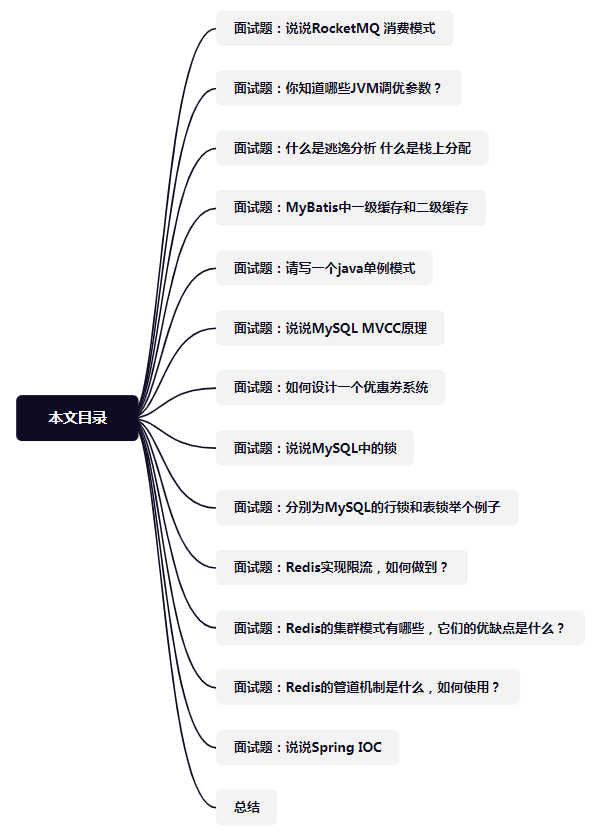
文章目录
- Representation Learning
- Inferring structure(推断结构)
- Transformation prediction
- Rotation prediction
- Relative transformation prediction
- Reconstruction
- Denoising Autoencoders
- Context encoders
- Colorization
- Split-brain encoders
- Instance classification
- Exemplar ConvNets
- Exemplar ConvNets via metric learning
- InfoNCE 损失函数
- Contrastive predictive coding (CPC)
- Exploiting time
- Watching objects move
- Tracking by colorization
- Temporal ordering
- Multimodal
- Bag-of-Words (BoW)
- Audio-visual correspondence
- Leveraging narration
来自Manolis Kellis教授(MIT计算生物学主任)的课《人工智能与机器学习》
主要内容是表示学习(Representation Learning)的part1----Pretext Text(代理任务/前置任务/辅助任务等等),可以理解为是一种为达到特定训练任务而设计的间接任务。
包括这几个部分:推断结构、转换预测、重构、利用时间、多模态、实例分类(对应英文见目录)
下面贴出油管链接:
Generative Models, Adversarial Networks GANs, Variational Autoencoders VAEs, Representation Learning
Representation Learning
Representation Learning: Pretext tasks, embedding spaces, knowledge representation, next word prediction, image placement prediction, Variational AutoEncoders.
表示学习:这是一种机器学习方法,目的是自动识别更好的方式来表示输入数据到学习算法。这个想法是,如果给出正确的数据表示,下游任务(如分类或回归)应该变得更容易。
假设任务:在自监督学习中,假设任务被设计为辅助任务,其中模型从无标签数据中学习丰富的特征表示,然后可以用于主要任务。假设任务的例子是预测句子中的下一个单词,图像完成,或黑白图像的着色。
嵌入空间:这些是高维向量空间,其中相似的对象靠得很近,不同的对象离得很远。它们经常用于表示分类变量或离散对象,如单词(在Word2Vec或GloVe中),句子(在Sentence-BERT中),甚至图(在图神经网络中)。
知识表示:这是人工智能领域的一部分,专注于以计算机系统可以用来解决复杂任务的形式表示关于世界的信息,例如诊断医疗状况或使用自然语言进行对话。它包括动作、时间、因果关系和信念等的表示。
下一个单词预测:这是语言建模的一个任务,其中模型预测给定前面单词的句子中的下一个单词。它常用于训练深度学习模型,如变形金刚(如GPT-3或GPT-4),目标是预测序列中的下一个标记。
图像位置预测:这可能是一个任务,目标是基于某些上下文预测图像的正确位置或排列。例如,给定一个缺少一个面板的漫画系列,任务将是预测缺失面板的正确位置。这种任务需要很好地理解视觉叙述和上下文。
变分自编码器(VAEs):这些是使用神经网络进行复杂,难以处理的概率模型的有效贝叶斯推理的生成模型。VAEs有一种特定的架构,允许它们生成新的数据,这些数据类似于训练数据。它们对于如异常检测、去噪和生成新样本等任务特别有用。

深度学习是一种用于理解和学习数据表示的强大框架。其关键思想是表示学习,即将原始数据转化为更有意义的形式,更容易用于任务,如分类。
- 一种常用的深度学习模型是卷积神经网络(CNNs),这种模型经常被用于图像分类任务。一个典型的CNN包括多个层,如卷积层、ReLU(线性整流单元)激活层、池化层和全连接层。
- 在卷积层,模型通过卷积运算从输入图像中提取特征,即局部感受野内的图像像素间的交互。
- ReLU激活层将所有的负值设为0,以引入非线性。
- 池化层(如最大池化)则用于降低模型的空间尺寸,增加模型的健壮性和计算效率。
- 全连接层在网络的最后,作为分类器对前面提取的特征进行分析,输出预测结果。
深度学习与传统神经网络的主要区别在于它将特征提取和分类两个任务结合在一起:分类任务驱动特征的提取。这是一种极为强大和通用的模型,但我们仍然需要不断创新,因为这个领域仍然处于其发展的初期。
新的应用领域(比如超越图像的领域)可能具有当前架构无法捕获或利用的结构。例如,基因组学、生物学和神经科学可能有助于推动新架构的发展。
当我们说新的应用领域可能具有当前架构无法捕获或利用的结构时,这就好像你有一个超级先进的工具箱,里面有各种锤子、螺丝刀、扳手等工具,这些工具在修理家具或汽车时可能非常有效。但是,如果现在你面临的挑战是烹饪一顿美味的晚餐,那么你可能需要一些全新的工具,比如锅、刀和烤箱,而这些工具可能还不在你的工具箱里。
同样,我们当前的深度学习架构(例如卷积神经网络或循环神经网络)在处理图像、音频和文本数据时表现得非常出色。然而,当我们尝试应用深度学习到新的领域,比如基因组学(DNA序列分析)、生物学(如蛋白质结构预测)或神经科学(如脑波分析)时,我们可能会发现我们现有的工具并不完全适合。我们可能需要发展新的深度学习架构,这些架构能够更好地理解和利用这些领域的数据结构。
举个例子,一个DNA序列可以看作是一个长字符串,由四种基因(A,T,C,G)组成。虽然我们可以使用类似于处理文本的方法来处理这种数据,但DNA序列具有一些特殊的结构和属性(比如三个基因编码一个氨基酸),这些特性可能无法被当前的深度学习架构充分利用。因此,我们可能需要开发新的架构,特别是为了捕捉和利用这些特性。

- 无监督学习中的表示学习
- 如何在没有标注数据的情况下从数据中学习有用的表示。
- 预测未来:例如使用递归神经网络(RNN)或在视频序列中预测下一帧。在这种设置中,未来的预测成为一种学习数据表示的方式。
- 压缩:自编码器是一种试图通过低维表示(称为潜在空间)来重建其输入的神经网络,因此也可以看作一种压缩。
- Pretext任务:这是一种构造任务,目的是推动有用表示的学习,而不是直接解决我们关心的任务。例如,预测图像中缺失的部分,预测图像的旋转角度,颜色化黑白图像,上采样低分辨率图像等。
- 捕获参数分布(变异):变分自编码器(VAEs)试图学习输入数据的潜在概率分布,使得通过这个分布采样的潜在表示可以生成类似于输入数据的新数据。
- **使潜在空间参数有意义:**潜在空间的设计可以使每个维度都有具体的意义,可以是正交的,显式的,或可调的。
- **使用第二个网络进行训练:**生成对抗网络(GANs)包含一个生成网络和一个判别网络,通过两者的对抗训练,生成网络能够生成越来越好的假数据。
- **无限可能:**以上只是现有的一些方法,这个领域还有无限的可能等待我们去探索。你的创新想法可能会开辟出新的道路。
总的来说,这段话的主题是通过无监督学习或自监督学习在没有标注数据的情况下进行表示学习。这种学习方法为我们提供了一种强大的工具,能够从大量的未标注数据中学习有用的知识。

本文所讲的是Pretext任务
在深度学习领域,自我监督学习是一种无监督学习的形式,其中训练信号(也就是标签)是从输入数据本身生成的,而不是由人工提供。这种方法的目标是学习良好的数据表示,而不关心代理任务的结果。
代理任务是自我监督学习的一种实现方式,通过构建一种任务,这种任务可以从输入数据本身获取监督信号。实际上,我们并不关心代理任务本身的结果,我们关心的只是它是否能促使模型学习出有用的数据表示(比如真正的识别出照片里是个猫)。
代理任务可以大致分为以下几类:
- **推断结构:**这类任务要求模型从输入数据中推断出某种结构或模式。
- **转换预测:**这类任务要求模型预测数据的某种转换,例如旋转、翻译或缩放。
- **重构:**这类任务要求模型重构其输入,通常在某种转换(如添加噪声)之后。自编码器就是这类任务的例子。
- **利用时间:**在这类任务中,模型需要理解数据的时间顺序或者预测未来的事件。例如,在自然语言处理中,模型可能需要预测下一个词。
- **多模态任务:**这些任务涉及到多种类型的数据,例如图像和文本,目标是学习跨模态的表示。
- **实例分类:**这是一种特殊类型的任务,其中每个数据实例都被视为自己的类别。
需要注意的是,这只是一种对代理任务的大致分类,有些任务可能会符合多个类别。

Inferring structure(推断结构)



- 上下文预测: 这是一种自我监督学习方法,在此方法中,模型学会从输入的其他部分预测输入的一部分。这是一种理解图像中对象部分或特征的有用方法。然而,这种方法假设训练图像是以规范(标准)的方向拍摄的,这可能并非总是真实的。
- 上下文预测的缺点: 上下文预测有一些问题。
- 首先,它假设所有的图片都是从一个规范的方向拍摄的,这可能并不符合现实。比如拍云的时候,并没有一个规范方向。
- 用patch(小部分)去训练,却想学习整体的表示。
- 其次,这些模型通常会"作弊",通过使用在测试时无法使用的提示,因此在设计这些模型时需要特别小心。由于数据分布的差异,以及可能在训练中缺乏细粒度的区别,训练和评估之间存在差距。
- 如果分类器没有用来自其他图像的负例(不尝试识别的例子)进行训练,可能会有局限性。例如,如果没有负面的例子,它可能无法区分猫眼和狗眼。
- 输出空间较小: 这似乎是指模型预测的类别或情况数量有限的问题。在这个例子中,模型可能只能区分8个不同的位置,这可能限制了模型的有效性。
以下这些是因为我个人听的有点抽象,提出的一些问题和gpt4的解答,可以跳过。其实就是表示学习是自动学到了很多的表示(特征),但是这个特征更加的高级,比机器学习里人一个个去造特征要有潜力的多
Unsupervised visual representation learning by context prediction
无监督视觉表示学习的基本概念:无监督视觉表示学习通过上下文预测是一种自我监督的学习方法,其目标是使机器学习模型从输入的未标记图像中学习有用的表示方法。这种学习方法通过预测图像中的上下文来实现,通常是通过预测图像的一部分来理解图像的其他部分。
举一个简单的例子来说明这个概念:
假设你有一张照片,上面是一只猫正在玩一个球。我们把这张照片切割成几个部分,然后随机地把其中一个部分移除,我们的任务就是预测被移除的部分应该是什么。
在这个任务中,模型需要理解各种上下文线索,比如猫的形状,球的颜色和形状,以及它们在图像中的相对位置。通过这种方式,模型可以学习到猫和球的视觉表示以及它们的空间关系。这样,即使在测试时遇到新的猫或球的图片,模型也能根据已经学习到的表示来理解和分类它们。
这就是无监督视觉表示学习通过上下文预测的基本概念。注意,这是一种自我监督的学习方法,也就是说,它不需要人工标签就可以学习,因此可以处理大量的未标记数据。
- 第二个问题 表示空间
“表示空间”在机器学习中通常指的是模型对输入数据的内部表示。在CNN中,卷积层和池化层(如果有的话)处理输入图像,并生成一个复杂的特征图。这个特征图就是输入图像在模型中的表示。这些表示编码了图像的很多信息,如颜色、纹理、形状等。
在无监督视觉表示学习中,模型的目标就是找到一种表示方法,使得这种表示对于预测任务(如上下文预测)最有帮助。在这种情况下,我们希望模型的表示空间可以捕捉到图像中的重要特征和结构。
以CNN为例,比如说我们用上下文预测任务来训练一个CNN。在训练过程中,CNN的卷积层会学习到如何提取图像中的有用特征,这些特征会被编码在特征图(即表示空间)中。在经过训练之后,CNN应该能够生成对于上下文预测任务有用的表示。
这就是无监督视觉表示学习和表示空间之间的关系。在无监督学习中,我们的目标就是找到一种能够对预测任务有用的表示方法。
- 第三个问题 怎么量化表示空间
表示空间是可以量化的。在卷积神经网络(CNN)中,表示空间通常指的是网络中一层或多层的输出,这些输出是一种对原始输入(如图像)的编码或表示。这些表示通常是具有许多维度的数值向量,因此是可以量化的。
具体到一个新的图像,表示空间是这样工作的:
- 首先,新的图像被输入到经过训练的CNN中。
- CNN的卷积层会开始处理图像,每一层都会提取出图像的一些特征。早期的层可能会提取出一些基本的特征,如边缘和颜色,而更深的层可能会提取出更复杂的特征,如对象的部分或整体。
- 这些提取出的特征就构成了新图像在模型中的表示,也就是在“表示空间”中的点。这些表示通常会被送入全连接层或其他类型的层进行进一步处理,以完成最终的预测任务(如分类)。
举个例子,假设你有一个用于区分猫和狗的CNN。你给它输入一张新的猫的图片。CNN的卷积层会提取出图片中的各种特征,并生成一个表示。这个表示捕捉了图片中的很多关于猫的信息,如它的形状、颜色、纹理等。然后,这个表示被送入全连接层,全连接层根据这个表示预测出“猫”的标签。这就是表示空间在处理新图像时的作用。
- 拼图问题:更加复杂

Transformation prediction
Rotation prediction
- 预测图像要旋转多少度,模型被训练去预测图像被旋转了多少度

首先,图像被随机旋转一个角度(例如90°、180°、270°),然后输入到神经网络(例如ConvNet)中,模型的任务就是预测这个旋转角度。这个过程可以通过分类损失(Classification Loss)进行优化,因为这实际上是一个4类分类问题(假设我们只考虑0°、90°、180°、270°这四种旋转)。
优点:
- 很简单就可以实现,且效果相当好。
缺点:
- 假设训练图像都是用标准的方向拍摄的(而且存在标准的方向)。
- 训练-评估差距:评估阶段没有旋转的图像。
- 由于没有来自其他图像的负例,精度不够细致。例如,没有必要区分猫和狗。
- 输出空间小 - 只有4种情况(旋转)需要区分,增加类别并不容易。
- 在某些领域,这种方法可能过于简单,例如在街景图像中,只需要识别天空就可以了。
需要注意的是,虽然这种方法有其局限性,但是它提供了一种简单且有效的方式来在没有标签的情况下学习视觉表示,这对于大规模的未标记数据集来说非常有用。
- Q:什么是自监督学习
- A:这种从输入数据本身生成标签的方法被称为自监督学习(Self-supervised learning)。自监督学习是无监督学习的一种形式,它通过设计一种任务(比如预测图像的旋转角度)使得模型可以从输入数据本身得到监督信号。这种方式不需要手动标记的标签,这是它的主要优点,因为手动标记大量数据通常需要大量的时间和资源。
- 在“旋转预测”的例子中,模型的目标是预测图像被旋转的角度。这个角度就是从输入数据本身得到的标签。通过这种方式,模型可以在没有人工标签的情况下学习有用的视觉表示。这就是自监督学习的基本概念。
- 那前面的上下文预测的标签是从哪里来的
- 在上下文预测的自我监督学习任务中,标签同样是从输入数据本身生成的。具体如何生成标签,取决于你使用的具体的上下文预测任务。
- 以一种常见的上下文预测任务为例——预测图像中丢失的部分。在这个任务中,你首先选择图像的一部分作为输入,然后选择图像的另一部分作为你要预测的目标。这个目标就是你的标签。例如,你可能会随机选取图像的左半部分作为输入,然后用右半部分作为目标。在这种情况下,右半部分的图像就是你的标签。
- 需要注意的是,这只是上下文预测任务的一种可能的形式。有许多不同的方式可以设计这样的任务,取决于你具体的目标和你的数据。但是在所有这些情况下,标签都是直接从输入数据本身生成的。这就是为什么这种学习方法被称为自我监督学习。
Relative transformation prediction
- 相对变换预测,一种自我监督学习策略,用于估计两幅图像之间的转换。这种方法通常需要有良好的特征提取。

在这种方法中,模型的目标是估计从一幅图像变换到另一幅图像的过程。假设我们有两幅图像x和t(x),其中t(x)是x经过某种变换(如旋转、缩放等)后的图像。模型会首先提取这两幅图像的特征,记为E(x)和E(t(x)),然后预测从E(x)到E(t(x))的变换。
-
优点:
- 与传统的计算机视觉方法相吻合,例如,SIFT(尺度不变特征变换)就是为了图像匹配而开发的。
-
缺点:
-
训练-评估差距:评估阶段没有变换后的图像。
-
由于没有来自其他图像的负例,精度不够细致。例如,没有必要区分猫和狗。
-
对于语义和低级特征的重要性有疑问(假设我们关注的是语义)。
- 特征对于变换可能不是不变的。
-
Reconstruction
重构,破坏原来的一部分,重新去学习预测
Denoising Autoencoders
一种基于重构的自我监督学习方法,即使用去噪自编码器(Denoising Autoencoders)。去噪自编码器是一种特殊的自编码器,它接受一种带有噪声的输入信号,然后试图重构原始的、未被噪声污染的信号。

去噪自编码器包括两个部分:编码器(Encoder)和解码器(Decoder)。编码器将输入信号编码为一个中间的表示,然后解码器将这个表示解码回原始的信号空间。通过最小化重构损失(Reconstruction Loss)——即解码器输出和未被噪声污染的原始信号之间的差异,去噪自编码器可以被训练成从带噪声的输入中提取出有用的特征(represention)。
例如,去噪自编码器可以用来提取手写数字图像中的有用特征。即使图像被噪声污染,例如图像中添加了一些随机的像素,去噪自编码器仍然可以学习到如何从带噪声的图像中提取出有关手写数字的有用信息。
-
优点:
-
去噪自编码器是一种简单的、经典的方法。
-
除了能够学习有用的表示,我们还可以免费得到一个去噪器。
-
-
缺点:
-
训练-评估差距:在带噪声的数据上进行训练。
-
这个任务可能过于简单,可能无需理解语义——低级别的线索可能就足够了。
-
去噪自编码器是自我监督学习中的一种有效方法,尽管它可能对一些复杂的、需要深入理解语义的任务来说过于简单。然而,这种方法仍然非常有用,尤其是在需要去噪或者恢复被噪声污染的信号的场合。
Context encoders
另一个版本的重构器

最有效的预测方法,就是你能够理解这是个啥
“上下文编码器”(Context Encoders)。上下文编码器尝试预测图像中被遮挡或者缺失的部分。这个方法在自然语言处理领域也很常见,例如word2vec和BERT模型中的掩码语言模型任务。
在这个方法中,模型的输入是一部分被遮挡或者缺失的图像,模型的任务是预测被遮挡或者缺失的部分。这通常需要模型能够理解图像的上下文信息,因为只有理解了图像的上下文,模型才可能预测出被遮挡或者缺失的部分可能是什么。
例如,如果一个图像显示了一只大象,但是大象的一部分被遮挡了,如果模型理解了这是一只大象,那么它可能就能准确地预测出被遮挡的部分是什么。

-
优点:
-
需要保留细粒度的信息。
-
重构+感知损失:可以用来训练模型更好地理解图像。
-
-
缺点:
-
训练-评估差距:在评估阶段没有遮挡。
-
重构任务可能过于困难和模糊。
-
在“无用”的细节上花费了大量的努力,比如精确的颜色、好的边界等。
-
虽然上下文编码器可能需要处理一些复杂和模糊的任务,但它们提供了一种强大的方式来学习理解图像上下文的表示,这对于许多计算机视觉任务来说是非常有价值的。
Colorization

图像颜色重构任务的一个总结。在这个任务中,模型接收一张灰度图像作为输入,然后尝试预测出原始的彩色图像
在这个过程中,编码器(Encoder)首先将输入的灰度图像编码为一个中间的表示(Representation),然后解码器(Decoder)尝试从这个表示重构出彩色的图像。重构的好坏通过重构损失(Reconstruction Loss)来衡量,即预测出的彩色图像与原始的彩色图像之间的差异。

- 优点:
- 需要保存细粒度信息,因为模型需要从灰度图像中提取出足够的信息来预测出彩色图像。
- 缺点:
- 重构任务可能过于困难和模糊,因为从灰度图像重构出彩色图像需要模型理解复杂的颜色关系,这在很多情况下是困难的。
- 需要在“无用”的细节上投入大量的工作,例如精确的颜色和良好的边界等。
- 需要在灰度图像上进行评估,这可能会丧失一部分信息,因为灰度图像不包含颜色信息。
Split-brain encoders
这段内容描述的是“上下文编码器”的一种特殊形式,被称为“分脑编码器”(Split-brain Encoders)。在这种模型中,输入的图像被分成两个部分,每个部分分别由模型的一部分处理,然后模型尝试预测其他部分的信息。
例如,可以将彩色图像分解为灰度通道和颜色通道。然后,模型的一个部分处理灰度通道,尝试预测颜色通道,而另一个部分处理颜色通道,尝试预测灰度通道。这样,模型需要学习如何从图像的一部分信息中推断出其他部分的信息。
将二者预测结果融合,得到最终预测结果。

优点:
- 需要保留细粒度的信息,因为模型需要从图像的一部分信息中推断出其他部分的信息。
缺点:
- 重构任务可能过于困难和模糊,因为从图像的一部分信息中推断出其他部分的信息需要模型理解复杂的颜色和亮度关系。
- 需要在“无用”的细节上投入大量的工作,例如精确的颜色和良好的边界等。
- 需要处理输入的不同部分,这可能使得模型更难训练和评估。
Instance classification
**实例分类:**这是一种特殊类型的任务,其中每个数据实例都被视为自己的类别。
Exemplar ConvNets
范例卷积神经网络,一种无监督特征学习方法

范例卷积神经网络的工作方式是:从单个图像中提取多个畸变的剪切(crop),然后让模型判断哪些剪切来自同一原始图像。如果模型能够对期望的变换(比如几何变换和颜色变换)保持稳健性,那么这个任务就相对简单。模型通过对K个“类别”(这里的类别实际上是原始图像)进行分类来实现这个任务。

-
优点:
-
通过此方式学习到的表示能对期望的变换保持不变性。
-
需要保留细粒度信息。
-
-
缺点:
-
选择正确的数据增强方法很重要。
-
作为一种范例(Exemplar)方法,同一类或同一实例的图像是负样本,但没有防止模型关注背景的机制。
-
原始的设计方式并不具备可扩展性(因为“类别”的数量等于数据集的大小)。
-
这种方法的一个关键思想是利用来自同一图像的多个畸变剪切来训练模型对图像中的对象保持稳健性,这也就要求模型能够忽略颜色和几何形状的变化,而专注于识别图像中的物体。
Exemplar ConvNets via metric learning

如何通过度量学习来实现范例卷积神经网络(Exemplar ConvNets)。
原始的范例卷积神经网络有一个可扩展性问题,即“类别”的数量等于训练图像的数量。为了解决这个问题,可以通过度量学习的方式来重塑这个任务。
度量学习是一种方法,目标是学习到数据点之间的距离度量,使得同类别的数据点之间的距离小,而不同类别的数据点之间的距离大。在范例卷积神经网络中,可以使用如对比损失(Contrastive Loss)或三元组损失(Triplet Loss)等传统的度量学习损失函数,也可以使用更近期的 InfoNCE 损失函数。
InfoNCE 损失函数

InfoNCE 损失函数是一种特别流行的版本,被许多最近的方法所使用,如 CPC, AMDIM, SimCLR, MoCo 等。它的工作方式类似于一个排名损失:对于查询(query)和正样本(positive)的组合,应该接近,而对于查询和负样本(negative)的组合,应该远离。在实现上,可以看作是一个分类损失,只不过替换了标签和权重。
图的右侧,上面是传统的分类,可能是one-hot编码,一个非常冗长的向量。二下面是度量学习,就是学习不同样本间的相似性,映射在潜在空间中。
这种方法的一个关键优点是它将范例卷积神经网络的问题重新定义为一个更易于扩展的问题,即学习到的表示能够保留数据点之间的相似度度量。虽然这可能会带来一些新的挑战,如如何选择或生成负样本,但这也为自我监督学习提供了新的可能性。
有点抽象,举个例子
假设我们有一些图片,这些图片是不同种类的狗的照片。我们的目标是,让机器学会区分不同种类的狗,即使它在训练过程中没有见过这种狗的照片。
在原始的范例卷积神经网络中,我们会将每一张狗的照片都视为一个单独的“类别”。然后,我们会从每一张狗的照片中随机剪裁出多个片段,然后让网络去判断这些剪裁片段是否来自同一张狗的照片。这种方法的问题在于,如果我们有非常多的狗的照片,那么我们就会有非常多的“类别”,这使得训练网络变得非常困难。
于是,我们转向度量学习。在度量学习中,我们不再关心每一张狗的照片是否构成一个单独的“类别”。相反,我们只关心不同狗的照片之间是否“相似”。对于每一张狗的照片,我们都会从中随机剪裁出一个片段作为“查询”,然后我们从其他的狗的照片中随机剪裁出其他的片段,其中一些片段来自同一张狗的照片(这些是“正样本”),而另一些片段来自不同狗的照片(这些是“负样本”)。然后,我们训练网络,使得查询和正样本的距离小,而查询和负样本的距离大。
通过这种方式,我们就可以使网络学会如何区分不同种类的狗,即使它在训练过程中没有见过这种狗的照片。因为网络学会的是如何判断狗的照片之间的“相似性”,而不是记住每一张狗的照片。这就是度量学习在范例卷积神经网络中的应用。
Contrastive predictive coding (CPC)
对比预测编码(Contrastive Predictive Coding,CPC)是一种自监督学习方法,主要用于学习无监督数据的有用表示。

CPC 的基本想法是预测数据的未来部分,然后使用对比性损失(比如InfoNCE损失)对预测结果进行训练。在图像处理的场景中,CPC可以从图像的一个区块预测下面的其他区块的表示。然后,它会对预测的表示和实际的表示进行比较,并把这个结果与其他负样本(即其他图像或者同一图像的其他区块)进行对比。这样的目标是要使得网络更好地理解数据的内在结构和上下文信息。
想象我们有一张图片,这是一个大自然的景色,图片上方是蔚蓝的天空,中部是郁郁葱葱的树木,下方是一片湖泊。
在CPC中,我们将这个图像分成三个区域(或者叫做patch),分别是天空、树木和湖泊。然后,我们会选择一个区域,比如说天空,然后试图预测下面的区域(树木)的表示。这个过程被称为“上下文预测”。
接下来,我们使用神经网络生成预测的树木区域的表示,然后和实际的树木区域的表示进行比较,看预测的表示和实际的表示是否接近。同时,我们还会从其他图像(比如说城市风景的图像,上面也可能是天空)中取出一部分作为负样本,看预测的表示和这些负样本是否足够远。
通过这样的训练,神经网络将学习到如何根据一个区域(比如天空)去预测下面的区域(比如树木)。这样,即使在测试阶段,当神经网络只看到天空部分,也可能准确地预测出下面可能是树木,而不是其他的物体,比如建筑物或者海洋。

CPC 的优点包括:
- 它是一个通用的框架,可以应用于图像、视频、音频、自然语言处理等多种领域。
- 它需要保留细粒度的信息,这有助于更好地理解数据的特征。
- 它通过上下文预测,可以帮助网络学习到物体的各个部分。
然而,CPC 也存在一些缺点:
- 它是基于范例的,也就是说,同一类别或者同一实例的图像都会被视为负样本。这可能会影响模型的性能。
- 训练-评估间隙:CPC 在训练时使用的是图像的小块区域(patches),而在评估时使用的是整张图像,这可能导致训练和评估之间存在一定的差距。
- CPC 假设训练图像都是以规范化的角度拍摄的(并且这样的规范化角度存在),这可能会限制它的适用范围。
- 由于需要将图像分成许多小块,所以CPC的训练过程可能比较慢。
Exploiting time
Watching objects move
“观察物体移动”是一种自监督学习的方法,它的主要目标是预测哪些像素会移动。这个过程往往在我们可以将物体分割出来之后变得相对容易

具体来说,网络将从图像中提取特征,并试图预测哪些像素在下一帧图像中会移动。这个预测是以像素为单位进行的,所以这种方法需要像素级的标签。这些标签通常由一个外部的运动分割算法生成。
"观察物体移动"的优点包括:
- 自发的行为:网络可能会自发地学习到物体分割segment的能力(分离出这个物体,理解这个物体的概念),因为知道哪些像素会移动对于理解物体的边界是非常有帮助的。
- 没有训练-评估间隙:在训练和评估阶段,网络都是在进行像素级的预测,一直在训练同时评估,所以不存在训练-评估间隙。
然而,这种方法也有一些缺点:
- “盲点”:对于静止不动的物体,这种方法可能无法正确处理,因为它主要关注的是会移动的像素。
- 可能会过度关注大的显眼物体:大的、显眼的物体往往会产生更多的移动像素,所以网络可能会过度关注这些物体,而忽视了小的或者不太显眼的物体。
- 依赖于外部的运动分割算法:生成像素级标签需要一个运动分割算法,这就导致了这种方法的性能很大程度上依赖于运动分割算法的性能。
- 不能扩展到时间网络:在处理视频数据时,网络需要预测每一帧图像的移动像素,但如果预测的是下一帧图像,那么这个任务就变得很简单,因为下一帧图像大部分内容和当前帧图像是一样的。
Tracking by colorization
"颜色追踪"是一种自监督学习的方法,其主要目标是通过早期帧的颜色信息来给新的帧进行上色。如果所有的物体都能被追踪,那么这个任务就变得相对容易。

具体来说,网络需要从参考帧(已经上色的帧)中提取颜色信息,然后将这些颜色信息用于对输入帧(没有上色的帧)进行上色。这就相当于是在追踪颜色信息在视频中的移动。

"颜色追踪"的优点包括:
- 自发的行为:网络可能会自发地学习到跟踪、匹配、光流和分割等技术,因为这些技术对于正确地从参考帧中提取颜色信息并将其应用到输入帧上是非常有帮助的。
然而,这种方法也有一些缺点:
- 低级别线索很有效:颜色信息是一种非常直接的、低级别的线索,因此网络可能会依赖这些线索进行学习,而忽视了更高级别、更语义化的信息。
- 在灰度帧上进行评估:由于输入帧是没有上色的,因此网络必须在灰度帧上进行评估,这就导致了一部分颜色信息的丢失。
Temporal ordering
"是否按正确顺序排列这组帧序列"是一种自监督学习的方法,其主要目标是判断一组视频帧是否按正确的时间顺序排列。如果我们能识别出视频中的动作和人体姿势,那么这个任务就变得相对容易。

具体来说,网络需要对每一帧进行特征提取,并对这些特征进行分析,从而判断帧序列是否按正确的顺序排列。这就相当于是在追踪动作和人体姿势在时间上的变化。

"是否按正确顺序排列这组帧序列"的优点包括:
- 没有训练-评估间隙:在训练和评估阶段,网络都是在进行序列判断,所以不存在训练-评估间隙。
- 学习到识别人体姿势的能力:由于这个任务的成功解决需要识别出视频中的动作和人体姿势,所以网络在解决这个任务的过程中可能会学习到识别人体姿势的能力。
然而,这种方法也有一些缺点:
- 主要关注人体姿势:这个方法主要关注人体姿势,但是有时候仅凭人体姿势是无法确定帧序列的正确顺序的,因为不同的动作可能会有相同的人体姿势。
- 可扩展性有待商榷:尽管这个方法在处理帧序列时效果不错,但是其是否可以扩展到处理时间序列网络(例如RNN等)尚待商榷,因为在处理时间序列网络时,任务可能会变得过于简单。
此外,这个方法还有一些扩展方向:
- 在N个帧中随机放置一个帧,然后找出这个帧。这就需要网络不仅能判断帧序列的正确性,还能找出不属于这个序列的帧。
- 使用排序损失:网络应该对时间接近的帧生成相似的嵌入,而对时间远离的帧生成不同的嵌入。这就要求网络能够识别出帧之间的时间距离。
Multimodal
Bag-of-Words (BoW)
"Bag-of-Words (BoW)"是一种常用于自然语言处理和计算机视觉的技术,其基本思想是将输入(如一段文字或一幅图像)分解为一组“词”,然后构建一个“词袋”来表示这个输入。
在自然语言处理中,“词”就是文本中的单词,在计算机视觉中,“词”可以是图像中的某个局部特征或者某种模式。

我们首先使用预训练的自监督卷积神经网络对图像进行特征提取。然后,将提取出的特征赋给视觉词汇,形成一种"视觉词袋"。再接着,我们可以对图像进行一些随机的扰动(如旋转、裁剪等),并尝试从扰动后的图像中预测原始图像的“词袋”。
尝试用一个比较通俗的例子来解释这个概念。假设我们有一张包含多种动物的图像,如猫、狗和兔子。
在使用视觉词袋(Bag-of-Words,简称BoW)的方法中,首先,我们需要一个预先训练好的神经网络模型,这个模型能够识别并提取出图像中的特征。比如,在我们这个例子中,神经网络模型可能会识别出猫的特征(如尾巴、耳朵和眼睛)、狗的特征(如鼻子、腿和尾巴)以及兔子的特征(如耳朵和脚)。
这些特征被视为**“视觉词”**,我们把它们全部放进一个"词袋"里,就像我们在做文本分析时,把一个文本中的所有单词都放进一个词袋里一样。因此,无论这些动物在图片中的具体位置如何,或者它们的姿态如何变化,只要这些特征在图片中,我们就可以在词袋中找到对应的"视觉词"。
然后,我们对图像进行一些随机扰动,比如旋转、放大、缩小、裁剪等。接着,我们尝试从这个扰动后的图像中预测出原始图像的视觉词袋。这就需要神经网络模型有强大的学习和推理能力,能够从扰动的图像中,正确地识别出属于原图像的视觉词。
这种方法的一大优点是它可以从不同的角度和尺度去理解和描述图像,而这对于许多计算机视觉的任务,如物体识别、场景理解等,都是非常重要的。但是,这种方法也有一些局限性,比如它无法捕获到图像中的精细特征,以及视觉词之间的相对位置信息。因此,尽管视觉词袋是一个强大的工具,但是在实际应用中,我们通常会结合其他的方法,如卷积神经网络(Convolutional Neural Networks,简称CNNs)等,来进一步提升我们的模型的性能。

这种方法的优点包括:
- 生成的表示对所需的变换具有不变性:也就是说,不管图像如何旋转、裁剪,只要包含同样的“词”,就会生成同样的“词袋”。
- 学习上下文推理技巧:因为需要从扰动后的图像预测原始图像的“词袋”,网络需要学习如何从图像的某部分推理出图像的其他部分。
- 推断缺失图像区域的词:如果图像的某部分丢失或被遮盖,我们也可以通过“词袋”预测出这部分可能包含哪些“词”。
然而,这种方法也有一些缺点:
- 需要从另一个网络进行启动:这个网络无法从头开始学习,必须从另一个已经预训练好的网络启动。
- 对精细特征的学习能力有限:虽然“词袋”方法可以识别出图像中的大体特征,但对于更精细的特征,如颜色、纹理等的学习能力可能有限。
另外,虽然"视觉词袋"是一种有效的特征提取方法,但是由于其丢失了空间信息,例如,特征之间的相对位置信息,这在许多应用中是非常重要的。所以有一种改进方法叫做"空间词袋",即在保留词袋特征的同时,也保留了部分空间信息。
Audio-visual correspondence
"音-视对应"的自监督学习任务是通过将音频与图像结合起来进行的。其目标是根据图像和声音来判断它们是否是匹配的。
让我们以一个简单的例子来说明:假设你有一个视频片段,视频中一个足球被踢出去,然后你听到了一个踢球的声音。在这个例子中,图像和声音是匹配的,因为你在视觉上看到的足球被踢,和你在听觉上听到的声音是一致的。
然而,如果我们把这段视频中的音频替换为一只猫的叫声,那么这个图像和声音就不再匹配,因为你看到的是一个足球被踢,但你听到的却是一只猫的叫声。

在"音-视对应"的任务中,神经网络的目标就是学习这种对应关系。在训练时,网络需要判断输入的图像和声音是否是匹配的。如果匹配,网络应该输出"是";如果不匹配,网络应该输出"否"。[外链图片转存中…(img-pjRJW98E-1686298179749)]

通过这种方式,网络可以学习如何从视觉和听觉的信号中提取有用的特征,并理解这两种信号之间的关联。
这种方法的优点是我们可以同时得到两种模态的表示,而且不需要额外的数据增强方法。
这种方法的缺点是并不是所有的图像都有对应的声音,也就是说,有一些"盲区"是网络无法学习到的。此外,这种方法基于实例的特性使得相同类别或实例的视频成为负样本,这可能会对结果产生影响。
Leveraging narration