0. 简介
在真实的SLAM场景中,我们会发现在遇到大量动态障碍物的场景时候,特别容易造成跟丢的问题。传统的解决方法是通过将动态障碍物滤除,而本文《RigidFusion: Robot Localisation and Mapping in Environments with Large Dynamic Rigid Objects》中提到将动态物体看做刚体进行跟踪。虽然这篇文章创新点并不是很足,但是研究现状总结的很好。目前这篇文章的代码没有开源,但是有视频讲解。文中提出一种新的RGB-D SLAM方法,可以同时分割、跟踪和重建静态背景和可能遮挡相机视野主要部分的大型动态刚性物体。之前的方法将场景的动态部分视为异常值,因此局限于场景中的少量变化,或依赖场景中所有对象的先验信息,以实现鲁棒的摄像机跟踪。本文提出将所有动态部件视为一个刚体,同时分割和跟踪静态和动态部件。因此,在动态对象造成大遮挡的环境中,能够同时定位和重建静态背景和刚性动态组件。
RigidFusion: Robot Localisation and Mapping inEnvironments with Large Dynamic Ri
1. 文章贡献
在无人仓库中搬运和运输物体这些任务需要机器人的移动操作,要求机器人在移动的静态环境中定位,同时对动态物体的干扰具有鲁棒性,并跟踪他们需要操纵的物体。虽然这两个问题之前被单独解决。但是同时解决这两个任务是很少的。

-
一个新的SLAM框架,使用RGB-D摄像头,在整个SLAM框架中同时分割、跟踪和重建场景,通过具有潜在漂移的运动先验来完成静态背景和一个动态刚体的构建。
-
使用稠密SLAM建图的方法,对视觉输入中的大型动态遮挡(超过视野的65%)具有鲁棒性。同时该SLAM模型不依赖静态和动态模型的初始化;
-
提供一个新的RGB-D SLAM数据集,数据集中包括具有在场景中造成大遮挡的动态对象和真实轨迹。
2. 详细内容
本文提出一种SLAM框架,将动态部件视为单个刚体,利用运动先验分割静态部件和动态部件。利用分割后的图像对摄像机进行跟踪,重建背景和目标模型。
下图展示了该方法的重建流程,首先需要连续两个RGBD关键帧A和B,以及静态和动态物体的先验信息,静态和动态物体的先验信息即为
ξ
~
s
\tilde{ξ}_s
ξ~s和
ξ
~
d
\tilde{ξ}_d
ξ~d是属于
s
e
(
3
)
se(3)
se(3)的,此外还需要前一帧的语义分割信息
Γ
~
A
∈
R
w
×
h
\tilde{\Gamma}_A\in \mathbb{R}^{w\times h}
Γ~A∈Rw×h。首先根据运动先验信息检测物体是否为动态物体;然后,当物体运动时,基于帧间对齐,我们联合估计分割
Γ
~
B
\tilde{\Gamma}_B
Γ~B和刚体运动
ξ
~
s
\tilde{ξ}_s
ξ~s和
ξ
~
d
\tilde{ξ}_d
ξ~d。这些片段用于重建静态环境和动态对象,并利用帧与模型的对齐实现摄像机的定位。
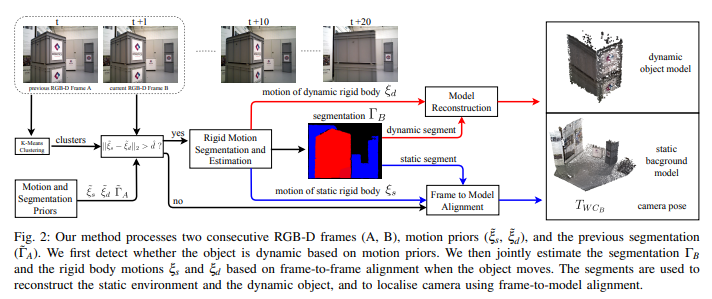
2.1 图像聚合
类似于文献[4],每个新的强度和深度图像 ( I , D ) ∈ R W × H (I,D) ∈ \mathbb{R}^{W×H} (I,D)∈RW×H对通过使用K-均值聚类(g K-Means),被分割成K个几何簇 V = { V i ∣ i = 1 , ⋅ ⋅ ⋅ , K } V =\{V_i| i = 1,··· ,K\} V={Vi∣i=1,⋅⋅⋅,K}。假设每个簇满足刚性条件,每个刚体可以通过簇的组合来近似。同时文中还为每个集群分配一个分数 γ i ∈ [ 0 , 1 ] γ_i ∈ [0,1] γi∈[0,1]表示簇属于静态刚体的概率: γ i = 0 γ_i=0 γi=0表示动态簇,而 γ i = 1 γ_i=1 γi=1表示静态簇。对于RGB-D帧A,我们将总体分数表示为 γ A ∈ R K γ_A∈ \mathbb{R}^K γA∈RK。
2.2 距离判断
如果两个运动先验之间的差 ∣ ∣ ξ ~ s − ξ ~ d ∣ ∣ 2 ||\tilde{ξ}_s− \tilde{ξ}_d||^2 ∣∣ξ~s−ξ~d∣∣2小于阈值 d ^ \hat{d} d^,则将图像中的所有聚类视为静态和运动分割。否则,将共同优化当前帧的分数 γ B γ_B γB以及静态和动态刚体的相对运动 ξ s ξ_s ξs和 ξ d ξ_d ξd
2.3 图像分割
然后从聚类和分数中计算像素级分割 Γ ~ B ∈ R w × h \tilde{\Gamma}_B\in \mathbb{R}^{w\times h} Γ~B∈Rw×h。与静态融合类似,我们从分割中计算静态和动态刚体的加权RGB-D图像 Γ ~ B \tilde{\Gamma}_B Γ~B。这些加权图像用于重建背景和动态目标的模型,并通过帧-模型对齐来细化估计的相机姿态(第V节)。






![深度学习应用篇-推荐系统[11]:推荐系统的组成、场景转化指标(pv点击率,uv点击率,曝光点击率)、用户数据指标等评价指标详解](https://img-blog.csdnimg.cn/img_convert/3be20f20fef024e998854b404aa0f662.png)