说在前面的话
满打满算工作也有三年了,还是没有感觉到自己和刚毕业相比有什么明显的进步。
严格来讲,代码力确实有提升,对各类工具的使用也更加熟练。但是对算法的理解和从0开始编程的能力仍然没有什么长进。归根到底,是因为在工作环境中对已有的repo和懒人神器pytorch-lightning的依赖。
所以今天翻了翻网上的教程,打算重新熟悉一下pytorch。
即使做不了senior的算法工程师,也不能永远做一个数据女工呀。
教程参考:
https://pytorch.org/tutorials/
https://github.com/TingsongYu/PyTorch_Tutorial
https://github.com/yunjey/pytorch-tutorial
本章内容
- cifar 数据介绍
- pickle 数据格式
- 为什么使用pickle
- 怎么使用pickle
- cifar 数据读取
- cifar 文件介绍
- cifar 文件读取与处理
- 读取数据
- 数据集的划分
- 制作图片索引
- pytorch 读取数据
- Dataset的使用
- Dataloader的使用
- map-style and iterable-style dataset
- data loading order and sampler
- loading batched and non-batched data
- single- and multi-process data loading
- memory pinning
cifar 数据介绍
官网地址: http://www.cs.toronto.edu/~kriz/cifar.html
官网上对CIFAR-10数据和CIFAR-100数据进行了简要介绍。
CIFAR10 数据包括十个类别,每个类别各6000张,一共6万张大小为32x32的彩色图片,其中包括5w张训练集和1w张测试集。其中5w张训练集被分为了5个batch,每个包括1w张图片。测试集从每个类别的图片中随机选择了1000张,十个类别共1w张图片。训练集与测试集不重复,测试集中的图片顺序是随机的,但是每个batch中图片的种类分布是不均匀的。各个类别间是完全独立的,比如automobile和truck之间就不存在相同的数据,automobile包括了大轿车sedans,越野车suvs等,而trucks只包括大货车 big trucks。

CIFAR100数据包括100个类别,每个类别各600张,一共6w张图片。每个类别有500张训练图片和100张测试图片。结构上来说和CIFAR10相似。
官网上提供的数据都分为三个版本:python version, matlab version 和 binary version。
我们在此只使用python version。
数据读取的方式参考官网给出的代码样例。
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
pickle 数据格式
教程参考: https://www.datacamp.com/tutorial/pickle-python-tutorial
为什么使用pickle
可以看到,cifar数据是存储为pickle格式的。
python中的pickle模块和其他模块存储的主要区别是pickle模块可以把python对象直接保存到文件里,而且不需要转成字符串再保存。
举例说明:假如我们有一个dict类型的数据
students = {
'student1': {'name':'a', 'age':'b'},
'student2': {'name':'c', 'age':'d'},
}
当我们想保存这个数据,比如保存到txt文件中时
with open('student_info.txt','w') as data:
data.write(str(students))
当我们重新从txt文件中读取 students时,发现这个数据的类型会变成str格式,而不是我们所希望的dict。而如果我们使用pickle模块来进行保存,则不会改变students的数据类型。
这就是pickle相比别的数据保存方式的一个优势:Pickle can serialize almost every commonly used built-in Python data type。
When dealing with more complex data types like dictionaries, data frames, and nested lists, serialization allows the user to preserve the object’s original state without losing any relevant information.
pickle能够保存Python的复杂的数据类型,包括列表、元组、自定义类等,并且不会丢失相关信息。
在使用pickle,你以什么形式保存数据,就可以在读取时获得什么形式的数据,省去了重新编辑代码的麻烦。
此外,pickle是一个专属于python的模块,因此你不能使用别的语言来读取你保存的数据。
怎么使用pickle
pickle的用法十分简单,最基本的操作就是dumps()和loads()。
# 将python数据据对象obj转换保存到file中去
pickle.dump(obj, file, protocol=None, *, fix_imports=True, buffer_callback=None)
# 将python数据对象obj转换为pickle格式
pickle.dumps(obj, protocol=None, *, fix_imports=True, buffer_callback=None)
# 从file文件中读取数据并转换为python类型
pickle.load(file, *, fix_imports=True, encoding='ASCII', errors='strict', buffers=None)
# 将pickle格式的数据转换为python类型
pickle.loads(data, /, *, fix_imports=True, encoding=”ASCII”, errors=”strict”, buffers=None)
cifar 数据读取
cifar 文件介绍
下载并解压cifar10文件后,可以看到压缩包中包括的文件内容如下:
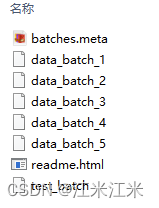
一共八个文件。
其中 xxx_batch是保存为pickle格式的数据文件。每个batch文件加载后,是一个dict,它拥有四个key,分别是dict_keys([b’batch_label’, b’labels’, b’data’, b’filenames’])。
batch_label – index of batch. 当前使用的batch的标号
data – a 10000x3072 numpy array of uint8s. 保存了所有的32x32的彩色图片,按照red-green-blue的顺序。
labels – a list of 10000 numbers in the range 0-9. 保存了每个图片对应的类别。
filenames – a list of filenames of 10000 images。保存了所有图片的名称。
此外还有一个单独的batches.meta文件,它也是一个dict,拥有三个key,分别是
dict_keys([b’num_cases_per_batch’, b’label_names’, b’num_vis’])。包括了一些数据的基本信息。比如class_index和class_name的对应关系,在这里我们先不需要使用这个文件。
cifar 文件读取与处理
读取数据
批量处理数据的代码可以直接参考: https://github.com/TingsongYu/PyTorch_Tutorial/blob/master/Code/1_data_prepare/1_1_cifar10_to_png.py
使用官网给出的代码样例来进行文件的读取。
比如说对于batch文件:file1 = ‘xxx/cifar-10-batches-py/data_batch_1’,我们可以使用如下代码来读取文件
import pickle
def unpickle(file):
with open(file,'rb')as f:
dict = pickle.load(f,encoding = 'bytes')
return dict
data = unpickle(file1)
读取到的data包括当前batch的10000个数据。我们可以用data[b’labels’][i]获得第i个图像的类别,data[b’filename’][i]获得第i个图像的名称,data[b’data’][i]为第i个图片数据本身,这个数据为长度3072 = 3 x 32 x 32的array,我们需要把它转换成一个图片的格式。
可以使用代码
# 首先ere'sha成(3, 32, 32)是因为数据是按照通道排序的
img = np.reshape(data[b'data'][i], (3, 32, 32)
# 将通道数反转到最后一维。要注意这里的图片是rgb格式。
img = img.transpose(1, 2, 0)
数据集的划分
数据集的划分可以直接参考: https://github.com/TingsongYu/PyTorch_Tutorial/blob/master/Code/1_data_prepare/1_2_split_dataset.py
该代码中没有使用所有的数据集,而是将一万张test数据重新划分。
划分完成后,训练集包含每个类别各800张,共8000张图片,验证集和测试集分别包括1000张图片。
关于为什么要划分数据集,在这里不做过多描述。
制作图片索引
教程代码中将图片和标签保存到txt中,我本人更喜欢用csv,在这里提供csv样例代码。之后的数据读取过程均基于csv编写。
def gen_csv(csv_path, img_dir):
out = {}
out['path'] = []
out['label'] = []
for root, s_dirs, _ in os.walk(img_dir, topdown=True): # 获取 train文件下各文件夹名称
for sub_dir in s_dirs:
i_dir = os.path.join(root, sub_dir) # 获取各类的文件夹 绝对路径
img_list = os.listdir(i_dir) # 获取类别文件夹下所有png图片的路径
for i in range(len(img_list)):
if not img_list[i].endswith('png'): # 若不是png文件,跳过
continue
label = img_list[i].split('_')[0]
img_path = os.path.join(i_dir, img_list[i])
out['path'].append(img_path)
out['label'].append(label)
out = pd.DataFrame(out)
out.to_csv(csv_path,index=False)
gen_csv(train_csv_path, train_dir)
gen_csv(valid_csv_path, valid_dir)
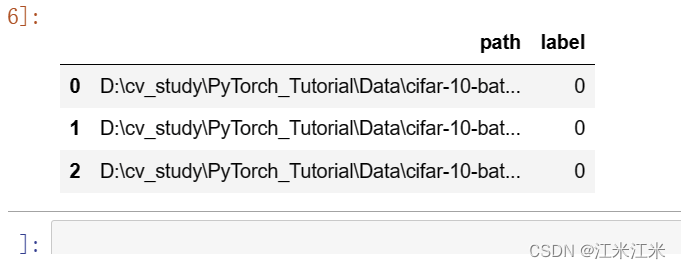
生成的csv内容如下,第一列为图片的位置,第二列为图片的label。
pytorch 读取数据
Dataset的使用
教程参考: https://pytorch.org/tutorials/beginner/basics/data_tutorial.html?highlight=dataset
要想使用pytorch读取数据并用于训练,就需要将数据处理成pytorch可以使用的格式,遵守pytorch的基本法。pytorch中提供了两个类帮助大家进行数据的处理,分别是Dataset和DataLoader。Dataset类帮助我们预加载数据,并存储数据和对应的label。Dataloader则帮助我们快速获取其中的样本。
在pytorch教程中,给出了制作自己的数据集的样例代码(添加了注释):
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file) # 读取包含了图片相对地址和标注信息的csv
self.img_dir = img_dir # 图片存放的路径
self.transform = transform #使用的图片transform方法
self.target_transform = target_transform # 使用的label的transform方法
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0]) # 获取图片的绝对路径
image = read_image(img_path) # 读取图片
label = self.img_labels.iloc[idx, 1] # 获取图片的label
if self.transform: # 将图片进行transform
image = self.transform(image)
if self.target_transform: # 将label进行transform
label = self.target_transform(label)
return image, label
可以看到该样例代码的数据读取也是基于csv文件的。
这里读取图片时使用的是torchvision.io 的read_image函数,这个函数的作用是Reads a JPEG or PNG image into a 3 dimensional RGB or grayscale Tensor. Optionally converts the image to the desired format. The values of the output tensor are uint8 in [0, 255]. 所以不需要我们额外将图片转为tensor。
实例化CustomImageDataset后,可以使用以下代码绘制出dataset的样例。
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3 # 三行三列图片
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item() # 随机取得一个index
img, label = training_data[sample_idx] # 获取数据
figure.add_subplot(rows, cols, i)
plt.title(label)
plt.axis("off")
plt.imshow(img.numpy().transpose(1,2,0)) # 因为数据为大小(3, 32, 32)的tensor,所以将它transpose一下。
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fPvThO2S-1686486343859)(en-resource://database/659:1)]](https://img-blog.csdnimg.cn/f46ba91a44c84d71bd570565809b499c.png)
Dataloader的使用
dataset中每次可以获取到我们的数据集中的一共sample和对应的label。但是在训练的时候,我们希望按照batch进行数据的读取,并且数据需要通过shuffle来增加随机性,防止overfitting,甚至使用multiporcessing来加速数据的获取。
综合来说,Dataloader起到了对以下功能的支持:
- map-style and iterable-style datasets [pytorch的两种dataset类型,第一种是我们常用的]
- customizing data loading order
- automatic batching
- single-and multi-process data loading
- automatic memory pinning
我们使用一个最简单的dataloader,将batch_size设为64,shuffler = True。这样我们的dataloader每次会按照随机顺序取64个数据。
from torch.utils.data import DataLoader
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
我们可以测试一下数据的情况。
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x4GcPl7E-1686486343859)(en-resource://database/661:1)]](https://img-blog.csdnimg.cn/bb71bab8120c49a69d4654233715febe.png)
可以看到我们获得的featurebatch包括64个大小为[3, 32, 32]的数据,我们的label的大小也是64。
使用和之前类似的方法画出整个batch的数据的图像。因为我们的shuffle = True,所以数据的读取是随机的,得到的label也是无序的。

假如我们使用 shuffle = False,数据会按照我们csv中的顺序读取,那么得到的batch的数据的图像就会如下。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rs6HzGCw-1686486343859)(en-resource://database/665:0)]](https://img-blog.csdnimg.cn/1dc999539f814b42a521deecc6d71b47.png)
map-style and iterable-style dataset
map-style datasets就是我们在上一节中使用的Dataset的类型,它拥有__getitem__()和__len__(),并可以根据给定的index来返回data samples。
iterable-style dataset和它不同,是一个基于IterableDataset实现的dataset,它拥有__iter__(),一般用于很难进行随机读取的情况。这个几乎没有用过,在这里不多介绍。可以参考: https://pytorch.org/docs/stable/data.html#torch.utils.data.IterableDataset
data loading order and sampler
这里的order主要是指对map-style数据集的order的控制,对于iterable-style的数据集,它的 order is entirely controlled by the user-defined iterable。
DataLoader的入参sampler,在这里起到了决定数据顺序的作用。所以当你使用sampler时,你的shuffle就失去了作用。
默认来讲,在不使用sampler的情况下,当你的shuffle = True时,你使用的其实是SequentialSampler,即按顺序取样;当你的shuffle = False时,你使用的其实是RandomSampler,即随机取样。
loading batched and non-batched data
DataLoader中有四个参数影响着基于batch取数据的过程,分别是batch_size, drop_last, batch_sampler 和 collate_fn。
- batch_size 决定了一共batch的大小。
- drop_last 决定了batch中数据是否要保留。
- batch_sampler 决定了batch的取样顺序。
- collate_fn 决定了batch中数据的组合方式。
从一个map-style的数据集中加载数据,可以等价于下面的过程:
for indices in batch_sampler:
yield collate_fn([dataset[i] for i in indices])
在这个过程中,collate_fn可以按照你指定的方式对一个batch中所有数据进行组合。
# Example with a batch of `int`s:
default_collate([0, 1, 2, 3]) => tensor([0, 1, 2, 3])
# Example with a batch of `str`s:
default_collate(['a', 'b', 'c']) => ['a', 'b', 'c']
# Example with `Map` inside the batch:
default_collate([{'A': 0, 'B': 1}, {'A': 100, 'B': 100}]) => {'A': tensor([ 0, 100]), 'B': tensor([ 1, 100])}
# Example with `Tuple` inside the batch:
default_collate([(0, 1), (2, 3)]) => [tensor([0, 2]), tensor([1, 3])]
# Example with `List` inside the batch:
default_collate([[0, 1], [2, 3]]) => [tensor([0, 2]), tensor([1, 3])]
可以看到默认的形式中会对数据优先按照dimension进行组合,当你不希望使用这样的组合方式时,可以使用自定义的collate_fn,如下例子:
def collate_fn_resturecture(data):
data_tensor = torch.tensor(data, dtype = torch.float32)
xs, y = data_tensor[:,:2], data_tensor[:,-1].squeeze()
return xs, y
#给定一个输入
item_list = [[1,2,3] , [3,4,5], [5, 6, 7]]
collate_fn_resturcture(item_list)
# 得到的结果是 (tensor([[1., 2.],[3., 4.],[5., 6.]]), tensor([3., 5., 7.]))
当入参的batch_size和batch_sampler都是None的时候,意味着没有使用automatic-batching。从数据集中加载数据,可以等价于下面的过程:
for index in sampler:
yield collate_fn(dataset[index])
在这个过程中,collate_fn只起到了把numpy转为tensor的作用。
single- and multi-process data loading
DataLoader默认使用single-process,即入参num_workers = 0。因此数据加载过程很慢的话,可能会block计算的过程。在资源不足或者数据集很小的情况下,大家还是更喜欢用single-process。单线程时如果出现bug,也更容易追踪和修改。
将num_workers设置成一个正整数时,会使用多进程数据加载。这种情况下可能会引发一些问题:https://github.com/pytorch/pytorch/issues/13246#issuecomment-905703662
memory pinning
当内存固定时,数据到gpu的传输速度会更快,所以可以使用 pin_memory = True 来固定数据的内存空间。
下一步会按照tutorial教程的顺序进行transform的介绍和一些augmentation的扩展。




![【群智能算法改进】基于动态折射反向学习和自适应权重的改进麻雀搜索算法[4]【Matlab代码#39】](https://img-blog.csdnimg.cn/1a6401103003418081afe895613ac8e5.png#pic_center)


![深度学习应用篇-计算机视觉-视频分类[8]:时间偏移模块(TSM)、TimeSformer无卷积视频分类方法、注意力机制](https://img-blog.csdnimg.cn/img_convert/9aa65dbabf21aa8f30a3b355227a931b.png)