2023.6.8-TS-yum update集群后奔溃故障(已解决)

1、故障背景
自己在安装falco软件时,使用yum update升级了系统后,就出现这个情况了。。。
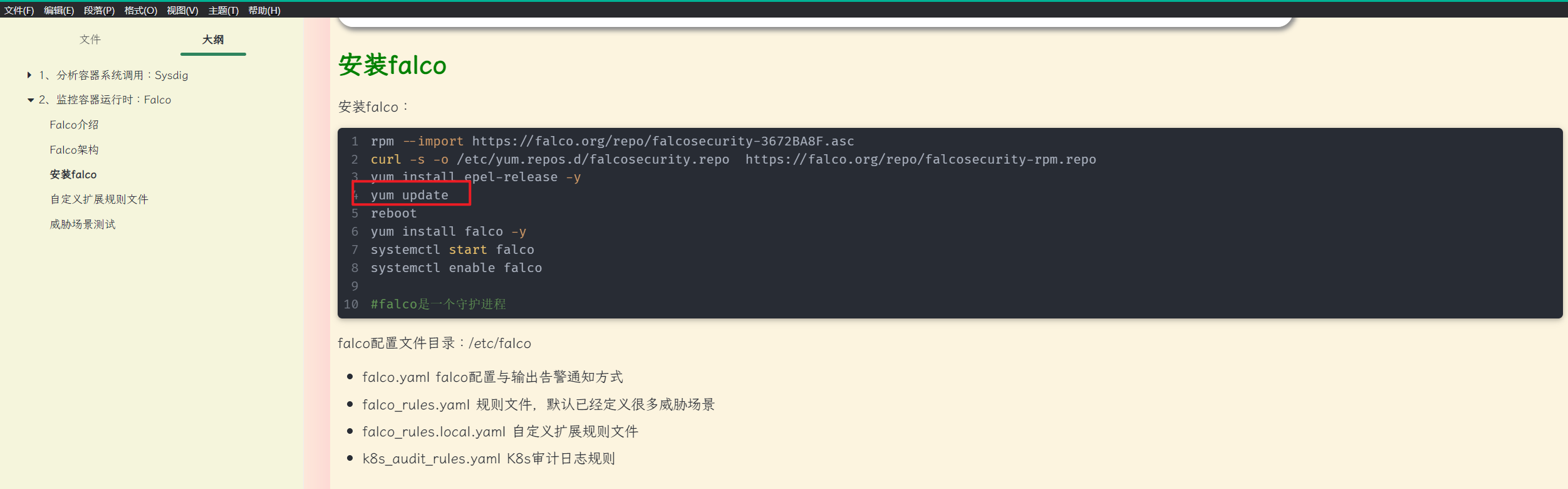
2、报错现象
kubeclt无法查看pod
kubectl get po
E0608 09:38:49.094714 2268 memcache.go:265] couldn't get current server API group list: Get "https://172.29.9.31:6443/api?timeout=32s": dial tcp 172.29.9.31:6443: connect: connection refused

kubelt报错日志
[root@k8s-master1 manifests]#journalctl -xefu kubelet
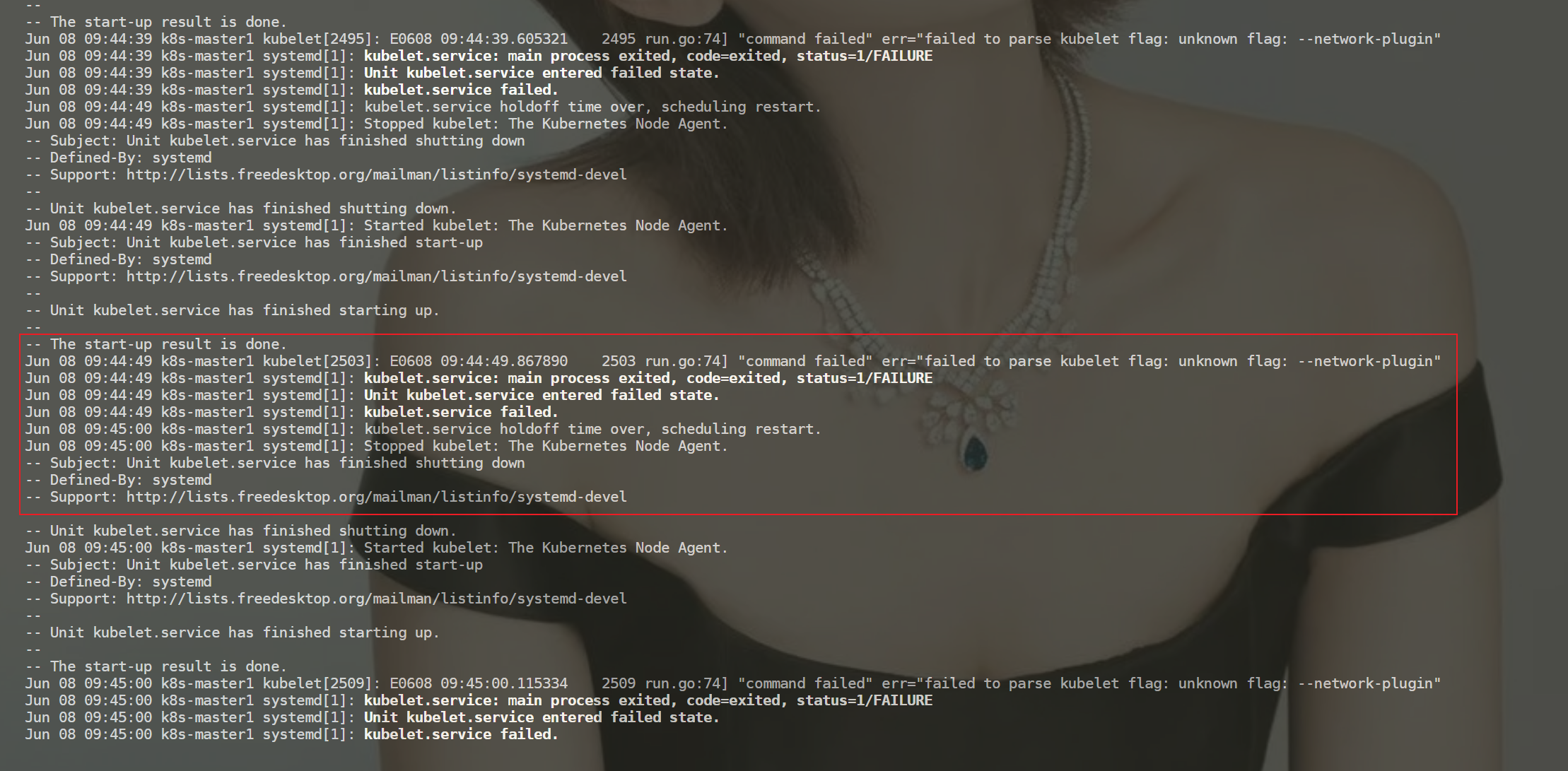
kubelet状态:dead
[root@k8s-master1 manifests]#systemctl status kubelet

查看基础环境
查看selinux关闭的,swap分区也是关闭的,防火墙关闭的,运行的容器为空
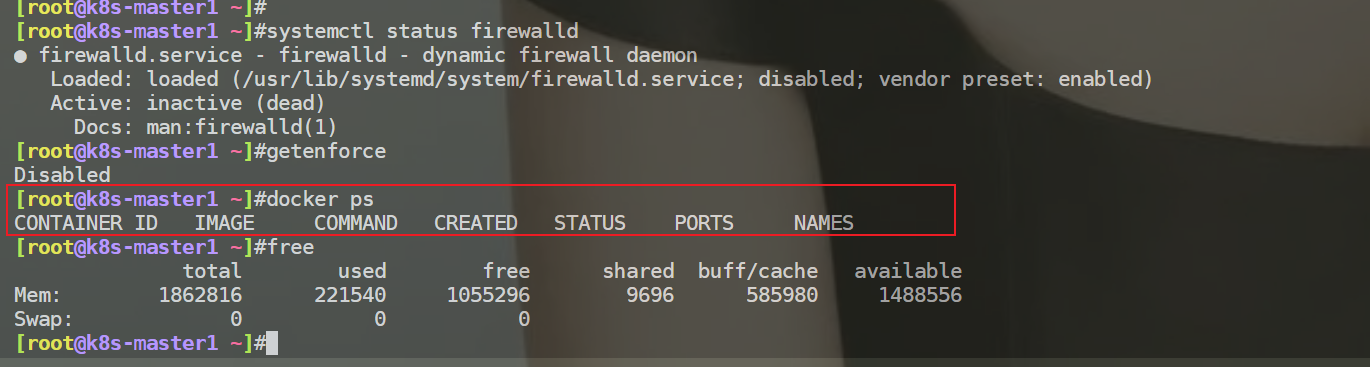
找到问题
经过关键字查找,发现是更新之后k8s自动升级到了1.26版本,由于1.21版本之后弃用docker所以导致集群不可用
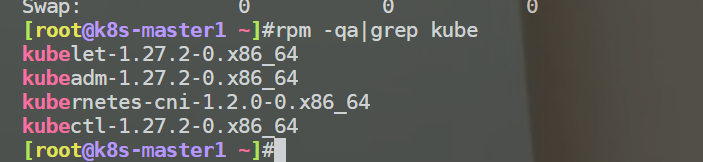
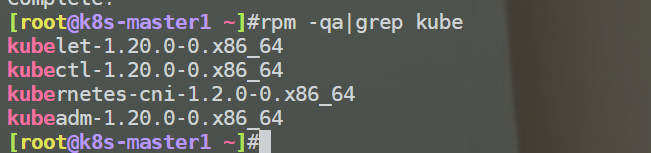
自己之前k8s版本:


[root@k8s-node1 ~]#rpm -qa|grep kubectl
kubectl-1.20.0-0.x86_64
[root@k8s-node1 ~]#rpm -qa|grep kubeadm
kubeadm-1.20.0-0.x86_64
[root@k8s-node1 ~]#rpm -qa|grep kubelet
kubelet-1.20.0-0.x86_64
[root@k8s-node1 ~]#
3、解决过程
重启集群(失败)
百度:降级安装k8s版本(成功)
将集群中所有节点降级(这里只操作k8s-master1节点),把k8s相关服务降级到1.20版本,虽然官方说明1.21之后弃用docker但是,1.20还是可用的
此处为测试环境,生产环境建议严格按照官方要求
yum downgrade kubectl-1.20.0-0.x86_64 \
kubeadm-1.20.0-0.x86_64 \
kubelet-1.20.0-0.x86_64
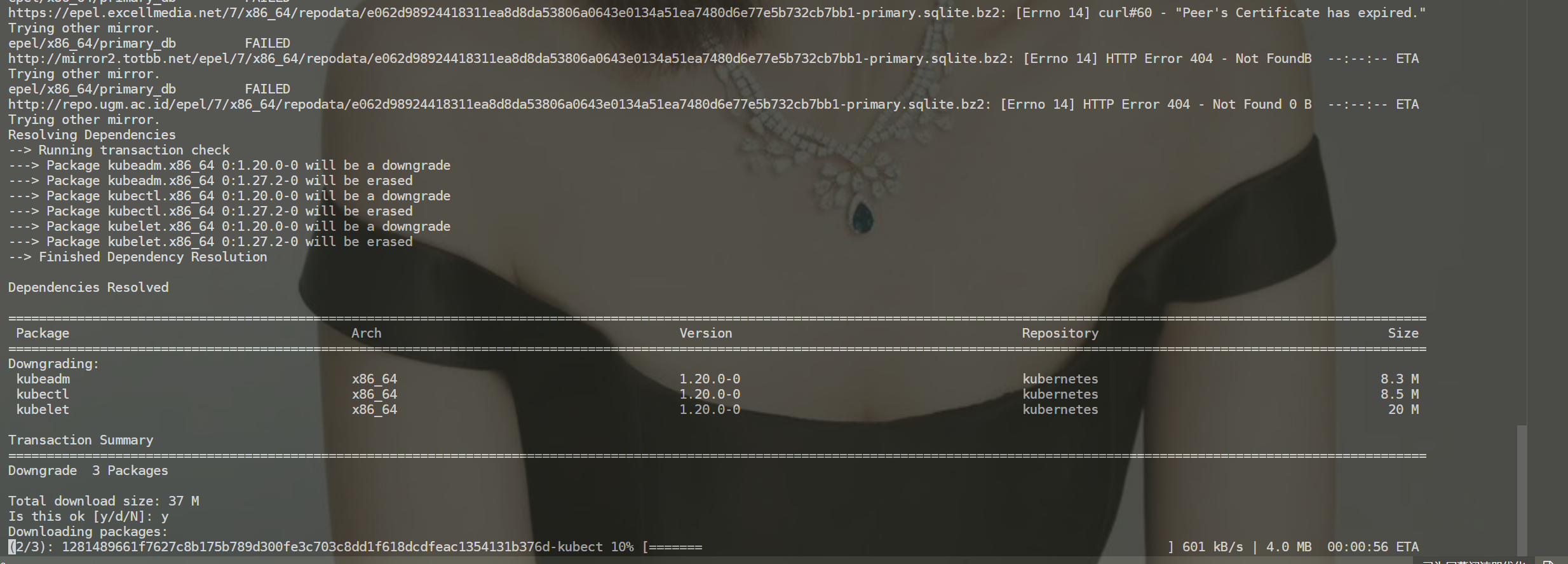
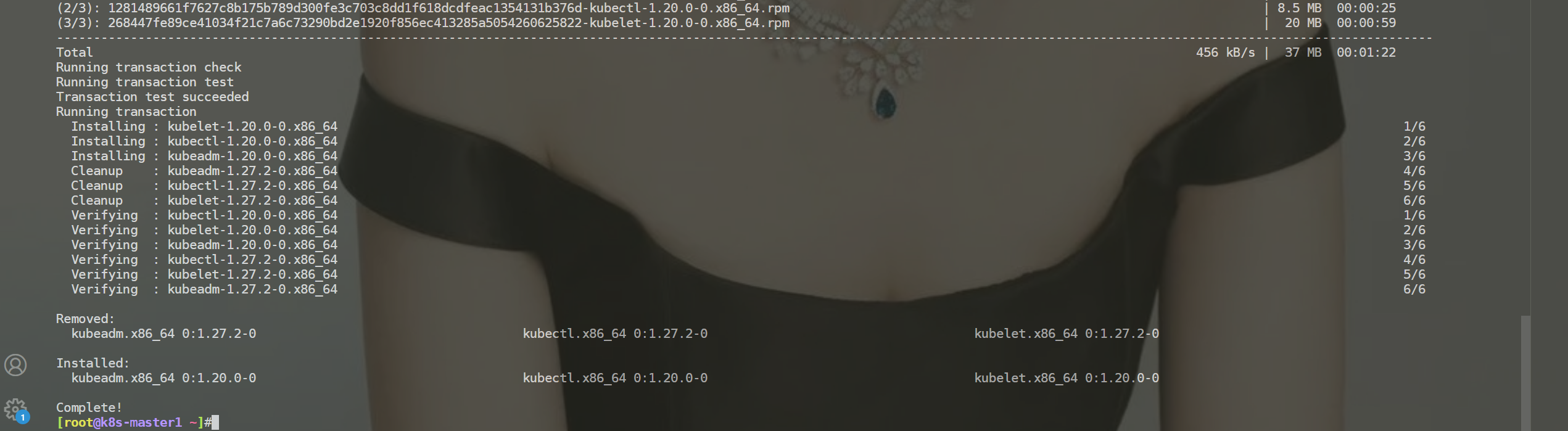
- 重载服务,查看服务状态
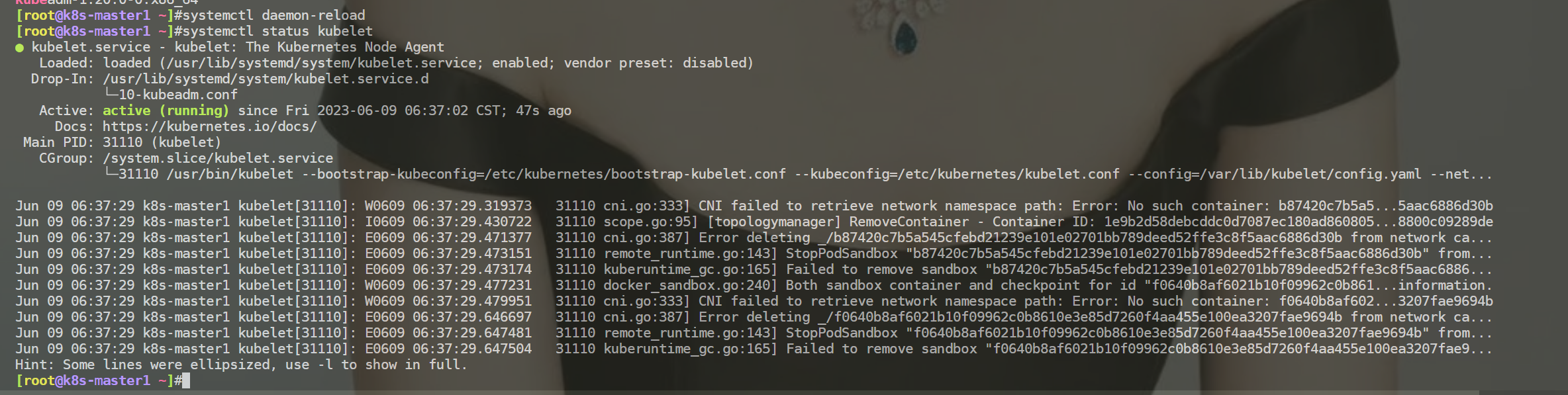
- 安装完成后,经查询集群已全部恢复正常
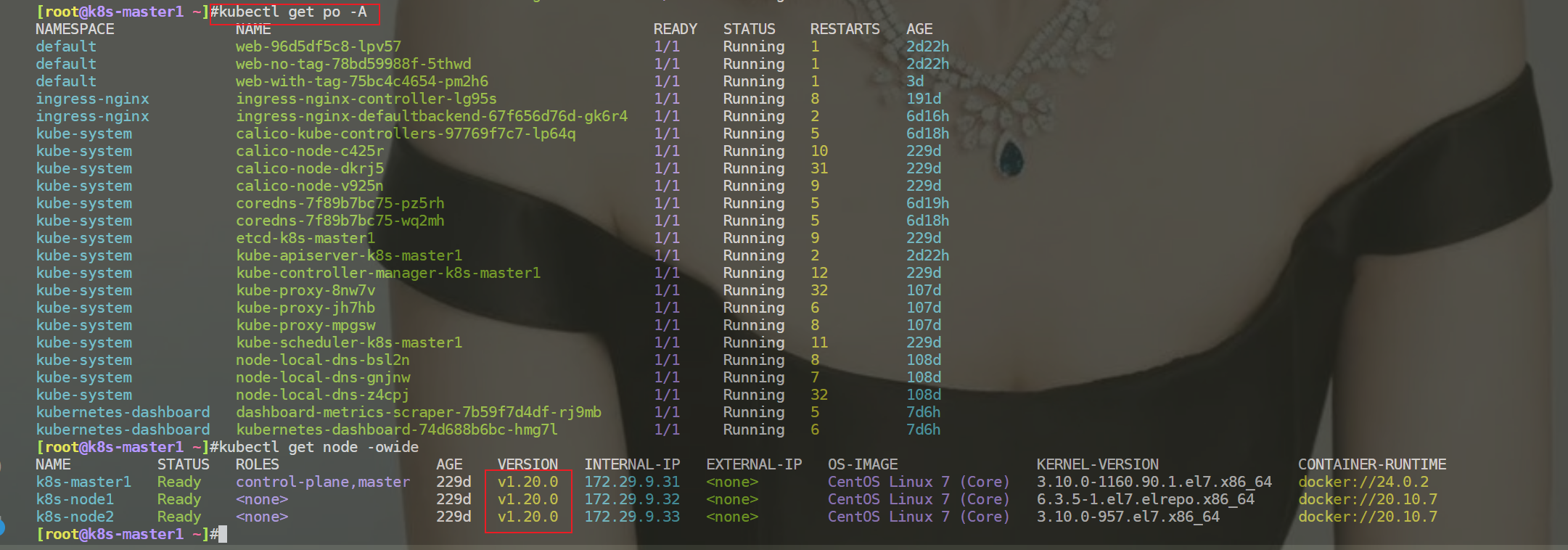
- 重启k8s集群,再次观察现象
重启后,k8s集群依然是可以使用的。
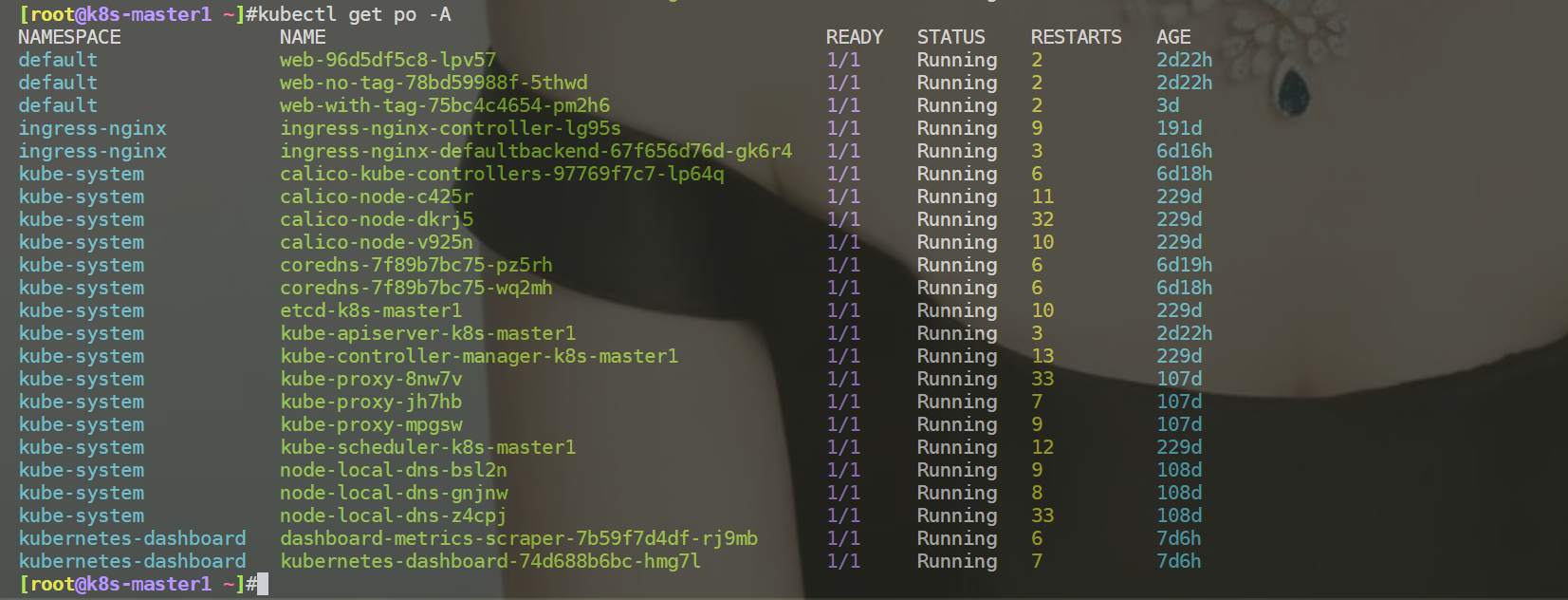
此问题已解决。
附加:
- 这里也降级下k8s-master1节点的docker版本
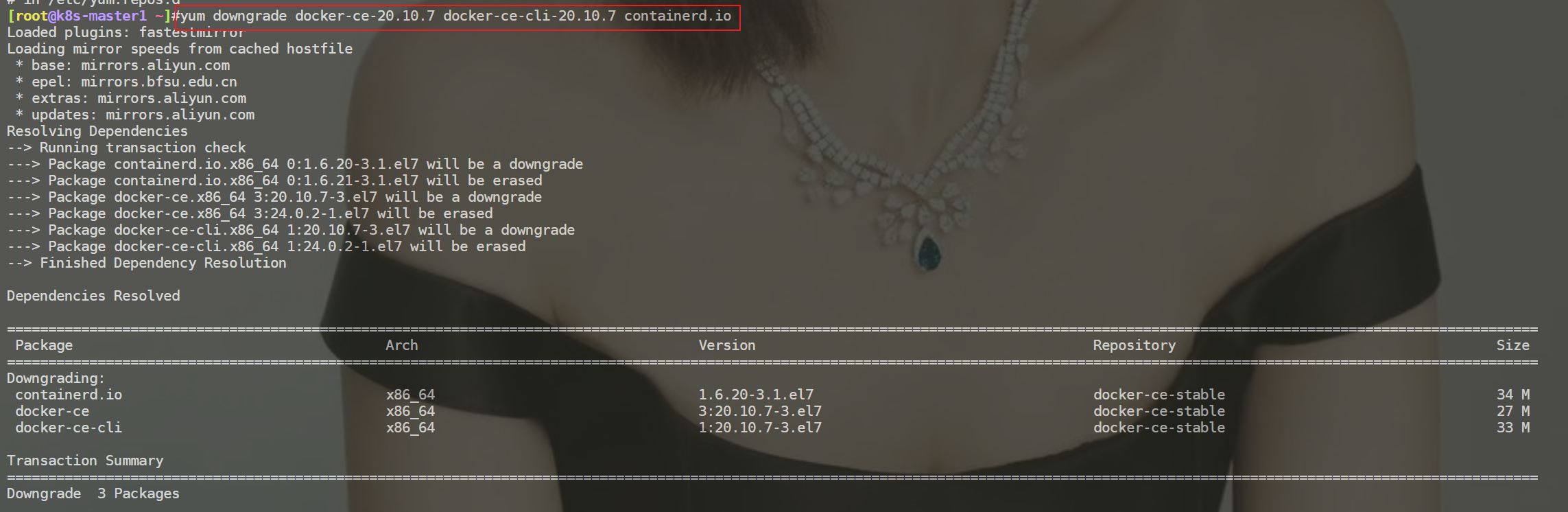
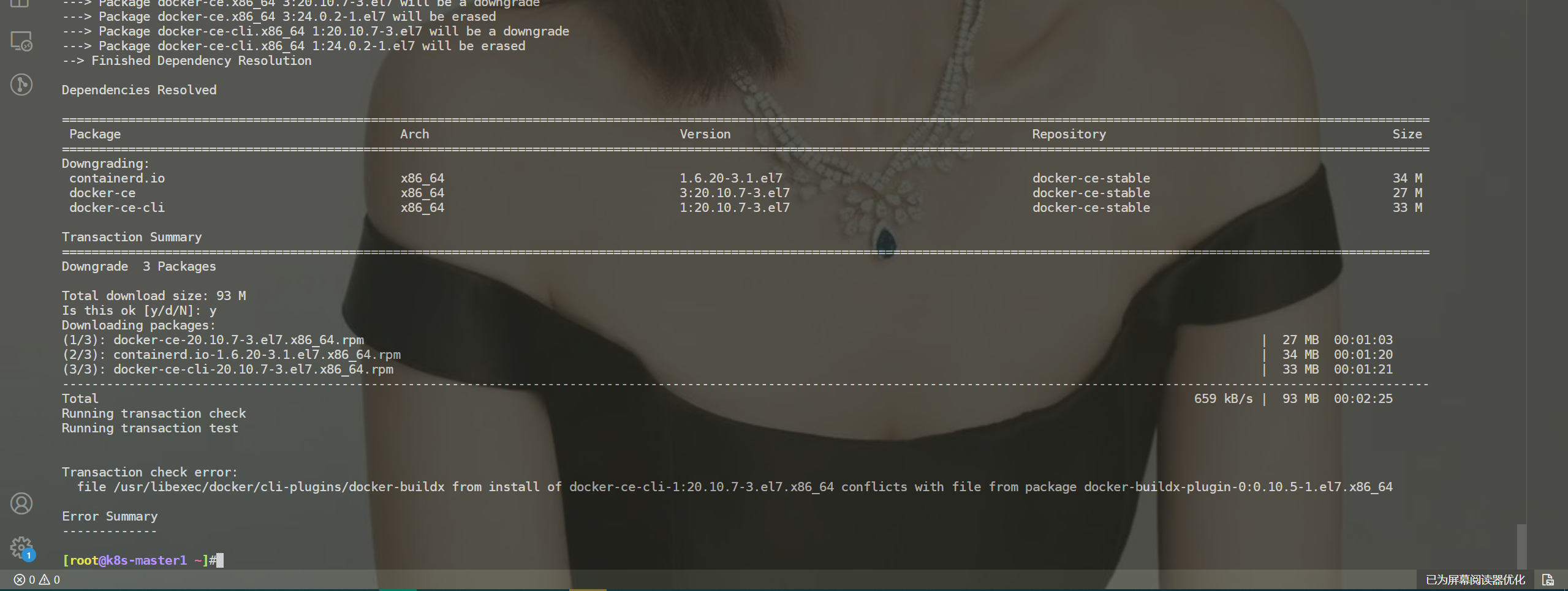
但是在使用降级命令时,报错了,关闭docker服务时,还是报错了。
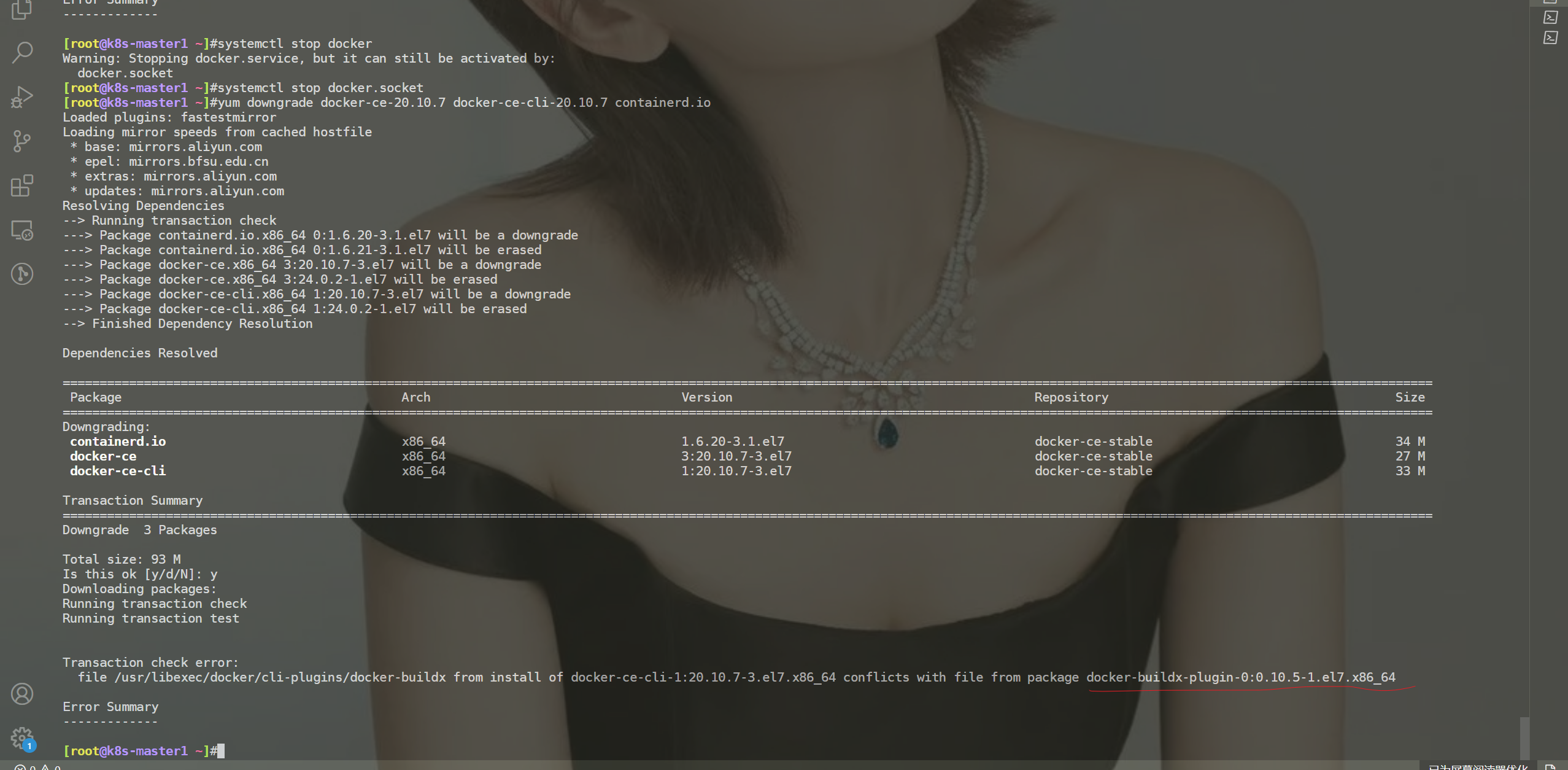
最后,只能先卸载当前版本docker,再重新安装老版本docker:
yum remove -y dockerce*
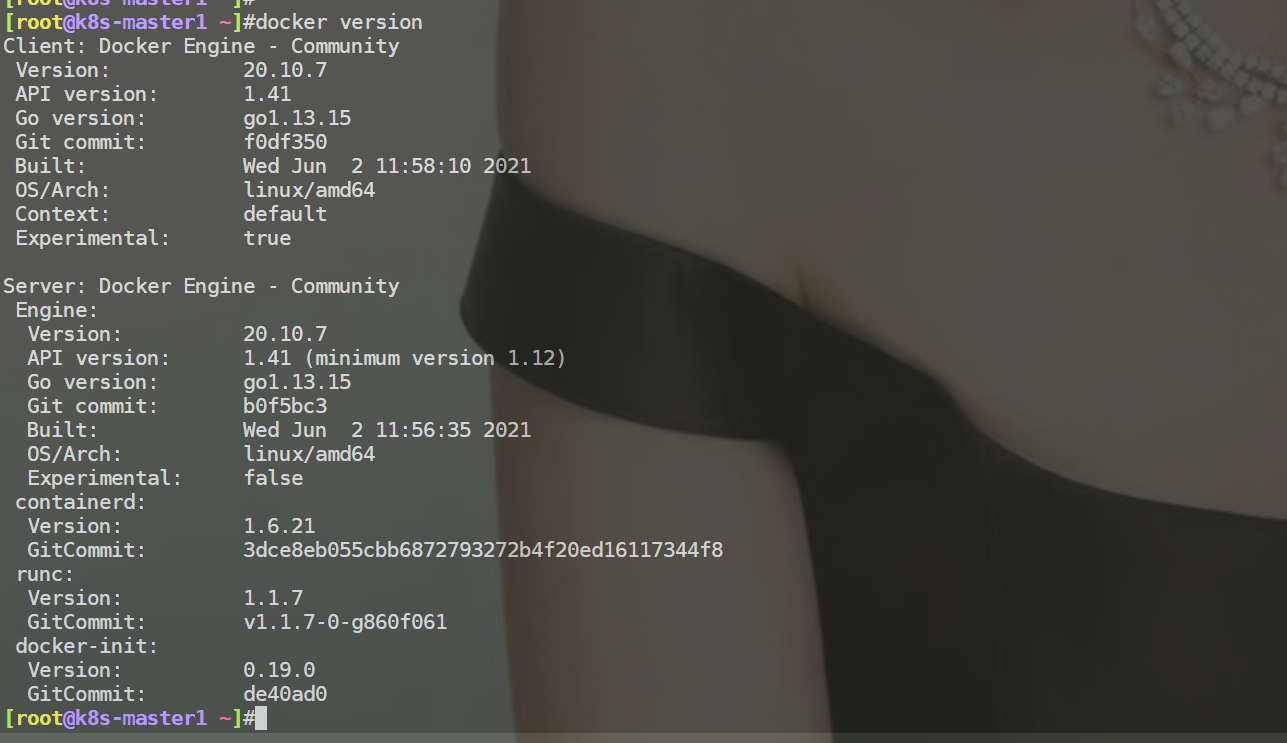
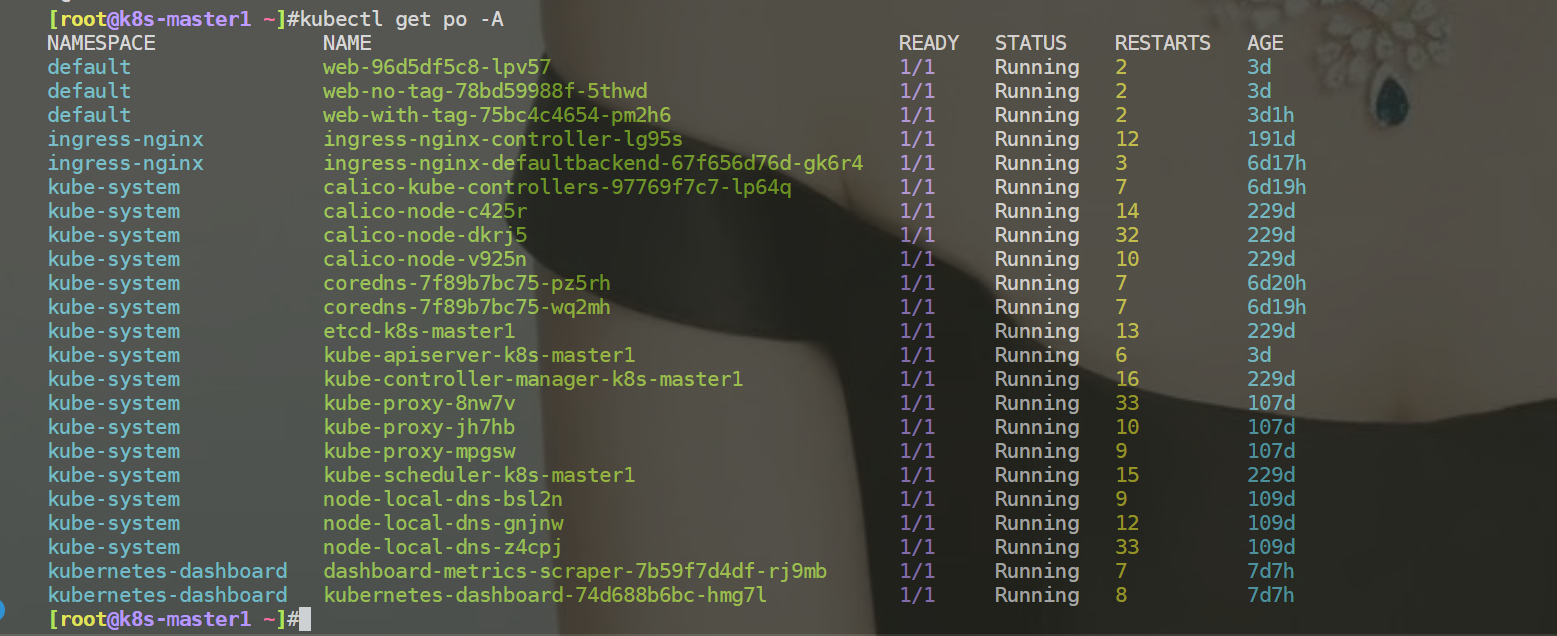
测试,发现都是ok的:

4、参考文章
https://www.xxapp.net/22171.html
5、总结
这幸好只是测试集群,可以进行随意测试,生产环境里特别要注意禁止使用yum update/upgrade命令!!!