你好,我是田哥
面试造火箭工作拧螺丝,最近一位朋友在面试中被问到各种各样的分布式微服务的面试题,也回答上来了。可是,等正式入职后,发现这家公司居然全部是使用单体项目,完全没有分布式微服务的东东,失望至极!
倒不是说进去搞架构设计,你这单体服务面试问俺那么多微服务分布式相关问题有啥用呢?重点是这位朋友还和领导聊过项目的问题,领导却说这个单体能搞定,不需要搞成微服务模式(真想一巴掌呼过去)。
好吧,不说多了,下面来聊聊这位小伙伴在面试中遇到的一些问题。
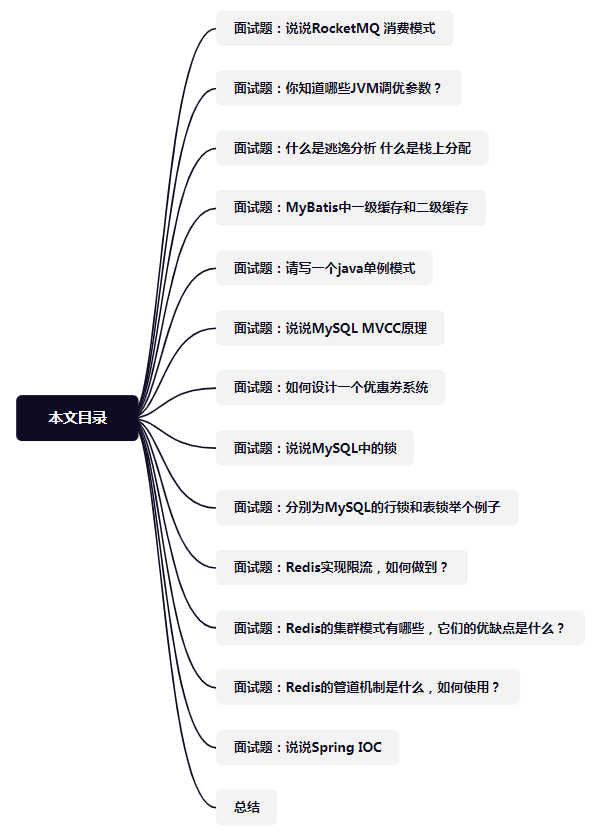
面试题:说说RocketMQ 消费模式
RocketMQ 消息队列的消费模式一般有两种,即集群消费和广播消费。
集群消费(Clustering)
集群消费是指多个消费者同时消费同一个主题(Topic)的消息,每个消息只能被其中一个消费者处理。当消费者组中的某个消费者挂掉后,其它消费者会自动接管该消费者的所有未确认的消息进行消费。这种消费模式适用于并行处理消息的场景。
广播消费(Broadcasting)
广播消费是指多个消费者同时消费同一个主题(Topic)的消息,每个消费者都会消费一遍所有的消息,而不是共同消费所有消息。这种消费模式适用于需要将消息推送给所有消费者的场景,如系统通知。
在实际场景中,可以根据不同的业务需求选择不同的消费模式。
面试题:你知道哪些JVM调优参数?
常见的JVM调优参数包括:
-Xms:设置JVM初始分配的内存大小,如-Xms512m表示初始分配512MB内存。
-Xmx:设置JVM最大可用的内存大小,如-Xmx1024m表示最大可用1GB内存。
-XX:PermSize:设置JVM方法区初始大小,如-XX:PermSize=256m表示初始分配256MB内存。
-XX:MaxPermSize:设置JVM方法区最大可用的内存大小,如-XX:MaxPermSize=512m表示最大可用512MB内存。
-Xmn:设置JVM年轻代的大小,如-Xmn256m表示年轻代分配256MB内存。
-XX:SurvivorRatio:设置JVM年轻代中Eden区和Survivor区的比例,如-XX:SurvivorRatio=8表示Eden区和Survivor区的比例为8:1。
-XX:MaxTenuringThreshold:设置JVM对象进入老年代的年龄阈值,如-XX:MaxTenuringThreshold=15表示对象年龄超过15就进入老年代。
-XX:NewRatio:设置JVM年轻代和老年代的比例,如-XX:NewRatio=2表示年轻代和老年代的比例为2:1。
设置参数大小需要根据具体的应用场景和系统配置来进行调整。一般来说,需要根据应用的内存占用情况和系统的硬件配置来确定合适的参数大小。如果设置过小,会导致频繁的Full GC,影响系统的性能;如果设置过大,会浪费系统的资源。可以通过监控系统的GC情况和内存占用情况来进行调优。同时,也可以通过一些工具来辅助调优,如JVisualVM、JConsole等。
在JDK8中,元空间(Metaspace)是用来存储类信息的区域,它替代了JDK7及之前版本中的永久代(PermGen)。与永久代不同,元空间不再有固定的大小限制,而是根据需要动态地调整大小。以下是一些常见的元空间调优参数:
-XX:MetaspaceSize:设置元空间的初始大小,默认为21MB。
-XX:MaxMetaspaceSize:设置元空间的最大大小,默认为无限制。
-XX:MinMetaspaceExpansion:设置元空间自动扩容的最小值,默认为3MB。
-XX:MaxMetaspaceExpansion:设置元空间自动扩容的最大值,默认为无限制。
-XX:MetaspaceSizeSizeIncrement:设置元空间自动扩容时的增量,默认为12MB。
-XX:MinMetaspaceFreeRatio:设置元空间释放空间后的最小比例,默认为40%。
-XX:MaxMetaspaceFreeRatio:设置元空间释放空间后的最大比例,默认为70%。
需要注意的是,元空间的大小和自动扩容机制是根据应用程序的需要动态调整的,因此需要根据实际情况进行调优。可以通过监控元空间的使用情况和系统的性能指标来进行调优,保证应用程序的稳定性和性能。
面试题:什么是逃逸分析 什么是栈上分配
逃逸分析和栈上分配是JVM的两种优化技术。
逃逸分析 是一种分析技术,用于判断对象的作用域是否超出了方法的范围。如果对象的作用域仅限于方法内部,那么就可以将其分配到栈上,从而避免在堆上分配对象的开销。逃逸分析可以提高程序的性能,减少垃圾回收的开销。
**栈上分配 **是指将对象分配到栈上而不是堆上。栈上分配可以避免在堆上分配对象的开销,从而提高程序的性能。栈上分配的前提是对象的生命周期必须在方法内部结束,否则对象会被强制转移到堆上。栈上分配可以和逃逸分析结合使用,从而进一步提高程序的性能。
需要注意的是,逃逸分析和栈上分配都是JVM的优化技术,不是所有的JVM都支持这些技术。在使用这些技术时需要根据具体的JVM版本和应用程序的特性进行调优。同时,也需要注意不要过度优化,避免出现反效果的情况。
面试题:MyBatis中一级缓存和二级缓存
MyBatis是一种开源的Java持久化框架,它提供了一系列的功能,包括SQL映射、对象关系映射(ORM)、缓存等。MyBatis中的缓存机制包括一级缓存和二级缓存,它们都是为了提高数据库访问效率而设计的。以下是它们的详细介绍:
一级缓存:
一级缓存是指在同一个SqlSession中,对于同一个查询语句,MyBatis会将查询结果缓存到内存中,以便于下一次查询时直接从缓存中获取数据,而不需要再次访问数据库。一级缓存是默认开启的,当执行相同的查询语句时,MyBatis会先从缓存中获取数据,如果缓存中没有数据,则会从数据库中查询数据,并将查询结果缓存到缓存中。
一级缓存的作用域是SqlSession级别的,即同一个SqlSession中的所有操作共享同一个缓存。当一个SqlSession被关闭时,该SqlSession中的缓存也会被清空。如果需要在多个SqlSession之间共享缓存,则需要使用二级缓存。
二级缓存:
二级缓存是指在多个SqlSession之间共享缓存,它可以提高多个SqlSession之间的数据共享和访问效率。二级缓存是可选的,需要在MyBatis配置文件中进行配置。如果开启了二级缓存,则在执行查询操作时,MyBatis会先从二级缓存中获取数据,如果缓存中没有数据,则会从数据库中查询数据,并将查询结果缓存到缓存中。当执行更新、插入、删除等操作时,MyBatis会清空二级缓存中的数据,以避免数据不一致的问题。
二级缓存的作用域是Mapper级别的,即同一个Mapper中的所有操作共享同一个缓存。如果需要在多个Mapper之间共享缓存,则需要使用自定义缓存。
需要注意的是,缓存虽然可以提高数据库访问效率,但是也会带来一些问题,比如数据不一致、缓存过期等问题。
面试题:请写一个java单例模式
Java单例模式是一种常见的设计模式,它可以确保一个类只有一个实例,并提供全局访问点来访问该实例。
以下是一个Java单例模式的示例代码:
public class Singleton {
// 定义私有静态变量instance,用于保存单例实例
private static Singleton instance;
// 定义私有构造函数,防止外部实例化该类
private Singleton() {}
// 定义公共静态方法getInstance,用于获取单例实例
public static Singleton getInstance() {
// 如果instance为空,则创建一个新的单例实例
if (instance == null) {
instance = new Singleton();
}
// 返回单例实例
return instance;
}
}在上述代码中,我们定义了一个私有静态变量instance,用于保存单例实例。由于该变量是私有的,因此外部无法直接访问它。我们还定义了一个私有构造函数,防止外部通过实例化该类来创建多个实例。最后,我们定义了一个公共静态方法getInstance,用于获取单例实例。在该方法中,我们首先判断instance是否为空,如果为空,则创建一个新的单例实例,并返回它。如果不为空,则直接返回现有的单例实例。
需要注意的是,上述代码实现了懒汉式单例模式,即在第一次调用getInstance方法时才创建单例实例。这种实现方式可以避免在程序启动时就创建单例实例,从而节省资源。但是,它可能会存在多线程安全问题,因为多个线程可能同时调用getInstance方法,导致创建多个实例。因此,在实际应用中,我们需要考虑线程安全问题,并采用适当的线程安全措施来保证单例实例的唯一性。
另外,如果在面试中,面试官让你写一个单例模式,最好是问清楚,有什么要求和先关限制条件?
单例模式写法还有:饿汉式单例模式、双重检查锁单例模式、注册式单例模式、枚举式单例模式等。
面试题:说说MySQL MVCC原理
MySQL的MVCC是指多版本并发控制,它是一种并发控制机制,用于在多个用户同时访问数据库时保证数据的一致性和隔离性。MVCC机制是通过在数据库中保存多个版本的数据来实现的,每个版本都有一个唯一的时间戳,以便于事务的隔离和恢复。
MVCC机制的实现原理如下:
每行数据都有一个隐藏的版本号,用于标识数据的版本。
当一个事务对数据进行修改时,MySQL会为该事务创建一个新的版本,并将新版本的版本号与该事务关联。
当其他事务读取数据时,MySQL会根据事务的隔离级别和版本号来判断哪些数据是可见的。
对于读取未提交数据的事务,MySQL会直接返回当前版本的数据,不考虑其他事务的修改。
对于读取已提交数据的事务,MySQL会返回提交时间早于该事务开始时间的所有版本中最新的版本。
对于可重复读和串行化的事务,MySQL会在事务开始时记录当前版本号,并在事务执行期间保持不变,以保证读取的数据版本一致性。
当事务提交时,MySQL会将该事务所修改的数据的版本号更新为事务的提交时间,以便其他事务可以读取到最新的数据版本。
通过MVCC机制,MySQL可以实现高并发的读写操作,并保证数据的一致性和隔离性。但是,MVCC机制也会带来一些额外的存储和计算成本,因为需要保存多个版本的数据和版本号。因此,在设计数据库时,需要根据实际情况选择适当的隔离级别和优化方案,以提高数据库的性能和稳定性。
面试题:如何设计一个优惠券系统
设计一个优惠券系统需要考虑以下几个方面:
优惠券类型:确定优惠券的类型,比如折扣券、满减券、免费券等。
优惠券规则:设置优惠券的使用规则,比如最低消费金额、适用商品、使用时间等。
优惠券发放:确定发放优惠券的渠道和方式,比如通过邮件、短信、APP推送等方式发放。
优惠券使用:设计用户如何使用优惠券,比如在结算页面输入优惠码或者扫描二维码等方式。
优惠券管理:设计优惠券管理系统,包括优惠券的发放、使用、过期等情况的记录和统计。
优惠券反馈:设置用户使用优惠券后的反馈机制,比如评价、分享等。
优惠券营销:设计优惠券的营销策略,比如促销活动、限时抢购等。
在设计优惠券系统时,需要考虑到用户体验和安全性,确保系统稳定、可靠和易于使用。同时,需要根据实际情况不断优化和调整,提高系统的效率和用户的满意度。
面试题:说说MySQL中的锁
MySQL 数据库中,悲观锁、乐观锁、表锁、行锁、页锁是常见的锁定方式。
悲观锁:悲观锁是一种传统的锁定方式,它的核心思想是“先加锁再操作”,即在每次对数据进行读写操作时,都会先对数据进行锁定,以防止其他并发操作对数据的干扰。悲观锁通常使用数据库的锁机制来实现,比如行锁或表锁等。由于需要频繁地加锁和解锁,在高并发的情况下可能会导致性能问题。
乐观锁:乐观锁是一种基于版本号的锁定方式,它的核心思想是“先操作再判断”,即在每次对数据进行读写操作时,会先获取当前数据的版本号,并将其存储在本地。然后在提交更新之前,会先检查当前数据的版本号是否与本地存储的一致,如果一致,则说明没有其他并发操作对数据进行了修改,可以直接提交更新;如果不一致,则说明有其他并发操作对数据进行了修改,此时需要重新获取数据并重试更新操作。
表锁:表锁是对整张表进行锁定的方式。在使用表锁时,会对整张表进行加锁,从而保证同时只有一个事务可以对表进行操作。表锁是一种粗粒度的锁定方式,可能会导致性能瓶颈。
行锁:行锁是对单行数据进行锁定的方式。在使用行锁时,会对要操作的数据行进行加锁,从而保证同时只有一个事务可以对该行数据进行操作。行锁是一种细粒度的锁定方式,可以提高并发性能和吞吐量。
页锁:页锁是对数据页进行锁定的方式。在使用页锁时,会对要操作的数据所在的页进行加锁,从而保证同时只有一个事务可以对该页数据进行操作。页锁是一种介于行锁和表锁之间的锁定方式,可以根据实际情况选择使用。
需要注意的是,在 MySQL 数据库中,不同的存储引擎对锁的支持程度也不同,比如 InnoDB 存储引擎支持行锁和表锁,而 MyISAM 存储引擎只支持表锁。因此,在使用锁定方式时,还需要考虑存储引擎的特点和限制。
面试题:分别为MySQL的行锁和表锁举个例子
MySQL 中的行锁和表锁是两种不同的锁机制,各自适用于不同的情况。
举例来说,当我们需要更新一张表中的某些记录时,可以使用行级锁来避免其他线程同时修改同一行数据,保证数据的一致性和并发性能。
例如:
BEGIN;
SELECT * FROM table WHERE id = 1 FOR UPDATE;
-- 对 id = 1 的行加锁,其他线程无法同时对该行进行修改操作
UPDATE table SET col1 = 'new value' WHERE id = 1;
COMMIT;而当我们需要对整张表进行某些操作时,可以使用表级锁来避免其他线程同时操作该表,保证数据的一致性和完整性。
例如:
LOCK TABLES table WRITE;
-- 对整张表加写锁,其他线程无法同时对该表进行读或写操作
INSERT INTO table (col1, col2) VALUES ('value1', 'value2');
UNLOCK TABLES;需要注意的是,在实际使用中,要根据具体的业务场景和性能需求来选择合适的锁机制和隔离级别,以避免锁竞争导致的性能问题。
面试题:Redis实现限流,如何做到?
Redis可以通过令牌桶算法来实现。令牌桶算法是一种常见的限流算法,它可以通过控制令牌的数量来限制请求的流量,从而保护系统的稳定性和可用性。
令牌桶算法的实现方式如下:
定义一个令牌桶,包含一定数量的令牌。
每当有请求到来时,从令牌桶中取出一个令牌,如果令牌桶中没有令牌,则拒绝请求。
每隔一定时间,往令牌桶中添加一定数量的令牌,使得令牌桶中的令牌数量不超过一定的上限。
在Redis中,可以使用Lua脚本结合Redis的计数器和定时器来实现令牌桶算法。具体实现步骤如下:
使用Redis的计数器来记录当前令牌桶中的令牌数量。
使用Redis的定时器来定期往令牌桶中添加令牌。
在Lua脚本中通过Redis的计数器和定时器来实现令牌桶算法,每当有请求到来时,判断令牌桶中是否有足够的令牌,如果有,则从令牌桶中取出一个令牌,并返回成功;如果没有,则返回失败。
需要注意的是,令牌桶算法可以根据实际情况进行调整,包括令牌桶的大小、令牌的生成速率和请求的处理速率等。在使用令牌桶算法时,需要根据实际情况进行调优,以保证系统的稳定性和可用性。
面试题:Redis的集群模式有哪些,它们的优缺点是什么?
Redis的集群模式有以下三种:
Redis Sentinel模式:Sentinel是Redis官方提供的高可用解决方案,它通过监控Redis主节点和从节点的状态来实现自动故障切换,从而保证Redis集群的高可用性。优点是部署简单,易于管理,缺点是不支持数据分片,性能有限。
Redis Cluster模式:Redis Cluster是Redis官方提供的分布式解决方案,它将数据分片存储在多个节点上,支持自动故障转移和数据重平衡,可以扩展到数百个节点,具有较高的可扩展性和性能。缺点是部署和管理相对复杂,需要考虑数据分片和节点间通信等问题。
Redis Proxy模式:Redis Proxy是一种中间件,它将Redis请求转发到多个Redis节点上,实现了读写分离和负载均衡,可以提高Redis的性能和可用性。优点是部署和管理相对简单,可以与其他Redis集群模式配合使用,缺点是需要考虑代理节点的单点故障问题。
总的来说,不同的Redis集群模式适用于不同的场景,需要根据实际情况进行选择。如果数据量较小,可以选择Sentinel模式;如果需要扩展到多个节点,可以选择Cluster模式;如果需要读写分离和负载均衡,可以选择Proxy模式。
面试题:说说Spring IOC
Spring IOC(Inversion of Control,控制反转)是Spring框架的核心功能之一,它是一种设计模式,用于解耦对象之间的依赖关系。在Spring IOC中,对象的创建和依赖关系的管理都由Spring容器来负责,而不是由对象自己来管理。
Spring IOC的核心是容器(Container),它负责管理对象的生命周期和依赖关系。在Spring中,容器有两种类型:BeanFactory和ApplicationContext。BeanFactory是Spring的基础容器,它提供了基本的IOC功能;ApplicationContext是BeanFactory的扩展,它提供了更多的功能,如AOP、事件机制和国际化等。
在Spring IOC中,对象的创建和依赖关系的管理是通过配置文件或注解来实现的。Spring提供了多种方式来配置对象和依赖关系,包括XML配置、注解配置和Java配置等。配置完成后,Spring容器会自动将对象创建并管理它们之间的依赖关系。
面试题:Redis的管道机制是什么,如何使用?
Redis的管道(Pipeline)机制是一种优化技术,用于提高Redis的性能。管道机制可以将多个Redis命令一次性发送到服务器执行,从而减少网络延迟和通信开销,提高Redis的吞吐量和响应速度。
管道机制的使用步骤如下:
创建Redis的管道对象。
向管道对象中添加需要执行的Redis命令。
一次性发送所有的Redis命令到服务器执行。
从管道对象中获取执行结果。
需要注意的是,管道机制可以提高Redis的性能,但也存在一些限制。例如,由于所有的Redis命令都是一次性发送到服务器执行的,因此如果其中某个命令执行失败,会导致整个管道执行失败。此外,由于管道机制需要占用一定的内存空间,因此在使用管道时需要注意内存的使用情况。
在Java中,可以使用Jedis或Lettuce等Redis客户端库来实现Redis的管道机制。具体实现方式如下:
创建Redis客户端对象。
通过客户端对象创建管道对象。
向管道对象中添加需要执行的Redis命令。
一次性发送所有的Redis命令到服务器执行。
从管道对象中获取执行结果。
需要注意的是,管道机制的使用需要结合实际情况进行调优,以保证系统的稳定性和性能。在使用管道时,需要根据实际情况进行调整,包括管道中命令的数量、管道的大小和管道的超时时间等。
再说几句
其实,面试中,面试官还问了一堆分布式的问题:
CAP理论
分布式锁实现方案有哪些?如何选择?
分布式事务方案有哪些?在实际项目中用过吗?
项目中并发最大的是哪些接口?你们是如何解决的?
还问了一些注册中心的区别?你们为什么使用Nacos?
你们网关用来做什么的?
消息队列为什么使用RocketMQ?你们项目中是如何保证消息不丢失的?
缓存数据一致性问题,你们项目中是怎么做的?为什么这么做?
......
关于分布式事务,我之前有分享过:
实战分布式事务【Seata+Spring Cloud】
Spring Boot+MyBatis+Atomikos+MySQL(附源码)
在我的充电桩项目中,用到了分布式锁 Redisson实现、消息队列 使用RabbitMQ并采用延迟双删来保证缓存数据一致性问题(也不是100%能保证的,毕竟CAP理论的三个条件是无法做到完全满足的,只能选一个相对适合即可)、注册中心和分布式配置中心使用的Nacos......
可以通过下面两篇文章了解充电桩项目内容:
分布式微服务项目实战:充电桩项目
手把手项目实战,搞完,直接写在简历上!
好了,今天就分享这么多。
如果有需要简历修改、简历优化、简历包装、面试辅导、模拟面试、技术辅导、技术支持等,欢迎加我微x(tj20120622)。
个人技术博客可刷题:http://woaijava.cc/
回复77 ,获取《面试小抄2.0版》
回复电子书,获取《后端必读的200本电子书籍》
文章推荐
中厂,面试就问了4道题,凉了!
分布式问题,你知道几个?
应届生,实力已超6年,太卷了!
手把手教你写简历,包装、优化!
面试不问java,问MySQL,如何破局?