摘要:本文整理自美团买菜实时数仓技术负责人严书,在 Flink Forward Asia 2022 实时湖仓专场的分享。本篇内容主要分为四个部分:
1. 背景介绍
2. 技术愿景和架构设计
3. 典型场景、挑战与应对
4. 未来规划
Tips:点击「阅读原文」免费领取 5000CU*小时 Flink 云资源
01
背景介绍
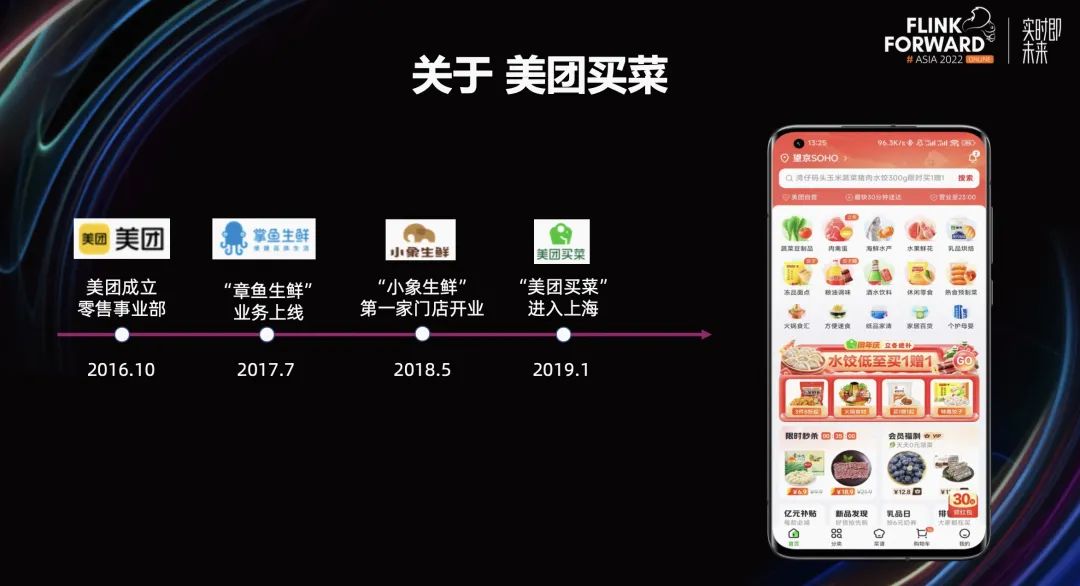
美团买菜是美团自营生鲜零售平台,上面所有的商品都由美团亲自采购,并通过供应链物流体系,运输到距离用户 3km 范围内的服务站。用户从美团买菜平台下单后,商品会从服务站送到用户手中,最快 30 分钟内。
上图中,左侧的时间轴展示了美团买菜的发展历程,右侧展示了美团买菜丰富的商品。目前,美团买菜在北上广深、武汉等城市均有业务覆盖,为人们日常的生活提供便利。在疫情场景下,起到了非常重要的保障民生作用。

接下来,介绍一下实时数仓场景。美团买菜的实时数仓场景分为三个部分。
第一个应用场景,数据分析部分。其主要用户是业务管理层、数据分析师、数据运营人员等等。他们通过数据大盘、数据看板等形式,获取数据指标,用于企业经营、运营、活动决策。
第二个应用场景,业务监控部分。其主要用户是大仓物流服务站的一线管理人员和总部的运营中台。他们会对线下作业情况进行异常监控,及时了解并处理线下业务的异动。
第三个应用场景,实时特征部分。其主要面向算法模型的实时特征,例如供应链场景的销量预测、履约场景的动态 ETA、用户的搜索排序推荐等等。
02
技术愿景和架构设计

技术愿景和架构设计。实时数仓的技术愿景是在新零售场景下,建设质量可靠、运行稳定、覆盖核心链路环节的实时数据体系。这里着重强调质量可靠、运行稳定、覆盖核心链路环节。
美团买菜所处的新零售行业,是一个薄毛利率赛道,对数据准确性的要求较高。由于买菜业务的正常运转,对数据有着强依赖,所以要求数据必须运行稳定。与此同时,美团买菜是自营的全链条业务,业务的链条环节较多,我们希望能够覆盖核心的链路环节。

基于上述的技术愿景,我们着重建设了质量保障体系、稳定性保障体系。这两个体系的主要目的是,提升实时数仓基线能力,让数据稳定生产,质量可信赖。希望质量保障体系、稳定性保障体系能够成为实时数仓的基石,建设好实时数仓的基本功。
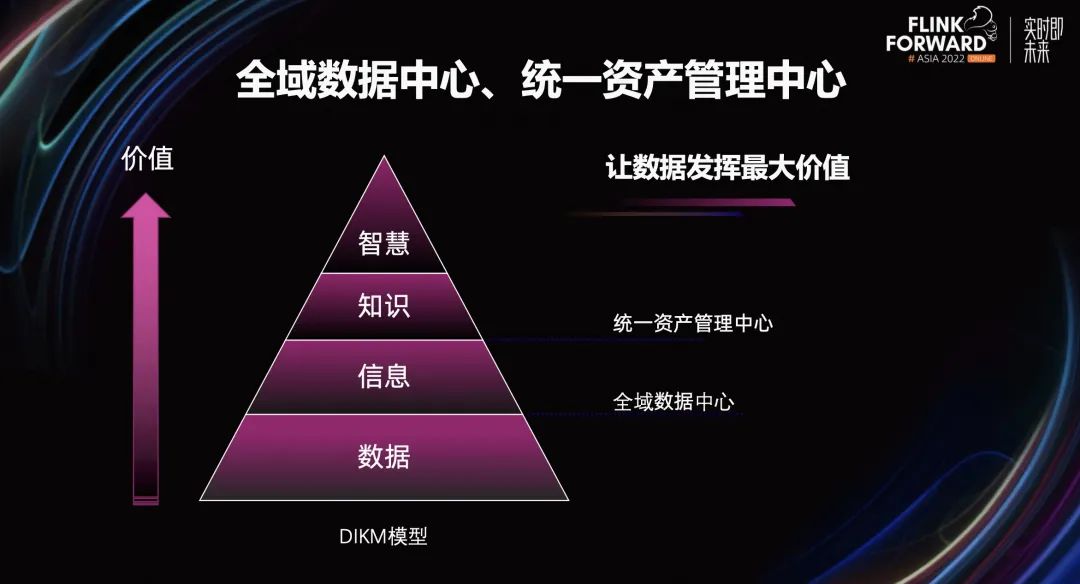
在做好实时数仓基本功的基础上,我们希望数据发挥它的最大价值。根据 DIKM 模型,从数据到信息,信息到知识,知识到智慧,价值会被不断放大。基于 DIKM 模型的理论指导,我们建立了全域数据中心、统一资产管理中心。
其中,全域数据中心会有效组织原始事实和原始数据,让数据转换成信息。统一资产管理中心对信息加以提炼,提升洞察力、创造力,帮助信息更好的转换成知识、智慧。
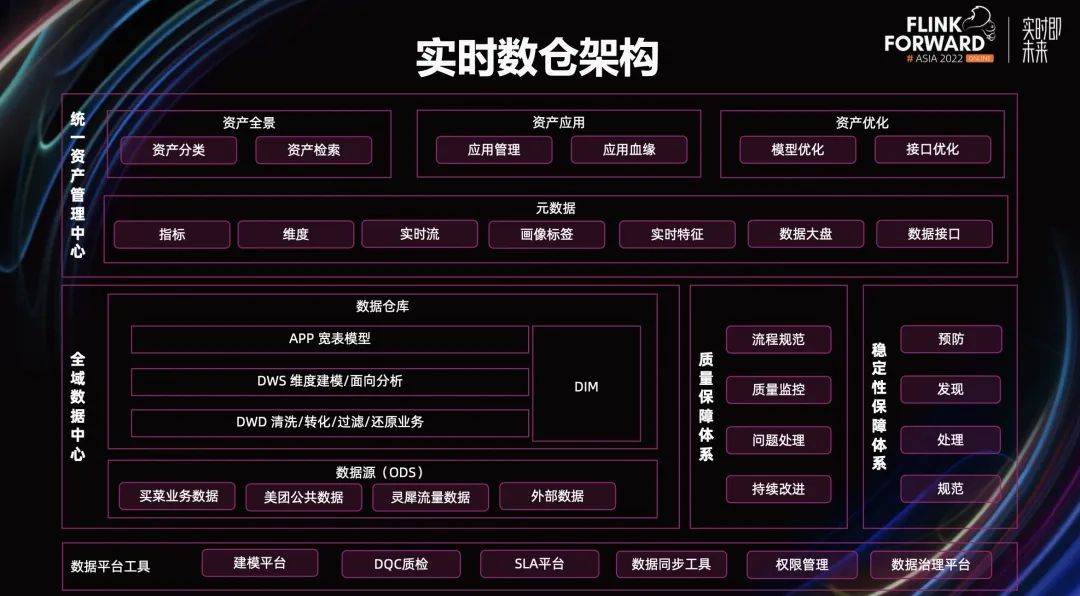
接下来,介绍一下实时数仓的整体架构。如上图所示,底层模块是数据平台部分,包含了数据的同步、加工、质量检测、管理权限、数据治理等环节设计的数据工具链。
在数据平台工具模块之上是全域数据中心、质量保障体系、稳定性保障体系三个模块。其中,全域数据中心是基于数据源 ODS 层建设的数据仓库。在数据源 ODS 层,当前主要包含买菜业务数据、美团公共数据、灵犀流量数据、外部数据四个部分。
数据仓库主要有 DWD 层、DWS 层、APP 层和一致性的 DIM 层组成。其中,DWD 层主要还原业务的数据加工过程,包含清洗、转换、过滤。原子指标的加工会在 DWD 层进行收口。
DWS 层是面向分析场景建设的,主要的建模方式是维度建模。在 DWS 层常见的数据加工过程包含多个业务主题的数据关联,数据力度上的轻度汇总,衍生指标的加工。
APP 层主要面向应用场景建设宽表模型,其目的是更好地满足应用场景的个性化需求,提升数据应用的效率和体验。
质量保障体系主要包含流程规范、质量监控、问题处理、持续改进四个部分,形成了一个闭环的管理系统。稳定性保障体系从预防、发现、处理、规范四个角度建设。
统一资产管理中心基于全域数据管理中心质量保障体系、稳定性保障体系,其建设基础是元数据管理。元数据包含指标、维度、实时流、画像标签、实时特征、数据大盘、数据接口等等。
基于原数据之上是资产全景、资产应用、资产优化三个部分。资产全景将数据资产,通过分类检索的形式展示出来。数据应用部分包含了应用的管理、应用的血缘。资产优化部分包含模型优化、接口优化。
03
典型场景、挑战与应对
3.1 动态 ETA 实时特征

实时数仓典型场景下的挑战和应对方法。首先,介绍一下动态 ETA 实时特征场景。
如上图所示,展示了用户在美团买菜下单的页面情况。页面中显示的预计送达时间,涉及到了动态 ETA。动态 ETA 是动态的承诺送达时间。经过研究发现,承诺用户送达时间不准,会影响用户的下单意愿。与此同时,当订单预计送达时间和实际送达时间差异变大后,客诉率及取消率均有明显攀升。
动态 ETA 的实现依赖算法模型预估履约时效。算法模型预估履约时效需要用到天气特征、用户下单商品特征、服务站内作业实时特征、配送实时特征。

动态 ETA 算法模型需要的实时特征数量非常多。算法特征生产链路比较复杂,任何一个实质特征的缺失,都会影响到算法模型的准确性,从而直接影响 C 端用户。因此实时特征数据稳定性要求 3 个 9 以上。

那么什么是 3 个 9 的稳定性呢?提升稳定性的本质,是提高系统的可用性。系统的可用性等于,平均无故障时间除以,平均无故障时间+平均故障修复时间。想要实现 3 个 9 的稳定性,要求平均每天故障时间少于 1.44 分钟。
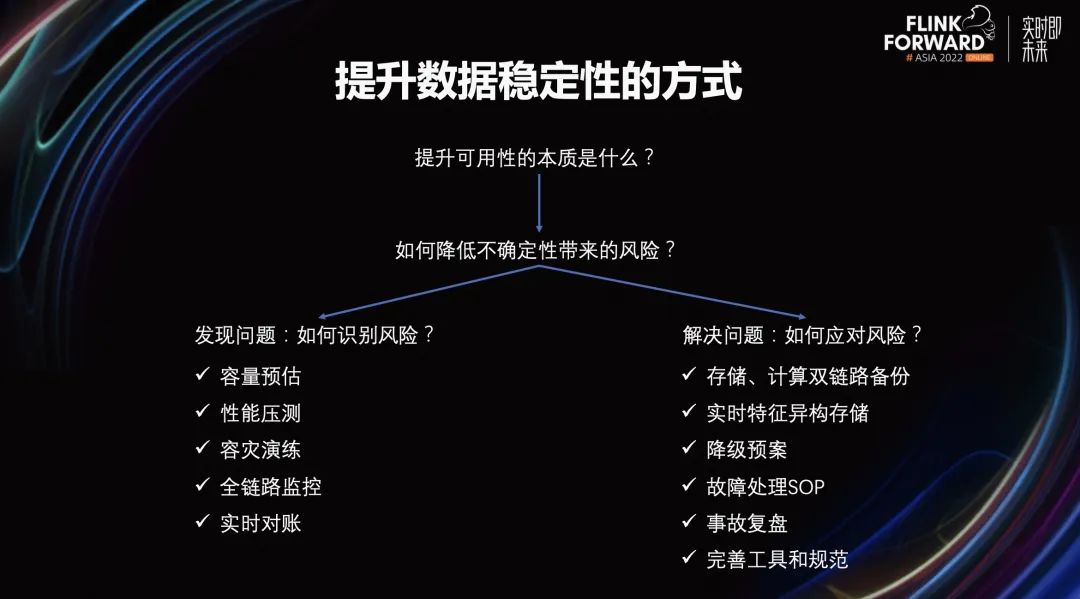
接下来,讲一讲提升数据稳定性的方式。提升数据稳定性需要提升可用性。提升可用性的本质是,降低不确定性带来的风险。降低不确定性带来的风险包含发现问题、解决问题两个部分。
在发现问题方面,需要思考如何识别风险。在实时特征的生产中,我们会通过容量预估、性能压测、容灾演练、全链路监控,实时对账的方式,更好的识别风险。
在解决问题方面,需要思考如何应对风险。一些常见应对风险的方式包含存储计算、双链路备份、实时特征、易购存储、降级预案、故障处理 SOP、事故复盘、完善工具和规范等。
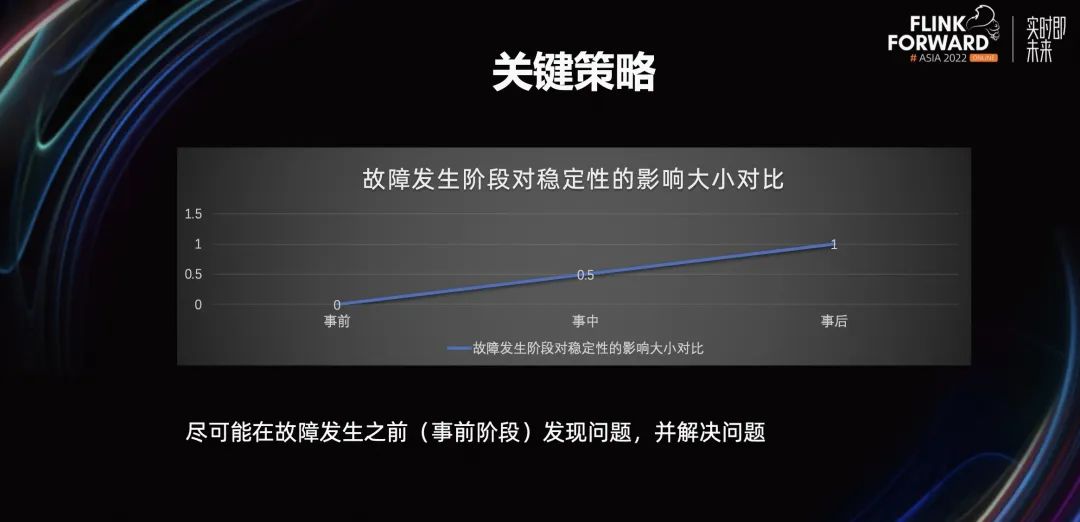
上图展示了,在故障发生的不同阶段,对稳定性的影响。事前阶段发生故障,对稳定性的影响最小。所以实时特征场景稳定性建设的关键策略是,尽可能在故障发生之前发现问题、解决问题。
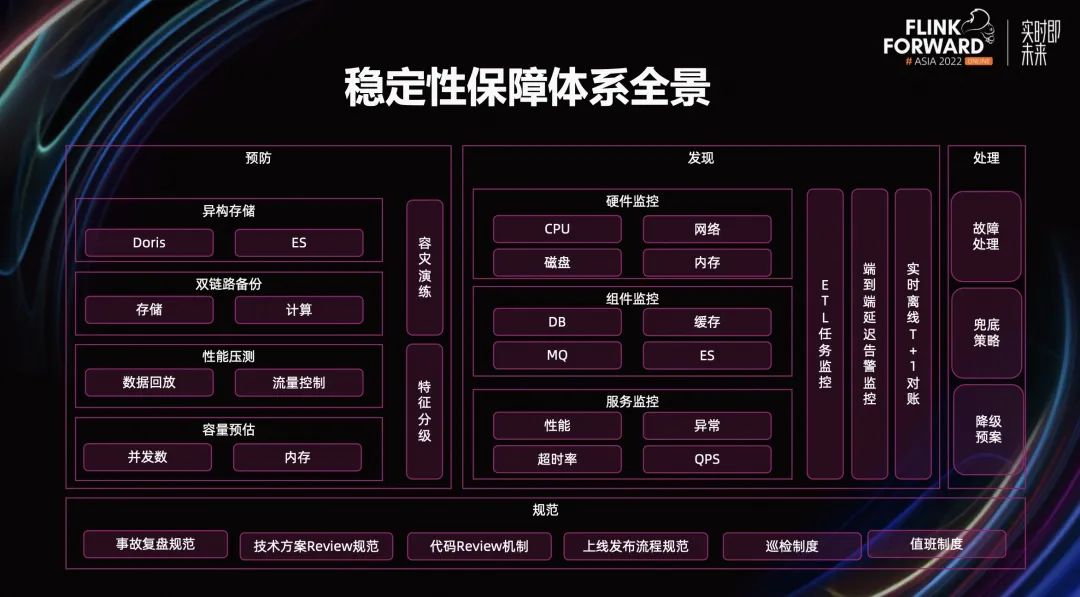
稳定性保障体系全景。稳定性保障体系全景包含预防、发现、处理、规范四个部分。其中,预防部分主要包括异构存储、双链路备份、性能压测、容量预估、容灾演练、特征分级等等。
异构存储是指,Doris 和 ES 作为应用层的存储引擎。双链路备份是指,存储和计算,多机房部署两条数据生产链路。这两条数据生产链路互为储备,任何一条链路出现问题,都可以快速切换到另一条链路,从而保障数据的持续生产。在性能压测部分,主要通过数据回放和流量控制实现。容量预估是指 Flink 的并发数和内存配置。
在发现部分,我们除了在硬件、组件、服务层建立完善的监控体系,还针对数据场景的常见风险、异常情况,着重建设了 ETL 任务监控、端到端数据延迟监控、实时离线 t+1 对账。在风险处理部分,我们主要通过故障处理、兜底策略、降低预案来实现。
在预防、发现、处理三个部分的经验,通过规范的形式进行沉淀。规范部分主要包含事故的复盘规范、技术方案 review 规范、代码 review 机制、上线发布流程规范、巡检机制、值班制度。
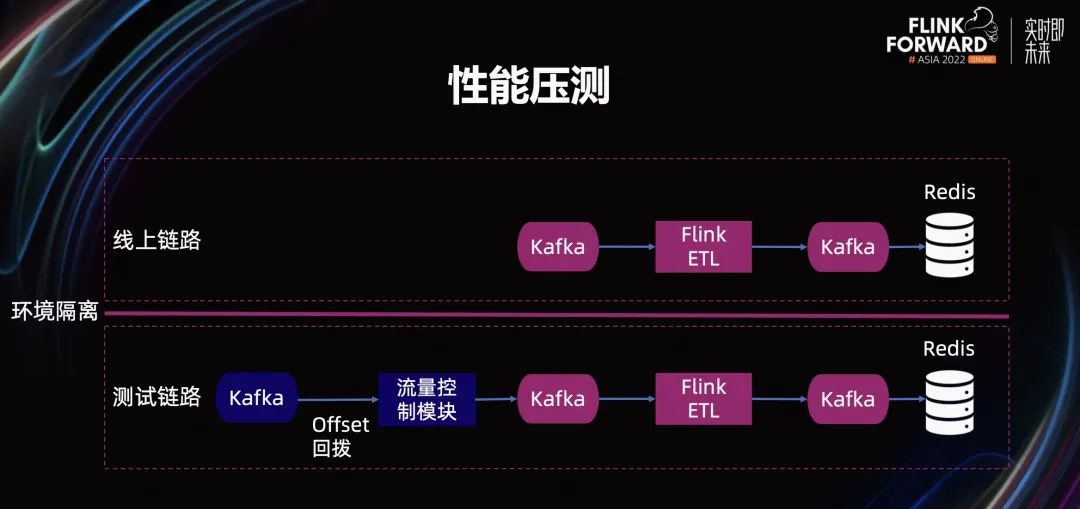
下面重点介绍一下性能压测部分。如上图所示,我们通过环境隔离的方式,建立了线上和测试两条完整的数据链路。
在测试链路中,我们通过回拨 Kafka Offset,得到了非常大的数据流量。然后,通过流量控制模块得到需要的测试流量,从而实现按需构建压测流量。最后,我们通过记录不同流量下的链路性能,得到了需要的性能压测结果。

上图展示了性能压测结果的评估指标体系,其中包含了过程指标和结果指标。主要指标有任务配置、机器状态、Source QPS、Sink QPS、瓶颈算子 QPS、最大可支撑流量倍数 N、端到端耗时。
3.2 实时数据经营分析

实时数据经营分析场景。美团买菜业务经常举行营销活动,提升用户的活跃度。在营销大促场景下,运营人员需要实时了解业务的经营状态,并制定运营策略。
与此同时,买菜业务受工作日、非工作日、节假日因素的影响,数据指标波动较大。单纯看指标的大小,很难判断指标的好坏,往往需要结合周同比、年同比进行辅助判断。在近几年的疫情场景下,买菜业务经常出现抢单模式,流量短时间内暴涨。

美团买菜面临的挑战。一方面,数据质量要求十分严苛。实时和离线数据差异不超过万分之三,端到端的数据差异不超过万分之一。在百万 QPS 流量下,需要保障无数据延迟。
另一方面,数据架构本身复杂度高。在实时、离线两条生产链路下,Flink 只支持计算引擎内的 exactly-once。
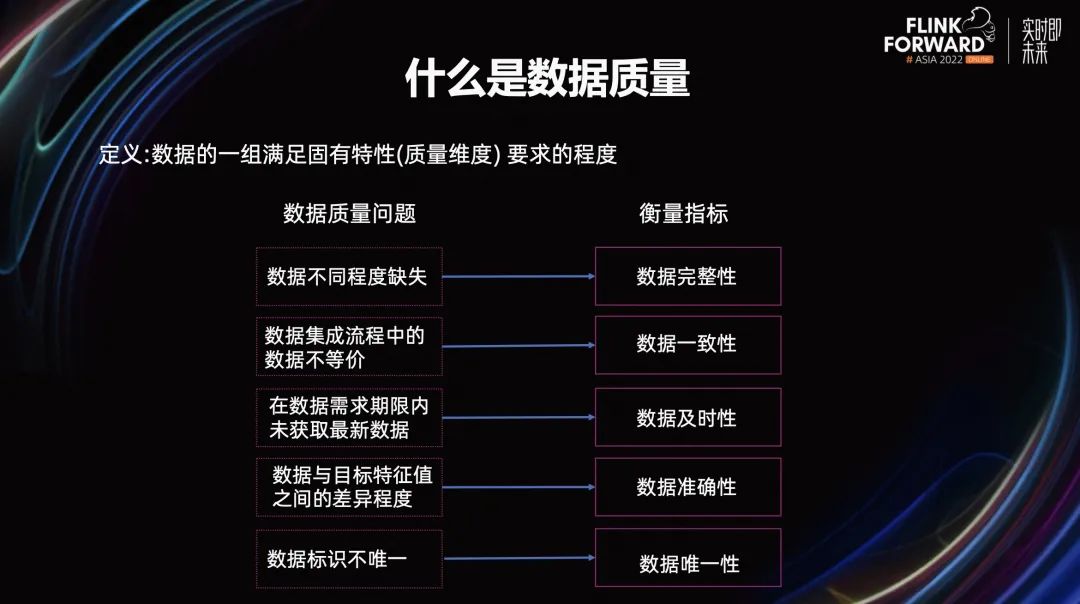
在上述情况下,数据质量的保障面临了很大挑战。数据质量是指,数据的一组满足固有特性(质量维度)要求的程度。
上图中,左边展示了数据质量问题。数据不同程度缺失,数据集成流程中的数据不等价,在数据需求期限内未获取最新数据,数据与目标特征值之间的差异程度、数据标识不唯一。
由于这些数据质量问题可以通过对应的指标来衡量,所以我们用数据完整性、数据一致性、数据及时性、数据准确性、数据唯一性,来衡量数据质量的好坏。
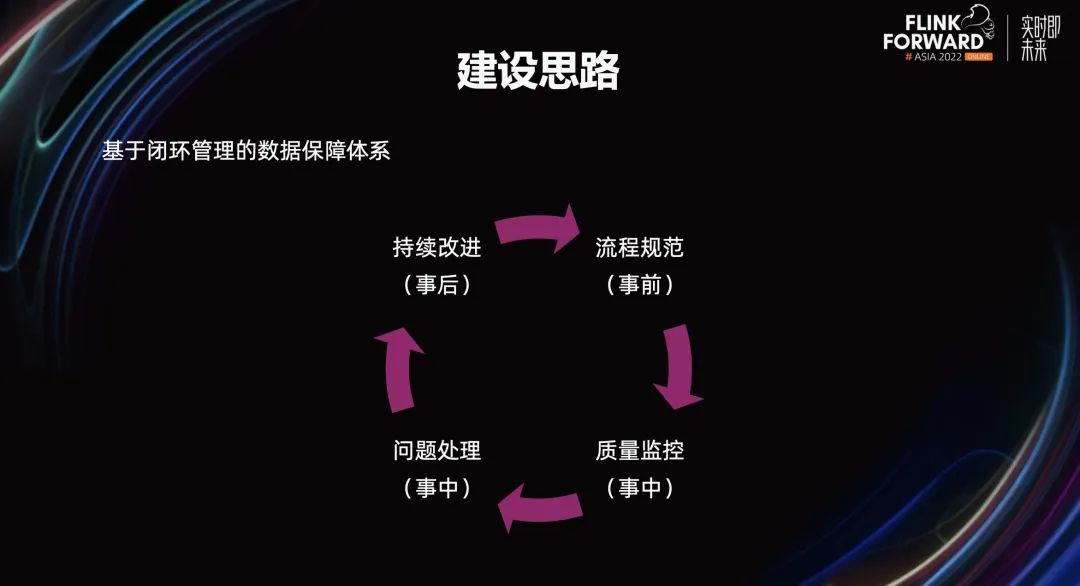
数据质量保障体系的建设思路是基于闭环管理,事前通过流程规范,减少质量问题的发生。事中通过数据质量监控系统,发现问题并处理问题。事后通过复盘的形式,将遇到的问题总结提炼,持续对流程规范进行改进。由此可见,事前、事中、事后组成了完整的闭环。
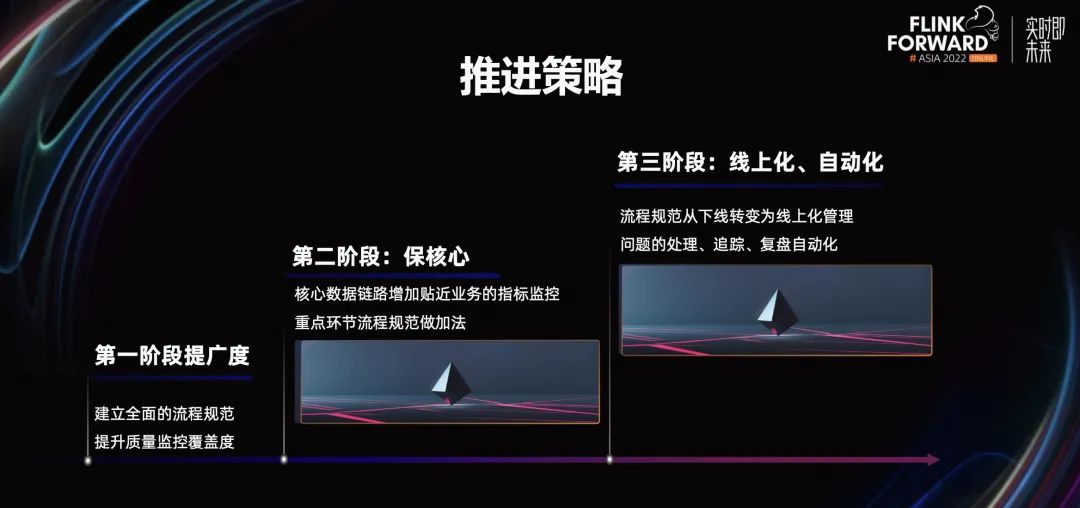
在数据保障体系的推进策略上,我们整体上分为三个阶段。
第一阶段,提广度。我们建立了从需求分析、技术设计、数据模型开发、数据测试数据上线等等,覆盖了数据研发全流程的规范体系。在这个阶段,我们重点提升质量监控覆盖度,将数据生产过程进行全面的监控覆盖。
第二阶段,保核心。在核心数据链路上,增加贴近业务的指标监控。相对于第一阶段的监控,第二阶段的监控能更好的发现个性化的业务问题。针对影响数据质量较大的流程规范做加法,保证完整的落地,持续的改进。
第三阶段,线上化、自动化。线上化是指,将流程规范从线下转变为线上管理。线上管理的好处是,便于后续的统计分析。自动化是指,问题的处理、追踪。从人工处理的方式,变成工具,自动化的方式实现,避免遗漏并减少运营成本。
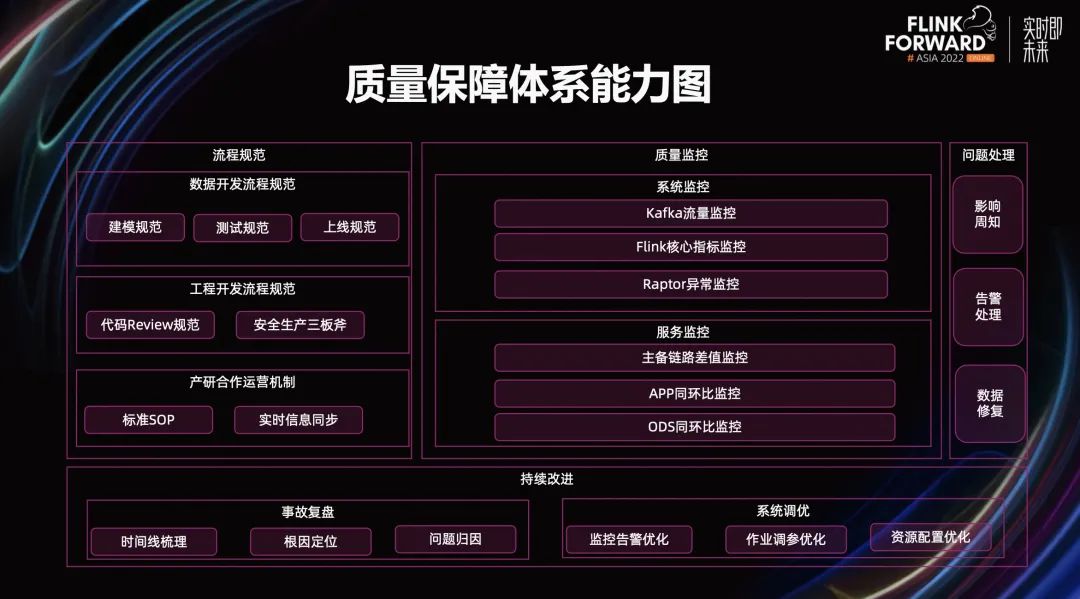
上图是数据质量保障体系的能力图,数据质量保障体系包含流程规范、质量监控、问题处理、持续改进四个模块儿。流程规范部分包含数据开发规范、工程开发流程规范、产业合作机制运营三个部分。
质量监控包含系统监控和服务监控。其中,系统监控包含存储引擎 Kafka 流量监控、计算引擎 Flink 核心指标监控、基于数据埋点的 Raptor 异常监控。
在服务监控方面,包含了主链路差值监控、APP 从同环比监控、ODS 层同环比监控。在问题处理方面,主要包括影响周知,告警处理、数据修复。在持续改进方面,包含基于时间线梳理、声音定位、问归因、监控告警优化、作业调参优化、资源配置优化。
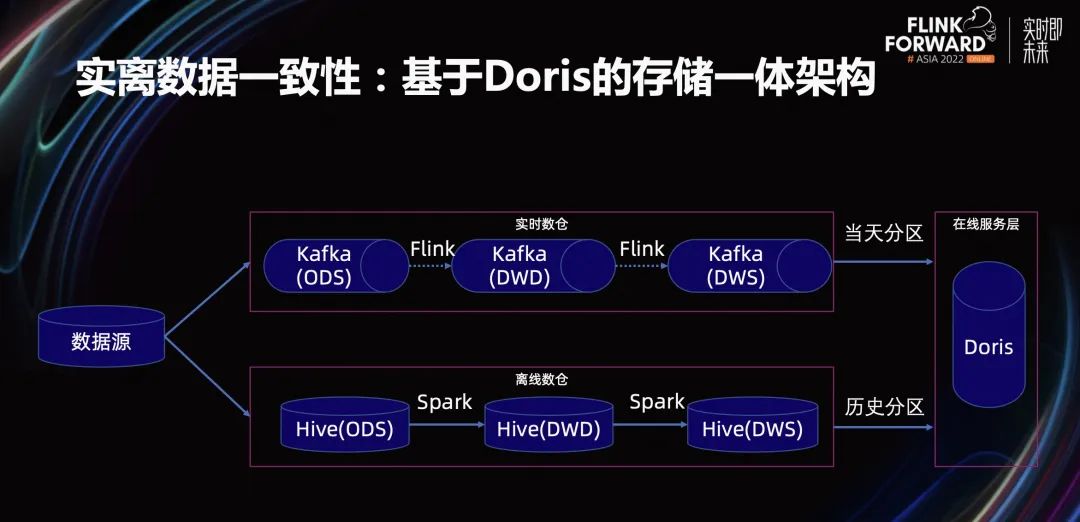
在实时离线数据的一致性方面,我们基于 Doris 实现了存储一体架构。存储一体架构是基于 Lambda 架构改进实现的。在数据源部分,数据源通过两种数据同步的方式,分别同步到实时数仓和离线数仓。
实时数仓通过 Flink 引擎,对数据进行分层加工。离线数仓通过 Spark 引擎,对数据进行分层加工。实时数仓的数据和离线数仓的数据,最终会写到 Doris 存储引擎的同一个数据模型上。
Doris 数据模型按天进行分区,实时数仓的数据会写到当天分区,离线数仓的数据会写到历史分区。当外部的数据查询需要查询当天或历史数据时,只需要通过时间分区路由。从而保证数据指标、数据维度口径完全一致。

在数据准确性方面,我们通过数据幂等和监控来实现。Kafka 只支持计算引擎内的 exactly once。为了实现端到端的 exactly once,我们一方面使用 Doris 的约定模型,实现数据幂等。另一方面,在数据加工过程中,按照业务组件进行数据去重。数据去重通常采用 row number 或 last value 的方式实践。
在质量的监控上,监控指标体系包含窗口统计指标、波动监控窗口。窗口统计指标是指,数据量、最大值、最小值、平均值、空值、占比、正则匹配。波动监控是指,数据的同环比。
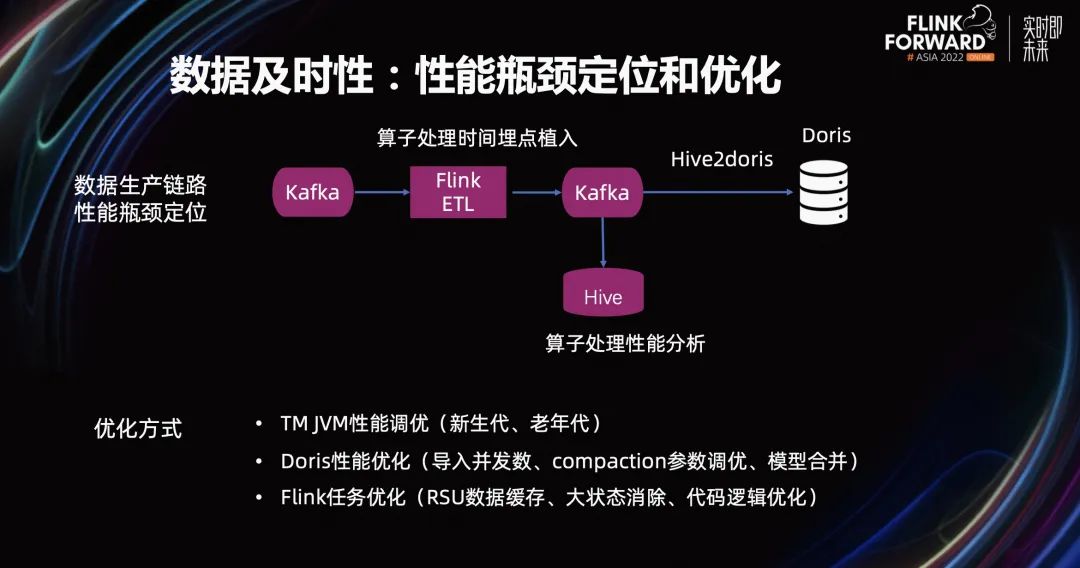
在数据的及时性方面,我们通过性能瓶颈的定位和优化来解决。上图展示了数据生产链路性能瓶颈定位的过程。我们在 Flink ETL 任务里,植入算子处理的时间埋点。然后,将 ETL 任务输出的 Kafka,同步一份埋点数据到 Hive 引擎里。基于 Hive 引擎进行算子处理、性能分析,从而定位性能瓶颈。
当算子定位到性能瓶颈之后,我们采用的优化方式包含 TM JVM 性能调优、Doris 性能优化、Flink 任务优化。具体的优化方式包括调整新生代、老年代比例;Doris 导入并发数;compaction 参数调优;模型合并;RSU 数据缓存;大状态消除;代码逻辑优化等等。
04
未来规划

接下来,讲一讲未来规划。实时数仓的未来规划主要包含三个部分。
第一部分,数据的标准化。数据标准化的好处是,更好的保障数据口径一致,提升建模规范程度,数据的应用性。
第二部分,流批一体。流批一体能提升实时离线数据的一致性和数据开发效率。
第三部分,自动化建模。自动化建模的好处是,统一模型设计并实现任务的智能构建。
往期精选





▼ 活动推荐▼

▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,免费领取 5000CU*小时 Flink 云资源
点击「阅读原文」,免费领取 5000CU*小时 Flink 云资源