分类目录:《深入理解深度学习》总目录
相关文章:
·注意力机制(AttentionMechanism):基础知识
·注意力机制(AttentionMechanism):注意力汇聚与Nadaraya-Watson核回归
·注意力机制(AttentionMechanism):注意力评分函数(AttentionScoringFunction)
·注意力机制(AttentionMechanism):Bahdanau注意力
·注意力机制(AttentionMechanism):多头注意力(MultiheadAttention)
·注意力机制(AttentionMechanism):自注意力(Self-attention)
·注意力机制(AttentionMechanism):位置编码(PositionalEncoding)
在深度学习中,经常使用卷积神经网络(CNN)或循环神经网络(RNN)对序列进行编码。想象一下,有了注意力机制之后,我们将词元序列输入注意力池化中,以便同一组词元同时充当查询、键和值。具体来说,每个查询都会关注所有的键—值对并生成一个注意力输出。由于查询、键和值来自同一组输入,因此被称为自注意力(Self-attention),也被称为内部注意力(Intra-attention)。
给定一个由词元组成的输入序列
x
1
,
x
2
,
⋯
,
x
n
x_1,x_2,\cdots,x_n
x1,x2,⋯,xn,其中任意KaTeX parse error: Undefined control sequence: \inR at position 4: x_i\̲i̲n̲R̲^d(1\leqi\leqn)。该序列的自注意力输出为一个长度相同的序列
y
1
,
y
2
,
⋯
,
y
n
y_1,y_2,\cdots,y_n
y1,y2,⋯,yn,其中:
KaTeX parse error: Undefined control sequence: \inR at position 48: …dots,(x_n,x_n))\̲i̲n̲R̲^d
接下来比较下面几个架构,目标都是将由
n
n
n个词元组成的序列映射到另一个长度相等的序列,其中的每个输入词元或输出词元都由
d
d
d维向量表示。具体来说,将比较的是卷积神经网络、循环神经网络和自注意力这几个架构的计算复杂性、顺序操作和最大路径长度。请注意,顺序操作会妨碍并行计算,而任意的序列位置组合之间的路径越短,则能更轻松地学习序列中的远距离依赖关系。
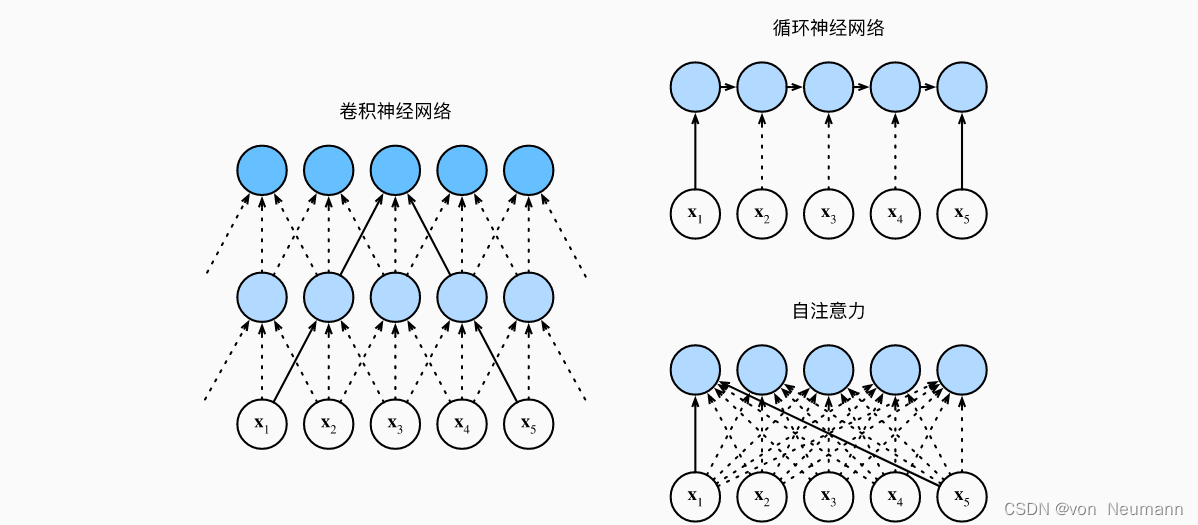
考虑一个卷积核大小为
k
k
k的卷积层。由于序列长度是
n
n
n,输入和输出的通道数量都是
d
d
d,所以卷积层的计算复杂度为
O
(
k
n
d
2
)
O(knd^2)
O(knd2)。如上图所示,卷积神经网络是分层的,因此为有
O
(
1
)
O(1)
O(1)个顺序操作,最大路径长度为
O
(
n
k
)
O(\frac{n}{k})
O(kn)。例如,
x
1
x_1
x1和
x
5
x_5
x5处于上图中卷积核大小为3的双层卷积神经网络的感受野内。当更新循环神经网络的隐状态时,KaTeX parse error: Undefined control sequence: \timesd at position 2: d\̲t̲i̲m̲e̲s̲d̲权重矩阵和
d
d
d维隐状态的乘法计算复杂度为
O
(
d
2
)
O(d^2)
O(d2)。由于序列长度为
n
n
n,因此循环神经网络层的计算复杂度为
O
(
n
d
2
)
O(nd^2)
O(nd2)。根据上图所示,有
O
(
n
)
O(n)
O(n)个顺序操作无法并行化,最大路径长度也是
O
(
n
)
O(n)
O(n)。而在自注意力中,查询、键和值都是KaTeX parse error: Undefined control sequence: \timesn at position 2: n\̲t̲i̲m̲e̲s̲n̲矩阵。考虑《深入理解深度学习——注意力机制(AttentionMechanism):注意力评分函数(AttentionScoringFunction)》中缩放的”点—积“注意力,其中KaTeX parse error: Undefined control sequence: \timesd at position 2: n\̲t̲i̲m̲e̲s̲d̲矩阵乘以KaTeX parse error: Undefined control sequence: \timesn at position 2: d\̲t̲i̲m̲e̲s̲n̲矩阵。之后输出的KaTeX parse error: Undefined control sequence: \timesn at position 2: n\̲t̲i̲m̲e̲s̲n̲矩阵乘以KaTeX parse error: Undefined control sequence: \timesd at position 2: n\̲t̲i̲m̲e̲s̲d̲矩阵。因此,自注意力具有
O
(
n
2
d
)
O(n^2d)
O(n2d)计算复杂性。正如在上图中所示,每个词元都通过自注意力直接连接到任何其他词元。因此,有
O
(
1
)
O(1)
O(1)个顺序操作可以并行计算,最大路径长度也是
O
(
1
)
O(1)
O(1)。
总而言之,卷积神经网络和自注意力都拥有并行计算的优势,而且自注意力的最大路径长度最短。但是因为其计算复杂度是关于序列长度的二次方,所以在很长的序列中计算会非常慢。
参考文献:
[1]LecunY,BengioY,HintonG.Deeplearning[J].Nature,2015
[2]AstonZhang,ZackC.Lipton,MuLi,AlexJ.Smola.DiveIntoDeepLearning[J].arXivpreprintarXiv:2106.11342,2021.






![[230604] 听力TPO66汇总·上篇| C1 L1 C2|10:20~12:00](https://img-blog.csdnimg.cn/acaa6eb1359e4dd2b54dfbe295160d0e.jpeg)