竟然是今年第一篇
hhhh
过两天把上半年的东西梳理好的话
陆续放上来吧~
公司本地测试环境的hive版本不支持不等式关联操作,而现在用hive也比较多,所以在本地装了一个hive,主要写一下大致步骤和过程中遇到的问题~🐣🐣🐣
并详细记录一下后续启动hive服务时的操作
主要分为四大步:
文章目录
- 安装mysql
- 1. 版本查看
- 2.安装
- 安装hadoop
- 1.安装JDK
- 2.启动共享SSH服务
- 3.安装brew(视情况而定)
- 4.安装hadoop
- 5.配置hadoop文件
- 6.启动hadoop服务
- 安装hive
- 1. hive下载&配置路径
- 2.创建元数据库
- 3.配置hive-site.xml
- 启动hive服务
- 参考链接
安装mysql
因为是新机子,还没有配过,所以从安装mysql开始。
1. 版本查看
需要查看macos版本对应的mysql版本(关键)
前面一直下的版本不对,显示安装成功,但页面内鼠标一直转圈,好像卡住了一样
需要先查看macos版本
桌面左上角——🍎——关于本机——查看
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gytyvQ2p-1686564408307)(evernotecid://4A2C0413-3745-487E-BADD-865195851786/appyinxiangcom/25370018/ENResource/p11384)]](https://img-blog.csdnimg.cn/996508d359d2474d8098fbefd5b287be.png)
然后,在官网查看对应的版本
我没找到官网对应的版本列表链接,直接用新必应查的😂

2.安装
下载好后一路安装即可
什么都不用选,可以参考这个链接
Mysql for Mac(M1)安装指南 (qq.com)
记得记住密码!!!
安装完毕后测试一下
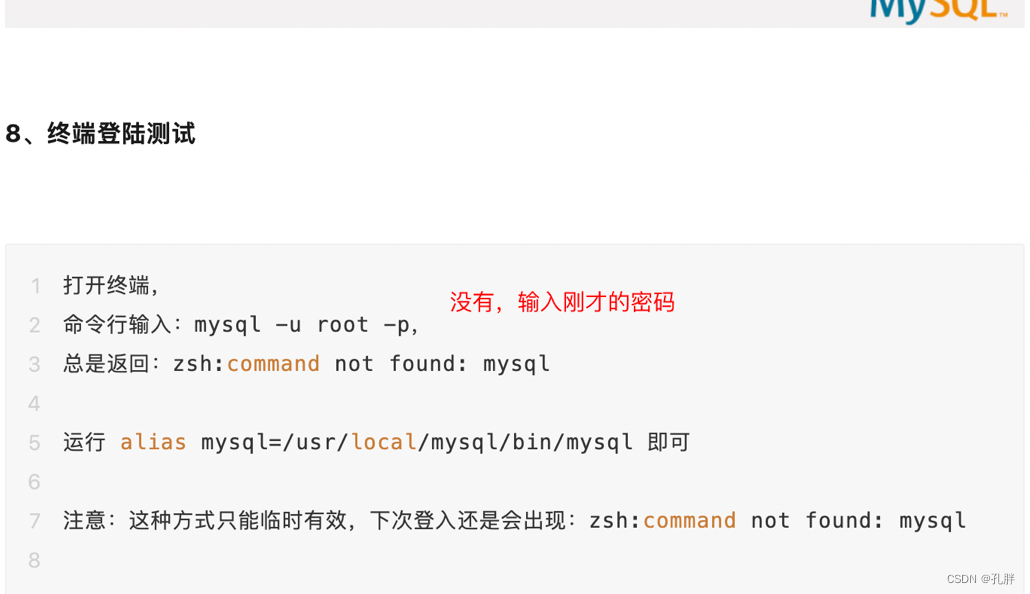

也可以配置到本地有的可视化编辑器,进行查看

至此,mysql就安装完毕了
安装hadoop
1.安装JDK
可以直接参考:https://mp.weixin.qq.com/s/wLW0qDyMbgEBCv22wWitow
官网地址:https://www.oracle.com/java/technologies/downloads/#jdk20-mac
选择合适的版本
bash_profile配置可以参考
JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_40.jdk/Contents/Home
PATH=$JAVA_HOME/bin:$PATH:.
CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:.
export JAVA_HOME
export PATH
export CLASSPATH
2.启动共享SSH服务
输入ssh localhost,如果提示错误,则
可以直接参照刚才这个链接里的步骤启动
https://blog.csdn.net/qq_20042935/article/details/123007927
如果没办法用界面打开,也可以使用命令行直接启动
开启:
sudo launchctl load -w /System/Library/LaunchDaemons/ssh.plist
启动后共享界面也显示打开状态

关闭:
sudo launchctl unload -w /System/Library/LaunchDaemons/ssh.plist
然后设置ssh免密码登陆
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
如果没有~/.ssh文件,就新建一个,生成新的密钥,再执行上述操作
klz@klzdeMacBook-Pro ~ % mkdir ~/.ssh
klz@klzdeMacBook-Pro ~ % cd ~/.ssh
klz@klzdeMacBook-Pro .ssh % ssh-keygen -t rsa -C "{email@**.com}”
3.安装brew(视情况而定)
可以使用brew安装的,可以安装brew后,使用brew来安装hadoop和hive。我这边因为os版本问题,brew安装一直有一个包无法下载,所以最后是手动下载hadoop和hive安装包下载的。
brew安装:
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
按回车后,根据提示操作:输入镜像序号 --> 输入Y,回车等待brew安装完成即可。
4.安装hadoop
- 法一
brew install hadoop
可能遇到的问题:
中途下载文件报错:curl: (7) Failed to connect to raw.githubusercontent.com port 443: Connection refused
解决方案参考:
https://www.debugpoint.com/failed-connect-raw-githubusercontent-com-port-443/
Open the /etc/hosts file.
sudo nano /etc/hosts
添加这一行在最后
85.199.108.133 raw.githubusercontent.com
保存后重新运行 brew install hadoop就可以了
- 法二
因为mac版本问题,后面一个安装包始终装不上(如果上面brew可以,就不用下载安装包进行安装了)
所以直接下载了hadoop安装包
# 新建目录,存放安装的hadoop应用mkdir Users/baihe/App
# 新建目录,存放应用的数据文件mkdir Users/baihe/Data/
tar -zxvf hadoop-2.7.3.tar.gz -C /Users/baihe/App
添加环境变量
vim ~/.bash_profile
# hadoop
export HADOOP_HOME=/Users/baihe/App/hadoop-2.7.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
退出编辑模式,使用 :wq 保存修改,然后运行 source 命令使文件中的修改立即生效:
source ~/.bash_profile
配置好环境后,可输入hadoop version进行查看
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iKtiRpnA-1686564408316)(evernotecid://4A2C0413-3745-487E-BADD-865195851786/appyinxiangcom/25370018/ENResource/p11390)]](https://img-blog.csdnimg.cn/6a2a9625dd4946ac946c60afc42cc461.png)
5.配置hadoop文件
需要配置的文件:
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
都是在configure内部进行辩解,粘贴property属性。
可以按照这个链接里的示例对上述文件进行编辑。
https://mp.weixin.qq.com/s/F-X9ph1g009qDWfmac7u2g
注意:
上面链接里core-site.xml部分的有问题。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LZhtX94T-1686564408316)(evernotecid://4A2C0413-3745-487E-BADD-865195851786/appyinxiangcom/25370018/ENResource/p11391)]](https://img-blog.csdnimg.cn/3940aef68f0b41a4a9bb4d33fa7d2e0e.png)
全部配置好之后
再运行 sudo hadoop namenode -format进行namenode格式化(我加了sudo,不然添加、删除一个current文件时会一直报错)
成功后

6.启动hadoop服务
进入刚才的目录 /Users/本地存放文件夹/App/hadoop……/sbin文件内
执行./start-all.sh
执行命令后,提示出入 yes/no 时,输入 yes 启动所有的 hadoop 服务,包括 hdfs 和 yarn服务
查看进程是否启动
在 Hadoop 的终端执行 jps 命令,在打印结果中会看到 5 个进程,分别是 namenode、 secondarynamenode、datanode、resourcemanager、nodemanager, 如下图所示。如果出现 了这 5 个进程表示主节点进程启动成功。

在这里可能会遇到的问题:
a. 刚才ssh免密登陆配置的有问题
和ssh publickey相关的,忘了截报错的图了……
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh localhost或者ssh 本地ip 查看是否配置成功(如果本地ip不行的话,可能要在hosts文件里面加一下ip)
b. localhost permission denied(使用sudo启动的话,可能会报 localhost: Disconnected from ::1 port 22)
需要设置一些文件夹权限(给最外层的文件夹循环赋权)
sudo chmod -R 777 /Users/kimdata
(我这里kimdata下一层就是刚才建的App和Data目录。)
设置正确应该就能正确启动了,
可以网页打开http://localhost:50070/,以及http://localhost:18088/;检查 namenode 和 datanode 是否正常,检查 Yarn 是否正常。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w6Dg8UlE-1686564408318)(evernotecid://4A2C0413-3745-487E-BADD-865195851786/appyinxiangcom/25370018/ENResource/p11394)]](https://img-blog.csdnimg.cn/77799df6af0d4eab9187b9389f4323f4.png)
安装hive
1. hive下载&配置路径
hive下载地址:http://archive.apache.org/dist/hive/
下载时需要注意,hive的版本需要和hadoop的版本对应一下,
对应链接可以参考:https://blog.csdn.net/tiankong_12345/article/details/80393774
下载好后解压到对应文件夹,配置对应路径 open ~/.bash_profile
export HIVE_HOME=/usr/local//hive # 刚才放置hive的目录,下一层是bin文件夹
export PATH=$HIVE_HOME/bin:$PATH
完毕后,source ~/.bash_profile,输入hive验证是否正常安装
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3JbfbQEP-1686564408319)(evernotecid://4A2C0413-3745-487E-BADD-865195851786/appyinxiangcom/25370018/ENResource/p11395)]](https://img-blog.csdnimg.cn/2d29fe2baeef417c87779d2ef87fb0e3.png)
2.创建元数据库
在mysql里创建,
mysql -u root -p进入mysql,
执行
create database metastore
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w38nI5Vh-1686564408320)(evernotecid://4A2C0413-3745-487E-BADD-865195851786/appyinxiangcom/25370018/ENResource/p11396)]](https://img-blog.csdnimg.cn/7e5a031441fd4f5285b209fb19e833eb.png)
3.配置hive-site.xml
需要更改的地方如下,ctrl+f “更改”找到对应地方替换,
其余地方直接粘贴过去。
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/metastore</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!--mysql用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>更改mysql的用户名</value>
</property>
<!--mysql密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>更改mysql的密码</value>
</property>
<!-- hive用来存储不同阶段的map/reduce的执行计划的目录,同时也存储中间输出结果,
,默认是/tmp/<user.name>/hive,我们实际一般会按组区分,然后组内自建一个tmp目录存>储 -->
<property> <name>hive.exec.local.scratchdir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/tmp/hive</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>false</value>
<description>Creates necessary schema on a startup if one doesn't exist
</description>
</property>
<!--自定义远程连接用户名和密码-->
<property>
<name>hive.server2.thrift.client.user</name>
<value>这里可以更改用户名</value>
<description>Username to use against thrift client</description>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>更改密码</value>
<description>Password to use against thrift client</description>
</property>
<!-- hive server2的使用端口,默认就是10000-->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- hive server2绑定的主机名-->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>localhost</value>
</property>
<property>
<name>hive.server2.enable.doAs </name>
<value>false</value>
</property>
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
<description>Whether HiveServer2 Active/Passive High Availability be enabled when Hive Interactive sessions are enabled.This will also require hive.server2.support.dynamic.service.discovery to be enabled.</description>
</property>
配置好后,
在https://dev.mysql.com/downloads/connector/j/mysql-connector,下载mysql连接器,选platform independent的操作系统。解压以后,把jar文件复制到/usr/local/hive/lib(hive的lib)目录下面。
命令行输入schematool -dbType mysql -initSchema ,再次打开hive,show databases;成功运行输出结果则安装成功。
启动hive服务
在hive的bin目录下,
hive --service metastore &
hive --service hiveserver2 &
或者后台长时间运行
nohup hive --service metastore 2>/usr/data/hive/log/metastore/metastore.err &
#或者
nohup hive --service metastore >/usr/data/hive/log/metastore/metastore.log &
查看服务
ps -ef|grep hive 查看服务
jps # 有两个runjar则okk
lsof -i tcp:9083 查看端口
lsof -i tcp:10000 查看端口
hive log日志的地址(启动服务时的报错可以在里面查看):
/System/Volumes/Data/private/var/folders/6r/xjdj2nb17zxb1jcg3zdc7yc80000gn/T/klz
(搜索hive_log可以找到)
确保hiveserver2正常启动(也可以查看10000端口是否正常)
然后启动beeline
命令行直接输入beeline
!connect jdbc:hive2://localhost:10000
然后不用输入密用户名和密码,直接按enter
正常启动,则OK了
!quit退出beeline
可以打开dbeaver连接本地hive,配置如图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8DvnmBXx-1686564408320)(evernotecid://4A2C0413-3745-487E-BADD-865195851786/appyinxiangcom/25370018/ENResource/p11397)]](https://img-blog.csdnimg.cn/6a73c16891a94ceb91fec4303d630c4f.png)
驱动选择jdbc里的jar包
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fSVZYmm2-1686564408321)(evernotecid://4A2C0413-3745-487E-BADD-865195851786/appyinxiangcom/25370018/ENResource/p11398)]](https://img-blog.csdnimg.cn/1a4f2c29c1fa4ca39387e679381004b2.png)
即可正常连接😭😭😭😭😭(太不容易了)
开启hive服务:
- 开启ssh共享
- 开启/关闭:
sudo launchctl load -w /System/Library/LaunchDaemons/ssh.plist
sudo launchctl unload -w /System/Library/LaunchDaemons/ssh.plist
- 开启hadoop
- 格式化(hadoop namenode -format)
- 在本地存放文件夹/App/hadoop……/sbin文件内,执行
start-all.sh(关闭是stop-all.sh)
- 开启hive服务
- 在hive的bin目录下
(/Users/hive_file/App/apache-hive-2.3.3-bin/bin)
- 在hive的bin目录下
hive --service metastore &
hive --service hiveserver2 &
或者
nohup hive --service metastore 2>/usr/data/hive/log/metastore/metastore.err &
#或者
nohup hive --service metastore >/usr/data/hive/log/metastore/metastore.log &
- 关闭hive/hadoop服务
查看服务
ps -ef|grep hive 查看服务
jps # 有两个runjar则okk
lsof -i tcp:9083 查看端口
lsof -i tcp:10000 查看端口
然后 kill -9 pid号
参考链接
https://mp.weixin.qq.com/s/F-X9ph1g009qDWfmac7u2g
Mac下安装Hadoop_mac安装hadoop_杨林伟的博客-CSDN博客
https://yanglinwei.blog.csdn.net/article/details/109644326
https://discussionschinese.apple.com/thread/254489986
https://blog.csdn.net/muyimo/article/details/125211460
https://www.5axxw.com/questions/simple/k93qak
https://mp.weixin.qq.com/s/F-X9ph1g009qDWfmac7u2g (安装包安装hadoop)
https://blog.csdn.net/sinat_35821976/article/details/99939757
https://blog.csdn.net/tktttt/article/details/110088179
后面插入数据的时候一直报错:
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Error caching map.xml: org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /tmp/hive/klz/8030d5ba-e55b-4ba0-b320-b7206685bd44/hive_2023-06-12_15-02-08_865_3712841866218528734-5/-mr-10003/cb4a1b04-b611-4ba6-943b-6c457ab81228/map.xml could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation.
我不确定是怎么解决的了
可能是:
- 删除dadoop里的Data/tmp/下面的current文件夹,然后重新格式化namenode format,然后重启hive服务
- 也可能是改了yarn-site.xml文件,添加了
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3.0</value>
</property>











![[CKA]考试之K8s 版本升级](https://img-blog.csdnimg.cn/e7da1dd29b2f4bea8ecc182f507a4347.png)



