etcd 备份与恢复
- 1. 先决条件
- 2. 内置快照
- 2.1 安装 etcd
- 2.2 获取 ENDPOINT 所提供的键空间的快照到文件 snapshotdb
- 注意!!!
- 在 harbor 仓库中准备好升级需要的镜像
- 控制平面节点:升级 kubeadm
- 控制平面节点:验证升级计划
- 控制平面节点:执行 kubeadm upgrade
- 控制平面节点:腾空节点
- 控制平面节点:升级 kubectl 和 kubelet
- 控制平面节点:解除节点保护
- 控制平面节点:验证节点状态
- 工作节点升级:升级 kubeadm
- 工作节点升级:执行 kubeadm upgrade node
- 工作节点升级:腾空节点
- 工作节点升级:升级 kubectl 和 kubelet
- 工作节点升级:取消节点的保护
- kubeadm 集群:验证集群的状态
- 3. 升级成功,进行 etcd 备份与恢复
- 3.1 获取 etcdctl 命令
- 3.2 创建 pod 资源
- 3.3 备份 etcd 数据
- 3.4 删除 pod 资源
- 3.5 恢复数据
- 3.5.1 关闭所有的组件
- 3.5.2 删除当前 etcd 的数据目录
- 3.5.3 开始恢复数据
- 3.5.4 运行所有的组件
- 3.6 验证集群的状态
- 4. 恢复成功!!!
官方文档:为 Kubernetes 运行 etcd | 备份 etcd 集群
1. 先决条件
-
etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
-
运行的 etcd 集群个数成员为奇数。
-
etcd 是一个 leader-based 分布式系统。确保主节点定期向所有从节点发送心跳,以保持集群稳定。
-
确保不发生资源不足。
集群的性能和稳定性对网络和磁盘 I/O 非常敏感。任何资源匮乏都会导致心跳超时, 从而导致集群的不稳定。不稳定的情况表明没有选出任何主节点。 在这种情况下,集群不能对其当前状态进行任何更改,这意味着不能调度新的 pod。
-
所有 Kubernetes 对象都存储在 etcd 上。定期备份 etcd 集群数据对于在灾难场景(例如丢失所有控制平面节点)下恢复 Kubernetes 集群非常重要。 快照文件包含所有 Kubernetes 状态和关键信息。为了保证敏感的 Kubernetes 数据的安全,可以对快照文件进行加密。
备份 etcd 集群可以通过两种方式完成:etcd 内置快照 和 卷快照。
2. 内置快照
- etcd 支持内置快照。快照可以从使用 etcdctl snapshot save 命令的活动成员中获取, 也可以通过从 etcd 数据目录 复制 member/snap/db 文件,该 etcd 数据目录目前没有被 etcd 进程使用。获取快照不会影响成员的性能。
2.1 安装 etcd
- 集群组件中没有 etcd
[root@k8s1 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-bdc44d9f-frm2b 1/1 Running 0 3m8s
coredns-bdc44d9f-xhlbg 1/1 Running 0 3m8s
etcd-k8s1 1/1 Running 1 3m28s
kube-apiserver-k8s1 1/1 Running 1 3m28s
kube-controller-manager-k8s1 1/1 Running 2 3m26s
kube-flannel-ds-59ndm 1/1 Running 0 2m42s
kube-flannel-ds-jmtfd 1/1 Running 0 98s
kube-flannel-ds-njlz7 1/1 Running 0 83s
kube-proxy-9qb29 1/1 Running 0 3m8s
kube-proxy-cl5w6 1/1 Running 0 83s
kube-proxy-t5mlj 1/1 Running 0 98s
kube-scheduler-k8s1 1/1 Running 2 3m28s
- 安装 etcd
[root@k8s1 ~]# yum install -y etcd
2.2 获取 ENDPOINT 所提供的键空间的快照到文件 snapshotdb
- 通过指定端点,证书等来拍摄快照
[root@k8s1 ~]# ETCDCTL_API=3 etcdctl --endpoints 127.0.0.1:2379 --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --cacert=/etc/kubernetes/pki/etcd/ca.crt member list
22f19206c985d9c7, started, k8s1, https://172.25.21.1:2380, https://172.25.21.1:2379
- 用表格的形式查看快照文件
[root@k8s1 ~]# ETCDCTL_API=3 etcdctl --endpoints 127.0.0.1:2379 --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --cacert=/etc/kubernetes/pki/etcd/ca.crt member list -w table
+------------------+---------+------+--------------------------+--------------------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS |
+------------------+---------+------+--------------------------+--------------------------+
| 22f19206c985d9c7 | started | k8s1 | https://172.25.21.1:2380 | https://172.25.21.1:2379 |
+------------------+---------+------+--------------------------+--------------------------+
[root@k8s1 ~]# ETCDCTL_API=3 etcdctl --endpoints 127.0.0.1:2379 --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --cacert=/etc/kubernetes/pki/etcd/ca.crt endpoint status -w table
+----------------+------------------+---------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+----------------+------------------+---------+---------+-----------+-----------+------------+
| 127.0.0.1:2379 | 22f19206c985d9c7 | 3.5.0 | 2.6 MB | true | 2 | 1553 |
+----------------+------------------+---------+---------+-----------+-----------+------------+
- 查看信息
[root@k8s1 ~]# ETCDCTL_API=3 etcdctl --endpoints 127.0.0.1:2379 --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --cacert=/etc/kubernetes/pki/etcd/ca.crt get / --prefix
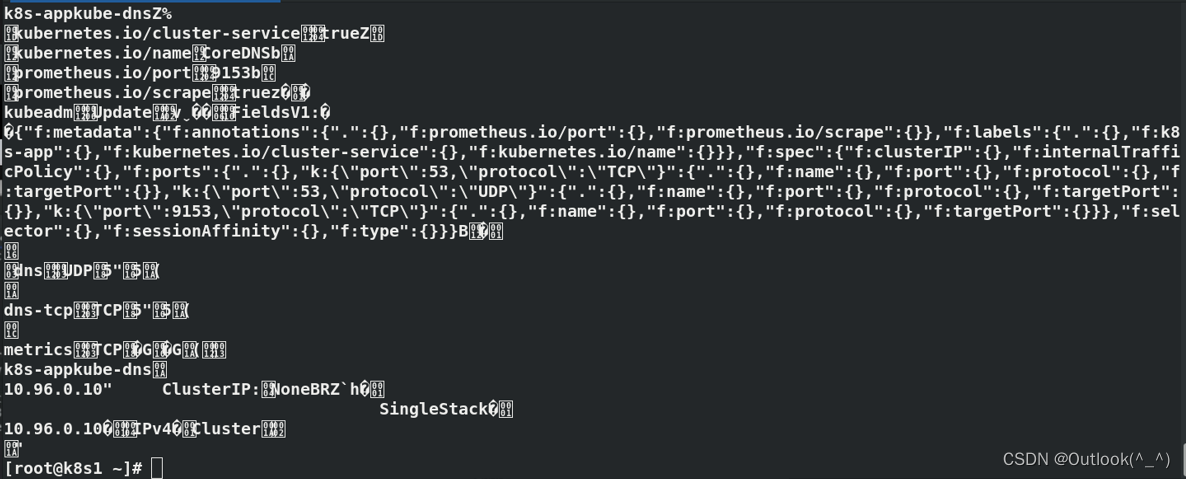
- 查看到pod demo的key
[root@k8s1 ~]# kubectl run demo --image=nginx
pod/demo created
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
demo 1/1 Running 0 59s
[root@k8s1 ~]# ETCDCTL_API=3 etcdctl --endpoints 127.0.0.1:2379 --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --cacert=/etc/kubernetes/pki/etcd/ca.crt get /registry/pods --prefix --keys-only
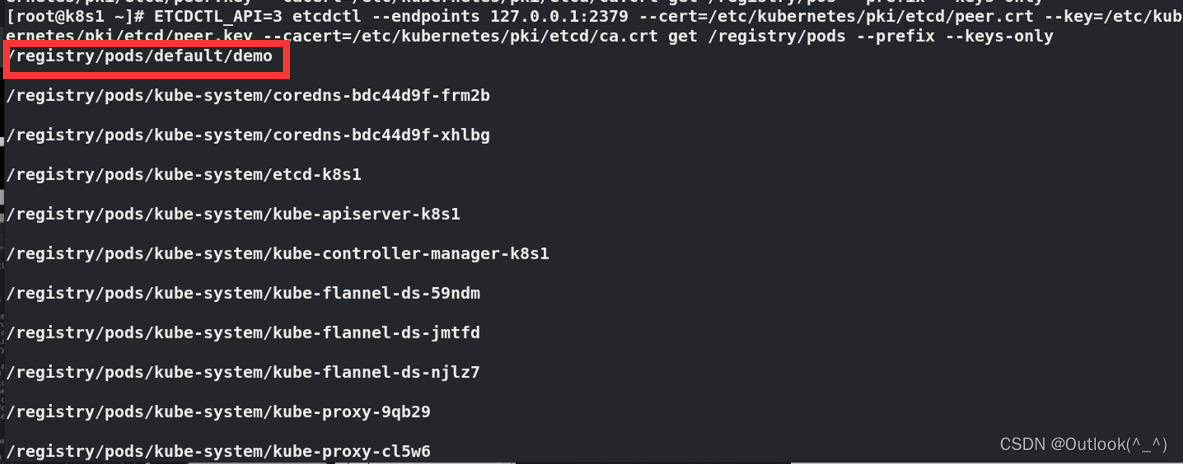
- kubectl 在创建 pod 时,会将信息写入 etcd,调度器会去 etcd 读取,然后调度到worker节点,
kubelet开始拉起pod(通过runtime)
- 备份数据
[root@k8s1 ~]# ETCDCTL_API=3 etcdctl --endpoints 127.0.0.1:2379 --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --cacert=/etc/kubernetes/pki/etcd/ca.crt snapshot save /tmp/backup/`hostname`-etcd-`date +%Y%m%d%H%M`.db
Snapshot saved at /tmp/backup/k8s1-etcd-202204232220.db
注意!!!
-
在做备份和恢复的时候,出现了问题。
问题是当将备份的数据 etcd 恢复后,发现 etcd 服务是起不来的,
分析后,认为原因可能是出在了 kubeadm 集群的版本和 etcd 的 3.3 版本不合适。
因此,我将之前版本为 1.22.2 的 kubeadm 集群又进行了一次升级,版本为 1.23.1 -
etcd 的版本是3.3,kubeadm 集群的版本应该在 1.23.1以上
[root@k8s1 ~]# yum list etcd
Loaded plugins: product-id, search-disabled-repos, subscription-manager
This system is not registered with an entitlement server. You can use subscription-manager to register.
Installed Packages
etcd.x86_64 3.3.11-2.el7.centos @extras
[root@k8s1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s1 Ready control-plane,master 2d v1.22.2
k8s2 Ready <none> 2d v1.22.2
k8s3 Ready <none> 2d v1.22.2
在 harbor 仓库中准备好升级需要的镜像
- 首先需要进入harbor的目录才能使用compose命令开启服务
- 存在第一个 error,解决方法:进入 harbor 配置目录进行服务的启动
[root@k8s4 ~]# docker-compose start
ERROR:
Can't find a suitable configuration file in this directory or any
parent. Are you in the right directory?
Supported filenames: docker-compose.yml, docker-compose.yaml
[root@k8s4 ~]# cd harbor/
[root@k8s4 harbor]# ls
common common.sh docker-compose.yml harbor.v1.10.1.tar.gz harbor.yml install.sh LICENSE prepare
[root@k8s4 harbor]# docker-compose start
Starting log ... done
Starting registry ... done
Starting registryctl ... done
Starting postgresql ... done
Starting portal ... done
Starting redis ... done
Starting core ... done
Starting jobservice ... done
Starting proxy ... done
- 存在第二个 error,解决方法:进行仓库的登陆
docker login
[root@k8s4 ~]# docker pull registry.aliyuncs.com/google_containers/kubeadm:v1.23.1
Error response from daemon: pull access denied for registry.aliyuncs.com/google_containers/kubeadm, repository does not exist or may require 'docker login': denied: requested access to the resource is denied
[root@k8s4 ~]# docker login reg.westos.org
Authenticating with existing credentials...
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
- harbor 仓库下载需要版本的组件
- 先拉取
[root@k8s4 ~]# docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.23.1
[root@k8s4 ~]# docker pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.23.1
[root@k8s4 ~]# docker pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.23.1
[root@k8s4 ~]# docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.23.1
- 再改名字
[root@k8s4 ~]# docker tag registry.aliyuncs.com/google_containers/kube-apiserver:v1.23.1 reg.westos.org/k8s/kube-apiserver:v1.23.1
[root@k8s4 ~]# docker tag registry.aliyuncs.com/google_containers/kube-controller-manager:v1.23.1 reg.westos.org/k8s/kube-controller-manager:v1.23.1
[root@k8s4 ~]# docker tag registry.aliyuncs.com/google_containers/kube-scheduler:v1.23.1 reg.westos.org/k8s/kube-scheduler:v1.23.1
[root@k8s4 ~]# docker tag registry.aliyuncs.com/google_containers/kube-proxy:v1.23.1 reg.westos.org/k8s/kube-proxy:v1.23.1
- 最后上传
[root@k8s4 ~]# docker push reg.westos.org/k8s/kube-apiserver:v1.23.1
[root@k8s4 ~]# docker push reg.westos.org/k8s/kube-controller-manager:v1.23.1
[root@k8s4 ~]# docker push reg.westos.org/k8s/kube-scheduler:v1.23.1
[root@k8s4 ~]# docker push reg.westos.org/k8s/kube-proxy:v1.23.1
控制平面节点:升级 kubeadm
[root@k8s1 ~]# yum install -y kubeadm-1.23.1-0
[root@k8s1 ~]# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.1", GitCommit:"86ec240af8cbd1b60bcc4c03c20da9b98005b92e", GitTreeState:"clean", BuildDate:"2021-12-16T11:39:51Z", GoVersion:"go1.17.5", Compiler:"gc", Platform:"linux/amd64"}
控制平面节点:验证升级计划
[root@k8s1 ~]# kubeadm upgrade plan
[upgrade/config] Making sure the configuration is correct:
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[preflight] Running pre-flight checks.
[upgrade] Running cluster health checks
[upgrade] Fetching available versions to upgrade to
[upgrade/versions] Cluster version: v1.22.1
[upgrade/versions] kubeadm version: v1.23.1
[upgrade/versions] Target version: v1.23.6
[upgrade/versions] Latest version in the v1.22 series: v1.22.9
Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply':
COMPONENT CURRENT TARGET
kubelet 3 x v1.22.2 v1.22.9
Upgrade to the latest version in the v1.22 series:
COMPONENT CURRENT TARGET
kube-apiserver v1.22.1 v1.22.9
kube-controller-manager v1.22.1 v1.22.9
kube-scheduler v1.22.1 v1.22.9
kube-proxy v1.22.1 v1.22.9
CoreDNS v1.8.4 v1.8.6
etcd 3.5.0-0 3.5.1-0
You can now apply the upgrade by executing the following command:
kubeadm upgrade apply v1.22.9
_____________________________________________________________________
Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply':
COMPONENT CURRENT TARGET
kubelet 3 x v1.22.2 v1.23.6
Upgrade to the latest stable version:
COMPONENT CURRENT TARGET
kube-apiserver v1.22.1 v1.23.6
kube-controller-manager v1.22.1 v1.23.6
kube-scheduler v1.22.1 v1.23.6
kube-proxy v1.22.1 v1.23.6
CoreDNS v1.8.4 v1.8.6
etcd 3.5.0-0 3.5.1-0
You can now apply the upgrade by executing the following command:
kubeadm upgrade apply v1.23.6
Note: Before you can perform this upgrade, you have to update kubeadm to v1.23.6.
_____________________________________________________________________
The table below shows the current state of component configs as understood by this version of kubeadm.
Configs that have a "yes" mark in the "MANUAL UPGRADE REQUIRED" column require manual config upgrade or
resetting to kubeadm defaults before a successful upgrade can be performed. The version to manually
upgrade to is denoted in the "PREFERRED VERSION" column.
API GROUP CURRENT VERSION PREFERRED VERSION MANUAL UPGRADE REQUIRED
kubeproxy.config.k8s.io v1alpha1 v1alpha1 no
kubelet.config.k8s.io v1beta1 v1beta1 no
_____________________________________________________________________
控制平面节点:执行 kubeadm upgrade
[root@k8s1 ~]# kubeadm upgrade apply v1.23.1
......
[upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.23.1". Enjoy!
[upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven't already done so.
控制平面节点:腾空节点
[root@k8s1 ~]# kubectl drain k8s1 --ignore-daemonsets
node/k8s1 already cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/kube-flannel-ds-59ndm, kube-system/kube-proxy-t4zpd
node/k8s1 drained
[root@k8s1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s1 Ready,SchedulingDisabled control-plane,master 2d v1.22.2
k8s2 Ready <none> 2d v1.22.2
k8s3 Ready <none> 2d v1.22.2
控制平面节点:升级 kubectl 和 kubelet
[root@k8s1 ~]# yum install -y kubelet-1.23.1-0 kubectl-1.23.1-0
[root@k8s1 ~]# systemctl daemon-reload
[root@k8s1 ~]# systemctl restart kubelet.service
控制平面节点:解除节点保护
[root@k8s1 ~]# kubectl uncordon k8s1
node/k8s1 uncordoned
控制平面节点:验证节点状态
[root@k8s1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s1 Ready control-plane,master 2d v1.23.1
k8s2 Ready <none> 2d v1.22.2
k8s3 Ready <none> 2d v1.22.2
工作节点升级:升级 kubeadm
[root@k8s2 ~]# yum install -y kubeadm-1.23.1-0
工作节点升级:执行 kubeadm upgrade node
[root@k8s2 ~]# kubeadm upgrade node
[upgrade] Reading configuration from the cluster...
[upgrade] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[preflight] Running pre-flight checks
[preflight] Skipping prepull. Not a control plane node.
[upgrade] Skipping phase. Not a control plane node.
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[upgrade] The configuration for this node was successfully updated!
[upgrade] Now you should go ahead and upgrade the kubelet package using your package manager.
工作节点升级:腾空节点
[root@k8s1 ~]# kubectl drain k8s2 --ignore-daemonsets
node/k8s2 cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/kube-flannel-ds-jmtfd, kube-system/kube-proxy-fhnvc
evicting pod kube-system/coredns-7b56f6bc55-dgh4p
pod/coredns-7b56f6bc55-dgh4p evicted
node/k8s2 drained
工作节点升级:升级 kubectl 和 kubelet
[root@k8s2 ~]# yum install -y kubectl-1.23.1-0 kubelet-1.23.1-0
[root@k8s2 ~]# systemctl daemon-reload
[root@k8s2 ~]# systemctl restart kubelet.service
工作节点升级:取消节点的保护
[root@k8s1 ~]# kubectl uncordon k8s2
node/k8s2 uncordoned
- 第二个工作节点 k8s3 的升级过程不再赘述了,和 k8s2 的过程一样
kubeadm 集群:验证集群的状态
[root@k8s1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s1 Ready control-plane,master 2d v1.23.1
k8s2 Ready <none> 2d v1.23.1
k8s3 Ready <none> 2d v1.23.1
3. 升级成功,进行 etcd 备份与恢复
3.1 获取 etcdctl 命令
- 打开docker
systemctl start docker,交互式进入 3.5.1-0 版本的 etcd
[root@k8s1 ~]# docker run -it --rm reg.westos.org/k8s/etcd:3.5.1-0 sh
sh-5.1# sh-5.1#
- 打开一个新的终端
[root@k8s1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d6c7021afde3 reg.westos.org/k8s/etcd:3.5.1-0 "sh" 42 seconds ago Up 40 seconds 2379-2380/tcp, 4001/tcp, 7001/tcp crazy_goodall
- 拷贝得到 etcdctl 命令,之后使用的 etcdctl 命令都是这个
[root@k8s1 ~]# docker cp d6c7021afde3:/usr/local/bin/etcdctl .
[root@k8s1 ~]# ll etcdctl
-r-xr-xr-x 1 root root 17981440 Nov 3 12:14 etcdctl
- 退出容器
[root@k8s1 ~]# docker run -it --rm reg.westos.org/k8s/etcd:3.5.1-0 sh
sh-5.1# sh-5.1# ^C
sh-5.1# exit
3.2 创建 pod 资源
- pod 的名称是 test
[root@k8s1 ~]# kubectl run test --image=nginx
pod/test created
[root@k8s1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
test 1/1 Running 0 94s
3.3 备份 etcd 数据
- 备份,生成快照文件
[root@k8s1 ~]# ETCDCTL_API=3 etcdctl --endpoints 127.0.0.1:2379 --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --cacert=/etc/kubernetes/pki/etcd/ca.crt snapshot save /tmp/backup/`hostname`-etcd-`date +%Y%m%d%H%M`.db
Snapshot saved at /tmp/backup/k8s1-etcd-202204232220.db
- 查看备份状态
- 注意,这次备份的数据中包含了创建的 pod 资源 test
[root@k8s1 ~]# ETCDCTL_API=3 etcdctl snapshot status /tmp/backup/k8s1-etcd-202204232220.db
f99920fc, 9452, 1431, 3.8 MB
3.4 删除 pod 资源
- 我们要做的是备份包含 test 的 pod 资源。删除 pod后,通过单机恢复的方式将 test 的 pod 资源恢复
[root@k8s1 ~]# kubectl delete --force pod test
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
pod "test" force deleted
3.5 恢复数据
3.5.1 关闭所有的组件
- 将 /etc/kubernetes/ 下的 manifest 目录进行备份,kubernetes 就会找不到配置数据,会自动宕掉
[root@k8s1 ~]# cd /etc/kubernetes/
[root@k8s1 kubernetes]# ls
admin.conf controller-manager.conf kubelet.conf manifests pki scheduler.conf tmp
[root@k8s1 kubernetes]# mv manifests/ manifests.bak
[root@k8s1 kubernetes]# ls
admin.conf controller-manager.conf kubelet.conf manifests.bak pki scheduler.conf tmp
- 通过 crictl 命令查看到部分组件服务宕掉了
[root@k8s1 kubernetes]# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
00a2c92eab979 a4ca41631cc7a 35 minutes ago Running coredns 0 39c40f3e94642
3dd14316876bf b46c42588d511 42 minutes ago Running kube-proxy 0 d7f3f39d341b0
a353f5362f207 9247abf086779 About an hour ago Running kube-flannel 1 f060899b44344
3.5.2 删除当前 etcd 的数据目录
- 将当前 etcd 的数据目录 /var/lib/etcd 进行备份(可以理解为删除)
[root@k8s1 kubernetes]# cd /var/lib/
[root@k8s1 lib]# mv etcd etcd.bak
3.5.3 开始恢复数据
- 需要的话,可以执行数据目录的位置
[root@k8s1 lib]# ETCDCTL_API=3 etcdctl snapshot restore /tmp/backup/k8s1-etcd-202204232220.db --data-dir=/var/lib/etcd
2022-04-23 22:28:22.580862 I | mvcc: restore compact to 8778
2022-04-23 22:28:22.632531 I | etcdserver/membership: added member 8e9e05c52164694d [http://localhost:2380] to cluster cdf818194e3a8c32
3.5.4 运行所有的组件
- 回到 kubernetes 的配置目录下,恢复 manifest 目录
[root@k8s1 lib]# cd /etc/kubernetes/
[root@k8s1 kubernetes]# mv manifests.bak manifests
- 重启守护进程 kubelet
[root@k8s1 kubernetes]# systemctl restart kubelet.service
3.6 验证集群的状态
- 检查 kubernetes 的服务是否恢复正常
[root@k8s1 kubernetes]# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
d73374d629173 b6d7abedde399 30 seconds ago Running kube-apiserver 0 a6ce154f8ed39
9644257cc5b79 71d575efe6283 30 seconds ago Running kube-scheduler 0 69a86c32d82c2
9d2c7fdfae301 25f8c7f3da61c 30 seconds ago Running etcd 0 a156d32b4bfca
89501643a9ba6 f51846a4fd288 30 seconds ago Running kube-controller-manager 0 e2f0acade1880
00a2c92eab979 a4ca41631cc7a 38 minutes ago Running coredns 0 39c40f3e94642
3dd14316876bf b46c42588d511 46 minutes ago Running kube-proxy 0 d7f3f39d341b0
a353f5362f207 9247abf086779 About an hour ago Running kube-flannel 1 f060899b44344
- 之前创建的 pod 资源 test 被恢复
[root@k8s1 kubernetes]# kubectl get pod
NAME READY STATUS RESTARTS AGE
test 1/1 Running 0 19m
4. 恢复成功!!!
tips:
第二个问题 单机恢复
【【【退出ssh的master节点,进入base环境】】】
(就2个命令)
先备份
ETCDCTL 3 save 路径tmp(路径不要手敲,复制网页的,浪费时间)
cd var lib
将etcd.bak 恢复成etcd