JMeter分布式压测

为什么要做分布式部署?
在上一篇文章中,我们提到了JMeter的线程启动和运行,是会占用系统资源的,一旦需要大并发,而JMeter单机部署配置不够,将会导致JMeter无法在规定时间内启动对应的线程数,无法对服务器产生预期的压力,最终影响到性能测试的结果。
为了解决单机部署JMeter产生的这类问题,我们引入了JMeter分布式部署。
JMeter分布式原理
JMeter分布式的实现,其实是在多台上机器部署java和JMeter。
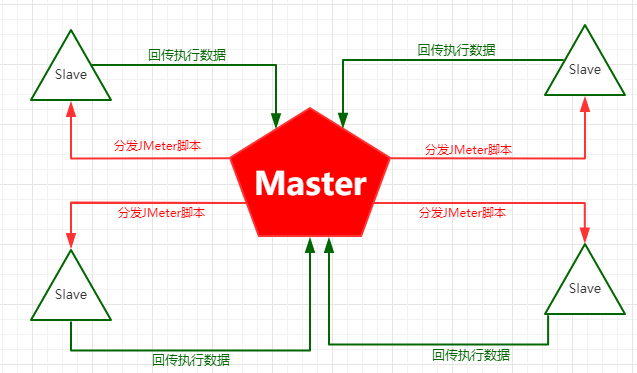
其中有一台机器叫做控制机,我们称之为Master,主要用于JMeter脚本分发和收集汇总Slaves的测试结果。
其他机器叫做压力机,或者叫负载机,我们称之为Slaves,数量可以是1台或多台,主要用于执行JMeter脚本并将结果反馈给Master。
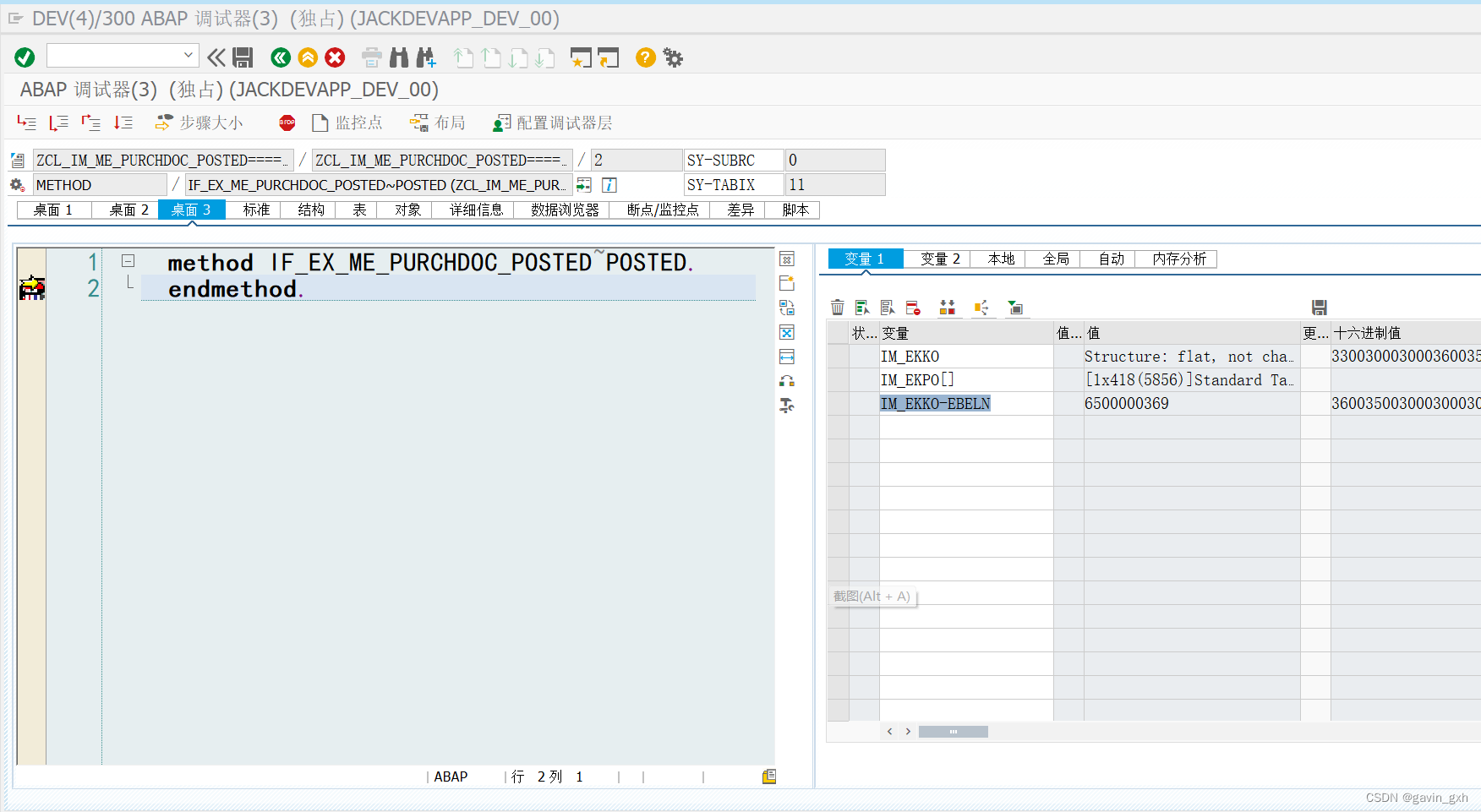
我们来看下Master和Slaves的运行过程:
-
Master运行时,会把JMeter脚本,分发给其他Slaves。
-
Slaves获取到脚本后,会以命令行的方式,运行JMeter脚本,并把执行产生的数据回传给Master。
-
Master汇总收集所有Slaves运行的结果。
我们来看下下面这张图,能够帮助我们理解这段话:
JMeter分布式环境搭建
搞清楚了JMeter分布式的原理,接下来我们来看下JMeter分布式环境搭建的具体步骤:
假设有3台机器:
Master: 10.0.0.1
Slave1: 10.0.0.2
Slave2: 10.0.0.3
-
Master配置
在Master上安装JMeter,并修改jmeter.properties文件的remote_honsts,如下图所示,端口(server_port)如果不冲突,可以不用改,用默认的1099即可:
-
Slave配置
1. 在Slave上安装JMeter,并修改jmeter.properties文件配置,如下图所示:

注意:
1. 端口如果没有被其他应用程序占用,可以不用修改server_port。
2. remote_hosts不用改。
2. 启动JMeter/bin目录下的jmeter-server。
jmeter -n -t test.jmx -l test.jtl -e -o test_report
-
以上配置完成后,我们就可以在Master上执行以下命令运行我们的脚本进行性能测试了:
以上就是JMeter分布式的运行原理和搭建步骤,接下来我们来了解下参数化。

JMeter参数化
为什么要做参数化
讲参数化之前,我们先来思考一个问题,为什么要做参数化?
原因主要有以下两点:
-
缓存
-
缓存的作用是为了提高数据的处理效率而设置的,比如某个用户频繁重复获取某一个商品的信息,有极大可能就是访问的缓存的数据,这种场景和实际的线上场景显然是不符合的。
-
而线上实际场景可能是多个用户获取多个不同的商品信息,这时候很大可能不是访问的缓存数据。
-
而cpu读取缓存的速度会比不读取缓存的速度快很多,这样会让性能测试结果和线上的实际运行情况不符合。
-
-
业务的需要
-
举个实际的例子,比如买车票,同一天同一车次,一个人只能买一张,这个时候如果不对用户做参数化,就会导致购票失败
-
JMeter参数化
JMeter参数化有很多种,这里介绍下常用的3种方式:
以用户登录的请求参数:phone(手机号),password(密码)为例
3. Function Helper(函数助手)中的函数:如__CSVReader,__Random等
-
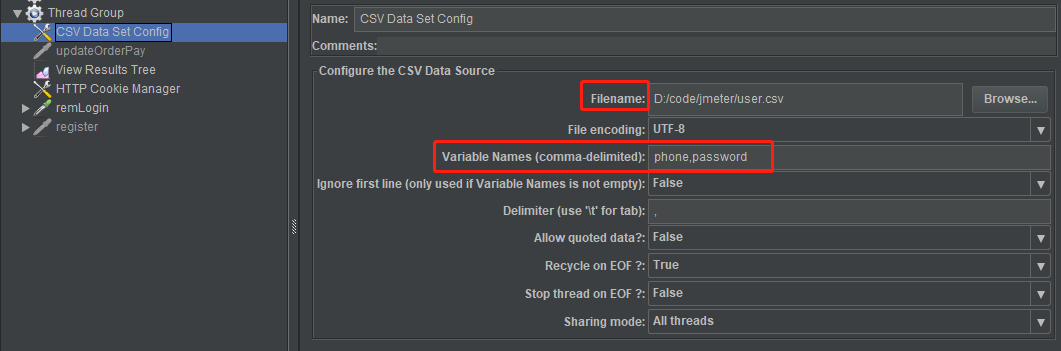
CSV Data Set Config组件:将参数放在txt或者csv文件中
-
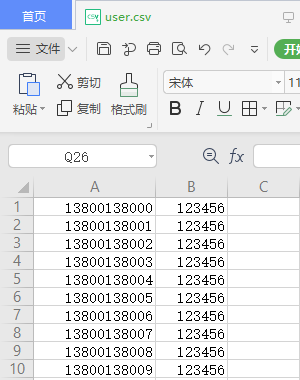
新增一个存放参数化数据的文件:user.csv
-
添加一个csv Data Set Config
-
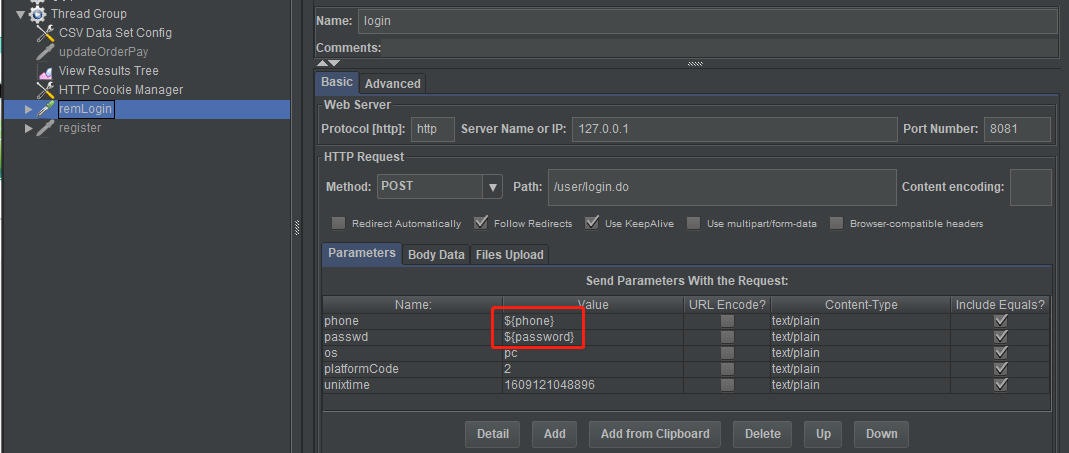
在HTTP Requests里使用参数:
-
-
User defined variable: 通常用来配置脚本公共的参数,比如域名,端口号等
-
新增一个config element - User defined variable组件:
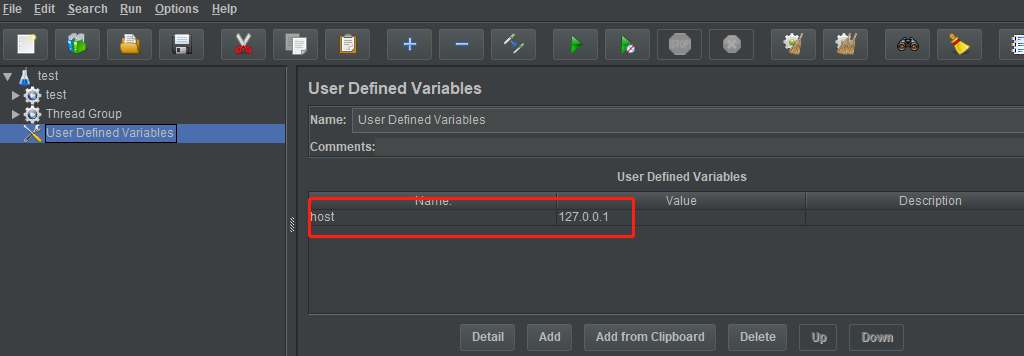
-
在HTTP Requests里使用:
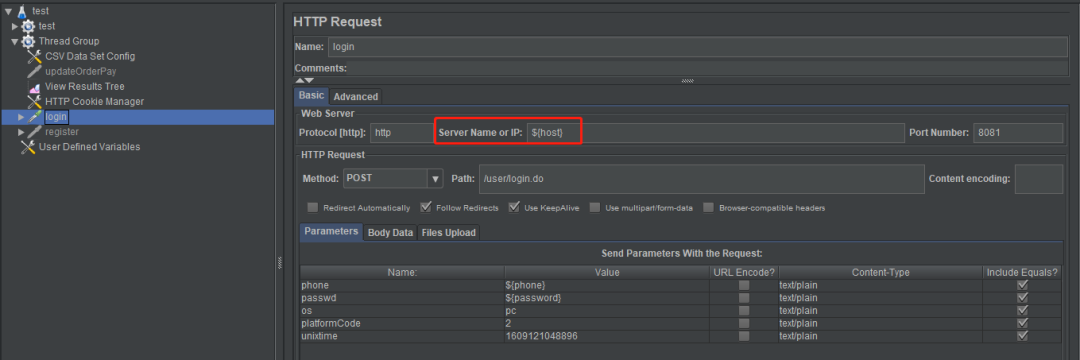
-
__Random可用于生成随机数,用法:
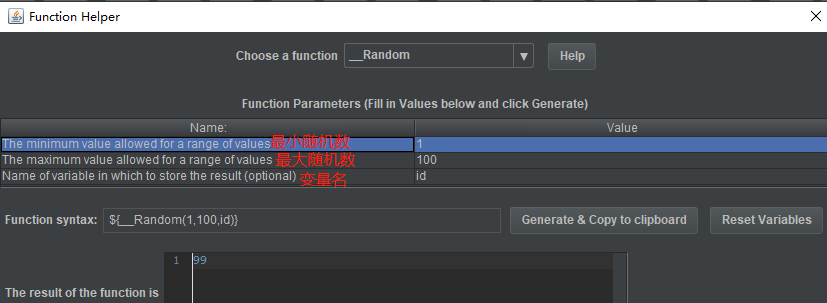
-
__CSVRead可用于读取文件,用法:
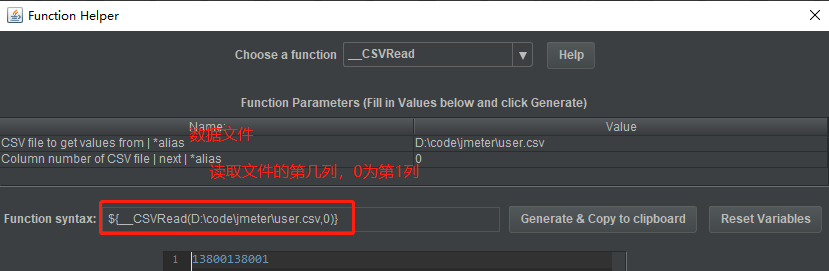
-
如果文章对你有帮助,记得点赞,收藏,加关注。会不定期分享一些干货哦......
END配套学习资源分享
最后: 为了回馈铁杆粉丝们,我给大家整理了完整的软件测试视频学习教程,朋友们如果需要可以自行免费领取 【保证100%免费】
加入我的软件测试交流qq群:110685036免费获取~(同行大佬一起学术交流,每晚都有大佬直播分享技术知识点)软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
全套资料获取方式: