目录
前言:
MySQL体系结构图:
存储引擎简介:
1. InnoDB存储引擎:
2. MyISAM存储引擎:
3. MEMORY存储引擎:
4. NDB Cluster存储引擎:
5. ARCHIVE存储引擎:
存储引擎语法:
ACID与行级锁:
总结:
前言:
经过前面15篇的学习,我们已经学完了SQL的基本语法内容,大致掌握了数据库的操作,而接下来我们将进行SQL的进阶学习,今天我们要学习的内容为:MySQL的存储引擎。
MySQL体系结构图:

MySQL的结构体系主要包含以下几个方面的内容:
1. 服务器层(Server Layer):提供了MySQL的核心服务,包括连接管理、查询解析、优化等功能。
2. 存储引擎(Storage Engine):提供了数据的存储和访问服务。MySQL自身支持多种存储引擎,如InnoDB、MyISAM等,每种存储引擎都有自己特有的特点和功能。
3. 网络层(Connection Layer):提供了MySQL与客户端之间的通讯服务,支持多种协议,如TCP/IP、HTTP等。
4. 应用编程接口(Application Programming Interfaces,APIs):提供了多种编程接口,包括C、C++、Python等接口,以方便应用程序与MySQL进行交互操作。
MySQL的整个体系结构主要是由这几个部分组成的,其中服务器层和存储引擎层是MySQL核心的组成部分,分别负责提供核心服务和数据的存储和访问服务。网络层和应用编程接口层则提供了与客户端和应用程序之间交互操作的相关服务。这些组成部分配合使用,构成了MySQL强大、灵活的系统结构。
InnoDB是MySQL5.5版本后的默认使用存储引擎。
存储引擎简介:
存储引擎就是存储数据,建立索引,更新/查询数据等技术的实现方式。存储引擎是基于表的,而不是基于库的,所以存储引擎也被称为是表结构。
MySQL中的存储引擎是处理数据存储和检索方面的核心组件。MySQL支持多种不同的存储引擎,这些存储引擎在某些方面有着自己的独特优势。
常见的MySQL存储引擎包括以下几种:
1. InnoDB存储引擎:
InnoDB存储引擎是MySQL中最常用的一个存储引擎,也是默认的存储引擎。它支持ACID事务,具有行级锁定和外键约束等特性,适合于应用于事务性和高并发的应用程序。InnoDB支持数据的热备份和恢复,并提供了高效的缓存机制。
2. MyISAM存储引擎:
MyISAM不支持事务,并且对于更新操作会锁定整个表,但是在插入和查询方面性能非常好。对于只读应用、或者单线程的应用,使用MyISAM可以获得更好的性能。MyISAM表的特点是表锁定,速度快,但是不支持事务,也不支持外键等约束。
3. MEMORY存储引擎:
MEMORY存储引擎是将表数据存储在内存中,适用于一些处理销售、环境监测等数据的场景。MEMORY是一个非常快速的存储引擎,但是它的缺点是,当服务器关闭进程或者崩溃时,表数据就被清空了。MEMORY还支持Hash索引,这极大的提高了查询效率。
4. NDB Cluster存储引擎:
NDB Cluster可以将一个数据库拆分成多个节点,每个节点都维护一个数据子集,并协同工作以支持完整的数据库操作。这种存储引擎用于大规模、高可用性的数据中心。
5. ARCHIVE存储引擎:
ARCHIVE存储引擎是一种仅用于存档目的的存储引擎,适用于一些数据日志、快照备份等场景。它旨在提供一个非常低的磁盘空间消耗和一个高性能的压缩和解压缩能力,不支持索引、更新和删除操作,常用于写入数据后压缩存档。
不同的存储引擎在性能、特性、使用场景等方面各不相同,开发者在使用MySQL时需要根据需求选择合适的存储引擎。
存储引擎语法:
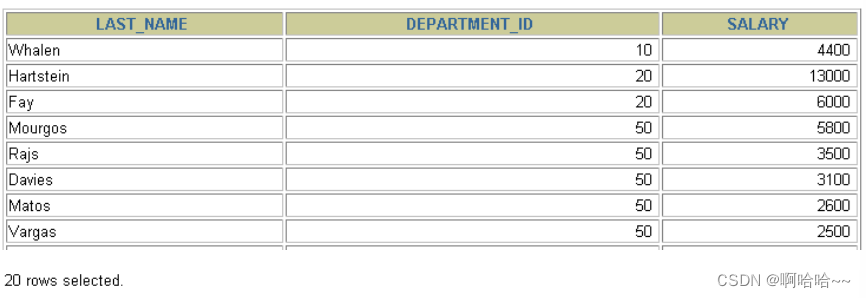
1.查询当前表的引擎:
show create table 表名;运行结果:
2.在创建表的时候指定存储引擎:
create table name(
字段1 字段类型
....
字段2 字段类型
) ENGINE = 引擎类型;实例:
create table try(
id int
) engine = MyISAM;运行结果:
3.查询当前数据库支持的引擎类型:
show engines ;运行结果:
ACID与行级锁:
ACID
是一个表示事务处理基本原则的缩写,包括以下四个方面:
原子性(Atomicity):一个事务被视为一个原子操作,它将所有的任务都视为一个整体(如果其中有一部分操作失败,整个事务就会被回滚),要么全部完成,要么全部不完成。
一致性(Consistency):在事务开始之前和事务结束之后,数据库的状态必须保持一致,这意味着事务执行中间不能破坏数据库的完整性约束。
隔离性(Isolation):隔离性指在数据库执行多个事务时,每个事务都应该是完全独立的,执行它们的顺序不应该影响结果。
持久性(Durability):持久性是指在事务完成之后,其产生的结果必须永久保存在数据库中,即使出现了硬件故障或其他系统故障,也不能影响已提交的事务结果。
行级锁:
行级锁(Row-Level Lock)是数据库管理系统(DBMS)中的一种锁机制,在处理并发读写时,对每一行数据进行锁定,以保证同时读写的数据不会冲突。与传统的表级锁(Table-Level Lock)不同,行级锁可以在只对某一行进行加锁的情况下,并发地处理多个事务,从而提高数据处理的效率。
行级锁的工作原理是:在对一行数据进行修改/删除操作之前,向该行添加一个锁定标记,直到事务完成或在commit/rollback之后才释放这行锁定标记。
行级锁的主要优点包括:
1. 提高了并发性:行级锁可以锁定单独的行而不是整个表,这意味着在并发访问时可以更加高效的实现读和写的操作。
2. 减少了锁定冲突:使用行级锁可以减少锁定并发访问带来的冲突,避免了串行化操作,从而提高了执行效率。
3. 支持更高的事务处理能力:通过优化锁机制,行级锁降低了锁等待时间和锁竞争的频率,从而支持更高的事务处理能力。
需要注意的是,行级锁在使用时需要控制两个方面的问题:锁定粒度和锁定时间。锁的粒度太细,可能会导致锁定的数据量过大,导致锁竞争的开销过大;锁的时间过长,又可能会影响并发读写性能。因此在使用行级锁时,需要权衡粒度和时间两个方面的因素,并根据实际应用需求进行适当调整。
总结:
存储引擎就是存储数据,建立索引,更新/查询数据等技术的实现方式。 我们根据不同的需求来选择不同的引擎来处理表数据,可以使得效率大大提高。
今天的内容到这里就结束了,感谢大家的阅读。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!