalized relation modeling for transformer tracking
摘要:相比于之前的双流跟踪器,最近的单流跟踪pipeline,允许模板和搜索区域更早的交互同时实现了显著的性能提升。但是现存的单流跟踪器通过所有的解码层总是允许模板和搜索区域内所有部分交互,可能使得当提取的特征表达不是特别显著时,目标-背景会发生混乱。
为了解决这个问题,提出了一个基于自适应token划分的泛化关系建模方法。所提方法时基于注意力建模的泛化模式,继承了双流和单流pipeline的优点并通过选择合适的搜索tokens和模板tokens交互进行更灵活的关系建模。引入注意力掩码策略和Gumbel-Softmax技术促进token划分模块的端到端学习和并行计算。
实验结果表明本方法比双流和单流pipeline更好在6个数据集上,实时运行速度。
Contribution:
- 展示了一个用于Transformer跟踪器关系建模的范式,将输入tokens分为3类,使模板和搜索区域交互更灵活;
- 为了实现泛化关系建模,设计了一个token划分模块以自适应分类输入tokens。引入注意力掩码策略和Gumbel-Softmax技术促进token划分模块的端到端学习和并行计算;
- 进行了大量的实验和分析验证了本文方法的有效性。


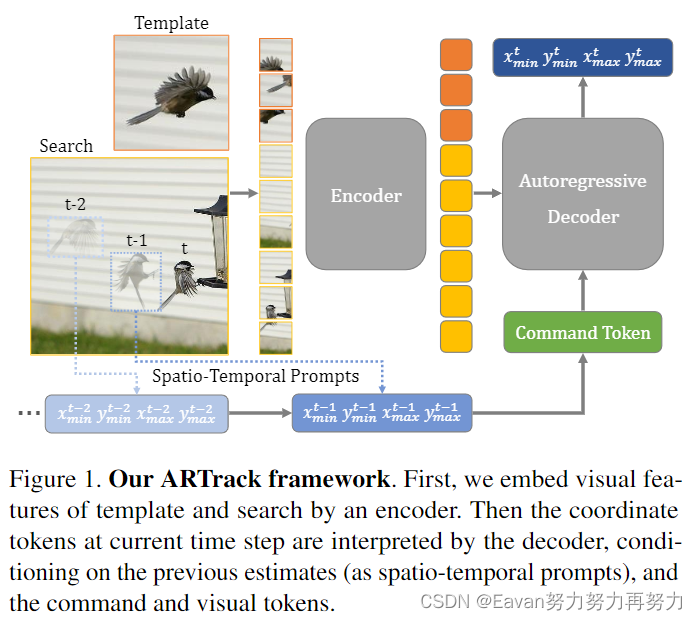
5. ARTrack: Autoregressive Visual Tracking
摘要:展示了ARTrack,一个用于视觉目标跟踪的自回归框架。ARTrack将跟踪问题看作逐步估计对象轨迹的坐标序列解释任务,其中当前估计由先前的状态引起并反过来影响子序列。这种时间自回归方法对轨迹的顺序演变(sequential evolution)进行建模,以保持跨帧跟踪对象,使其优于仅考虑每帧定位精度的现有基于模板匹配的跟踪器。
ARTrack简单且直接,消除了特有的定位头和后处理过程。 尽管ARTrack很简单,但其在流行的基准数据集上实现了最先进的性能。
(引入时序信息很常见的思想,但通过spatio-temporal prompts引入比较新~)

6. SparseTT: Visual Tracking with Sparse Transformers
摘要:Transformers已经成功应用于视觉跟踪任务并显著提升了跟踪的性能。自注意力机制是Transformers成功的关键,其建模了long-range依赖关系。然而,自注意力缺乏关注搜索区域中最相关的信息,易于被背景干扰。
为了解决该问题,本人通过聚焦搜索区域中最相关的信息 提出sparse attention mechanism。进一步,引入双头预测器double-head predictor以提升前背景分类精度和边界框的回归精度,其进一步提升了跟踪性能。
大量的实验展示,本文以40FPS的速度运行,并显著提升了跟踪效果在LaSOT, GOT-10k, TrackingNet, UAV123上。
Contribution:
- 提出了一个目标关注网络,聚焦于搜索区域中感兴趣的区域并强调最相关的信息特征以更好地估计目标状态;
- 提出了一个sparse Transformer based siamese tracking framework,有强大的能力处理目标形变,部分遮挡,尺度变换等问题;
- 大量实验展示本文以40FPS运行并在LaSOT, GOT-10k, TrackingNet, UAV123上表现良好。


7. Toward Robust Visual Object Tracking with Independent Target-Agnostic Detection and Effective Siamese Cross-Task Interaction
通过独立的目标不可知检测和有效的 Siamese 跨任务交互实现稳健的视觉对象跟踪
TIP,2023
摘要:Siamese 视觉目标跟踪架构使用成对输入图像进行联合训练,以执行目标分类和边界框回归,他们已经实现了不错的效果。但是,现存的方法有2大缺陷:1. 尽管Siamese结构能在每个实例帧内估计目标状态,但前提是目标外观不会偏离模板太多,在存在严重外观变化的情况下无法保证检测结果。2. 尽管分类和回归任务共享了backbone的输出,但他们特有的模块和损失函数都是独立设计的,没有任何交互,但是在一个跟踪任务中,中心分类和边界框回归任务协同工作以估计最终目标位置。
为了解决以上问题,实施目标不可知检测是非常重要的以提升在Siamese-based tracking中的跨任务交互。本文提出了一个具有目标不可知对象检测模块的新型网络,以补充direct target inference,并避免或最小化潜在template-instance matches的关键线索的错位。为了统一多任务学习范式,提出了一个跨任务交互模块确保分类和回归分支的一致监督,提高不同分支的协同作用。为了消除多任务架构中可能出现的潜在不一致,我们分配自适应标签,而不是固定的硬标签,以更有效地监督网络训练。
实现结果证明在OTB100, UAV123, VOT2018, VOT2019,LaSOT上证明了提出的目标检测模块和跨任务交互模型的先进性。


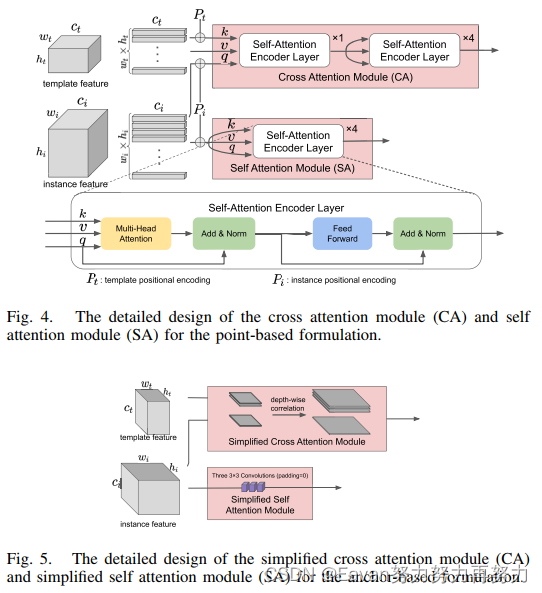

8. BeamTracking:Beyond Greedy Search: Tracking by Multi-agent Reinforcement learning-based beam search
超越贪婪搜索:基于多代理强化学习的波束搜索进行跟踪
TIP
摘要:常见的跟踪器往往采用贪婪搜索在每一帧中定位目标,即,具有最大响应值的候选区域被选择跟踪结果。但是,作者发现这可能不是最优选择,特别是在一些严重遮挡/快速移动的复杂场景中。具体地,如何一个跟踪器发生了漂移,误差将会累计并使得未来帧中的响应分数都不可靠。
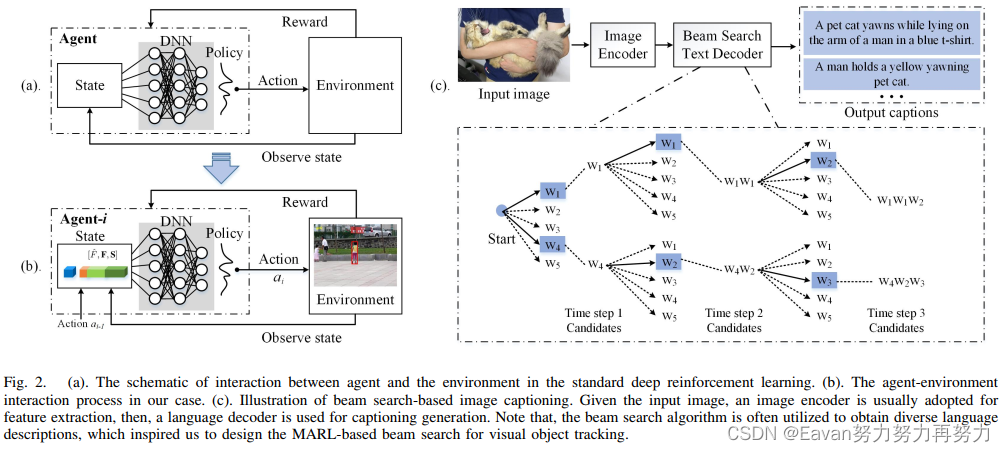
为了解决该问题,本文提出维持多个跟踪轨迹并应用beam搜索策略进行跟踪,使得拥有更少累积误差的轨迹被识别。本文引入了基于beam搜索的多智能体强化学习跟踪策略,称为BeamTracking。受到图像字幕任务的启发,其将一张图像作为输入并利用beam搜索算法生成各种各样的描述,所以本文将跟踪任务建模为由多个并行决策过程完成的样本选择问题,每个决策过程都挑选一个样本作为它们在每一帧中的跟踪结果。每个轨迹都与一个智能体相关联,以执行决策并确定应该采取什么行动来更新相关信息。此外,使用基于分类的跟踪器作为baseline,先采用 bi-GRU 将target feature, proposal feature, response score编码为统一的状态表示,然后将状态特征和贪心搜索结果输入第一个智能体进行独立的动作选择。 之后,输出的动作和状态特征被馈送到后续的代理中进行不同的结果预测。 当处理完所有帧后,选择具有最大累积分数的轨迹作为跟踪结果。
在7个数据集山证明了本文方法的有效性。
Contribution:
- 将视觉目标跟踪任务建模为样本选择问题可以使用多个平行的马尔可夫决策过程解决。提出了一个多智能体学习框架完成顺序决策问题。
- 将MARL beam搜索策略嵌入多个跟踪器并在多个流行的跟踪数据集上执行实验,实验充分验证了提出方法的有效性和通用性。

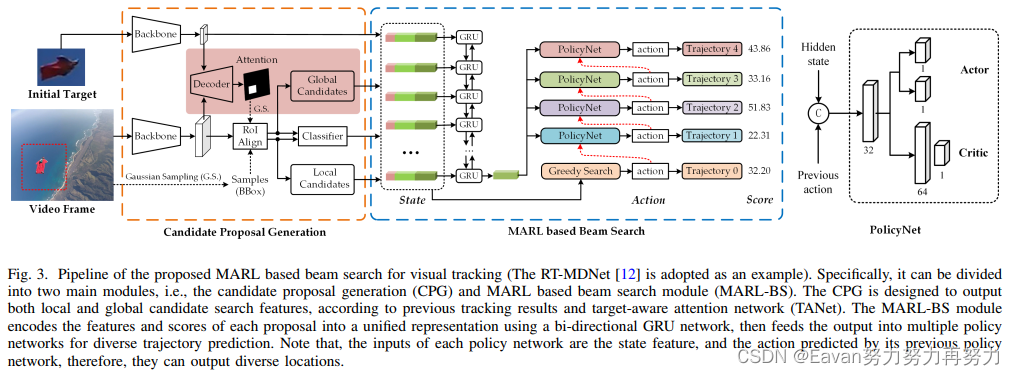
9. RGBD1K: A large-scale dataset and benchmark for RGB-D object tracking
摘要:RGB-D 目标跟踪最近已经引起了许多关注,并由于视觉通道和深度通道之间的共生性实现了很好的性能。然而,只有少量的有标注的RGB-D跟踪数据,大部分SOTA的RGB-D跟踪器只是RGB跟踪器的简单扩展,没有在离线训练阶段充分探索深度通道的潜力。
为了解决数据集低效的问题,本文提出了一个新的RGB-D数据集称为RGBD1K,共包含1050个序列和2.5M帧。为了展示在更大的 RGB-D 数据集(尤其是 RGBD1K)上训练的优势,我们开发了一个基于Transformer的 RGB-D 跟踪器,SPT,作为未来使用新数据集进行视觉对象跟踪研究的baseline。大量实验展示SPT提升RGB-D跟踪的可能性。


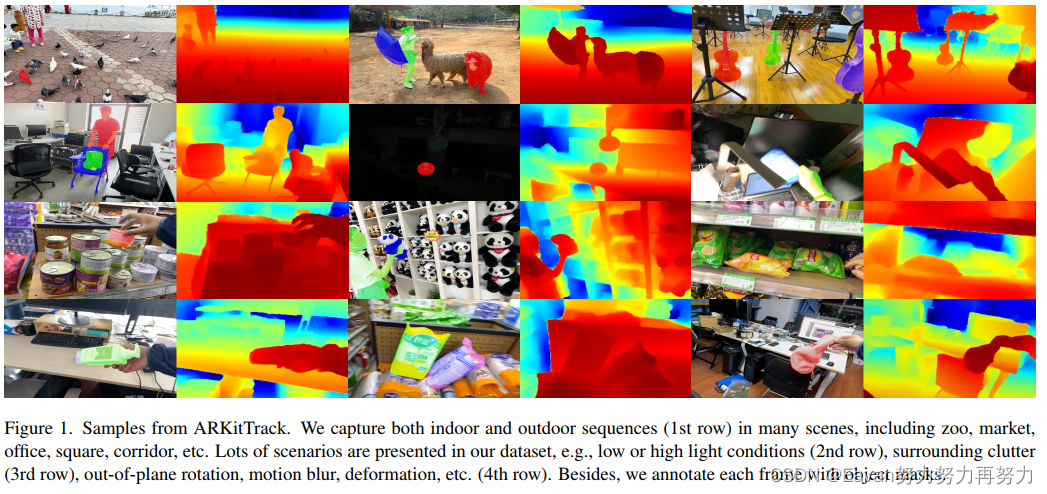
10. ARKitTrack: A new diverse dataset for tracking using mobile RGB-D Data
摘要:相比传统的RGB-only跟踪,几乎没有数据集用于RGB-D跟踪。
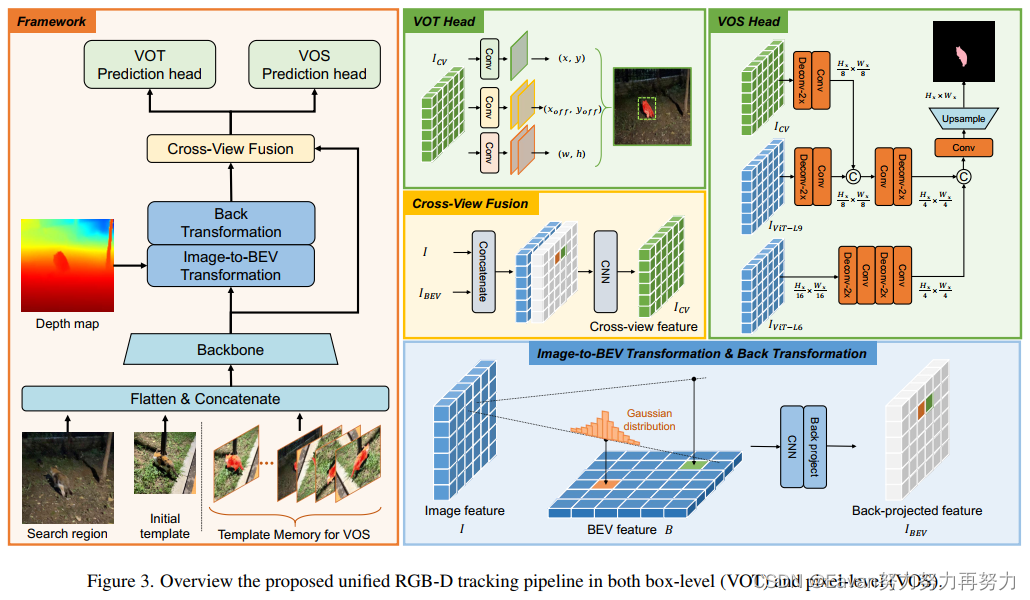
本文提出了ARKitTrack,一个新的 RGB-D 跟踪数据集,使用iPhone和iPad上配备的LiDAR 扫描仪捕获静态和动态场景。ARKitTrack包括300个RGB-D序列,455个目标和229.7K视频帧。除了边界框注释和帧级别的属性外,也用了123.9K 像素级别的目标掩码进行标注。此外,每一帧中相机位姿和属性也提供了。为了验证该数据集的潜在用途,进一步为框级和像素级跟踪提供了一个统一的baseline,将 RGB 特征与鸟瞰图表示相结合,以更好地探索跨模态3D几何。
深入的实验表明ARKitTrack数据集能够显著促进RGB-D跟踪的发展。
Contribution:
- 新的RGB-D跟踪数据集,包含各种静态和动态的场景,以及框级别和像素级别的精准注释;
- 一个统一的baseline方法用于RGB-D视频目标跟踪和目标分割,结合RGB和3D形态用于有效的RGB-D跟踪;
- 深度的评估和分析为促进 RGB-D 跟踪的未来研究提供新知识。