文章目录
- 顺序分区
- 轮询分区算法
- 时间片轮转分区算法
- 数据块分区算法
- 业务主题分区算法
- 哈希分区
- 节点取模分区算法
- 一致性哈希分区算法(重点)
- 1.Hash环
- 2.容错性和可扩展性
- 3.数据倾斜
- 4.带有限负载的一致性哈希算法
- 5.带虚拟节点的一致性哈希算法
- 虚拟槽分区算法(重点)
顺序分区
顺序分区规则可以将数据按照某种顺序平均分配到不同的节点。不同的顺序方式,产生了不同的分区算法。例如,轮询分区算法、时间片轮转分区算法、数据块分区算法、业务主题分区算法等。
轮询分区算法
轮询分区算法是最简单的一种分区算法,它将数据均匀地分散到不同的节点上。具体来说,轮询分区算法会将数据按照顺序分配到不同的节点上,每个节点处理一部分数据。该算法适合于数据问题不确定的场景。其分配的结果是,在数据总量非常庞大的情况下,每个节点中数据是很平均的。
时间片轮转分区算法
在某人固定长度的时间片内的数据都会分配到一个节点。时间片结束,再产生的数据就会被分配到下一个节点。这些节点会被依次轮转分配数据。该算法可能会出现节点数据不平均的情况(因为每个时间片内产生的数据量可能是不同的)。但生产者与节点间的连接只需占用当前正在使用的这个就可以,其它连接使用完毕后就立即释放。
数据块分区算法
在整体数据总量确定的情况下,根据各个节点的存储能力,可以将连接的某一整块数据分配到某一节点。
业务主题分区算法
数据可根据不同的业务主题,分配到不同的节点。
哈希分区
节点取模分区算法
该算法的前提是,每个节点都已分配好了一个唯一序号,对于 N 个节点的分布式系统,其序号范围为[0, N-1]。然后选取数据本身或可以代表数据特征的数据的一部分作为 key,计算 hash(key)与节点数量 N 的模,该计算结果即为该数据的存储节点的序号。
该算法最大的优点是简单,但其也存在较严重的不足。如果分布式系统扩容或缩容,已经存储过的数据需要根据新的节点数量 N 进行数据迁移,否则用户根据 key 是无法再找到原来的数据的。生产中扩容一般采用翻倍扩容方式,以减少扩容时数据迁移的比例。
一致性哈希分区算法(重点)
一致性hash算法可以有效地解决分布式存储结构下节点取模分区算法带来的伸缩性差的问题,可以保证在动态增加和删除节点的情况下尽量有多的请求命中原来的机器节点。
1.Hash环
一致性Hash算法也是使用取模的方法,只是,节点取模分区算法是对服务器的数量进行取模,而一致性Hash算法是对2^ 32-1取模。一致性 hash 算法通过一个叫作一致性 hash 环的数据结构实现。这个环的起点是 0,终点是 232 - 1(哈希值是一个32位无符号整型)。环中间的整数按逆/顺时针分布,故这个环的整数分布范围是[0, 232 -1]。整个哈希环如下:
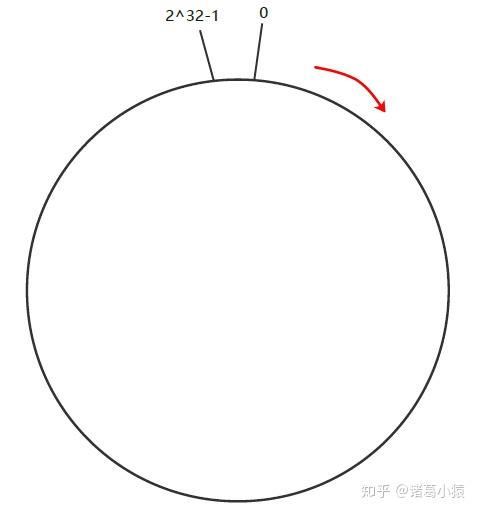
下一步将各个服务器的主机名(主机ID)进行一次哈希,这样每台机器就能确定其在哈希环上的位置,这里假设三个master节点主机哈希后在环空间的位置如下:
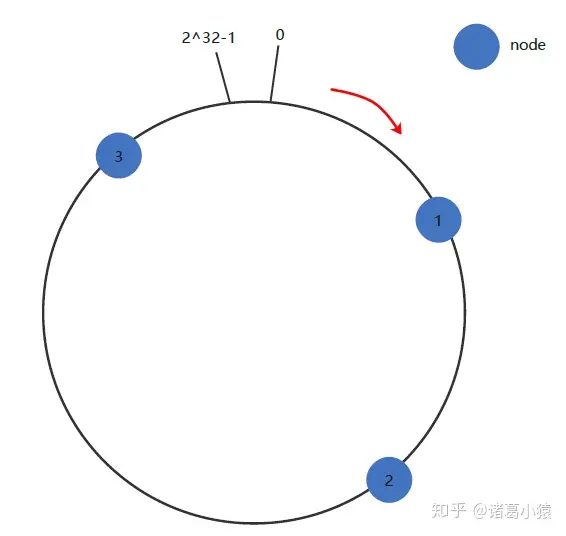
下面将三条key-value数据也放到环上:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置。将数据从所在位置顺时针找第一台遇到的服务器节点,这个节点就是该key存储的服务器!
例如我们有a、b、c三个key,经过哈希计算后,在环空间上的位置如下:key-a存储在node1,key-b存储在node2,key-c存储在node3。

2.容错性和可扩展性
现假设Node 2不幸宕机,可以看到此时对象key-a和key-c不会受到影响,只有key-b被重定位到Node 3。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中后一台服务器之间数据(b节点的前面一个节点是c,后面一个节点是a),其它不会受到影响。同样的,如果集群中新增一个node 4,受影响的数据是node 1和node 4之间的数据,其他的数据是不受影响的。
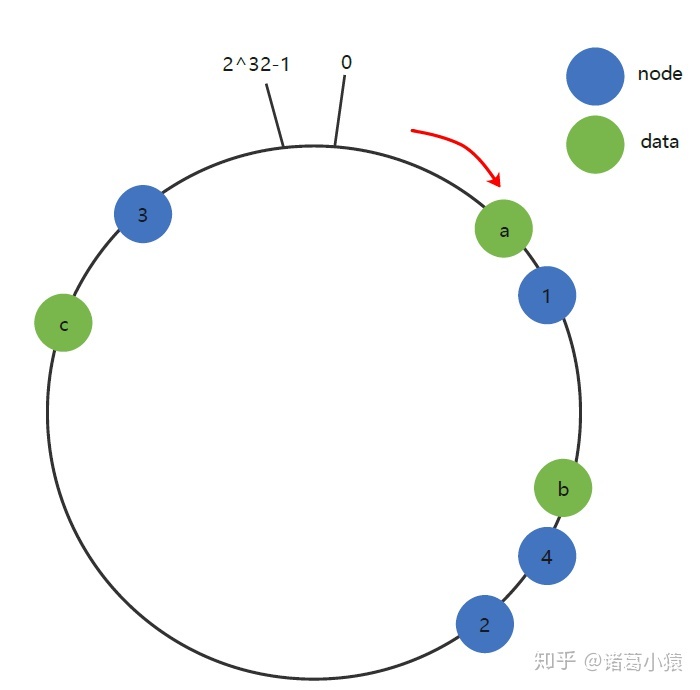
综上所述,一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
3.数据倾斜
一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器,此时必然造成大量数据集中到Node 2上,而只有极少量会定位到Node 1上。其环分布如下:
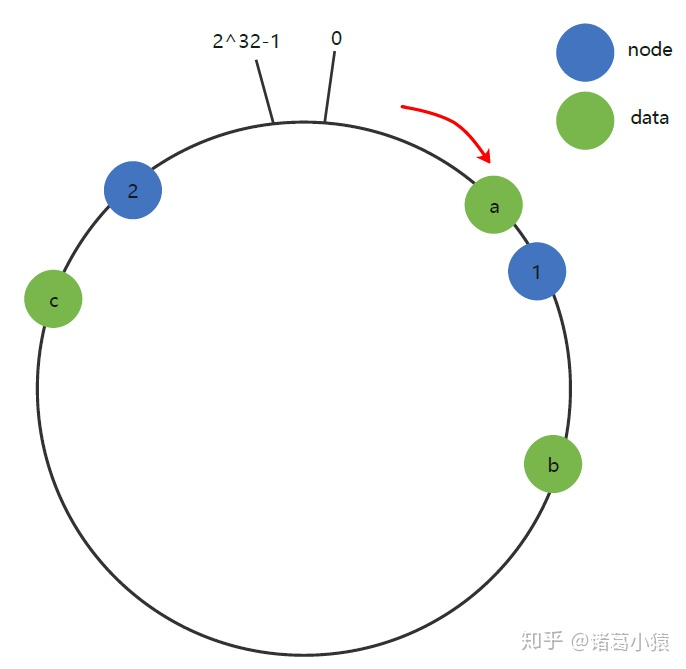
4.带有限负载的一致性哈希算法
因为一致性哈希算法的数据分布不均匀的问题,Google 在 2017 年提出了带有限负载的一致性哈希算法来解决这个问题,带有限负载的一致性哈希算法思想比较简单,给每个存储节点设置了一个存储上限值来控制存储节点添加或移除造成的数据不均匀。简单来说就是当数据按照一致性哈希算法找到相应的存储节点时,要先判断该存储节点是否达到了存储上限;如果已经达到了上限,则需要继续寻找该存储节点顺时针方向之后的节点进行存储。
5.带虚拟节点的一致性哈希算法
带有限负载的一致性哈希算法也有一个问题,那就是每台服务器的性能配置可能存在不一样,如果规定数量过小的话,对于配置高的服务器来说有点浪费,这是因为服务器之间可能存在差异,叫做服务器之间的异构性,为了解决服务器之间的异构性问题,引入了一种叫做带虚拟节点的一致性哈希算法,带虚拟节点的一致性哈希算法核心思想是:根据每个节点的性能为每个节点划分不同数量的虚拟节点,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点,并将这些虚拟节点映射到哈希环中,然后再按照一致性哈希算法进行数据映射和存储。
具体做法可以在主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node 1#1”、“Node 1#2”、“Node 1#3”、“Node 2#1”、“Node 2#2”、“Node 2#3”的哈希值,于是形成六个虚拟节点:
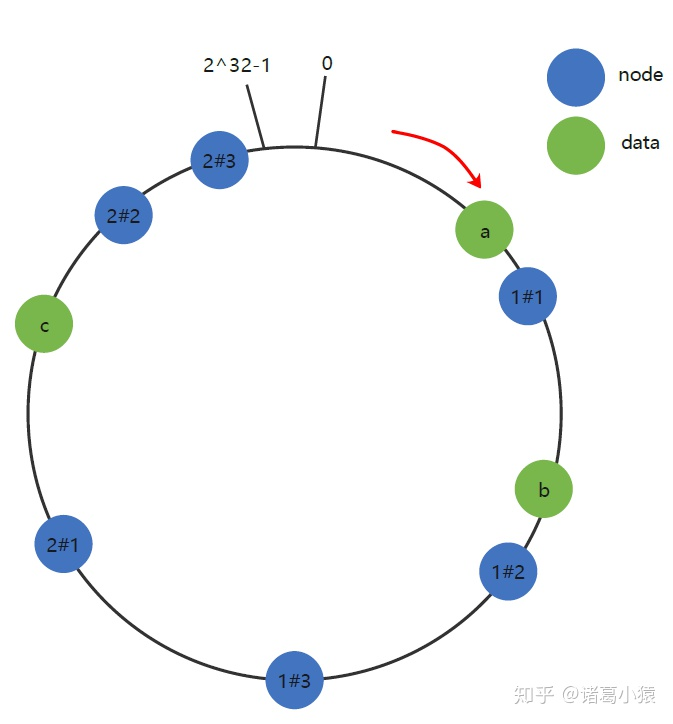
上图中虚拟节点node 1#1,node 1#2,node 1#3都属于真实节点node 1;虚拟节点node 2#1,node 2#2,node 2#3都属于真实节点node 2。
虚拟节点可以让配置好的服务器存储更多的数据,这样就解决了系统异构性的问题,同时由于大量的虚拟节点的存在 在数据迁移时数据会落到不同的物理机上,这样就减小了数据迁移时某台服务器的分担压力,能够保证系统的稳定性。
虚拟槽分区算法(重点)
该算法首先虚拟出一个固定数量的整数集合,该集合中的每个整数称为一个 slot 槽。这个槽的数量一般是远远大于节点数量的。然后再将所有 slot 槽平均映射到各个节点之上。例如,Redis 分布式系统中共虚拟了 16384 个 slot 槽,其范围为[0, 16383]。假设共有 3 个节点,那么 slot 槽与节点间的映射关系如下图所示:
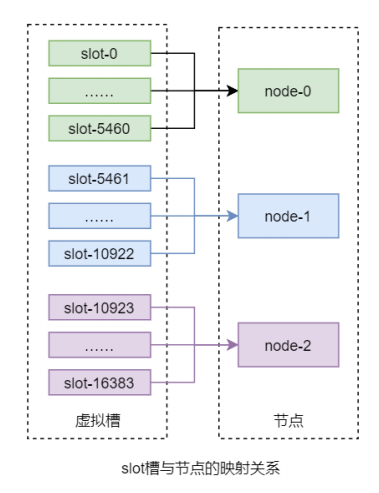
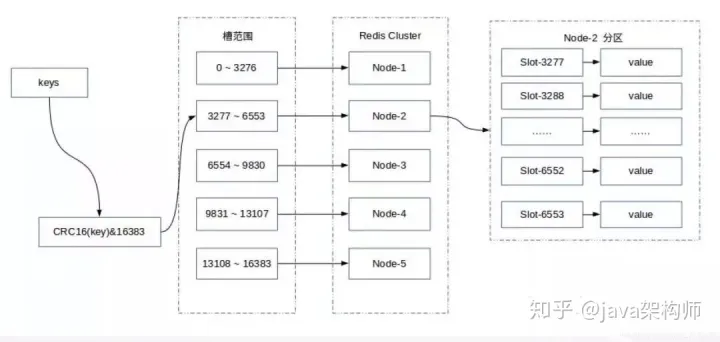
而数据只与 slot 槽有关系,与节点没有直接关系。数据只通过其 key 的 hash(key)映射到slot 槽:slot = hash(key) % slotNums。这也是该算法的一个优点,解耦了数据与节点,客户端无需维护节点,只需维护与 slot 槽的关系即可。Redis 数据分区采用的就是该算法。其计算槽点的公式为:slot = CRC16(key) % 16384。
CRC16()是一种带有校验功能的、具有良好分散功能的、特殊的 hash 算法函数。其实 Redis中计算槽点的公式不是上面的那个,而是:slot = CRC16(key) &16383。
若要计算 a % b,如果 b 是 2 的整数次幂,那么 a % b = a & (b-1)。当a=10,b=4时。10%4=10 & (4-1)=(1010) & (0011)=(0010)=2。之所以用这个公式是因为 & 运算的速度比 % 运算的速度快,这与Redis的特性相吻合。下面是数据存入Redis节点的过程图。
至于为什么Redis的虚拟槽的数量是16384个,而不是其他。详见:京东面试题:为啥RedisCluster设计成16384个槽 - 知乎
参考链接:
- redis系列之一致性hash算法 - 知乎
- 借Redis Cluster集群,窥探集群中数据分布算法 - 知乎
- 京东面试题:为啥RedisCluster设计成16384个槽 - 知乎