凯明团队新作。
论文地址:https://arxiv.org/abs/2212.00794
一、问题
Even using high-end infrastructures, the wall-clock training time is still a major bottleneck hindering explorations on scaling vision-language learning.
即使使用高端的基础设施,wall-clock training time仍然是阻碍视觉语言学习规模化探索的主要瓶颈。
二、模型
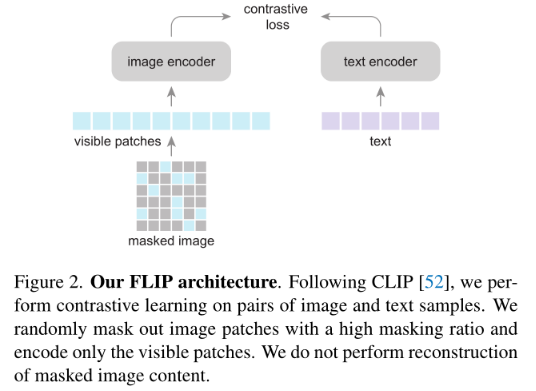
通过对图像patches的mask,有两点好处:
在相同的wall-clock training time下,从更多的图像-文本对中学习
在相同的内存约束下,对更大的batch有一个对比目标。
1、细节
Image masking.
image encoder采用ViT-L/16,mask patches ratio为50%、75%。mask50%(或者75%)可以将Vit编码的时间复杂度减低1/2(或者1/4)。在同内存成本下,可以采用2* (或者4*)的batch size。
Text masking.
由于文本编码器较小,没有进行mask
Objective.
只进行对比学习,不使用MAE进行decoder。因此只有对比学习损失。
Unmasking.
虽然编码器是预训练masked image,但是可以应用于完整的图像。(下游推理不用mask)
2、实现
在图像编码器的末尾使用global average pooling。输入尺寸为224,文本编码器是一种非自回归变压器,WordPiece tokenizer,将序列填充或剪切为固定的长度32。CLIP使用自回归文本编码器、BytePairEncoding标记器和77的长度,这些设计产生了微小的差异。
图像编码器和文本编码器的输出通过线性层投影到同维embedding空间。通过可学习温度参数缩放的embedding余弦相似度是InfoNCE损耗的输入。在zero-shot中,使用他们提供的7个prompt template进行ImageNet ImageNet zero-shot transfer。在TPU v3上训练。
三、Experiments
1、Ablations
在LAION-400M上进行训练,并在ImageNet-1K验证上评估zero-shot精度。
Masking ratio. 更改mask ratio,保持相同的内存占用。FLOPs大量减少,训练时间减少。
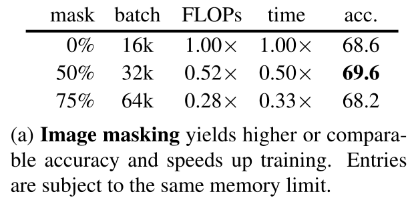
Batch size. 在上面(a),mask 50%时精度acc有提升,可能是batch_size带来的增益。因此有实验:
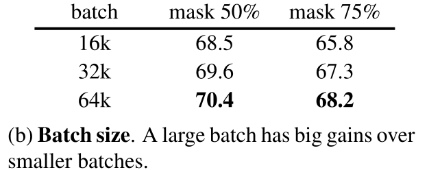
可以看到mask50% mask75%随着batch size的增大,精度acc有提升,但是mask75%时,由于失去太多信息,因此在微调时效果acc不佳。
Text masking. (image进行masking了,自然就是text进行masking)

随机mask50%时acc降低2.2%。因为语言数据的信息密度比图像高,因此文本掩蔽率应该更低。
当对可变长度的文本序列进行填充以生成固定长度的批处理时,可以优先屏蔽填充的token。优先采样比均匀地随机屏蔽填充序列保留更多的有效标记。acc仅降低到0.4%。
总体速度增益很小。这是因为文本编码器更小,文本序列更短。与图像编码器相比,文本编码器的计算成本仅为4.4%(没有屏蔽)。在这种设置下,文本屏蔽不是一种值得的权衡,在其他实验中没有屏蔽文本。因此这里只对image masking。
Inference unmasking.
在推理阶段是否masking:

可以看到without masking精度是最高的。因为在推理阶段mask的话,会丢失很多信息。ensemble减少了差距,但仍然落后于简单的全视图推理。
Unmasked tuning.

前面是zero-shot,如果下游turning,acc有提升,表明调优可以有效地缩小预训练和推理之间的分布差距。
Reconstruction. 添加一个重构损失函数。遵循MAE:小的解码器和重建归一化图像像素。将重构损耗加到对比损耗中。

精度下降,说明重建具有较小的负面影响。虽然这可能是次优超参数(例如,平衡两个损失)的结果,但为简化,不使用重构损失,提高精度/时间的权衡
Accuracy vs. time trade-off.

FLIP明显比CLIP有更好的权衡。达到与CLIP相似的精度,同时享受>3×的加速。在相同的32 epoch下,FLIP比CLIP方法的准确率高约1%,速度快2倍(mask 50%)
2、Comparisons with CLIP
ImageNet zero-shot transfer

可以看到FLIP的效果比OpenCLIP、CLIP好。FLIP、OpenCLIP比CLIP好可能是训练数据带来的偏差。
ImageNet linear probing.

线性探测结果,即在具有冻结特征的目标数据集上训练一个线性分类器。FLIP的准确率为83.6%,比CLIP的准确率高1.0%。也比使用相同的SGD训练器传输的原始CLIP检查点高0.6%。
Zero-shot classification on more datasets.

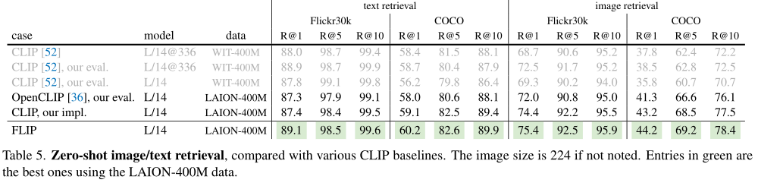
Zero-shot retrieval.
Zero-shot robustness evaluation.
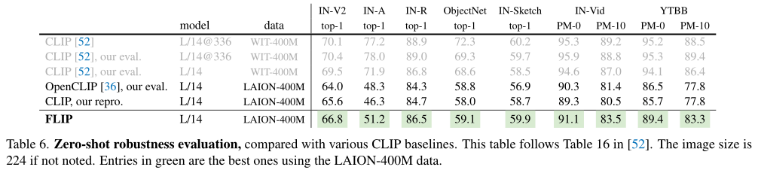
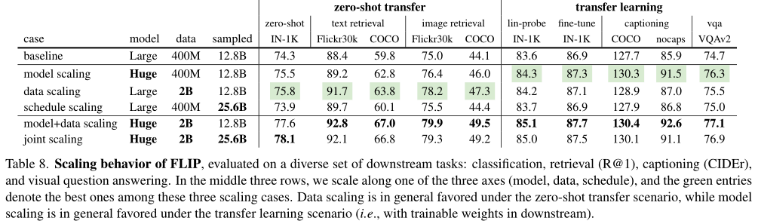
Image Captioning. Visual Question Answering.
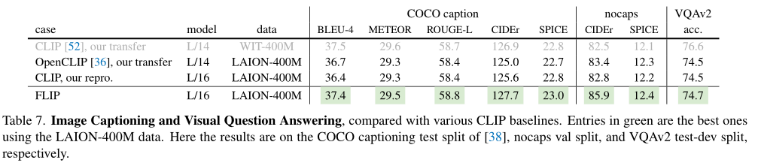
3、Scaling Behavior
Model scaling:ViT-H代替ViT-L,
Data scaling:使用LAION-2B,4亿→20亿
Schedule scaling:将采样数据从12.8B增加到25.6B
Training curves.

Transferability.
关于文章的个人经验(不一点适合全部图像、模型):
1、由于最近在做VLP预训练,发现Mask vision modeling(MAE架构),该任务对下游任务其实增益很少,甚至还有损耗。
2、采用预训练的MAE权重作为视觉分支的预训练权重,对下游任务是有提升的,因为visual encoder具备了一定的先验知识。
3、对于mask 50%的权重对下游任务的增益更大,mask75%时信息损失太多了,导致模型对部分内容是根据经常出现的元素在猜测,而不是根据现有信息推理。








![[附源码]计算机毕业设计JAVA疫情状况下生活物资集体团购系统](https://img-blog.csdnimg.cn/be2cd535e31546bc9206568ce4ebcda5.png)