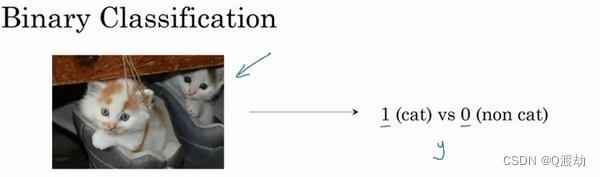
1、二分类(Binary Classification)
(1)、逻辑回归(logistic regression)是一个用于二分类(binary classification)的算法。所谓二分类是由输入到判断输出结果是或者不是。比如输入一个包含动物的图片,判断这张图片中的动物是否包含猫,有猫输出标签为 1,不是输出标签为 0,y表示输出的结果标签
(2)、为了在计算机中保存一张图片,需要保存三个矩阵, 它们分别对应图片中的红、绿、蓝三种颜色通道,每一个颜色通道需要一个矩阵来保存对应图片中红、绿、蓝三种像素的强度值。下面是三个规模为 5 * 4 的矩阵分别表示对应图片中红、绿、蓝三种像素的强度值(注意在实际中图片的每一个颜色通道的矩阵大小应该为 64 * 64的规模)
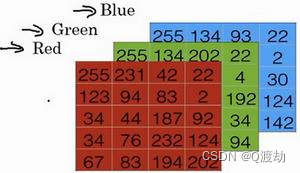
(3)、使用一个 5 * 4 * 3 的特征向量来保存上面三个颜色通道的像素强度值,大小为 60,使用
𝑛
𝑥 = 60 表示,来表示输入特征向量的维度
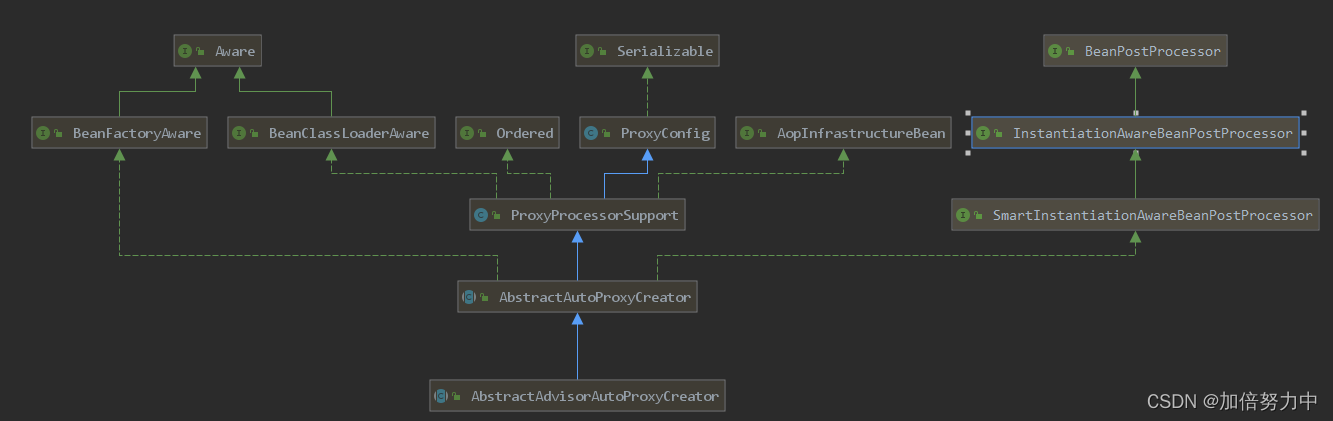
(4)、符号定义
- 𝑥:表示一个𝑛𝑥维数据,为输入数据,维度为(𝑛𝑥, 1),说白了就是一个列向量
- 𝑦:表示输出结果,取值为(0,1)
- (𝑥 (𝑖) , 𝑦 (𝑖) ):表示第𝑖组数据,可能是训练数据,也可能是测试数据,此处默认为训练数据,也即一组输入对应一组输出
- 𝑋 = [𝑥 (1) , 𝑥 (2) , . . . , 𝑥 (𝑚) ]:表示所有的训练数据集的输入值,放在一个 𝑛𝑥 × 𝑚的矩阵中,
- 其中𝑚表示样本数目,也即所有列向量构成的一个大矩阵,每一列就是一张图片的特征向量(也即红、蓝、绿三种像素的强度值),总共有 m 个这样的图片
- 𝑌 = [𝑦 (1) , 𝑦 (2) , . . . , 𝑦 (𝑚) ]:对应表示所有训练数据集的输出值,维度为1 × m
- 用一对(𝑥, 𝑦)来表示一个单独的样本,𝑥代表𝑛𝑥维的特征向量,𝑦 表示标签(输出结果)只能为 0 或 1。 而训练集将由𝑚个训练样本组成,其中(𝑥 (1) , 𝑦 (1) )表示第一个样本的输入和输 出,(𝑥 (2) , 𝑦 (2) )表示第二个样本的输入和输出,直到最后一个样本(𝑥 (𝑚) , 𝑦 (𝑚) ),然后所有的 这些一起表示整个训练集。有时候为了强调这是训练样本的个数,会写作𝑀𝑡𝑟𝑎𝑖𝑛,当涉及到 测试集的时候,我们会使用𝑀𝑡𝑒𝑠𝑡来表示测试集的样本数,所以这是测试集的样本数:
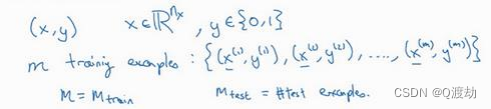
-
最后为了能把训练集表示得更紧凑一点,我们会定义一个矩阵用大写 𝑋 的表示,它由输入向量 𝑥 (1) 、 𝑥 (2) 等组成,如下图放在矩阵的列中,所以现在我们把 𝑥 (1) 作为第一列放在矩阵中, 𝑥 (2) 作为第二列, 𝑥 (𝑚) 放到第 𝑚 列,然后我们就得到了训练集矩阵 𝑋 。所以这个矩阵有 𝑚列, 𝑚 是训练集的样本数量,然后这个矩阵的高度记为 𝑛 𝑥 ,注意有时候可能因为其他某些原因,矩阵 𝑋 会由训练样本按照行堆叠起来而不是列,如下图所示: 𝑥 (1) 的转置直到 𝑥 (𝑚) 的转置,但是在实现神经网络的时候,使用左边的这种形式,会让整个实现的过程变得更加简单:

- 总之,𝑋是一个规模为𝑛𝑥乘以𝑚的矩阵,当用 Python 实现的时候,会使用 X.shape,这是一条 Python 命令,用于显示矩阵的规模,即 X.shape 等于(𝑛𝑥, 𝑚),𝑋是一个规模为𝑛𝑥乘以𝑚的矩阵,这就是如何将训练样本(输入向量𝑋的集合)表示为一个矩阵
- 同样,为了能更加容易地实现一个神经网络,将标签𝑦放在列
中将会使得后续计算非常方便,所以我们定义大写的 𝑌 等于 𝑦 (1) , 𝑦 (𝑚) , . . . , 𝑦 (𝑚) ,所以在这里 是一个规模为 1 乘以 𝑚 的矩阵,同样地使用 Python 将表示为 Y.shape 等于 (1, 𝑚) ,表示这 是一个规模为 1 乘以 𝑚 的矩阵。