Addressing Mistake Severity in Neural Networks with Semantic Knowledge
公众号:EDPJ
目录
0. 摘要
1. 简介
2. 相关工作
3. 方法
4. 实验
5. 结果
5.1 对抗扰动
5.2 自然损坏(Natural Corruptions)
6. 讨论与结论
7. 未来工作
8. 更广泛的影响
参考
S. 总结
S.1 主要思想
S.2 名词解释
S.3 方法
S.4 分析
0. 摘要
一般来说,深度神经网络和机器学习算法的稳健性是一项开放的研究挑战。 特别是,很难确保在训练时无法预期的分布外输入或异常实例上保持算法性能。实体代理(embodied agents),例如,机器人,将在这些条件下使用,并且很可能做出不正确的预测。 代理将被视为不可信任,除非它可以在动态环境中保持其性能。 大多数稳健的训练技术旨在提高模型对扰动输入的准确性; 作为鲁棒性的另一种形式,我们旨在减少神经网络在具有挑战性的条件下所犯错误的严重性(severity)。 我们利用当前的对抗性训练方法在训练过程中生成有目标性的对抗性攻击,以增加模型预测与错误分类的实例的真实标签之间的语义相似性。 结果表明,与标准模型和对抗训练的模型相比,我们的方法在错误严重性方面表现更好。 我们还发现非稳健特征在语义相似性方面发挥的有趣作用。
1. 简介
传统上,机器学习系统的成功是使用简单的指标来衡量的,这些指标平等地对待类别级别的所有错误。 然而,这个局限性的定义与某些错误比其他错误严重得多的自然直觉相矛盾。 随着机器学习在实体代理中的激增,分布变化、异常和独特情况将使得保证所有代理都能在不犯错误的情况下运行变得极其困难。 同样,当前的稳健性定义衡量机器学习系统在不断变化或退化的环境中保持分类准确性的能力。 我们从不同的角度考虑稳健性:评估模型不仅要看它们的准确性,还要看它们所犯错误的严重程度。 将这些指标用作附加目标可以促进优先考虑较低误差幅度的训练技术的发展。
考虑一个基于计算机视觉系统进行对象检测的自主家庭护理机器人。 随着机器人单元的大规模部署和部署时间的增加,目标检测系统将受到环境和时间分布变化的挑战,从而导致检测精度下降。 此外,在这些环境中的机器人最终可能会犯下代价高昂的错误; 例如,它可能会将手机误认为盘子,导致手机在洗碗机中损坏,或者在晚餐时提供室内植物而不是沙拉。 可以假设,犯了如此严重错误的机器人产品不会赢得用户的信任,也可能不会被保留。 但是,如果机器人犯的错误很小,它们可能会被忽略; 用户更有可能原谅机器人将餐垫而不是手机放入洗碗机。
在衡量错误严重性时,可以手动为某些错误分配更高的惩罚。 然而,这种方法需要直接的人工输入,并且随着可能出错的空间的增加而变得笨拙。 作为人类分配惩罚的替代品,我们根据真实类和预测类之间的语义相似性来衡量错误严重性。 该措施的动机很直观; 例如,考虑一辆自动驾驶汽车将行人错误识别为倒下的树枝 v.s. 将人错误识别为骑自行车的人。 骑自行车的人在语义上比行人更接近行人,因此汽车相应地更有可能采取适当的行动。 该指标也可以被视为“语义鲁棒性”指标; 在扰动下犯语义对齐错误(行人 → 骑自行车的人)的模型比犯随机错误(行人 → 树枝)的模型在语义上更稳健。
我们提出了一种使用对抗性训练将语义知识纳入训练过程的方法,目的是提升错误与各自真实标签之间的语义对齐。 虽然存在其他在神经网络中嵌入类别层次信息的方法,但我们的方法还有一个额外的好处,即提供对稳健和非稳健特征与语义对齐之间关系的视角。
我们还评估了我们的方法在对抗性和自然损坏的条件下的错误严重性——例如,亮度和饱和度的模糊或变化。 这些类型的退化会降低模型的辨别能力并导致它犯更多错误。 在我们的研究中,我们使用这些条件作为分布偏移和其他错误来源的代替,并旨在降低这些条件下的错误严重性。
这项工作的贡献如下:
- 我们提出了一种基于有目标性的对抗训练来增加语义相似类别对齐的方法。
- 我们表明,我们的方法产生的模型在错误严重性方面比在多种退化条件下使用标准模型和常见对抗训练的模型表现更好。
- 我们讨论了非稳健特征在支持语义对齐方面的惊人作用。
2. 相关工作
自从引入对抗性示例的概念以来,已经有许多作品试图理解对抗性攻击。Ilyas (2019) 等人将对抗性示例的存在归因于数据集中的“非稳健”特征,这些特征为模型提供了有用的分类信号,但对人类没有意义(并且通常难以察觉)。 对抗性强大的网络仅限于使用“强大”的特征——即使在应用对抗性扰动时仍然对分类有用的特征。 换句话说,Ilyas 等人假设数据集中可能存在对标准分类任务有用的信号,但可以在对抗性环境中轻松利用。
当前的对抗训练技术高度关注像素级扰动,与 Madry (2018) 等人介绍的“黄金标准”鲁棒优化技术相似。已经有一些工作将其扩展到噪声、光照或其他偏差的变化。 也就是说,文献中也有一些关于生成语义对抗性样本的示例,这些示例与经典的不可察觉的像素扰动不同,它们专注于创建修改语义上有意义的属性的输入,从而在语义意义上产生在视觉上仍然忠于真实标签的图像(轮船 vs 加了轮子的轮船)。
虽然也存在解决神经网络错误严重性问题的先前工作,但 Bertinetto (2020) 等人指出,尽管最先进的分类器的最高准确度在过去五年中显示出性能稳步提高,但错误严重性一直停滞不前。 他们还提供了一项关于 “犯更好的错误” 的工作调查,确定了三种主要方法。
- 第一种方法是在标签中嵌入语义知识,它试图将类别表示(representations)修改为语义更对齐的嵌入(embedding),例如,通过从维基百科等文本源中提取。
- 第二种方法是使用分层损失,即改变损失函数以惩罚远离分类树上真实标签的预测。
- 最后讨论的方法是使用层次结构,将语义类别层次结构合并到分类器中而不修改损失函数。 它们包括两个标准交叉熵损失变体,以将先验知识整合到模型中。
在对抗训练的背景下,Ma (2021) 等人引入了分层对抗鲁棒性的概念来解决错误的严重性。 分层对抗性鲁棒性依赖于分层对抗性示例的概念——在“粗略”级别导致错误分类的对抗性示例(即在真实标签超类之外的错误分类)。他们创建了由一个网络组成的分层网络来识别图像的粗类,然后使用特定于粗类的网络来识别图像的“精细”类。 然而,他们致力于防范对抗性示例,而我们的目标是增加模型预测的语义对齐,以减少对抗性和自然条件下的错误严重性。
3. 方法
我们首先定义标准分类任务如下:令 D 为数据的分布,从中我们有输入对 (x,y),其中 x 是真实标签为 y 的样本点。 给定一个由 θ 参数化的机器学习模型 f_θ ,损失函数可以写为 L(f_θ (x) , y)。 然后标准训练过程的目标是:
![]()
此外,我们将对抗性稳健模型称为使用非目标性对抗性训练训练的模型(即,找到会导致任何错误分类的扰动,而不考虑错误标签是什么),对抗性扰动指定为 δ 并受 ε 约束。 对抗训练目标定义为:
![]()
通过使用语义目标性对抗性攻击将语义知识嵌入到训练过程中。 与非目标性方法不同,这种方法会产生扰动,骗模型预测指定的(目标)类别。 我们最终使用分阶段训练(staged training,ST)方法,第一阶段应用语义目标性的对抗训练,第二阶段应用标准训练。 我们的语义目标性训练方法改编自对抗训练目标的目标性版本(因此将问题的表述从 min-max 方法转换为双层优化方法),目标 t 是从一组与原始标签 y 语义相似的类 C(y) 中选择的。 具体来说,我们的目标函数是:
![]()
其中 δ* 是导致错误分类到目标标签 t 的扰动所需的值:t ∈ C(y)
4. 实验
我们使用语义相似性的两个概念评估了我们的方法:根据 WordNet 的路径相似性(即 WordNet 结构中两个词之间的最短路径长度的倒数),以及基于 CIFAR100 的标签粗(超)类分组 。CIFAR100 提供了 100 个细类,这些细类被分为 20 个粗类。
我们让 C(y) 是与 y 的路径相似度最高的五个标签的集合。 每个对抗性攻击的目标标签都是从 C(y) 中随机均匀采样的。 所有模型都使用 ResNet50 架构,并使用 CIFAR100 训练。 我们使用 0.1 的学习率和 100 的批量大小,剩余训练参数使用标准值。 此外,数据增强以随机裁剪和随机水平翻转的形式应用。
为了生成目标扰动,我们使用了 Soklaski (2022) 等人开发的 rAI-toolbox 和一个被限制在 L2 空间中大小为 ε 的球内的 10 步投影梯度下降 (PGD) 对抗。PGD 求解器的学习率为 2.5*ε/10。 我们在不同模型中试验了 epsilon 的值。 此外,我们还尝试了标签修改,将扰动图像的标签拆分为原始类别和目标类别,以解决较大的扰动。
我们将错误严重性衡量为模型的错误预测与相应真实标签之间的平均路径相似度。 此外,我们还测量了模型错误的粗分类精度(即模型错误分类在正确粗分类中的比例)。 我们发现这两个指标高度一致,并且这两个指标的数据趋势几乎相同。
我们比较的模型如下:
- 标准模型:经过 200 个 epoch 标准训练的模型。
- 对抗稳健模型:模型经过 200 轮无目标性的对抗性训练,使用 ε = 1 的扰动。
- 低 Epsilon 语义目标性模型 (LE-SmT):使用 ε = 1 作为 L2 扰动约束进行语义目标性对抗训练的模型; 训练了 200 个 epoch。 在这个初始模型中使用小 epsilon 是基于标准的对抗框架,在该框架中人眼无法察觉扰动。
- 高 Epsilon 语义目标性模型 (HE-SmT):使用 ε = 2.5 的 L2 扰动约束进行语义目标性对抗训练的模型; 训练了 200 个 epoch。 我们在该模型中尝试了更高的 epsilon,以解决以下事实:目标类可能不靠近嵌入空间中的原始类,因此针对低 epsilon 值的目标对抗攻击可能会失败。
- 修改标签的 HE-SmT (HE-SmT-LM):使用 ε = 2.5 的 L2 扰动约束进行语义目标性对抗训练的模型; 训练了 300 个 epoch。 为了更好地解释大的扰动,我们将扰动实例的标签设置为目标图像和原始图像的混合体。 我们修改了 one-hot 编码标签,使真实类的索引和目标类的索引都设置为 0.5。
- 阶段训练模型 (ST):使用阶段训练方法训练的模型,将我们的语义目标性方法与标准训练相结合。 这种方法背后的动机是应用我们的语义目标性方法来增加相似类之间的对齐,同时还利用似乎有助于基线标准模型性能的非稳健信号。 该模型经过 200 轮语义训练(按照 HE-SmT-LM 的规定设置训练),然后再进行 100 轮标准训练。
我们在使用 NVIDIA Tesla V100 GPU 的集群上进行了所有实验。 一轮标准训练大约需要 1 分钟,一轮语义目标性训练和非目标性对抗训练大约需要 10 分钟。
5. 结果
在本节中,我们将展示针对对抗性扰动和自然损坏的错误严重性结果。 我们提供证据表明 ST 模型在这个指标上优于其他模型。
5.1 对抗扰动
我们使用非目标性扰动测量了越来越多的扰动数据的错误严重性,并特别考虑了 ε = 1.5 到 ε = 2.0 的范围作为不完美条件下数据的代理,正如我们最初的目标是在具有挑战性的条件下保持稳健性。 图 1 显示了此范围内的扰动示例。 我们的基线模型是标准的和对抗性强的模型。 标准模型在对比的模型中实现了干净数据(0 扰动)错误的最佳语义对齐(错误最少)。 对抗性鲁棒模型的错误严重性比标准模型差得多,即使是在具有高度扰动的数据上也是如此(因为稳健,所以扰动对其影响不大)。
LE-SmT 和 HE-SmT 模型都未能改善错误严重性。 我们发现,与非目标攻击相比,低 epsilon 语义目标攻击在训练早期的成功率较低; 因此,我们的其他模型(HE-SmT-LM 和 ST)专注于更高的 epsilon 值,以确保对最初未对齐的类进行更高的攻击成功率。 HE-SmT-LM 产生了略微改善的结果,但仍无法与标准模型竞争。 ST 模型在干净的数据上恢复了一些语义对齐,并且在高度扰动的数据上也比所有其他模型表现得更好。 所有模型的结果如图 2 所示。
5.2 自然损坏(Natural Corruptions)
此外,我们在 CIFAR-100-C 数据集上比较了标准模型、对抗鲁棒模型和 ST 模型的错误严重性。 CIFAR-100-C 数据集对来自 CIFAR-100 的图像应用了常见的损坏,例如对比度变化或模糊。 该数据集允许我们在自然损坏条件下测试模型性能,因为它提供了不同严重程度的自然损坏。损坏以 1-5 的等级衡量,1 表示最不严重,5 表示最严重; 我们将严重性 1 称为低严重性,将严重性 5 称为高严重性。 我们针对 19 个损坏来源的测试数据评估了模型性能。

标准模型在低严重性损坏方面优于对抗性鲁棒模型和 ST 模型,在 11/19 损坏类型上实现了错误的最高语义对齐。对于低严重性损坏,ST 表现最佳是 8 种类型。 然而,对于高严重性的损坏,ST 在 9/19 损坏类型上具有最高的错误语义对齐。标准模型仅在 4/19 上表现最佳,而对抗性鲁棒模型在 6/19 上表现最佳。 在高严重性损坏下,ST 在 9/19 损坏类型的错误严重性方面优于标准模型。 具体损坏的示例如图 3 所示。所有严重程度的结果如图 4 所示。
这些结果提供了进一步的证据,表明相对于标准和对抗训练的模型,ST 保留了高度退化条件下错误的语义对齐。
6. 讨论与结论
首先,我们注意到许多稳健性的定义使用针对特定类型损坏的准确性作为成功指标; 这些定义未能说明模型错误的严重性。 我们的实验表明,当前流行的鲁棒性技术与其衡量错误严重性时的有效性存在差距。 我们展示了一种在对抗性和自然退化条件下降低错误严重性的方法,表明通过将此目标纳入模型训练过程可以提高错误的语义一致性。 我们希望这些结果将推动进一步改进训练过程,以减少错误的严重程度。
其次,我们观察了非稳健信号在类别语义对齐中的作用。 由于非鲁棒信号在视觉上难以察觉并且不会影响人类对图像语义的感知,因此可以直观地假设非鲁棒信号比鲁棒信号更少的对齐语义,因此鲁棒模型应该在语义上更对齐。然而,我们在实验中发现了相反的情况。 与未经对抗训练的模型相比,经过训练以利用稳健信号的模型在错误的语义对齐方面表现更差。 即使是针对语义的对抗训练也是如此。 我们的语义训练方法,仅在允许模型通过分阶段训练利用一定数量的非稳健信号时,在我们的实验中才有效。 我们假设我们的两步训练方法在非稳健特征之间创建了语义对齐; 当稳健特征退化时使用非稳健特征的能力将有助于增加错误的语义对齐。 或者,非稳健特征可能比最初预期的与语义对齐更密切相关。
最后,我们强调语义对齐并不总是与视觉对齐一致。 由于神经网络依赖于数据的视觉特征,因此考虑外部语义知识来源可以在多大程度上补偿类别中的视觉差异是很有趣的。Bertinetto (2020) 等人讨论了一个类似的问题,即语义知识在多大程度上可以是任意的(从而打破了语义和视觉相似性之间的任何相关性)。 Bertinetto (2020) 等人发现在他们的方法中使用任意语义层次结构导致错误严重性方面的性能大幅下降。 探索这些结果是否适用于我们的方法,以及所使用的扰动类型是否对结果有影响,将会很有趣。
7. 未来工作
分阶段训练方法的结果表明,我们的语义定位方法有助于类的某些对齐,但非稳健信号的限制使用阻碍了我们方法的成功。 这为探索非稳健特征对相似类对齐的贡献开辟了一条有趣的途径,特别是考虑到非稳健信号通常指的是根据人类感知无意义的数据。
未来的工作可以将我们的方法与嵌入语义知识的替代方法进行比较,例如修改损失函数以惩罚更严重的错误。 另一个方向可以是探索应用更具语义意义的扰动的替代扰动方法,例如属性引导的扰动或基于空间变换的扰动。
我们还注意到,在这项工作中,我们通过测量类别的语义对齐而不是视觉对齐来量化错误严重性; 然而,在某些情况下,我们可能更愿意将一个类别与视觉上相似的类而不是语义上相似的类对齐。 例如,如果错误地取回了处方药而不是一瓶苹果汁,一个被派去取止咳糖浆的自主家庭帮手机器人可能会不太可信,即使处方药在语义上更类似于真实目标。 因此,未来的工作可以考虑平衡语义相似性和视觉相似性的重要性的问题。 特别是,探索使用非稳健特征来添加与类的视觉相似性不一致的语义信息的潜在用途也很有用。
8. 更广泛的影响
我们相信,这项工作有望进一步推进稳健的机器学习工作,并与任何使用这些算法的具体系统建立信任。 此外,它鼓励对鲁棒性的通常定义采取不同的观点,并探索在过去几年的进步中一直停滞不前的指标。 更重要的是,我们预计,随着人们寻求从狭义 AI 向前发展,寻找新方法来利用人类知识并提供具有更多语义一致性的模型将非常重要。 语义不仅可以为模型提供更好地理解环境的能力,而且它们还可以成为减轻数据中已知偏差的一种方式——例如,我们能否编码更符合当今社会期望的更“公平”的关联? 然而,与该领域的几乎所有研究一样,从业者需要谨慎行事,尤其是要避免在模型中嵌入有偏见的语义关系。 幸运的是,机器学习科学家和工程师越来越意识到这些问题,我们相信,有助于建立更符合人类的、值得信赖的、稳健的模型的贡献工作将导致总体上更安全的操作。
参考
Abreu N, Vaska N, Helus V. Addressing Mistake Severity in Neural Networks with Semantic Knowledge[J]. arXiv preprint arXiv:2211.11880, 2022.
S. 总结
S.1 主要思想
(分类)模型的不同错误的严重性是不同的。作者利用模型预测和真实标签之间的语义差异来量化错误的严重程度,用于生成有目标性的对抗性攻击,以提高模型的稳健性。
S.2 名词解释
错误严重性:对于自动驾驶系统,把行人误判为树枝 vs 把行人误判为骑自行车的人,明显前者有更低的语义相似性,同时也表示更高的错误严重性。
错误的语义对齐:如上所述,即使模型预测出错,也应该尽量使预测的错误标签与真实标签有更接近的语义相似性(做法就是语义对齐),从而降低错误严重性。
模型稳健性:在有扰动的条件下,模型的预测精度不变或是仅有略微的降低。此外,即使出错,也应该有较低的错误严重性。
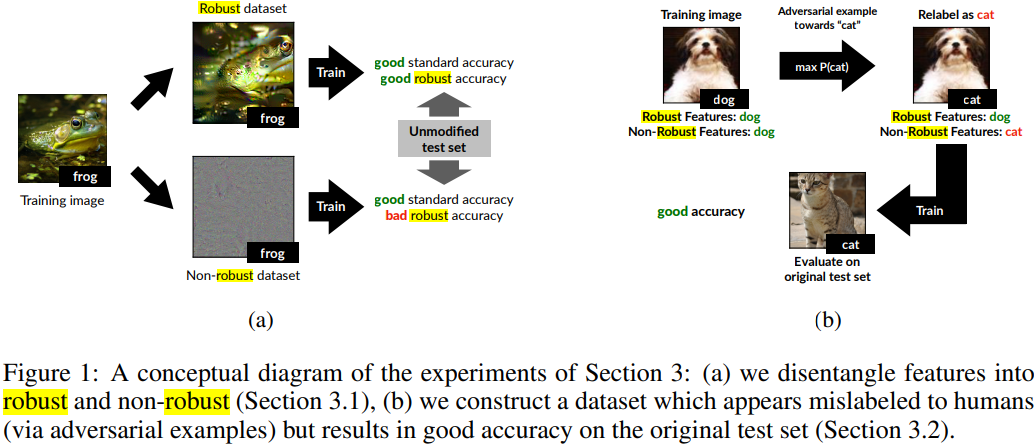
稳健特征与非稳健特征:图像的特征可以分为稳健特征和非稳健特征。如下图所示,图像来源于Ilyas (2019) 等人的论文 “Adversarial Examples Are Not Bugs, They Are Features”。
- 非稳健特征可以为分类模型预测提供信息,但人类难以察觉。例如在对抗防御中,为图像添加微小的扰动,在人类看来,图像并未发生变化,但是模型缺可能把该图像误判为其他类别。
- 而稳健特征不受扰动的影响。
S.3 方法
使用分阶段训练:
第一阶段使用语义目标性对抗训练,把语义知识嵌入到训练过程中。与非目标性方法(找到会导致任何错误分类的扰动,而不考虑错误标签是什么)不同,这种方法会产生扰动,骗模型预测指定的(目标)类别。
目标 t 是从一组与图像 x 的原始标签 y 语义相似的类 C(y) 中选择的。C(y) 是与 y 的语义相似度最高的五个标签的集合。该式促使找到范围 ε 内使模型误判为 t 的扰动 δ* 。
第二阶段进行标准训练。如下式所示。即使出现可能使模型发生误判的扰动,模型依然能够进行正确判断。即,通过训练提升了模型的稳健性。
![]()
S.4 分析
经过分阶段训练后,模型的稳健性提升,不容易因为扰动而发生误判。而且即使误判,也会预测与真实标签语义接近的标签,降低了错误严重性。
![[NIPS 1989] Optimal brain damage (OBD)](https://img-blog.csdnimg.cn/a3b69cd4a19f4e58a6ba12dc674c0ae5.png#pic_center)











![[Diffusion] Speed is all your need](https://img-blog.csdnimg.cn/c6dba39d973641f38bb3a8df56df4d92.png)
