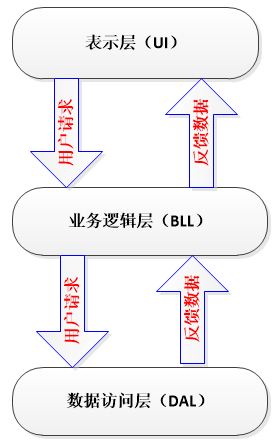
当遇到这个问题时,你可以尝试一下这些建议,按代码更改的顺序递增:
-
减少“batch_size”
-
降低精度
-
按照错误说的做
-
清除缓存
-
修改模型/训练
在这些选项中,如果你使用的是预训练模型,则最容易和最有可能解决问题的选项是第一个。
修改batchsize
如果你是在运行现成的代码或模型,则最好的做法是减小batchsize。减半,然后继续减半,直到没有错误为止。
但是,如果在此过程中,你发现自己将batchsize大小设置为 1 并且仍然无济于事,那么就还有其他问题,如果可以修复它,那么模型训练可以在更大的batchsize下工作。
降低精度
如果你用的是 Pytorch-Lightning,你也可以尝试将精度更改为“float16”。这可能会带来诸如预期的 Double 和 Float 张量之间的不匹配等问题,但它可以节省很多内存的,并且在性能上有一个非常轻微的权衡,使其成为一个可行的选择。
这第三种选择 ——
按照错误信息去做
可以使用以下命令完成此操作。如果你使用的是 Windows 计算机,则可以使用 set 而不是 export
export PYTORCH_CUDA_ALLOC_CONF=garbage_collection_thre







![深度学习应用篇-推荐系统[12]:经典模型-DeepFM模型、DSSM模型召回排序策略以及和其他模型对比](https://img-blog.csdnimg.cn/img_convert/d2e9d5399a50ed3a0003c6f9168d89ae.png)