今天,随着数据量的不断增加,数据可视化成为将数字变成可用的信息的一个重要方式。R语言提供了一系列的已有函数和可调用的库,通过建立可视化的方式进行数据的呈现。在使用技术的方式实现可视化之前,我们可以先和AI科技评论一起看看如何选择正确的图表类型。
作者 Dikesh Jariwala是一个软件工程师,并且在Tatvic平台上编写了一些很酷很有趣的程序。他用API编写了第一版Price Discovery,AI科技评论对他所写的这篇文章做了编译,未经许可不得转载。
如何选择正确的图表类型
四种可选择的基本类型:
1. 比较类图表
2. 组成类图表
3. 分布类图表
4. 关系类图表
为了选择最适合分析手中数据的图表类型,首先考虑以下几个问题:
1. 单个图表里,需要几个变量?
2. 单个变量,需要用多少数据点来描述?
3. 数据是随时间的变量,还是离散的,以单体或组的形式?
针对如何选择最适宜的图表,Dr.Andrew Abela 提供了一个很好的方法示意图:
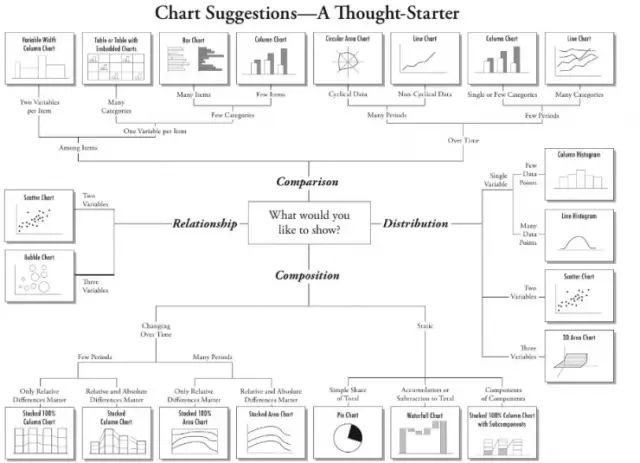
在使用图表分析的时候,常用的有7种图表:
1. 散点图
2. 直方图
3. 柱状图和条形图
4. 箱线图
5. 面积图
6. 热点图
7. 相关图
我们使用“Big Mart data”作为案例来理解 R 可视化的实现方法,你可以点击此处下载完整的数据(google doc)。
AI科技评论将在以下篇幅介绍如何利用 R 实现可视化:
1. 散点图
使用场景:散点图通常用于分析两个连续变量之间的关系。
在上面介绍的超市数据中,如果我们想根据他们的成本数据来可视化商品的知名度,我们可以用散点图,两个连续的变量这里我们命名为Item_Visibility和Item_MRP。
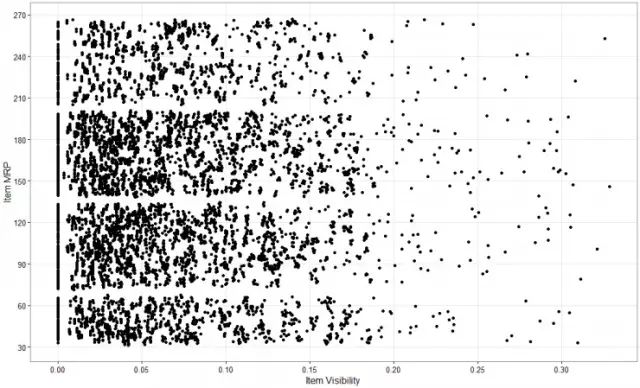
这里使用R中的ggplot()和geom_point()函数。
library(ggplot2) // ggplot2 是R中的一个函数库
ggplot(train, aes(Item_Visibility, Item_MRP)) + geom_point() + scale_x_continuous("Item
Visibility", breaks = seq(0,0.35,0.05))+ scale_y_continuous("Item MRP", breaks = seq(0,270,by =
30))+ theme_bw()
下图中增加了一个新的变量,对产品进行分类的变量,命名为Item_Type,图中以不同的颜色作为显示。
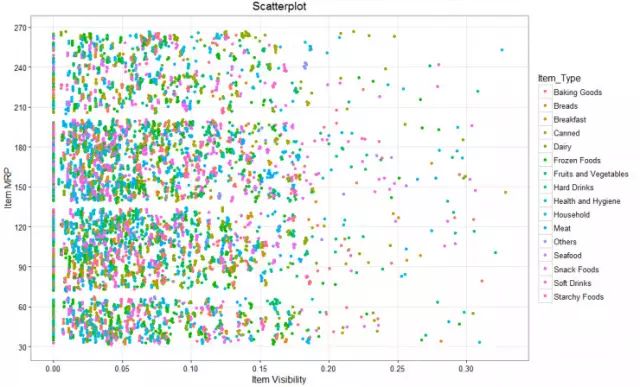
R代码中增加了分组:
ggplot(train, aes(Item_Visibility, Item_MRP)) + geom_point(aes(color = Item_Type)) +
scale_x_continuous("Item Visibility", breaks = seq(0,0.35,0.05))+
scale_y_continuous("Item MRP", breaks = seq(0,270,by = 30))+
theme_bw() + labs(title="Scatterplot")
可以进一步可视化,将散点图以不同的小图表的形式呈现,下图中,每一个小图表都代表一种不同的产品:
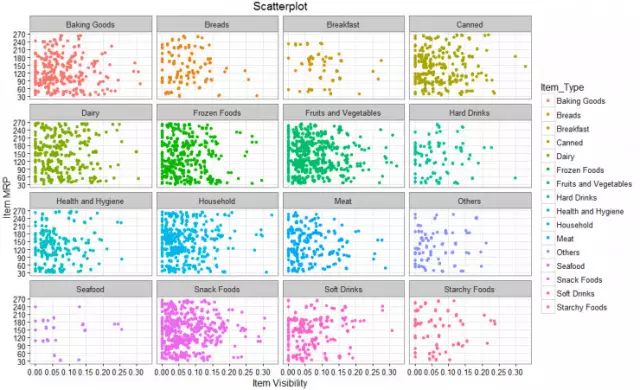
代码如下:
ggplot(train, aes(Item_Visibility, Item_MRP)) + geom_point(aes(color = Item_Type)) +
scale_x_continuous("Item Visibility", breaks = seq(0,0.35,0.05))+
scale_y_continuous("Item MRP", breaks = seq(0,270,by = 30))+
theme_bw() + labs(title="Scatterplot") + facet_wrap( ~ Item_Type)
代码中,facet_warp将图像显示在长方形图表中。
2. 直方图
使用场景:直方图用于连续变量的可视化分析。将数据划分,并用概率的形式呈现数据的规律。我们可以将分类根据需求进行组合和拆分,从而通过这种方式看到数据的变化。
继续使用上面我们引入的超市数据的例子,如果我们需要知道不同成本段的商品的数量,我们可以将所有数据画出一个直方图,Item_MRP作为横坐标。如下图所示:

下面是一个简单的画直方图的例子,使用的是R中的ggplot()和geom_histogram()函数。
ggplot(train, aes(Item_MRP)) + geom_histogram(binwidth = 2)+
scale_x_continuous("Item MRP", breaks = seq(0,270,by = 30))+
scale_y_continuous("Count", breaks = seq(0,200,by = 20))+
labs(title = "Histogram")
3. 柱状图和条形图
使用场景:柱状图一般用于表现分类的变量或者是连续的分类变量的组合。
在超市数据的例子中,如果我们需要知道在每一年新开的超市的门店数量,那么柱状图就是一个很好的图形分析的方式。用“年”的信息作为坐标,如下图所示:
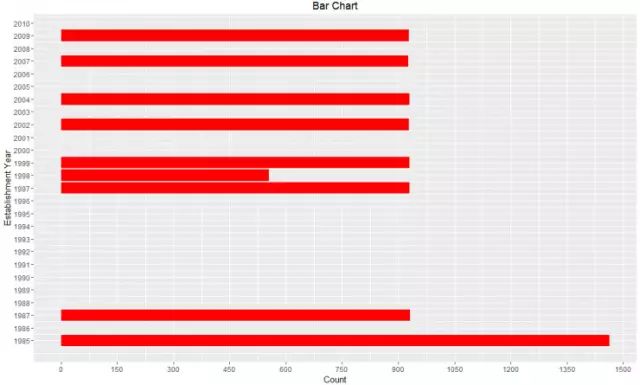
下面是一个简单的画柱状图的例子,使用的是R中的ggplot()函数。
ggplot(train, aes(Outlet_Establishment_Year)) + geom_bar(fill = "red")+theme_bw()+
scale_x_continuous("Establishment Year", breaks = seq(1985,2010)) +
scale_y_continuous("Count", breaks = seq(0,1500,150)) +
coord_flip()+ labs(title = "Bar Chart") + theme_gray()
水平柱状图
去除代码中的coord_flIP()变量,可以将直方图以水平直方图的方法呈现。
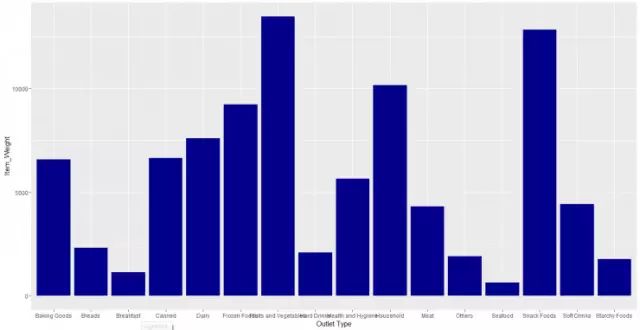
为了得到商品重量(连续变量)和折扣店(分类变量)的关系,可使用下面的代码:
ggplot(train, aes(Item_Type, Item_Weight)) + geom_bar(stat = "identity", fill = "darkblue") +
scale_x_discrete("Outlet Type")+ scale_y_continuous("Item Weight", breaks = seq(0,15000, by =
500))+ theme(axis.text.x = element_text(angle = 90, vjust = 0.5)) + labs(title = "Bar Chart")
堆叠条形图
堆叠条形图是柱状图的一个高级版本,可以将分类变量组合进行分析。
超市数据的例子中,如果我们想要知道不同分类商品的折扣店数量,包含折扣店种类和折扣店区域,堆叠条形图就是做这种分析最为有效的图表分析方法。
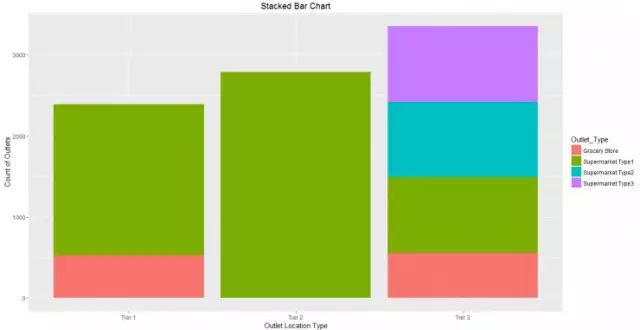
下面是一个简单的画堆叠条形图的例子,使用的是R中的ggplot()函数。
ggplot(train, aes(Outlet_Location_Type, fill = Outlet_Type)) + geom_bar()+
labs(title = "Stacked Bar Chart", x = "Outlet Location Type", y = "Count of Outlets")
4. 箱线图
使用场景:箱线图一般用于相对复杂的场景,通常是组合分类的连续变量。这种图表应用于对数据延伸的可视化分析和检测离值群。主要包含数据的5个重要节点,最小值,25%,50%,75%和最大值。
在我们的案例中,如果我们想要找出每个折扣店每个商品销售的价格的情况,包括最低价,最高价和中间价,箱线图就大有用处。除此之外,箱线图还可以提供非正常价格商品销售的情况,如下图所示。
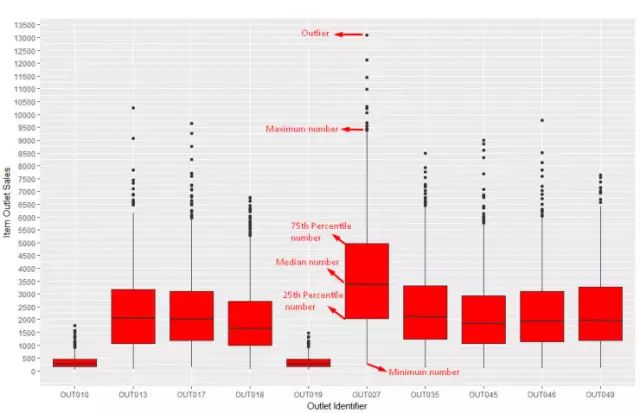
图中,黑色的点为离值群。离值群的检测和剔除是数据挖掘中很重要的环节。
下面是一个简单的画箱线图的例子,使用的是R中的ggplot()和geom_boxplot函数。
ggplot(train, aes(Outlet_Identifier, Item_Outlet_Sales)) + geom_boxplot(fill = "red")+
scale_y_continuous("Item Outlet Sales", breaks= seq(0,15000, by=500))+
labs(title = "Box Plot", x = "Outlet Identifier")
5. 面积图
使用场景:面积图通常用于显示变量和数据的连续性。和线性图很相近,是常用的时序分析方法。另外,它也被用来绘制连续变量和分析的基本趋势。
超市案例中,当我们需要知道随着时间的眼神,折扣店商品的品种走势,我们可以画出如下的面积图,图中呈现了折扣店商品的成交量的变化。

下面是一个简单的画面积图的例子,用于分析折扣店商品成交数量的走势,使用的是R中的ggplot()和geom_area函数。
ggplot(train, aes(Item_Outlet_Sales)) + geom_area(stat = "bin", bins = 30, fill = "steelblue") +
scale_x_continuous(breaks = seq(0,11000,1000))+
labs(title = "Area Chart", x = "Item Outlet Sales", y = "Count")
6. 热点图
使用场景:热点图用颜色的强度(密度)来显示二维图像中的两个或多个变量之间的关系。可对图表中三个部分的进行信息挖掘,两个坐标和图像颜色深度。
超市案例中,如果我们需要知道每个商品在每个折扣店的成本,如下图中所示,我们可以用三个变量Item_MRP,Outlet_Identifier和Item_type进行分析。
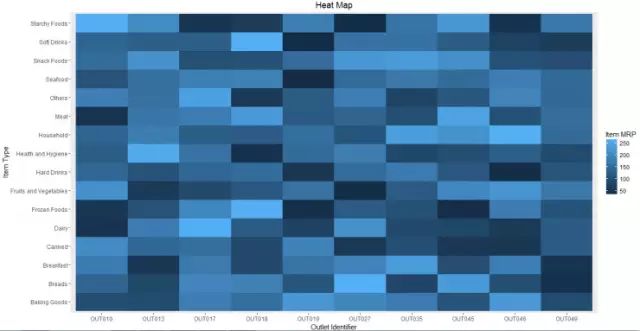
暗的数据表示Item_MRP低于50,亮的数据表示Item_MRP接近250。
下面是R代码,使用了ggplot()函数做简单的热点图。
ggplot(train, aes(Outlet_Identifier, Item_Type))+
geom_raster(aes(fill = Item_MRP))+
labs(title ="Heat Map", x = "Outlet Identifier", y = "Item Type")+
scale_fill_continuous(name = "Item MRP")
7. 关系图
使用场景:关系图用作表示连续变量之间的关联性。每个单元可以标注成阴影或颜色来表明关联的程度。颜色越深,代表关联程度越高。正相关用蓝色表示,负相关用红色表示。颜色的深度随着关联程度的递增而递增。
超市案例中,用下图可以展现成本,重量,知名度与折扣店开业的年份和销售价格之间的关系。可以发现,成本和售价成正相关,而商品的重量和知名度成负相关。

下面是用作简单关系图的R代码,使用的是corrgram()函数。
install.packages("corrgram")
library(corrgram)
corrgram(train, order=NULL, panel=panel.shade, text.panel=panel.txt,
main="Correlogram")
通过以上的分类介绍和R程序的简单介绍,相信你可以使用R中的ggplot库进行自己的数据可视化分析了。 除了可视化分析
原文:用数据说话,R语言有哪七种可视化应用?