在实际开发中,我们肯定希望提高MapReduce的工作效率,其实提高MapReduce的效率,无非就是提高Map阶段和Reduce阶段的效率。
Map阶段优化之小文件问题
我们知道Map阶段中的MapTask个数是与InputSplit的个数有关的,一般一个InputSplit切片对应一个,而且InputSplit的个数我们一般也无法控制,应为默认就是128MB,但是往往我们的文件并不是这样,而是大小不一,有的可能300MB,一个可能只有10KB,尤其是为一群几十KB的小文件一个划分一个InputSplit切片,实在浪费资源。
而且针对HDFS而言,每一个小文件在namenode中都会占用150字节的内存空间,最终会导致集群中虽然存储了很多个文件,但是文件的体积并不大,这样就没有意义了。
这就想到我之前的文章【自定义InputFormat】,我们可以这样来将多个小文件都合并到一个文件当中,进入map()方法后仍然需要我们进行处理才能使用,但这并不是标准的Sequence文件,它的输出键是一个文件名,值是我们文件的字节码,所以如果我们要实现一个WordCount,还需要进一步需要使用的话还需要针对每一行的值将字节码转为Stering,在做分词处理。而下面是真正生成一个Sequence文件的代码:
生成Sequence文件
我们需要将三个小文件合并成一个Sequence文件。
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.DefaultCodec;
import java.io.File;
/**
* 小文件解决方案之SequenceFile
*/
public class SmallFileSeq {
public static void main(String[] args) throws Exception{
//在hdfs中生成SequenceFile文件到临时目录下
// write("D:\\smallFile","/tmp/seqFile");
//读取SequenceFile文件
// read("/tmp/seqFile");
//在windows端生成SequenceFile文件
// write("D:\\MapReduce_Data_Test\\myinputformat\\input","D:\\MapReduce_Data_Test\\myinputformat\\outputSeq");
write("D:\\MapReduce_Data_Test\\sequence\\word\\","D:\\MapReduce_Data_Test\\sequence\\wordSeq");
//读取SequenceFile文件 注意是文件地址 不是目录地址
// read("D:\\MapReduce_Data_Test\\myinputformat\\outputSeq");
}
/**
* 生成SequenceFile文件
* @param inputDir 输入目录-windows目录
* @param outputFile 输出文件-hdfs文件
* @throws Exception
*/
private static void write(String inputDir,String outputFile)
throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
// conf.set("fs.defaultFS","hdfs://hadoop102:9000");
//获取操作文件系统对象
FileSystem fileSystem = FileSystem.get(conf);
//删除输出文件
fileSystem.delete(new Path(outputFile),true);
//构造opts数组,有三个元素
/*
第一个是输出路径
第二个是key类型
第三个是value类型
*/
SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{
SequenceFile.Writer.file(new Path(outputFile)),
SequenceFile.Writer.keyClass(Text.class),
SequenceFile.Writer.valueClass(Text.class)};
//创建一个writer实例
SequenceFile.Writer writer = SequenceFile.createWriter(conf, opts);
//指定要压缩的文件的目录
File inputDirPath = new File(inputDir);
if(inputDirPath.isDirectory()){
File[] files = inputDirPath.listFiles();
for (File file : files) {
//获取文件全部内容
String content = FileUtils.readFileToString(file, "UTF-8");
//文件名作为key
Text key = new Text(file.getName());
//文件内容作为value
Text value = new Text(content);
writer.append(key,value);
}
}
writer.close();
}
/**
* 读取SequenceFile文件
* @param inputFile SequenceFile文件路径 注意是文件地址不是目录地址
* @throws Exception
*/
private static void read(String inputFile)
throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
// conf.set("fs.defaultFS","hdfs://hadoop102:9000");
// 指定windows端的文件路径,注意在Windows系统中,文件系统没有端口号的概念。因此,只需要使用file://协议指定文件路径即可连接本地文件系统。
conf.set("fs.defaultFS","file:///");
//创建阅读器
SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFile.Reader.file(new Path(inputFile)));
Text key = new Text();
Text value = new Text();
//循环读取数据
while(reader.next(key,value)){
//输出文件名称
System.out.print("文件名:"+key.toString()+",");
//输出文件的内容
System.out.println("文件内容:\n"+value.toString());
}
reader.close();
}
}
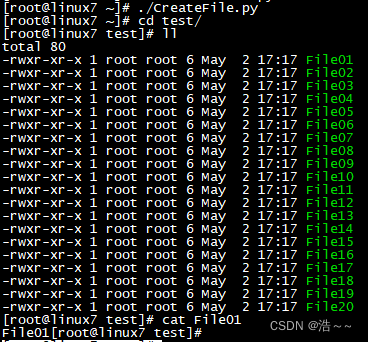
输入:

输出:

我们可以看到一共会输出两个文件,下面的 outputSeq是真正的Sequence文件 ,文件名是我们自己指定的,而上面的.outputSeq.crc则是一个校验码文件。
接下来要做的就是如何写一个MapReduce程序将我们的小文件内容从这个合并后的Sequence文件中读取出来
Mapper类
我们需要在Job中指定输入格式InputFormat为SequenceFileInputFormat,我们读取Sequence文件只需要指定键和值都为Text即可。
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
public class SeqMapper extends Mapper<Text, Text,Text,LongWritable> {
private Text OUT_KEY = new Text();
private LongWritable OUT_VALUE = new LongWritable(1);
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
System.out.println(line);
String[] words = StringUtils.split(line,'\t');
for (String word : words) {
System.out.println("key:" + word);
OUT_KEY.set(word);
context.write(OUT_KEY,OUT_VALUE);
}
}
}
Reducer类
依旧和之前的WordCount没什么两样。
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SeqReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
private LongWritable OUT_VALUE = new LongWritable();
@Override
public void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
long sum = 0;
for (LongWritable val : values) {
sum += val.get();
}
OUT_VALUE.set(sum);
context.write(key,OUT_VALUE);
}
}
Runner类
与之前不同的是修改输入格式为SequenceFileInputFormat,而且我们读取Sequence文件时,需要指定键和值的类型都为Text类型。
这个值并不是BytesWritable类型,如果设置为BytesWritable会报错:org.apache.hadoop.io.Text cannot be cast to org.apache.hadoop.io.BytesWritable。这就说明Sequence文件读取时的值类型为Text类型。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class SeqRunner extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(),new SeqRunner(),args);
}
@Override
public int run(String[] args) throws Exception {
//1.获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "sequence file word count");
//2.配置jar包路径
job.setJarByClass(SeqRunner.class);
//3.关联mapper和reducer
job.setMapperClass(SeqMapper.class);
job.setReducerClass(SeqReducer.class);
//设置输入格式为 Sequence文件格式
job.setInputFormatClass(SequenceFileInputFormat.class);
//4.设置map、reduce输出的k、v类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//5.设置统计文件输入的路径,将命令行的第一个参数作为输入文件的路径
FileInputFormat.setInputPaths(job,new Path("D:\\MapReduce_Data_Test\\sequence\\input"));
//6.设置结果数据存放路径,将命令行的第二个参数作为数据的输出路径
FileOutputFormat.setOutputPath(job,new Path("D:\\MapReduce_Data_Test\\sequence\\output"));
return job.waitForCompletion(true) ? 0 : 1;//verbose:是否监控并打印job的信息
}
}
输出: