目录
- 一、什么是优先级队列?
- 二、堆 (heap,基于二叉树)
- 2.1 什么是堆?
- 2.2 堆的分类
- 2.3 结构与存储
- 三、堆的操作
- 3.1 堆创建
- 3.2 插入元素
- 3.3 弹出元素
- 四、用堆模拟实现优先级队列
- 五、堆的一个重要应用-堆排序
- 六、经典的TOPK问题
- 6.1 排序
- 6.2 堆
一、什么是优先级队列?
如果我们给每个元素都分配一个数字来标记其优先级,不妨设较小的数字具有较高的优先级,这样我们就可以在一个集合中访问优先级最高的元素并对其进行查找和删除操作了。这样,我们就引入了 优先级队列 这种数据结构。 优先级队列(priority queue) 是0个或多个元素的集合,每个元素都有一个优先权,对优先级队列执行的操作有(1)查找(2)插入一个新元素 (3)删除 一般情况下,查找操作用来搜索优先权最大的元素,删除操作用来删除该元素 。对于优先权相同的元素,可按先进先出次序处理或按任意优先权进行。–(来源百度)
- 普通队列:FIFO。按照元素的入队顺序出队,先入先出。
- 按照优先级的大小动态出队(动态指的是元素个数动态变化,而非固定)。
举个现实里面的例子:
排队看病,如果病情相同的情况下会按照先来先进,如果病情严重,优先会看病。
电脑内存占用的资源是有限的,当资源不够的时候,会优先让优先级高的应用占用资源。
二、堆 (heap,基于二叉树)
2.1 什么是堆?
堆在逻辑上是一颗完全二叉树(不存储空节点值),也可以叫二叉堆(Binary Heap)
堆总是攒足下列性质:
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 堆总是一棵完全二叉树。
堆是非线性数据结构,相当于一维数组,有两个直接后继。
2.2 堆的分类
将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
2.3 结构与存储
从堆的概念可知,堆是一棵完全二叉树,因此可以层序的规则采用顺序的方式来高效存储
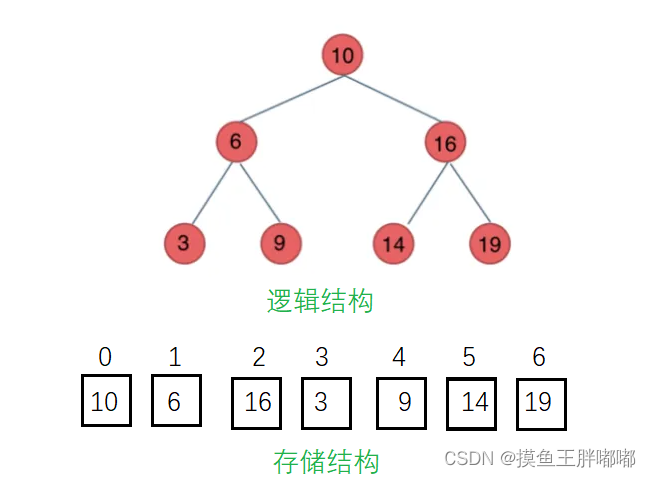
注意:对于非完全二叉树,则不适合使用顺序方式进行存储,因为为了能够还原二叉树,空间中必须要存储空节点,就会导致空间利用率比较低。
三、堆的操作
3.1 堆创建
创建堆之前我们需要复习一个知识点,那就是父子节点之间的关系,
将元素存储到数组中后,可以根据二叉树的性质对树进行还原。假设i为节点在数组中的下标,则有:
如果i为0,则i表示的节点为根节点,否则i节点的双亲节点为 (i - 1)/2
如果2 * i + 1 小于节点个数,则节点i的左孩子下标为2 * i + 1,否则没有左孩子
如果2 * i + 2 小于节点个数,则节点i的右孩子下标为2 * i + 2,否则没有右孩子
复习了这个知识点之后,我们就可以开始思考怎么去创建堆了?
创建的方式其实有很多种,那么我们这里就采用大根堆方式来创建吧!
还记得大根堆是什么特性吗?
将根结点最大的堆叫做最大堆或大根堆。
根据大根堆的特性,我们创建堆的思路是:向下操作。
- 需要一个parent标记需要调整的节点。
- 设置一个循环条件,使得每次调整都能进行,直至停止。
我们可以用child来标记parent的左孩子,如果存在,判断右孩子是否存在,如果存在找到左右孩子中最大的,依然用child标记,将parent与大孩子比较,parent小于小孩子,交换。
public class TestHeap {
public int[] elem;
public int usedSize;
public TestHeap() {
this.elem = new int[10];
}
/**
* 向下调整函数的实现
*
* @param parent 每棵树的根节点
* @param len 每棵树的调整的结束位置
*/
public void shiftDown(int parent, int len) {
int child = 2 * parent + 1;
// 1. 至少有1个孩子
while (child < len) {
if (child + 1 < len && elem[child] < elem[child + 1]) {
child++;// 保证当前左右最大值的下标
}
if (elem[child] > elem[parent]) {
int tmp = elem[child];
elem[child] = elem[parent];
elem[parent] = tmp;
parent = child;
child = 2 * parent + 1;
} else {
break;
}
}
}
public void createBigHeap(int[] array) {
for (int i = 0; i < array.length; i++) {
elem[i] = array[i];
usedSize++;
}
// 根据代码 显示的时间复杂度 看起来应该是O(N*logn) 但是实际上时O(N)
for (int parent = (usedSize - 1 - 1) / 2; parent >= 0; parent--) {
// 调整
shiftDown(parent, usedSize);
}
}
}
3.2 插入元素
插入元素之前,非常经典的我们会考虑到扩容的问题,我们需要判满之后扩容。
扩容之后我们就可以插入新元素了,为了保证堆的结构性,用该位置元素和父亲元素比较,如果大于父亲元素,则交换父子元素,然后指向父亲的位置。再与该位置的父亲位置元素比较,如果父亲元素大则重复上述操作,否则插入结束。
public void shiftUp(int child) {
int parent = (child-1)/2;
while (child > 0) {
if (elem[child] > elem[parent]) {
int tmp = elem[child];
elem[child] = elem[parent];
elem[parent] = tmp;
child = parent;
parent = (child-1)/2;
} else {
break;
}
}
}
public void offer(int val) {
if (isFull()) {
// 扩容
elem = Arrays.copyOf(elem,2*elem.length);
}
elem[usedSize++] = val;
// 注意这里传入的是usedSize-1
shiftUp(usedSize-1);
}
public boolean isFull() {
return usedSize == elem.length;
}
3.3 弹出元素
同样在弹出元素之前,我们需要判断是否为空!
如何弹出元素呢?
先将堆尾元素和堆首元素进行交换,然后将usedSize–;之后对堆首元素向下操作即可。
public boolean isEmpty() {
return usedSize == 0;
}
public int poll() {
if (isEmpty()) {
throw new RuntimeException("优先级队列为空!");
}
int tmp = elem[0];
elem[0] = elem[usedSize-1];
elem[usedSize-1] = tmp;
shiftDown(0, usedSize);
return tmp;
}
四、用堆模拟实现优先级队列

这里只模拟实现几个重要功能!
public class TestHeap {
public int[] elem;
public int usedSize;
public TestHeap() {
this.elem = new int[10];
}
/**
* 向下调整函数的实现
*
* @param parent 每棵树的根节点
* @param len 每棵树的调整的结束位置
*/
public void shiftDown(int parent, int len) {
int child = 2 * parent + 1;
// 1. 至少有1个孩子
while (child < len) {
if (child + 1 < len && elem[child] < elem[child + 1]) {
child++;// 保证当前左右最大值的下标
}
if (elem[child] > elem[parent]) {
int tmp = elem[child];
elem[child] = elem[parent];
elem[parent] = tmp;
parent = child;
child = 2 * parent + 1;
} else {
break;
}
}
}
public void createBigHeap(int[] array) {
for (int i = 0; i < array.length; i++) {
elem[i] = array[i];
usedSize++;
}
// 根据代码 显示的时间复杂度 看起来应该是O(N*logn) 但是实际上时O(N)
for (int parent = (usedSize - 1 - 1) / 2; parent >= 0; parent--) {
// 调整
shiftDown(parent, usedSize);
}
}
public void offer(int val) {
if (isFull()) {
// 扩容
elem = Arrays.copyOf(elem,2*elem.length);
}
elem[usedSize++] = val;
// 注意这里传入的是usedSize-1
shiftUp(usedSize-1);
}
public void shiftUp(int child) {
int parent = (child-1)/2;
while (child > 0) {
if (elem[child] > elem[parent]) {
int tmp = elem[child];
elem[child] = elem[parent];
elem[parent] = tmp;
child = parent;
parent = (child-1)/2;
} else {
break;
}
}
}
public boolean isFull() {
return usedSize == elem.length;
}
public boolean isEmpty() {
return usedSize == 0;
}
public int poll() {
if (isEmpty()) {
throw new RuntimeException("优先级队列为空!");
}
int tmp = elem[0];
elem[0] = elem[usedSize-1];
elem[usedSize-1] = tmp;
shiftDown(0, usedSize);
return tmp;
}
public int peek() {
if (isEmpty()) {
throw new RuntimeException("优先级队列为空!");
}
return elem[0];
}
}
五、堆的一个重要应用-堆排序
堆排序(、Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
在堆的数据结构中,堆中的最大值总是位于根节点(在优先队列中使用堆的话堆中的最小值位于根节点)。堆中定义以下几种操作:
- 最大堆调整(Max Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点
- 创建最大堆(Build Max Heap):将堆中的所有数据重新排序
- 堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整的递归运算
基本思想:
- 将待排序序列构造成一个大顶堆。
- 此时,整个序列的最大值就是堆顶的根节点。
- 将其与末尾元素进行交换,此时末尾就为最大值。
- 然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。
1.将堆顶元素8和末尾元素3进行交换
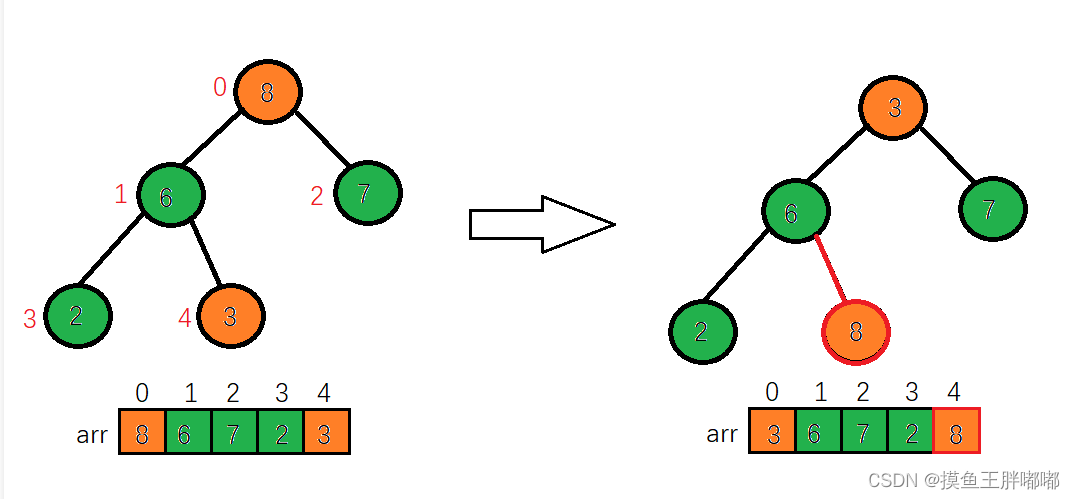
2.重新调整结构,使其继续满足堆定义
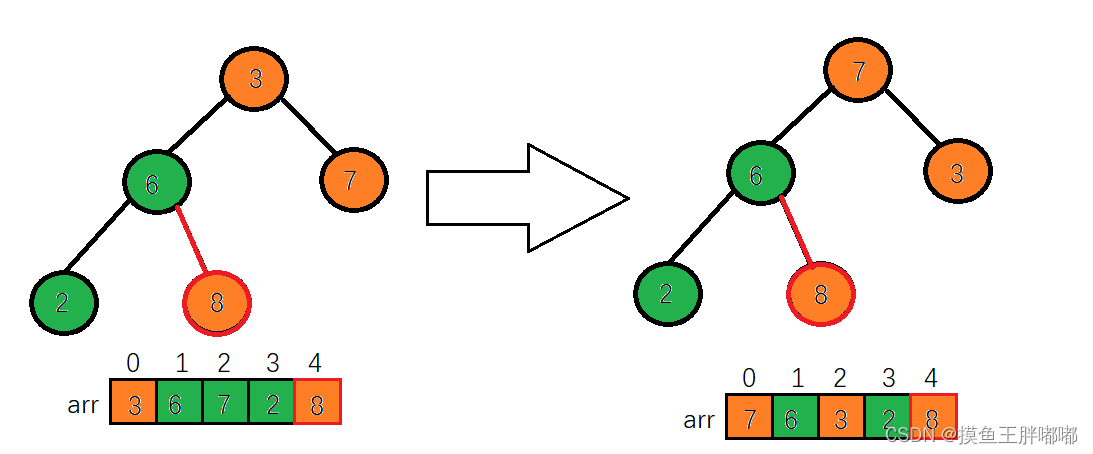
3.后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序
/**
* 向下调整函数的实现
*
* @param parent 每棵树的根节点
* @param len 每棵树的调整的结束位置
*/
public void shiftDown(int parent, int len) {
int child = 2 * parent + 1;
// 1. 至少有1个孩子
while (child < len) {
if (child + 1 < len && elem[child] < elem[child + 1]) {
child++;// 保证当前左右最大值的下标
}
if (elem[child] > elem[parent]) {
int tmp = elem[child];
elem[child] = elem[parent];
elem[parent] = tmp;
parent = child;
child = 2 * parent + 1;
} else {
break;
}
}
}
public void heapSort() {
int end = this.usedSize-1;
while (end > 0) {
int tmp = elem[0];
elem[0] = elem[end];
elem[end] = tmp;
shiftDown(0, end);
end--;
}
}
六、经典的TOPK问题
设计一个算法,找出数组中最小的个数。以任意顺序返回这K个数。
- sort排序:取前K个元素
- 二叉搜索树:按照中序遍历回收K个数据
- 优先级队列:peek,poll
6.1 排序
对原数组从小到大排序后取出前 kk 个数即可。
class Solution {
public int[] smallestK(int[] arr, int k) {
int[] vec = new int[k];
Arrays.sort(arr);
for (int i = 0; i < k; ++i) {
vec[i] = arr[i];
}
return vec;
}
}
- 时间复杂度:O(n*log n),其中 n 是数组 arr 的长度。算法的时间复杂度即排序的时间复杂度。
- 空间复杂度:O(logn),排序所需额外的空间复杂度为 O(logn)。

6.2 堆
我们用一个大根堆实时维护数组的前 kk 小值。首先将前 kk 个数插入大根堆中,随后从第 k+1k+1 个数开始遍历,如果当前遍历到的数比大根堆的堆顶的数要小,就把堆顶的数弹出,再插入当前遍历到的数。最后将大根堆里的数存入数组返回即可。
class Solution {
public int[] smallestK(int[] arr, int k) {
// 参数检测
if(null == arr || k <= 0)
return new int[0];
PriorityQueue<Integer> q = new PriorityQueue<>(arr.length);
// 将数组中的元素依次放到堆中
for(int i = 0; i < arr.length; ++i){
q.offer(arr[i]);
}
// 将优先级队列的前k个元素放到数组中
int[] ret = new int[k];
for(int i = 0; i < k; ++i){
ret[i] = q.poll();
}
return ret;
}
}
- 时间复杂度:O(n* logk),其中 nn 是数组 arr 的长度。由于大根堆实时维护前 k 小值,所以插入删除都是 O(logk) 的时间复杂度,最坏情况下数组里 n 个数都会插入,所以一共需要 O(n*logk) 的时间复杂度。
- 空间复杂度:O(k),因为大根堆里最多 kk 个数。