🧑💻作者: @情话0.0
📝专栏:《C++从入门到放弃》
👦个人简介:一名双非编程菜鸟,在这里分享自己的编程学习笔记,欢迎大家的指正与点赞,谢谢!

list
- 前言
- 一、list 的使用
- 1.1 list 的构造函数声明
- 1.2 list iterator的使用
- 1.3 list element access
- 1.4 list capacity
- 1.5 list modifiers
- 1.6 list operations
- 二、list的模拟实现
- 1. list节点构造
- 2. 迭代器
- 2.1 改造前 (有局限性,只限于非 const 类型)
- 2.2 改造后
- 3. 插入与删除
- 3.1 任意位置插入(insert)
- 3.2 任意位置删除(erase)
- 3.3 尾插、头插
- 3.4 尾删、头删
- 4. clear()
- 5. 析构函数
- 6. 构造
- 6.1 无参构造
- 6.2 迭代器区间构造
- 6.3 拷贝构造
- 7. 赋值运算符重载
- 总结
前言
-
list 是允许在序列内的任何位置进行常量时间的插入和删除操作的序列容器,并且该容器可以前后双向迭代。
-
list 的底层为双链表结构,双链表可以将它们包含的每个元素存储在不同且不相关的存储位置,在节点中通过指针指向其前一个元素和后一个元素。
-
list 与 forward_list 非常相似:主要区别在于 forward_list 是单链表,因此它们只能向前迭代,以让其更简单和更高效。
-
与其他基本标准序列容器(array、vector和deque)相比,list 在容器内的任何位置插入、获取和移动元素方面通常表现更好,效率更高。
-
与其他序列容器相比,list 和 forward_list 最大的缺陷是不支持任意位置的随机访问;例如,要访问列表中的第六个元素,必须从已知位置(如开始或结束)迭代到该位置,这需要在两者之间的距离上花费线性时间。它们还消耗一些额外的内存来保存与每个元素相关联的链接信息(对于包含小元素的大型列表来说,这可能是一个重要因素)。
一、list 的使用
对于 list 的学习还是和之前的序列容器的一样,先了解一下 list 中一些常见的接口。
1.1 list 的构造函数声明
| 构造函数( (constructor)) | 接口说明 |
|---|---|
| list (size_type n, const value_type& val = value_type()) | 构造的list中包含n个值为val的元素 |
| list() | 构造空的list |
| list (const list& x) | 拷贝构造函数 |
| list (InputIterator first, InputIterator last) | 用[first, last)区间中的元素构造list |
void ListTest1()
{
list<int> l1; //无参构造,参数类型为int
list<int> l2(5, 10); //构造l2,存放5个10
list<int> l3(l2);//通过l2拷贝构造l3
int arr[] = { 1, 2, 3, 4, 5 };
list<int> l4(arr,arr+sizeof(arr)/sizeof(arr[0]));//以数组为迭代器区间构造l4
list<int> l5(l4.begin(), l4.end());//用l4的[begin(), end())左闭右开的区间构造l5
}
1.2 list iterator的使用
在这里我们可以将迭代器理解成一个指针,该指针指向list中的某个节点,而list的迭代器是双向迭代器,支持 ‘++’ 和 ‘–’ ,但是不支持 ‘+’ 和 ‘-’ 。
| 函数声明 | 接口说明 |
|---|---|
| begin + end | 返回第一个元素的迭代器+返回最后一个元素下一个位置的迭代器 |
| rbegin + rend | 返回第一个元素的reverse_iterator,即end位置,返回最后一个元素下一个位置的reverse_iterator,即begin位置 |
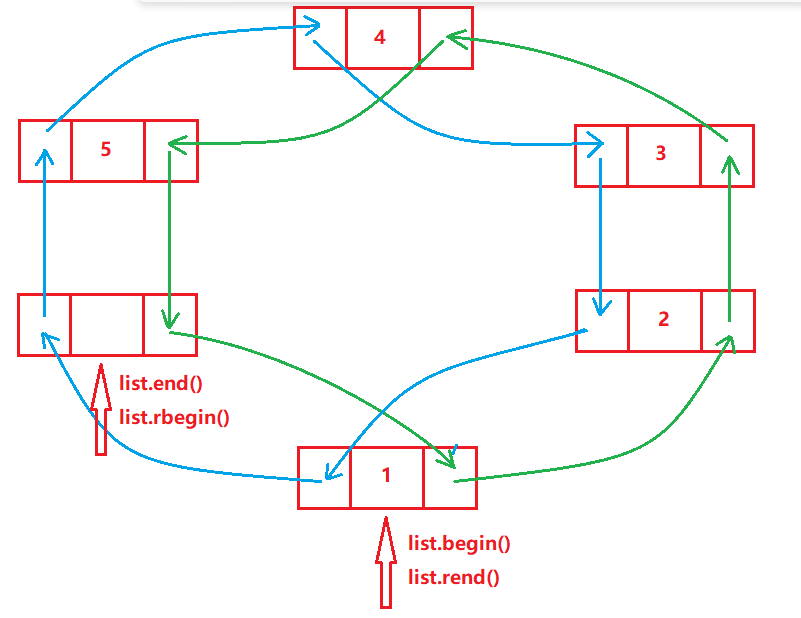
- begin与end为正向迭代器,对迭代器执行++操作,迭代器向后移动
- rbegin(end)与rend(begin)为反向迭代器,对迭代器执行++操作,迭代器向前移动
void ListTest2()
{
int arr[] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
list<int> l(arr, arr + sizeof(arr) / sizeof(arr[0]));
list<int>::iterator it = l.begin();
while (it != l.end())
{
cout << *it << " ";
it++;
}
cout << endl;
//这里可以用C++11的自动类型推断
auto rit = l.rbegin();
while (rit != l.rend())
{
cout << *rit << " ";
rit++;
}
cout << endl;
}
// 注意:遍历链表只能用迭代器和范围for
void PrintList(const list<int>& l)
{
// 注意这里调用的是list的 begin() const,返回list的const_iterator对象
for (list<int>::const_iterator it = l.begin(); it != l.end(); ++it)
{
cout << *it << " ";
// *it = 1; 编译不通过
}
cout << endl;
}
1.3 list element access
| 函数声明 | 接口说明 |
|---|---|
| front | 返回list的第一个节点中值的引用 |
| back | 返回list的最后一个节点中值的引用 |
1.4 list capacity
| 函数声明 | 接口说明 |
|---|---|
| empty | 检测list是否为空,是返回true,否则返回false |
| size | 返回list中有效节点的个数 |
1.5 list modifiers
| 函数声明 | 接口说明 |
|---|---|
| push_front | 在list首元素前插入值为val的元素 |
| pop_front | 删除list中第一个元素 |
| push_back | 在list尾部插入值为val的元素 |
| pop_back | 删除list中最后一个元素 |
| insert | 在list position 位置中插入值为val的元素 |
| erase | 删除list position位置的元素 |
| swap | 交换两个list中的元素 |
| clear | 清空list中的有效元素 |
void ListTest3()
{
int arr[] = { 1, 2, 3, 4, 5 };
list<int> l(arr, arr + sizeof(arr) / sizeof(arr[0]));
//头插 0
l.push_front(0);
PrintList(l);
//头删
l.pop_front();
PrintList(l);
//尾插 6
l.push_back(6);
PrintList(l);
//尾删
l.pop_back();
PrintList(l);
}
void ListTest4()
{
int arr[] = { 1, 2, 3, 4, 5 };
list<int> l(arr, arr + sizeof(arr) / sizeof(arr[0]));
auto pos = ++l.begin();
cout << *pos << endl;
// 在pos前插入值为0的元素
l.insert(pos, 0);
PrintList(l);
// 在pos前插入6个值为6的元素
l.insert(pos, 6, 6);
PrintList(l);
// 在pos前插入[v.begin(), v.end)区间中的元素
vector<int> v{ 7, 8, 9 };
l.insert(pos, v.begin(), v.end());
PrintList(l);
// 删除pos位置上的元素
l.erase(pos);
PrintList(l);
// 删除list中[begin, end)区间中的元素,即删除list中的所有元素
l.erase(l.begin(), l.end());
PrintList(l);
}
void ListTest5()
{
list<int> l1{ 0, 1, 2, 3, 4 };
list<int> l2{ 5, 6, 7, 8, 9 };
PrintList(l1);
l1.clear();
PrintList(l1);
l1.swap(l2);
PrintList(l1);
PrintList(l2);
l1.clear();
cout << l1.size() << endl;
}
1.6 list operations
| 函数声明 | 接口说明 |
|---|---|
| remove | 移除容器中某个特定值 |
| unique | 去除冗余值 |
| merge | 合并 |
| sort | 排序 |
| reverse | 反转 |
void ListTest7()
{
list<int> l1{ 2, 0, 0, 3, 0, 1, 4, 5 };
list<int> l2{6, 7, 8, 9};
//移除容器中的数值5
l1.remove(5);
PrintList(l1);
//移除数值10,虽然容器中没有这个数字,但不会报错
l1.remove(10);
PrintList(l1);
//去除冗余值
l1.unique();
PrintList(l1);
//排序
l1.sort();
PrintList(l1);
//合并
l1.merge(l2);
PrintList(l1);
//反转
l1.reverse();
PrintList(l1);
}
- remove 操作可以移除容器中的某个数值,但是当这个数值并不在容器中时并不会报错,没有任何影响;
- unique 可以去重,但是只能去重连续相同的,例如上面的去重例子中,在 3 的两边的 0 是不能去重掉的,所以去重的手尽量先排序,再去重;
- 虽然 list 也提供了排序,但是它的效率并不高,所以排序尽量不要使用 list 提供的,效率太低;
二、list的模拟实现
首先 list 是一个带头结点的双向循环链表,所以在模拟实现 list 功能前先完成对链表节点的构造。
1. list节点构造
对于链表节点来说需要三个成员变量,分别是指前和指后的指针,另外一个就是节点的数值。
template<class T>
struct ListNode
{
ListNode<T>* _next;
ListNode<T>* _prev;
T _val;
ListNode(const T& val = T())
:_next(nullptr), _prev(nullptr), _val(val)
{}
};
2. 迭代器
2.1 改造前 (有局限性,只限于非 const 类型)
template<class T>
struct list_iterator
{
typedef ListNode<T> Node; //链表节点
typedef list_iterator<T> self; //指向某个节点的指针
Node* _node;
//迭代器构造
list_iterator(Node* node)
:_node(node)
{}
T& operator*()
{
return _node->_val;
}
self& operator++()
{
_node = _node->_next;
return *this;
}
bool operator!=(const self& s)
{
return _node != s._node;
}
};
//实现在list的类中
typedef list_iterator<T> iterator;
iterator begin()
{
return iterator(_head->_next);
}
iterator end()
{
return iterator(_head);
}
通过上面的代码就可以完成对 list 的遍历,但是当要完成对 const 类型的 list 遍历就会出现报错,原因就在于将本来受限于const的 list 进行了权限的放大,也就是说被 const 修饰的 list 不能直接传给这类的迭代器,而应该给到也被 const 修饰的迭代器。
所以为了解决这个问题,可以通过再写一个 const 类型的迭代器来解决这个问题。但是很明显有一个瑕疵就是相较于上面的普通迭代器来说只对解引用函数的返回值的 const 修饰,这样就显得代码冗余。
template<class T>
struct const_iterator
{
typedef ListNode<T> Node;
typedef const_iterator<T> self;
Node* _node;
const_iterator(Node* node)
:_node(node)
{}
const T& operator*()
{
return _node->_val;
}
}
2.2 改造后
当然,我可以通过增加模板类型来完美地解决这个问题。为什么呢?在 list 类中,会根据 list 的 const 属性自动将模板参数第二个自行转化为是 const 类型的迭代器还是非 const 类型的迭代器。
什么意思呢?比如要对一个 const 修饰的 list 通过迭代器的方法进行遍历打印,首先我们要明白的就是被 const 修饰的 list 的每个结点是不能被改变的,当看到这个 list 被 const 修饰时就会自动选择typedef list_iterator<T, const T&, const T*> const_iterator;这行代码,那么这个迭代器的第二个参数就被修饰为 const 类型,进而在迭代器的类中就会将对应的参数Ref转化为 const 型,这样就使迭代器的解引用函数的返回值为 const 型,也就限制了链表节点是无法被修改的从而到达 const 的属性限制。而模板参数的第三个是节点的地址的获取,目的也就是为了对标STL模板库。
template<class T, class Ref, class Ptr>
struct list_iterator
{
typedef ListNode<T> Node;
typedef list_iterator<T, Ref, Ptr> self;
Node* _node;
list_iterator(Node* node)
:_node(node)
{}
Ref operator*()
{
return _node->_val;
}
Ptr operator->()
{
return &_node->_val;
}
self& operator++()
{
_node = _node->_next;
return *this;
}
self operator++(int)
{
self tmp(*this);
_node = _node->_next;
return tmp;
}
self& operator--()
{
_node = _node->_prev;
return *this;
}
self operator--(int)
{
self tmp(*this);
_node = _node->_prev;
return tmp;
}
bool operator!=(const self& s)
{
return _node != s._node;
}
bool operator==(const self& s)
{
return _node == s._node;
}
};
template<class T>
struct List
{
typedef ListNode<T> Node;
typedef list_iterator<T, T&, T*> iterator;
typedef list_iterator<T, const T&, const T*> const_iterator;
iterator begin()
{
return iterator(_head->_next);
}
iterator end()
{
return iterator(_head);
}
const_iterator begin()const
{
return const_iterator(_head->_next);
}
const_iterator end()const
{
return const_iterator(_head);
}
};
3. 插入与删除
3.1 任意位置插入(insert)
//在pos位置之前插入
void insert(iterator pos, const T& val)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
//构造新节点
Node* newnode = new Node(val);
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
prev->_next = newnode;
}
3.2 任意位置删除(erase)
一般来说,删除并不需要什么返回值,可是这里为什么返回值要是一个迭代器呢?具体原因后面再解释。
iterator erase(iterator pos)
{
assert(pos != end());
Node* prev = pos._node->_prev;
Node* next = pos._node->_next;
prev->_next = next;
next->_prev = prev;
delete pos._node;
return iterator(next);
}
3.3 尾插、头插
这里操作一定要要对 list 的结构有一个正确的认识,假设 list 有n个节点,那么就包含 n-1 个有效节点和一个非有效节点,而非有效节点是在头结点和为节点之间的。
void push_back(const T& val)
{
insert(end(), val);
}
void push_front(const T& val)
{
insert(begin(), val);
}
3.4 尾删、头删
void pop_back()
{
erase(--end());
}
void pop_front()
{
erase(begin());
}
4. clear()
这个函数的目的就是将链表的所有有效节点都删除掉,只留下那一个非有效节点。在这函数内部就是用了 erase 函数,在这里也就验证了为什么 erase 函数要传一个迭代器的返回值,原因就在于删除导致的迭代器失效问题,只有通过在删除之后在对删除节点的下一个位置进行标记才能有效地删除节点。
void clear()
{
iterator it = begin();
while (it != end())
{
it = erase(it);
}
}
5. 析构函数
析构函数可以先通过 clear 函数完成对所有有效节点的清楚,再删除掉唯一的一个非有效节点。
~List()
{
clear();
delete _head;
_head = nullptr;
}
6. 构造
6.1 无参构造
void List_Init()
{
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
}
//构造
List()
{
List_Init();
}
6.2 迭代器区间构造
template<class iterator>
List(iterator begin, iterator end)
{
List_Init();
while (begin != end)
{
push_back(*begin);
++begin;
}
}
6.3 拷贝构造
//传统写法
List(const List<T>& lt)
{
List_Init();
auto it = lt.begin();
while (it != lt.end())
{
lt.push_back(*it);
++it;
}
}
//现代写法
List(const List<T>& lt)
{
//这里的构造头结点极为重要,要不然在交换时 tmp 的节点根本无法连接到 this 指针对应的链表上
List_Init();
List<T> tmp(lt.begin(), lt.end());
swap(tmp);
}
//交换时只需交换头结点即可
void swap(List<T>& lt)
{
std::swap(_head, lt._head);
}
7. 赋值运算符重载
//注意:一定不能传引用,虽然传引用减少了拷贝,但是交换时原来的链表会受影响
List<T>& operator=(List<T> lt)
{
swap(lt);
return *this;
}
总结
vector 和 list 都是STL中非常重要的序列式容器,因为两个容器的底层结构不同,进而导致了它们的特性以及应用场景的不同,具体的不同点如下:
| 目录 | vector | list |
|---|---|---|
| 底层结构 | 动态顺序表,一段连续空间 | 带头结点的双向循环链表 |
| 随机访问 | 支持随机访问,访问某个元素效率O(1) | 不支持随机访问,访问某个元素效率O(N) |
| 插入和删除 | 任意位置插入和删除效率低,需要搬移元素,时间复杂度为O(N),插入时有可能需要增容,增容:开辟新空间,拷贝元素,释放旧空间,导致效率更低 | 任意位置插入和删除效率高,不需要搬移元素,时间复杂度为O(1) |
| 空间利用率 | 底层为连续空间,不容易造成内存碎片,空间利用率高,缓存利用率高 | 底层节点动态开辟,小节点容易造成内存碎片,空间利用率低,缓存利用率低 |
| 迭代器 | 原生态指针 | 对原生态指针(节点指针)进行封装 |
| 迭代器失效 | 在插入元素时,要给所有的迭代器重新赋值,因为插入元素有可能会导致重新扩容,致使原来迭代器失效,删除时,当前迭代器需要重新赋值否则会失效 | 插入元素不会导致迭代器失效,删除元素时,只会导致当前迭代器失效,其他迭代器不受影响 |
| 使用场景 | 需要高效存储,支持随机访问,不关心插入删除效率 | 大量插入和删除操作,不关心随机访问 |
以上就是关于 list 的学习总结,总的来说还是跟数据结构中的带头结点双向循环链表挺像的,对于 list 来说较为复杂难理解的就是迭代器这一块,可以好好的研究一下这里到底是如何实现的,其实 list 还有反向迭代器的实现,在这里就不多说,在后面的学习会提到。