1 安装conda
2 创建环境 conda activate --name wenda python=3.8
3 安装依赖工具包
pip install -r requirements/requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch BeautifulSoup4 torchvision torchaudio pdfminer.six -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -r requirements/requirements-chatglm_api.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -r requirements/requirements-glm6b-lora.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -r requirements/requirements-gpt4free.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -r requirements/requirements-llama.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -r requirements/requirements-openai.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -r requirements/requirements-qdrant.txt -i https://pypi.tuna.tsinghua.edu.cn/simple4 下载模型
语言模型是chatGLM-6B,大家也可以使用其他的基础模型
链接:百度网盘 请输入提取码 提取码:xt9l
放在 /home/user/wenda/model下
文本向量模型text2vec-large-chinese
cd /home/user/data/wenda/model
# 安装 git lfs
git lfs install
# 如果报错 git: 'lfs' is not a git command.
# 执行如下(Ubuntu):
sudo apt-get install git-lfs
# 从huggingface官网拉取模型指针文件
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
# 下载模型
wget https://huggingface.co/GanymedeNil/text2vec-large-chinese/resolve/main/pytorch_model.bin
# 覆盖text2vec-large-chinese中的 pytorch_model.bin文件
mv pytorch_model.bin text2vec-large-chinese/
5修改配置
example.config.yml改名为config.yml
library:
strategy: "sogowx:3 bingsite:2 rtst:2 agents:0"
#知识库参数,每组参数间用空格分隔,冒号前为知识库类型,后为抽取数量。
#知识库类型:
#bing cn.bing搜索,仅国内可用,目前处于服务降级状态
#sosowx sogo微信公众号搜索,可配合相应auto实现全文内容分析
#fess fess搜索引擎
#rtst 支持实时生成的sentence_transformers
#remote 调用远程闻达知识库,用于集群化部署
#kg 知识图谱,暂未启用
#特殊库:
#mix 根据参数进行多知识库融合
#agents 提供网络资源代理,没有知识库查找功能,所以数量为0
# (目前stable-diffusion的auto脚本需要使用其中功能,同时需开启stable-diffusion的api功能)
#fess模式下改为strategy: "fess:2" 2为抽取数量
show_soucre: true
#知识库显示来源
glm6b:
path: "model/chatglm-6b-int4"
#glm模型位置"
strategy: "cuda:1 fp16 *14 -> cuda:2"
#cuda fp16 所有glm模型 要直接跑在gpu上都可以使用这个参数
#cuda fp16i8 fp16原生模型 要自行量化为int8跑在gpu上可以使用这个参数
#cuda fp16i4 fp16原生模型 要自行量化为int4跑在gpu上可以使用这个参数
#cuda:0 fp16 *14 -> cuda:1 fp16 多卡流水线并行,使用方法参考RWKV的strategy介绍。总层数28
#strategy: "cuda:1 fp16 *14 -> cuda:2"可多卡并行
6 创建知识库
创建txt文件夹
cd /home/user/wenda/
mkdir txt
7 安装fess
先安装jdk
## linux系统
1. 安装JDK
```
wget https://download.java.net/java/17/latest/jdk-17_linux-x64_bin.tar.gz
sudo tar xvf jdk-17_linux-x64_bin.tar.gz -C /usr/local/
```
解压后,JDK 17 将被安装在 /usr/local/jdk-17 目录中。
配置环境变量。要在系统中使用 JDK 17,您需要将其添加到 PATH 环境变量中。您可以使用以下命令将其添加到 /etc/profile 文件中:
```
rm -f /etc/alternatives/java
ln -s /usr/local/jdk-17.0.6/bin/java /etc/alternatives/java
echo export JAVA_HOME=/usr/local/jdk-17.0.6 >>/etc/profile
echo export PATH='$PATH':'$JAVA_HOME'/bin >>/etc/profile
echo export CLASSPATH=.:'$JAVA_HOME'/lib/dt.jar:'$JAVA_HOME'/lib/tools.jar >>/etc/profile
source /etc/profile
```
确认安装。您可以使用以下命令检查 JDK 17 是否已成功安装:
```
java -version
```
如果一切正常,您应该会看到类似以下内容的输出:
openjdk version "17.0.1" 2021-10-19
OpenJDK Runtime Environment (build 17.0.1+12-39)
OpenJDK 64-Bit Server VM (build 17.0.1+12-39, mixed mode, sharing)安装fess
2. 安装fess14.7.0
下载fess
解压fess
```
unzip fess-14.7.0.zip
cd bin
./fess -d
```将知识库/home/user/wenda/txt添加到fess中
在crawler选的file system创建新的 name,输入名称和位置/home/user/wenda/txt
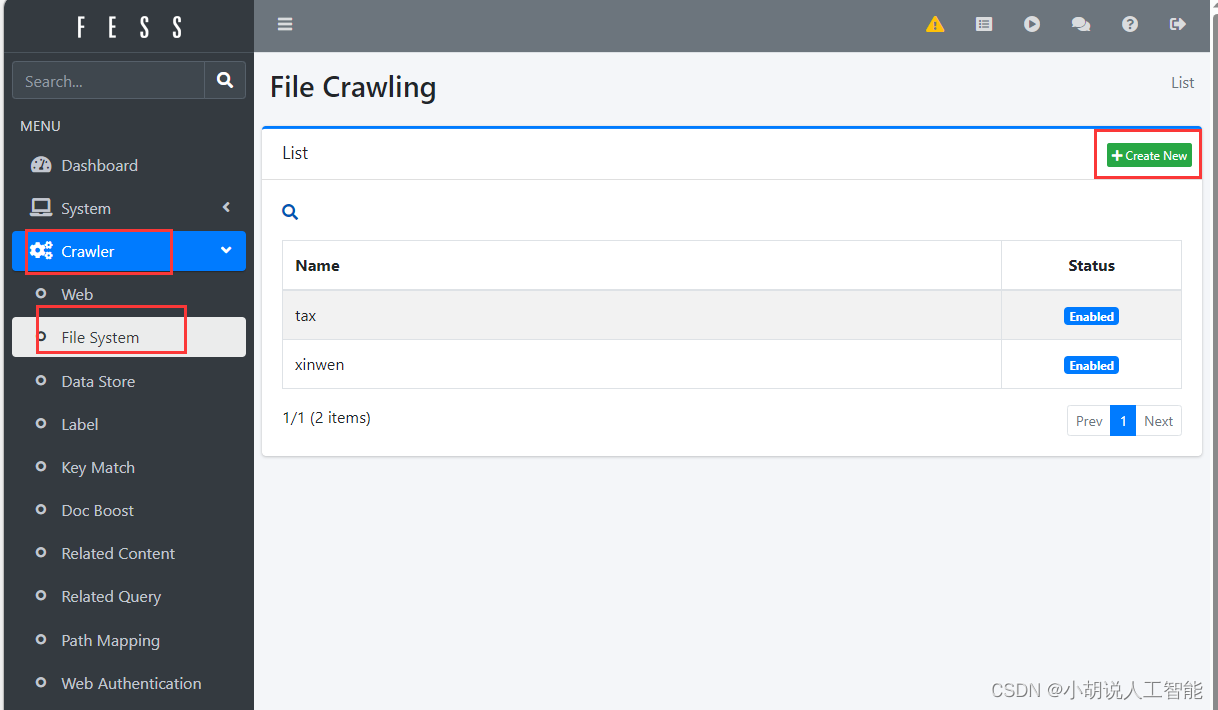
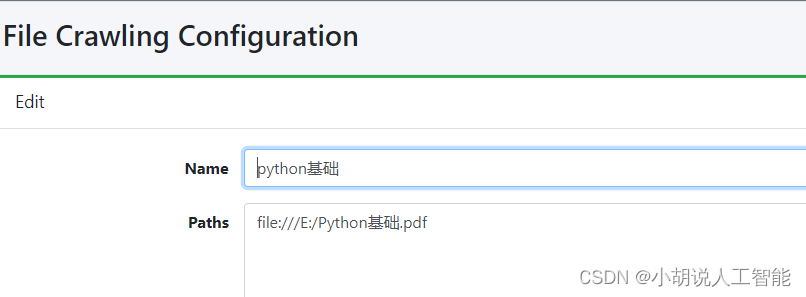
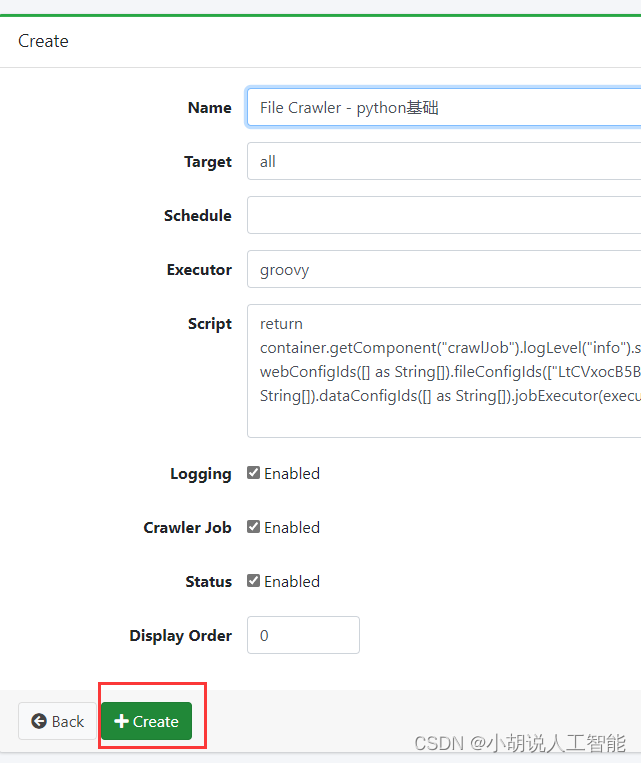
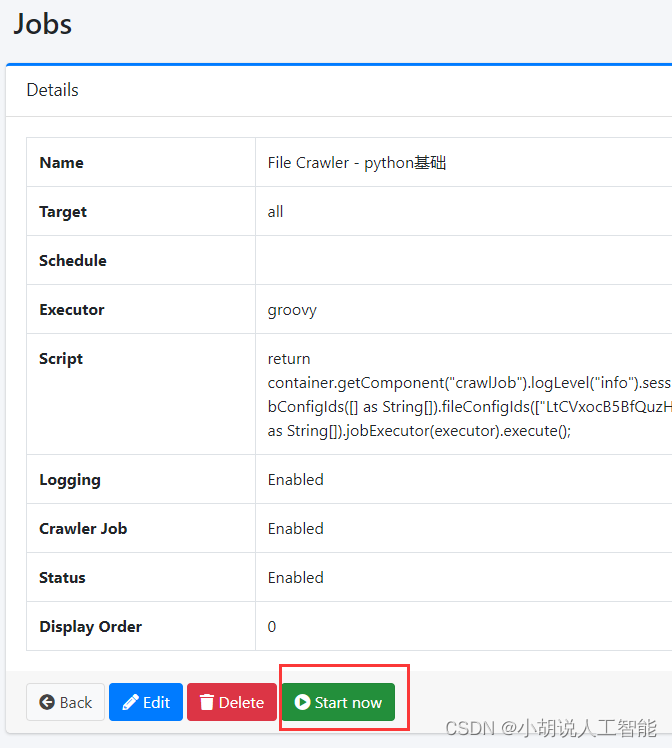
自动返回File System页面. 点击刚才创建的选项(自己输入的Name),新建job
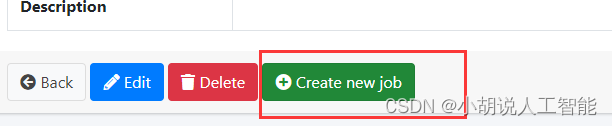
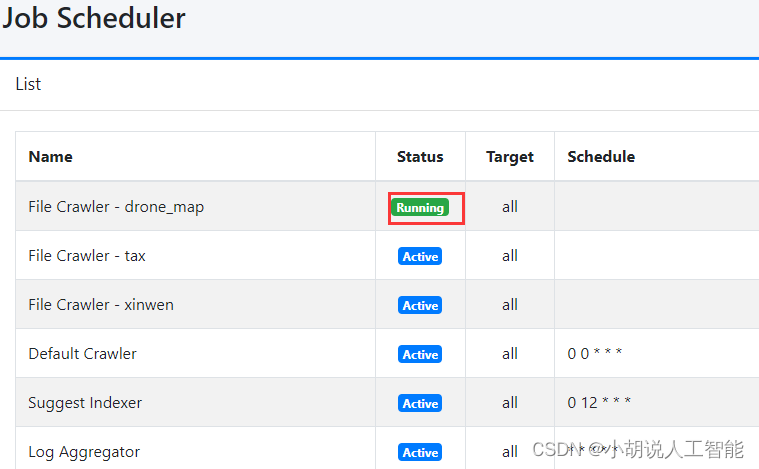
进入侧边栏的System内的Scheduler. 可以看到很多任务
- 目录的前面可以看到刚刚创建的job.点击进入
- 点击Start now. 刷新界面即可看到该任务正在运行. running
fess网址http://127.0.0.1:8080/
wenda网址http://127.0.0.1wenda网址