一、概述
title:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
论文地址:https://arxiv.org/abs/2201.11903
auto COT代码【COT升级版本】:GitHub - amazon-science/auto-cot: Official implementation for "Automatic Chain of Thought Prompting in Large Language Models" (stay tuned & more will be updated)
auto COT说明:人工去编写COT耗时耗力,auto COT使用机器生成推理过程,然后拼接成COT样例组装成context送入llm,效果居然超过了manual-COT(人工设置的COT)
1.1 Motivation
- 探究COT(chain of thought)【一系列中间的推理步骤】如何能极大的提升大模型对复杂问题的推理能力。
- type1 task:随着模型scale变大,效果也逐渐提升,像文本分类,情感分类就是这样。
- type2 task:随着模型scale变大,效果变平flat,即效果随着增大模型没什么提升,像复杂数学问题的推理就是这种情况。

- 左边:简单问题的推理效果随着模型增大而提高,这个时候COT比没有用COT好一丢丢
- 右边:复杂问题推理能力效果不随着模型增大而提高,这个时候用了COT,可以带来显著的提升
1.2 Methods
- 通过chain-of-thought prompting【一步一步思考】来验证足够大的模型存在的推理能力涌现的情况。
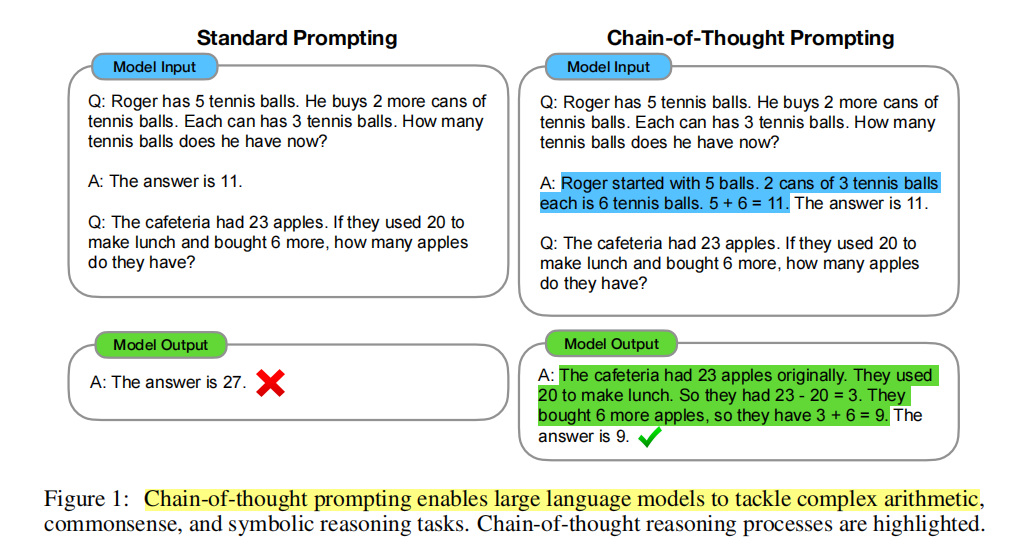
COT是什么:在给出的样例中,写出更详细的推理过程

各种场景COT例子
1.3 Conclusion
- 在三种大型语言模型上进行的实验表明,思维链提示可以提高其在一系列算术、常识和符号推理任务上的性能。

- 没用COT:18%解决率,用了COT:57%解决率,这提升量也太大了
- 收益可能是惊人的。例如一个只有8个思维链范例COT的PaLM 540B在数学单词问题的GSM8K基准测试上达到了最先进的准确性,甚至超过了finetuned后的GPT-3。
- 思维链推理是模型尺度的一个涌现属性【emergent property】,它允许足够大的语言模型来执行推理任务,否则就会有平坦的尺度曲线【小模型不太行】。
- COT(chain of thought)总结:
-
- COT原则上可以让模型执行多个中间步骤推理,可能可以给需要多个推理step的问题分配更多计算资源来解决。
- COT提供了可解释性
- COT可以解决一些常识性的问题
- 可以像few-shot一样,提供一些中间结果作为参考样例。
二、详细内容
1 COT是随着模型大小增加而涌现的一种能力

(1)只在100B左右的大模型上才有效果

(2):任务越难,效果越好,例如GSM8K上,GPT和PaLM用了COT比没有COT高差不多2倍。
(3):利用PaLM540B在GSM8K数据集上达到了SOTA。
2 消融实验:是哪些原因使COT效果表现不错

- Equation only:只在给出答案前,加入了数学equation【只给数学表达式,不给自然语言描述】,验证COT是否为Equation带来的提升,图5显示不是【说明自然语言在推理过程中起到了非常重要的作用】。
- Variable compute only:在给出答案前,加入和COT等长度的...,验证是否为COT增加token从而增加计算量带来的提升,发现和baseline也没啥变化,说明不是这个原因。
- Chain of thought after answer:验证COT是否因为新增的prompts让LLM更能够接入相关知识而带来效果的提升,这里让COT放在答案后,发现和baseline也没啥区别,说明COT并不是因为能够接入额外知识而带来的提升,是确实因为模型学到推理带来的提升。。
- 结论:COT确实在大模型里面能够带来推理能力的提升,而不是增加计算量,引入额外知识带来的提升。
3 鲁棒性

- 不同人写的COT还是有一定方差,但是都比没用COT要好
- 从训练集搞出来的examplars【训练集数据已经有step的推理过程】也验证了COT的有效性
- 结论:用了COT等类似的方法,在复杂推理问题上,就是要比没用好
4 其他场景

- 通用常识知识推理:CSQA:常识QA,StrategyQA:multi-hop 策略回答,Data:时间推理,Sports:运动,SayCan:指挥机器人
- 结论:1. 模型增大,效果提升。2. COT在这些通用知识上也有一定的提升,在CSQA上提升不是特别大,其他还可以。
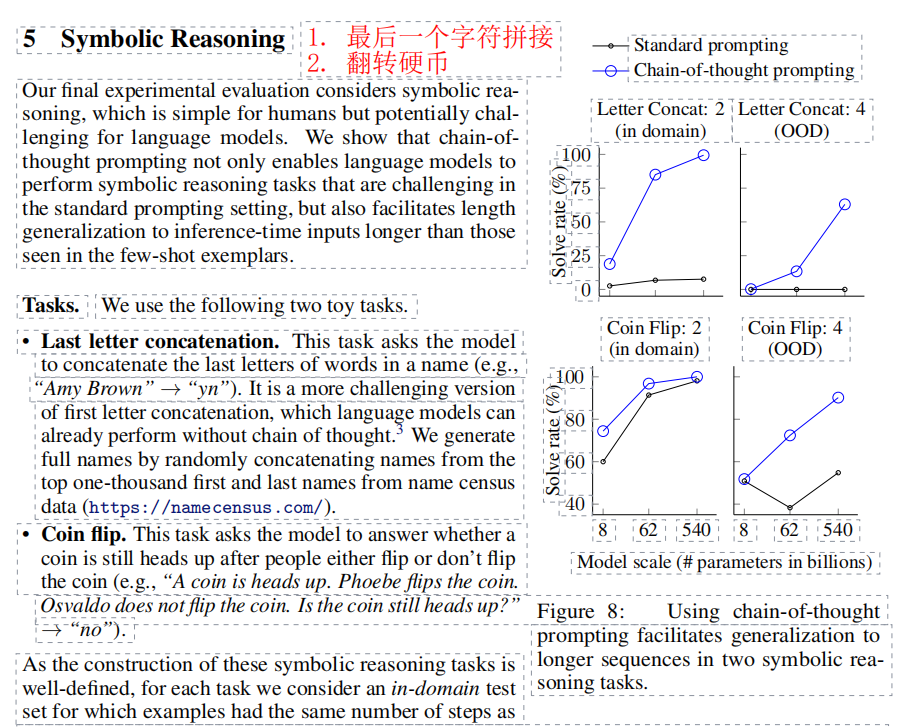
- 符号推理:(1)拼接尾字母。(2):翻转硬币(推理硬币是正面还是反面)。
- 实验方法:(1)in domain:该领域的测试数据。(2):OOD,out-of-domain的数据
- 结论:(1)in domain的COT比没有COT好,但是要模型在62B左右才有一个比较大的效果的提升。(2):对于OOD(out-of-domain)数据,要500B才有一个比较大的提升,同时COT比没有用COT好非常多。
三、其他参考
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models - 知乎
- Chain of Thought论文、代码和资源【论文精读·43】_哔哩哔哩_bilibili