目录
前言:
一、 什么是接口测试
二、 引入自动化背景
三、 自动化技术选型
四、 自动化测试用例
五、自动化成果
前言:
pytest和HttpRunner都是Python编程语言中常用的接口测试框架。
pytest是一种成熟的、灵活的、社区支持良好的测试框架,提供了丰富的测试功能和扩展机制,可以方便地运行各种类型的测试,如单元测试、功能测试和接口测试等。
HttpRunner 是一种基于Python的开源接口自动化测试框架,它支持多种测试用例的编写方式,包括YAML、JSON和Python等。它还提供了丰富的内置断言和可视化报告,使得接口测试变得更加高效和可靠。
一、 什么是接口测试
根据wiki中的定义,接口是一个共享的边界,计算机系统的多个独立组件通过它交换信息。这些信息的交换可以基于软件、硬件、外部设备、人和它们之间的组合。根据上述定义,可以面向软件、硬件、交互设备等展开接口测试。软件的接口测试是面向独立组件之间接口的一种测试,主要用于检测内外部系统及内部各子系统之间的交互点。测试的重点在于检查逻辑正确性、交互依赖性、数据正确性.
二、 引入自动化背景
基于以下几个情况,数栈引入自动化测试,以期提高测试效率,保障交付产品质量。
1、产品迭代迅速
目前数栈产品已经迭代至Release4.3版本。每过几个月进行一次产品release更新让回归测试的工作量持续上升。接口自动化测试可以很好的减少回归工作量。
2、应用系统日趋复杂
数栈目前自研8款产品和多个插件,产品之间的交互与产品-插件之间的交互日趋复杂。客观现实带来了更大的测试风险,测试消耗成本越来越高,花费的时间也越来越长。接口自动化测试可以提高测试效率。
3、部署环境多样
作为一款面向大数据的产品,除了开源的Hadoop,还需要适配TDH、CDH、HDP等其他引擎。同时,各种客户的POC环境也需要大量人力支持。
三、 自动化技术选型
接口测试可以使用的工具有很多,Postman、Jmeter、REST-Assured、SoapUI、httpclient等等。数栈产品使用的是HttpRunner这个框架。相比较于前几类工具,它具有以下特点:
1、简单易用。
虽然前几款工具中有图形化界面可以让人直观的进行操作,但HttpRunner以“关键字”的优势可以让QA快速的上手框架,对代码能力要求低。根据对应的关键字填入相应的值,即可生成一条测试用例。
2、可扩展性强
HttpRunner的V3版本支持了pytest,可以方便的借助pytest插件解决接口测试中遇到的问题,如数据驱动、参数化等。jUnit虽然也具有扩展性强的特点,但是Java语言对于QA来说太重,且学习成本比HttpRunner更高。
1、易于集成CI
HttpRunner支持CLI命令,可以方便的接入Jenkins、Gitlab CI等工具。
2、录制回放
通过Charles、Fiddler等工具将请求到处为.har文件,然后通过HttpRunner提供的命令,就可以将.har文件转换成json/yaml文件。
数栈产品曾使用过Jmeter作为接口自动化工具。Jmeter拥有可视化图形界面,通过拖动组件信息就可完成用例编排,方便QA使用。但是Jmeter的内置函数不能满足于复杂的数栈产品,虽然可以选择beanshell来写工具脚本,但其难以调试,第三方包管理困难等问题使编写效率低下。同时Jmeter容易出现编码混乱、日志不易于查看等问题。
HttpRunner作为一款优秀的开源框架,在GitHub上拥有2.6k star,集简单易用、扩展性强、易于集成、录制回放等特性于一体,相比较于Jmeter更适用于数栈自动化实践。
四、 自动化测试用例
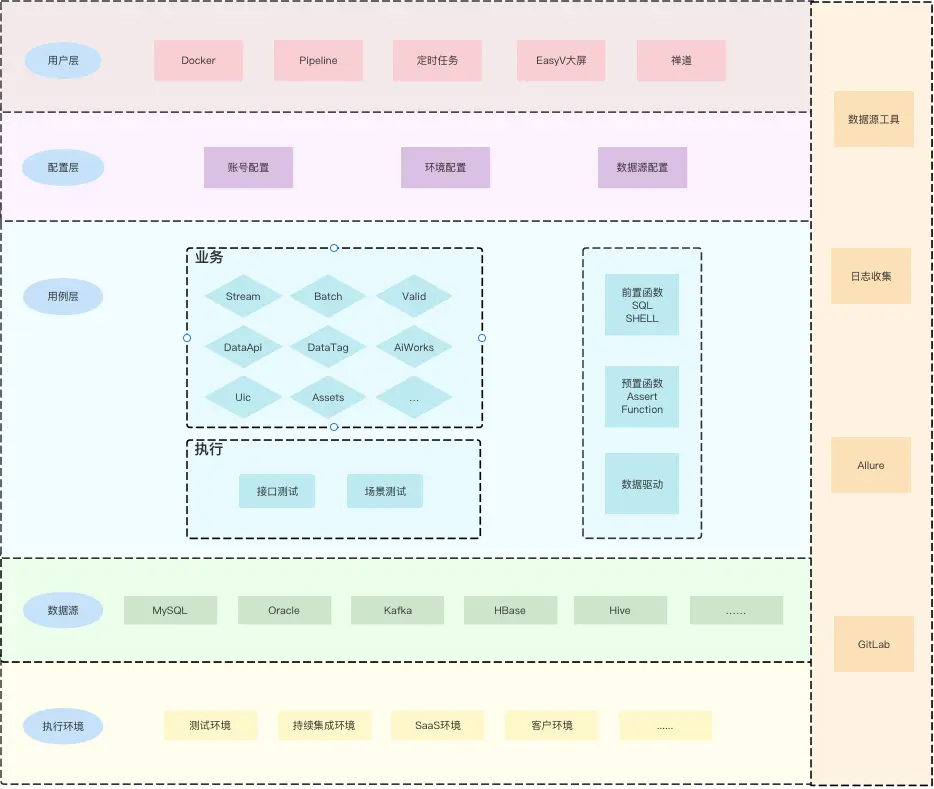
数栈整体自动化测试架构如下图所示。从上到下可分为用户层、配置层、用例层、数据源。用户可以通过Docker镜像、Pipeline、定时任务来触发自动化任务。运行的结果记录到禅道,然后通过接入自研的EasyV进行展示。配置文件分为两类:一类是应用系统信息,如业务数据库信息、域名、账号密码等;另一类是数据源信息,用于用例的执行,现在支持的数据源有MySQL、Oracle、Kafka、HBase等等。从业务层面分,可以分为8个产品,每个产品编写各自的用例;从执行层面分,可分为接口测试和场景测试。若选择接口测试,则会运行所有产品的接口测试用例。下面拿接口测试用例进行举例说明。
一条接口测试用例可分为两部分:配置和测试步骤。先来看配置:
config = (
Config("测试创建项目接口")
.variables(
**{
"cookie": Cookie().get_cookie(),
"url": api.aiworks.aiworks_api.AiworksApi.create_project.value,
"tenant_name": ENV_CONF.uic.tenant_name,
"project_name": project_name
}
)
.base_url(ENV_CONF.base_url.rdos)
)首先第一个遇到的问题就是获取cookie。基本上接口都需要cookie或者token校验才能调用,因此将获取cookie的方法抽象提取成一个get_cookie(),避免了每个用例写一遍登陆。这个方法就属于架构图中预置函数的模块。url、tenant_name、project_name三个变量是后续测试步骤中所需要用到的变量值,这些都预先在variables中定义好。其中还可以看到有AiworksApi、ENV_CONF这几个文件。AiworksApi是所有Aiwork产品的接口枚举类,对接口内容进行管理;ENV_CONF包含了整个自动化项目的配置信息,是一个配置文件,属于配置层。
teststeps = [
Step(
RunRequest("开始请求创建项目接口")
.post("$url")
.with_headers(**{"cookie": "$cookie"})
.with_json(
{
"enableCycleSchedule": "$enableCycleSchedule",
"isSwitchJupyter": "$isSwitchJupyter",
"projectAlias": "$projectAlias",
"projectDesc": "$projectDesc",
"projectEngineList": "$projectEngineList",
"projectName": "$projectName",
"switchGpu": "$switchGpu"
}
)
.validate()
.assert_equal("status_code", 200)
.assert_equal("body.code", "$code")
.assert_contains("body.message", "$message")
.teardown_hook("${delete_project()}")
)
]然后在测试步骤部分,整个teststeps由Step数组构成。可以看到创建项目这个接口只有一个Step,整个Step分为post、with_headers、with_json、validate、teardown_hooke5个部分组成。其中,with_json中key-value键值对的值全都是引用的方式来取得,而不是写死的固定值。这样就可以将用例与数据区分开来。而具体的值则通过@pytest.mark.parameterize这个装饰器传入,params里定义了这个用例所需的所有字段值。整体用例编写思路为“用例与数据分离”,避免修改测试用例需要改动大量的代码。
@pytest.mark.parametrize("params", params)
def test_start(self, params):
super().test_start(params)所以整体来看,HttpRunner框架提供了一个用例模版--由多个关键字组成,使用者只需要将模版中的内容填充完整,就可以完成一条用例的编写。
五、自动化成果
自2021年4月自动化立项以来,已编写超过900条用例,8个子产品接口覆盖率平均达到60%以上。每日通过Jenkins构建定时任务,在持续集成环境对最新的代码进行自动化测试。同时,自动化测试接入了测试环境、客户环境中使用。在提供环境信息完备的情况下,可以随时接入自动化,并运行得出报告给到QA,大大减少了回归工作量,从原先3-4周的时间缩短到1-2周完成。
![]()
作为一位过来人也是希望大家少走一些弯路,希望能对你带来帮助。(WEB自动化测试、app自动化测试、接口自动化测试、持续集成、自动化测试开发、大厂面试真题、简历模板等等),相信能使你更好的进步!
留【自动化测试】即可:【自动化测试交流】:574737577(备注ccc)![]() http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=Af5vb8Yd04Vko7N1pLyynmp07ZePYHSQ&authKey=ks61fFogMnCB2Mw40a8gAbIgAW0iXxiu3fEp%2BsUtanTrM%2F8aJ4pzu%2B74Fo%2Fp%2Fd8G&noverify=0&group_code=574737577
http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=Af5vb8Yd04Vko7N1pLyynmp07ZePYHSQ&authKey=ks61fFogMnCB2Mw40a8gAbIgAW0iXxiu3fEp%2BsUtanTrM%2F8aJ4pzu%2B74Fo%2Fp%2Fd8G&noverify=0&group_code=574737577