知识目录
- 一、写在前面💕
- 二、Hive的安装与配置✨
- 2.1 Hive简介
- 2.2 上传与解压
- 2.3 拷贝MySQL驱动
- 2.4 hive-site.xml文件
- 2.5 启动hive
- 三、导入Hdfs数据到Hive✨
- 3.1 修改Hadoop集群配置
- 3.2 初始化
- 3.3 创建表
- 3.4 从Hdfs导入数据
- 四、总结撒花😊
一、写在前面💕
大家好!我是初心,很高兴再次和大家见面。
今天跟大家分享的文章是 Hive的安装以及导入Hdfs的数据到Hive中 ,希望能帮助到大家!本篇文章收录于 初心 的 大数据 专栏。
🏠 个人主页:初心%个人主页
🧑 个人简介:大家好,我是初心,和大家共同努力
💕欢迎大家:这里是CSDN,我记录知识的地方,喜欢的话请三连,有问题请私信😘
写作背景:接着上篇我们说到将 Mysql 中的数据通过 Sqoop 导入到 Hdfs 中去,本次我们将实现将 Hdfs 中的数据导入到 Hive 中。
二、Hive的安装与配置✨
2.1 Hive简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,类似于RDBMS(如MySQL、Oracle等),并提供类似于SQL的查询功能。

- 产生背景
在Hadoop中,可以简单的概括一下内容:
HDFS: 海量数据存储
MapReduce: 海量数据的分析与计算
Yarn: 集群资源的管理和作业调度
其中MapReduce处理大数据会 面临的问题 有:
MR开发难度大,学习成本高
HDFS文件没有字段名、数据类型,不方便进行数据的管理
使用MR的框架开发,项目周期长,成本高
- Hive为了解决以上问题而产生。
简单总结:Hive是一个将SQL转换为MR任务的工具
- 数据仓库相关概念
1. 是一个面向主题的、集成的、相对稳定的、反应历史变化的数据集合
2. 目的:构建面向分析的、集成的数据集合,为企业提供决策支持
3. 数据仓库本身不产生数据,数据来源于外部
4. 存储了大量数据
2.2 上传与解压
我们使用Xshell加Xftp将Hive的安装包上传到 /opt/software 目录下:
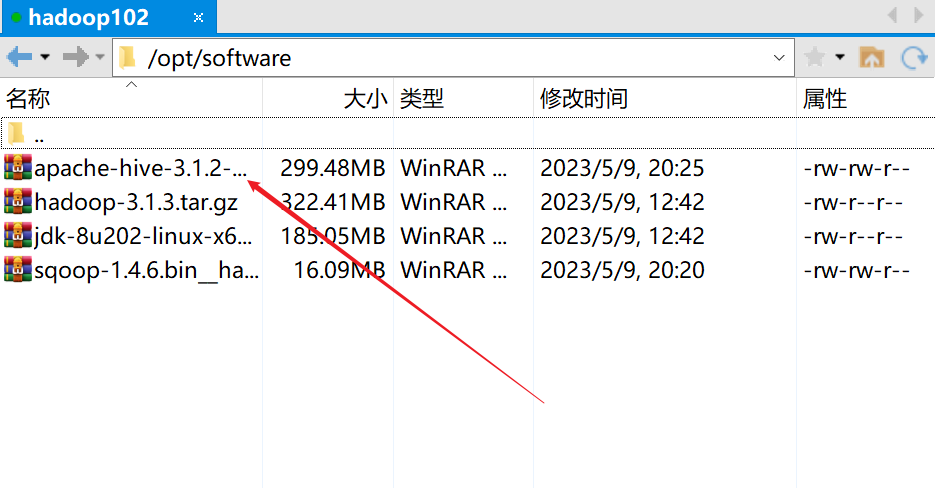
进入到该上传的目录:
cd /opt/software
解压Hive:
tar -xzvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
进入到module目录下:
cd /opt/module
重命名文件:
mv apache-hive-3.1.2-bin/ hive
2.3 拷贝MySQL驱动
我们这里使用的MySQL驱动是 mysql-connector-java-5.1.49.jar 与当前Hive版本相匹配。
同理将mysql-connector-java-5.1.49.jar上传,不过这里上传到 hive 的lib目录下。
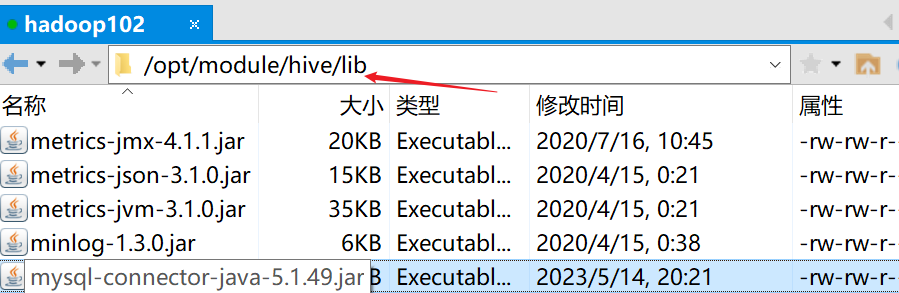
这里大家肯定有疑问,为什么要拷贝MySQL驱动?
因为我们这里使用MySQL作为存储元数据的数据库,所以需要把连接MySQL的jar包放入或链接到$HIVE_HOME/lib目录下。如果你奇思妙想,换成其他数据库也是可以的。
2.4 hive-site.xml文件
进入到 hive 的conf目录:
cd /opt/module/hive/conf/
查看当前文件夹下内容会发现没有hive-site.xml文件,不要慌!这里我们选择新建即可:
vim hive-site.xml
将以下文件内容拷贝到文本编辑器中(因为还有要修改的地方,我会以 注释 的形式说明),修改好后再复制到 hive-site.xml 中去:
<configuration>
<!--jdbc连接url,将url中的主机名hadoop改成自己的主机名或者IP-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3307/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<!--jdbc驱动类的名字-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!--连接MySQL的用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<!--连接MySQL的密码(密码改成自己的数据库root用户密码)-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>sky</value>
<description>password to use against metastore database</description>
</property>
<!--当参数为None时,任何登录的用户都拥有超级用户权限-->
<property>
<name>hive.server2.authentication</name>
<value>NONE</value>
</property>
<!--配置hiveserver2连接的主机(hadoop102改成自己的)-->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!--配置hiveserver2连接的主机的端口号-->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
</configuration>
2.5 启动hive
修改好配置文件后,我们就可以启动 Hive 了!
在启动 Hive 之前,我们还需要启动MySQL,这里我的MySQL安装在了 Docker 中。
- 启动docker
sudo systemctl start docker
- 查看MySQL的容器id
sudo docker ps -a
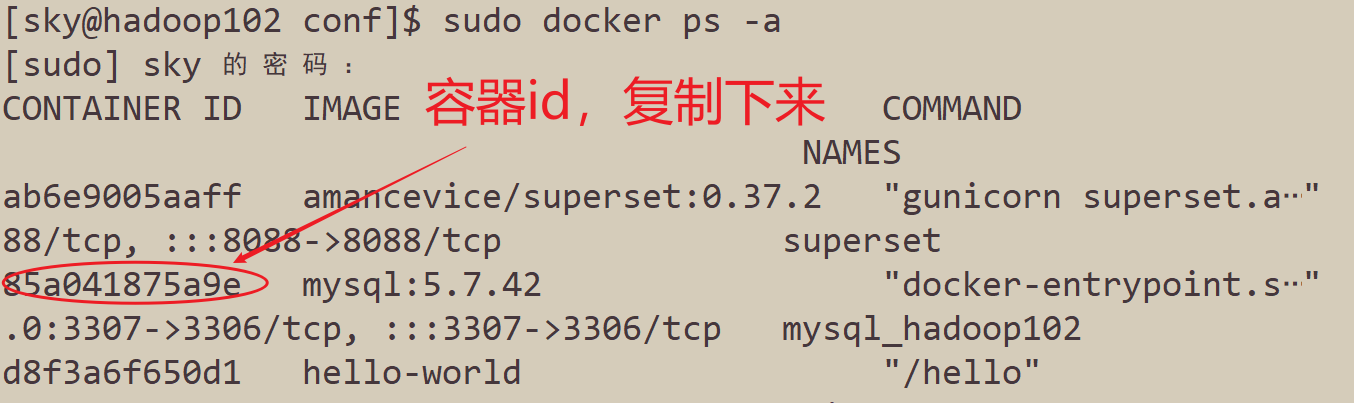
- 启动MySQL
sudo docker start 85a041875a9e(刚才拷贝的id)
进入到hive安装目录下,执行以下命令初始化元数据库:
schematool -dbType mysql -initSchema
- 启动Hive
启动HiveServer2:
$HIVE_HOME/bin/hiveserver2
启动Hive:
hive
三、导入Hdfs数据到Hive✨
3.1 修改Hadoop集群配置
- 进入到Hadoop安装目录下
cd /opt/module/hadoop-3.1.3/etc/hadoop/
- 修改core-site.xml文件
vim core-site.xml
- 将以下内容添加进入,已经有的可以不用添加,需要修改的地方已经用注释的形式说明
<!-- 1.基本配置——hdfs -->
<!--指定NameNode的内部通讯地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
<description>version of this configuration file</description>
</property>
<!-- 指定Hadoop数据的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
<description>A base for other temporary directories.</description>
</property>
<!-- 配置网页登录的静态用户是sky(换成自己的)-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>sky</value>
</property>
<!--配置使用sky用户(换成自己的)登录的主机为任意主机-->
<property>
<name>hadoop.proxyuser.sky.hosts</name>
<value>*</value>
</property>
<!--配置使用sky用户(换成自己的)登录的群组为任意群组-->
<property>
<name>hadoop.proxyuser.sky.groups</name>
<value>*</value>
</property>
3.2 初始化
进入到hive目录:
cd /opt/module/hive
初始化元数据库:
schematool -dbType mysql -initSchema
3.3 创建表
create table order_by_province(dt string,
province_id string,
province_name string,
area_code string,
iso_code string,
order_count bigint,
order_amount decimal)
row format delimited
fields terminated by '\t';
3.4 从Hdfs导入数据
使用Load命令从HDFS导入数据刀Hive:
load data inpath '/mysql/gmall_report/order_by_province/*' into table order_by_province;
四、总结撒花😊
本文主要讲解了Hive的安装配置及使用,个人感觉还不是很完善,仅供参考哈,有错误欢迎指出。😊
✨ 这就是今天要分享给大家的全部内容了,我们下期再见!😊
🏠 本文由初心原创,首发于CSDN博客, 博客主页:初心%🏠
🏠 我在CSDN等你哦!😍

![[230604] 听力TPO66汇总·上篇| C1 L1 C2|10:20~12:00](https://img-blog.csdnimg.cn/acaa6eb1359e4dd2b54dfbe295160d0e.jpeg)