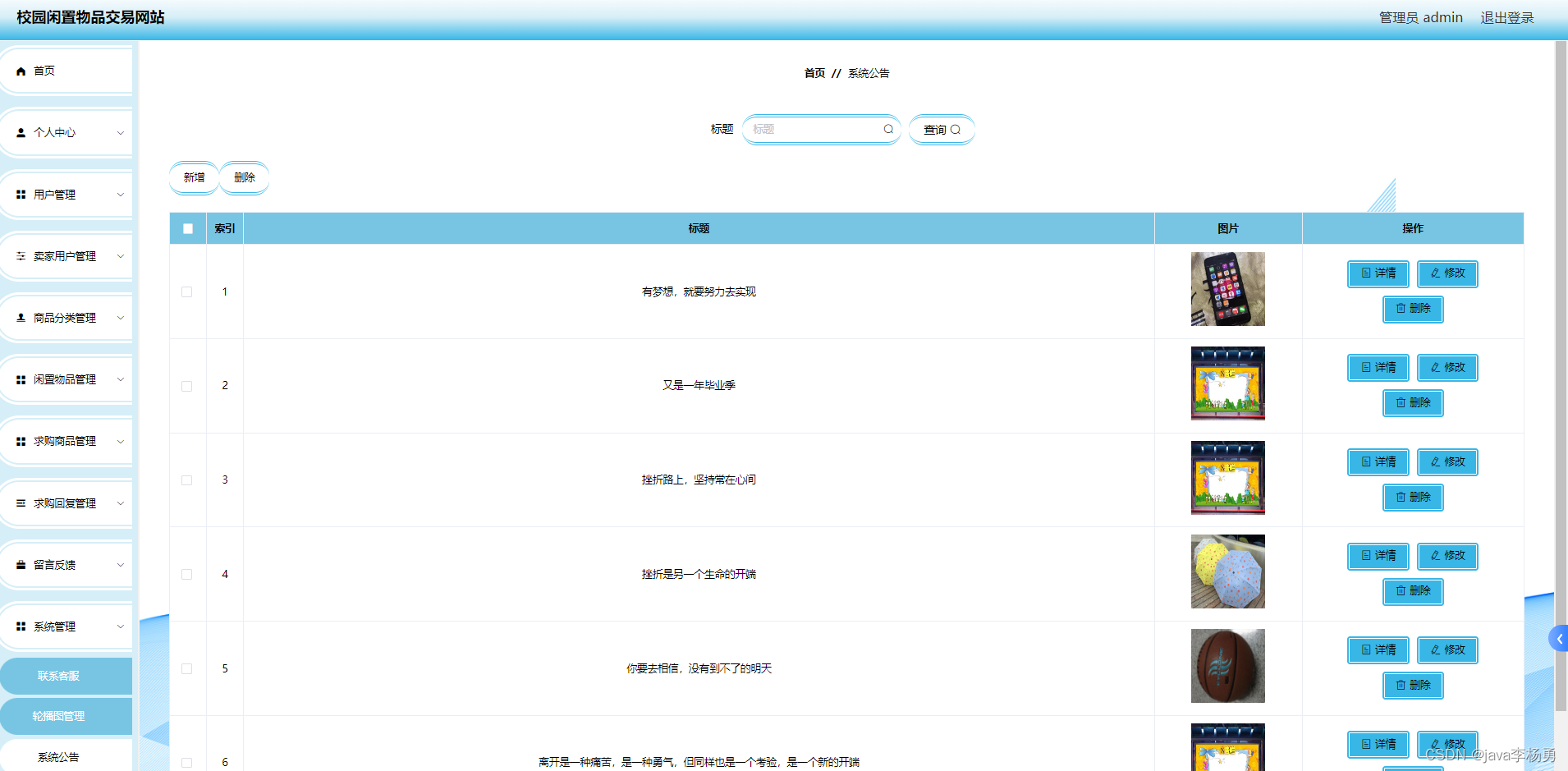
**需求是使用阿里云oss存储,实现一个文件管理功能,支持新建文件夹、文件的上传、下载、批量下载、删除、批量删除、预览、移动、名称搜索、文件路径搜索等。**本人也参考了网上的一些项目,这里记录一下后端的Java代码实现:
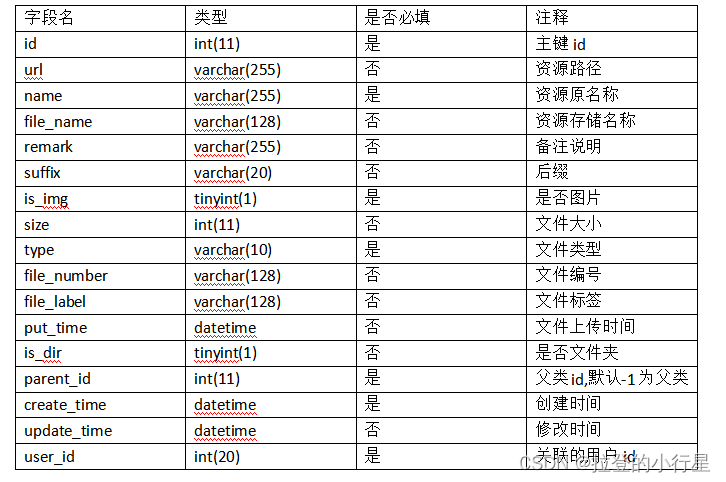
首先是表设计的实现,
文件和文件夹,很明显是父子关系,文件夹下存在多个文件夹或者文件,文件和文件夹的区别只是是否存在url下载地址,基本一张表就能实现,表结构设计如下:其中file_name 就是存储在oss中的名称
接下来就是功能分解:
首先是文件夹的增删改,这里没啥好说的,service层基本代码如下:
//新增
@Override
public boolean addFolder(FilePojo pojo) {
String dirId = pojo.getDirIds().substring(pojo.getDirIds().lastIndexOf("/") + 1);
if ("/".equals(dirId) || StringUtils.isEmpty(dirId)) {
pojo.setParentId(-1);
} else {
FilePojo p = baseMapper.selectById(Long.parseLong(dirId));
pojo.setParentId(p.getId());
}
pojo.setType("dir");
pojo.setIsDir(Boolean.TRUE);
pojo.setIsImg(Boolean.FALSE);
pojo.setCreateTime(new DateTime());
User tokenUser = userService.getById(tokenUtil.getId());
pojo.setUserId(tokenUser.getUserId());
//判断文件夹名称在当前目录中是否存在
Integer count = baseMapper.selectCount(
new LambdaQueryWrapper<FilePojo>()
.eq(FilePojo::getName, pojo.getName())
.eq(FilePojo::getIsDir, Boolean.TRUE)
.eq(FilePojo::getParentId, pojo.getParentId())
);
if (count > 0) {
throw new RuntimeException("当前目录名称已存在,请修改后重试!");
}
return baseMapper.insert(pojo)>0;
}
//修改文件名称
@Override
public boolean updateByName(FilePojo pojo) {
FilePojo p = baseMapper.selectById(pojo.getId());
Integer count = baseMapper.selectCount(
new LambdaQueryWrapper<FilePojo>()
.eq(FilePojo::getName, pojo.getName())
.eq(FilePojo::getIsDir, p.getIsDir())
.eq(FilePojo::getParentId, p.getParentId())
.ne(FilePojo::getId, p.getId())
);
if (count > 0) {
throw new RuntimeException("当前目录已存在该名称,请修改后重试!");
}
FilePojo updPojo = new FilePojo();
updPojo.setId(pojo.getId());
updPojo.setName(pojo.getName());
updPojo.setUpdateTime(new DateTime());
return baseMapper.updateById(updPojo) > 0;
}
//删除
@Transactional(rollbackFor = Exception.class)
@Override
public boolean deleteByIds(String ids) {
String[] idArray = ids.split(",");
List<String> idsList=Arrays.asList(idArray);
//idlist 区分文件还是文件夹
QueryWrapper<FilePojo> wrapper = new QueryWrapper<>();
wrapper.in("id", idsList);
List<FilePojo> filesAll = baseMapper.selectList(wrapper);
List<FilePojo> folder=new ArrayList<>();
List<FilePojo> files=new ArrayList<>();
filesAll.forEach(filePojo -> {
if(filePojo.getIsDir()){
folder.add(filePojo);
}else{
files.add(filePojo);
}
});
//查询所有文件夹下的子文件信息(oss服务器删除)
List<FilePojo> childFiles=new ArrayList<>();
folder.forEach(fo->{
listChildFiles(fo.getId(), childFiles);
});
//需要删除的文件信息
files.addAll(childFiles);
//删除阿里云服务器文件信息
for (FilePojo child : files) {
ossClientUtil.delete(child.getFileName());
}
//文件夹下的文件夹信息
List<FilePojo> fchids = new ArrayList<>();
filesAll.forEach(all->{
delChildFiles(all.getId(), fchids);
});
filesAll.addAll(fchids);
//删除表记录
List<Integer> deleteIds = new ArrayList<>();
filesAll.forEach(del->{
deleteIds.add(del.getId());
});
return baseMapper.deleteBatchIds(deleteIds)>0;
}
这里重点说一下删除方法,我这里将删除文件夹和文件方法合并了,当id为文件时,我会递归查询文件夹下的所有文件,先删除阿里云中文件信息,再删除表里的记录信息。递归查询方法如下:
//递归查询子节点所有信息(不区分文件还是文件夹)
public void delChildFiles(Integer id, List<FilePojo> childFiles) {
QueryWrapper<FilePojo> wrapper = new QueryWrapper<>();
wrapper.eq("parent_id", id);
List<FilePojo> files = baseMapper.selectList(wrapper);
for (FilePojo file : files) {
childFiles.add(file);
delChildFiles(file.getId(), childFiles);
}
}
//递归查询文件子节点信息(下载时使用,判断url是否为空)
public void listChildFiles(Integer id, List<FilePojo> childFiles) {
QueryWrapper<FilePojo> wrapper = new QueryWrapper<>();
wrapper.eq("parent_id", id);
List<FilePojo> files = baseMapper.selectList(wrapper);
for (FilePojo file : files) {
//如果url不为空
if(!file.getIsDir() && StringUtils.isNotBlank(file.getUrl())){
childFiles.add(file);
}
listChildFiles(file.getId(), childFiles);
}
}
**接下来就是文件上传功能:这里将用到阿里云oss的sdk
oss存储配置可以参考如下链接:**https://blog.csdn.net/m0_75063085/article/details/127787899。
代码如下:
@Override
public Result upload(MultipartFile[] files, String dirIds,String fileNumber,String fileLabel) {
if (files == null || files.length == 0) {
throw new RuntimeException("文件不能为空");
}
for (MultipartFile file : files) {
FilePojo filePojo =null;
try {
filePojo = ossClientUtil.upload(file);
} catch (Exception e) {
e.printStackTrace();
return Result.error("文件:" + file.getOriginalFilename() + "上传失败");
}
String dirId = dirIds.substring(dirIds.lastIndexOf("/") + 1);
if ("/".equals(dirId) || StringUtils.isEmpty(dirId)) {
filePojo.setParentId(-1);
} else {
FilePojo p = baseMapper.selectById(Long.parseLong(dirId));
filePojo.setParentId(p.getId());
}
int flag = 0;
//名称重复时重命名
filePojo.setName(recursionFindName(filePojo.getName(), filePojo.getName(), filePojo.getParentId(), flag));
filePojo.setFileNumber(fileNumber);
filePojo.setFileLabel(fileLabel);
User tokenUser = userService.getById(tokenUtil.getId());
filePojo.setUserId(tokenUser.getUserId());
filePojo.setCreateTime(new DateTime());
filePojo.setPutTime(new DateTime());
if (baseMapper.insert(filePojo) <= 0) {
return Result.error("文件:" + file.getOriginalFilename() + "上传失败");
}
}
return Result.OK("上传成功");
}
/**
* 递归查询查询name是否存在,如果存在,则给name+(flag)
*
* @param sname 原name
* @param rname 修改后name
* @param flag 标记值
* @return
*/
private String recursionFindName(String sname, String rname, Integer parentId, int flag) {
boolean exists = true;
while (exists) {
Integer count = baseMapper.selectCount(new LambdaQueryWrapper<FilePojo>()
.eq(FilePojo::getName, rname)
.eq(FilePojo::getIsDir, Boolean.FALSE)
.eq(FilePojo::getParentId, parentId));
if (count > 0) {
flag++;
rname = sname + "(" + flag + ")";
} else {
exists = false;
}
}
return flag > 0 ? sname + "(" + flag + ")" : sname;
}
这里简单说明一下传的三个参数String dirIds,String fileNumber,String fileLabel。 后面两个就是存入数据库中的参数,为文件编号和文件标签,因个人需求而定。重点说一下dirIds这个参数表示文件所在的目录层级,用‘/’分隔,另外还有一个将文件重命名的步骤,当文件上传时,同一个文件夹内的文件不能重复,如果重名自动修改。
接下来就是下载功能:单文件下载很简单,调用阿里云api 传入key就可以,这里的key就是存储的文件名,service代码如下:
@Override
public void download(Integer id, HttpServletResponse response) {
FilePojo filePojo= baseMapper.selectById(id);
ossClientUtil.download(filePojo, response);
}
最为关键的就是文件的批量下载,这里会涉及到递归查询,如果你选择的有文件夹,则要先查出其中的子文件,然后将所有文件打包成一个zip下载,这里要注意下,首先要把文件下载到本地的临时目录下,然后再进行打包,另外在下载到本地时,需要给文件加个时间戳,防止名称重复,否则打包会出现异常,代码如下:
@SneakyThrows
@Override
public ResponseEntity<ByteArrayResource> batchDownload(String ids) {
String[] idstring = ids.split(",");
List<String> idlist= Arrays.asList(idstring);
//idlist 区分文件还是文件夹
QueryWrapper<FilePojo> wrapper = new QueryWrapper<>();
wrapper.in("id", idlist);
List<FilePojo> filesAll = baseMapper.selectList(wrapper);
List<FilePojo> folder=new ArrayList<>();
List<FilePojo> files=new ArrayList<>();
filesAll.forEach(filePojo -> {
if(filePojo.getIsDir()){
folder.add(filePojo);
}else{
files.add(filePojo);
}
});
//查询所有文件夹下的子文件信息
List<FilePojo> childFiles=new ArrayList<>();
folder.forEach(fo->{
listChildFiles(fo.getId(), childFiles);
});
//需要下载的所有文件 files + childFiles
files.addAll(childFiles);
return batchDownload(files);
}
//递归查询文件子节点信息(下载时使用,判断url是否为空)
public void listChildFiles(Integer id, List<FilePojo> childFiles) {
QueryWrapper<FilePojo> wrapper = new QueryWrapper<>();
wrapper.eq("parent_id", id);
List<FilePojo> files = baseMapper.selectList(wrapper);
for (FilePojo file : files) {
//如果url不为空
if(!file.getIsDir() && StringUtils.isNotBlank(file.getUrl())){
childFiles.add(file);
}
listChildFiles(file.getId(), childFiles);
}
}
public ResponseEntity<ByteArrayResource> batchDownload(List<FilePojo> files) throws IOException {
// 创建一个临时目录,用于保存下载的文件
File tempDir = Files.createTempDir();
List<File> downloadedFiles = new ArrayList<>();
// 将文件下载到临时目录中
for (FilePojo fileItem : files) {
//加时间戳防止名称重复
String name = fileItem.getName()+"_"+System.currentTimeMillis()+"."+fileItem.getSuffix();
//fileName 是oss的存储名称
String fileName = fileItem.getFileName();
File tempFile = new File(tempDir, name);
ossClientUtil.downFileAll(fileName,tempFile);
downloadedFiles.add(tempFile);
}
// 创建一个 ZIP 文件,将下载的文件保存到其中
File zipFile = new File(tempDir, "downloads.zip");
ZipOutputStream zipOutputStream = new ZipOutputStream(new FileOutputStream(zipFile));
for (File downloadedFile : downloadedFiles) {
ZipEntry zipEntry = new ZipEntry(downloadedFile.getName());
zipOutputStream.putNextEntry(zipEntry);
FileInputStream fileInputStream = new FileInputStream(downloadedFile);
IOUtils.copy(fileInputStream, zipOutputStream);
fileInputStream.close();
zipOutputStream.closeEntry();
}
zipOutputStream.close();
// 将 ZIP 文件作为 ResponseEntity 返回给前端
ByteArrayResource resource = new ByteArrayResource(Files.toByteArray(zipFile));
HttpHeaders headers = new HttpHeaders();
headers.add(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=\"downloads.zip\"");
headers.add(HttpHeaders.CONTENT_TYPE, "application/zip");
return ResponseEntity.ok()
.headers(headers)
.contentLength(zipFile.length())
.body(resource);
}
然后的文件的移动,
这里很简单,只要修改关联文件的parent_id就行,但是在移动时你同时需要先查询出当前所有的文件夹列表,以供移动时选择:代码如下,
//移动
@Override
public boolean move(String ids, Integer parentId) {
if (StringUtils.isEmpty(ids)) {
throw new RuntimeException("请选择要移动的文件或目录");
}
String[] idsArry = ids.split(",");
return baseMapper.moves(parentId,idsArry)>0;
}
//文件夹目录树形列表
@Override
public List<DtreeVo> getTreeList(String name) {
User tokenUser = userService.getById(tokenUtil.getId());
List<FilePojo> fileList = baseMapper.selectFileListByName(name,tokenUser.getUserId());
if (fileList == null || fileList.isEmpty()) {
return Collections.emptyList();
}
Map<Integer, DtreeVo> map = new HashMap<>(); // 用于存储所有文件节点的映射
for (FilePojo file : fileList) {
DtreeVo node = new DtreeVo();
BeanUtils.copyProperties(file, node);
map.put(file.getId(), node);
}
List<DtreeVo> result = new ArrayList<>(); // 用于存储所有根节点
for (DtreeVo node : map.values()) {
if (node.getParentId() == null || !map.containsKey(node.getParentId())) { // 找到根节点
buildFileTree(map, node);
result.add(node);
}
}
return result;
}
private void buildFileTree(Map<Integer, DtreeVo> map, DtreeVo node) {
List<DtreeVo> children = new ArrayList<>(); // 用于存储当前节点的子节点
for (DtreeVo child : map.values()) { // 遍历所有节点,找到当前节点的子节点
if (node.getId().equals(child.getParentId())) {
buildFileTree(map, child);
children.add(child);
}
}
node.setChildren(children);
}
其中baseMapper.selectFileListByName是 mapper方法,对应xml如下:
<select id="selectFileListByName" resultType="com.jsbd.entity.FilePojo">
SELECT * FROM file_info WHERE
id IN (
SELECT DISTINCT a.id
FROM file_info a, file_info b
WHERE a.parent_id = b.id
UNION ALL
SELECT id FROM file_info
)
and is_dir=1
and user_id =#{userId}
<if test="name !=null and name!=''">
and name = #{name}
</if>
ORDER BY url ASC
</select>
最后是文件名称查询和路径查询,重点是路径查询,还是相当麻烦的,需要一层一层查,另外名称查询时也需要传入dirIds 层级,默认是’/’ 第一层:
//名称查询
@Override
public Page<FilePojo> getList(Page page, FilePojo pojo) {
LambdaQueryWrapper<FilePojo> wrapper = new LambdaQueryWrapper<>();
String dirIds = pojo.getDirIds();
if(StringUtils.isNotEmpty(dirIds)){
dirIds = dirIds.substring(dirIds.lastIndexOf("/") + 1);
}
wrapper.eq(FilePojo::getParentId, StringUtils.isEmpty(dirIds) ? -1L : Long.parseLong(dirIds));
if(StringUtils.isNotEmpty(pojo.getName())){
wrapper.eq(FilePojo::getName,pojo.getName());
}
User tokenUser = userService.getById(tokenUtil.getId());
wrapper.eq(FilePojo::getUserId,tokenUser.getUserId());
wrapper.orderByDesc(FilePojo::getIsDir, FilePojo::getPutTime);
return baseMapper.selectPage(page,wrapper);
}
//路径查询
@Override
public Page<FilePojo> listBySource(Page page,String path) {
User tokenUser = userService.getById(tokenUtil.getId());
// 将路径按照分隔符拆分成目录名称数组
String[] names = path.split("/");
// 从根节点开始逐级向下遍历
Page<FilePojo> result = new Page<>();
FilePojo node = baseMapper.selectOne(
new LambdaQueryWrapper<FilePojo>()
.eq(FilePojo::getParentId, -1)
.eq(FilePojo::getName, names[1])
.eq(FilePojo::getUserId, tokenUser.getUserId())
);
if (node != null) {
for (int i = 2; i < names.length; i++) {
List<FilePojo> children = baseMapper.selectList(
new LambdaQueryWrapper<FilePojo>()
.eq(FilePojo::getParentId, node.getId())
.eq(FilePojo::getName, names[i])
.eq(FilePojo::getUserId, tokenUser.getUserId())
);
if (children.size() > 0) {
node = children.get(0);
} else {
return result;
}
}
result = baseMapper.selectPage(page,
new LambdaQueryWrapper<FilePojo>()
.eq(FilePojo::getParentId, node.getId())
.eq(FilePojo::getUserId, tokenUser.getUserId())
);
}
return result;
}
oss工具类如下:
package com.jsbd.utils;
import com.aliyun.oss.ClientConfiguration;
import com.aliyun.oss.OSS;
import com.aliyun.oss.OSSClient;
import com.aliyun.oss.OSSClientBuilder;
import com.aliyun.oss.model.*;
import com.google.common.base.Strings;
import com.google.common.io.Files;
import com.jsbd.entity.FilePojo;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import org.springframework.web.multipart.MultipartFile;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.net.URLEncoder;
import java.util.UUID;
@Slf4j
@Component
public class OSSClientUtil {
@Value("${oss.file.bucketName}")
private String bucketName="";
@Value("${oss.file.endpoint}")
private String endPoint="";
@Value("${oss.file.accessKeyId}")
private String accessKeyId="";
@Value("${oss.file.accessKeySecret}")
private String secretAccessKey="";
private String path="https://"+bucketName+"."+endPoint;
private int retryLimit = 3;
private OSS ossClient;
/* 获取连接 */
private OSS getClient() {
// 创建OSSClient实例。
ossClient = new OSSClientBuilder().build(endPoint, accessKeyId, secretAccessKey);
return ossClient;
}
/* 重新获取连接 */
private OSS reGetClient() {
log.info("重构OSSClient");
this.ossClient.shutdown();
this.ossClient = null;
return this.getClient();
}
/* 文件上传 */
public FilePojo upload(MultipartFile file) throws Exception {
InputStream in= file.getInputStream();
if (in == null) return null;
int retryCount = 0;
OSS ossClient = this.getClient();
while (retryCount++ < retryLimit) {
try {
//随机生成新的文件名
FilePojo pojo = MyFileUtil.buildFilePojo(file);
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentType(MyFileUtil.getcontentType(pojo.getFileName().substring(pojo.getFileName().lastIndexOf("."))));
PutObjectRequest putObjectRequest = new PutObjectRequest(this.bucketName, pojo.getFileName(), file.getInputStream());
putObjectRequest.setMetadata(metadata);
log.debug("OSS上传开始 fileName={}", pojo.getFileName());
ossClient.putObject(putObjectRequest);
String url = this.path + "/" + pojo.getFileName();
pojo.setUrl(url);
log.debug("OSS上传结束 url={}", url);
return pojo;
} catch (Exception e) {
log.error("OSS上传异常 -> 尝试{}次", retryCount, e);
ossClient = this.reGetClient();// 重新构建连接
}finally {
ossClient.shutdown();
}
}
throw new RuntimeException("OSS上传异常");
}
/**
* 下载对象
*
* @param filePojo
* @param response
*/
@SneakyThrows
public void download(FilePojo filePojo, HttpServletResponse response) {
if(filePojo==null){
throw new RuntimeException("文件不存在!");
}
response.setHeader("Content-disposition", "attachment;filename=" + URLEncoder.encode(filePojo.getName()+"."+filePojo.getSuffix(), "UTF-8"));
OSS ossClient = this.getClient();
OSSObject ossObject = ossClient.getObject(this.bucketName, filePojo.getFileName());
BufferedInputStream in = new BufferedInputStream(ossObject.getObjectContent());
BufferedOutputStream out = new BufferedOutputStream(response.getOutputStream());
byte[] buffer = new byte[1024];
int lenght = 0;
while ((lenght = in.read(buffer)) != -1) {
out.write(buffer, 0, lenght);
}
if (out != null) {
out.flush();
out.close();
}
if (in != null) {
in.close();
}
ossClient.shutdown();
}
/* 文件删除 */
public void delete(String key) {
if (Strings.isNullOrEmpty(key)) return;
int retryCount = 0;
OSS ossClient = this.getClient();
while (retryCount++ < retryLimit) {
try {
log.info("OSS删除开始 file={}", key);
ossClient.deleteObject(this.bucketName, key);
log.info("OSS删除结束 file={}", key);
return;
} catch (Exception e) {
log.error("OSS删除异常 -> 尝试{}次", retryCount, e);
ossClient = this.reGetClient();// 重新构建连接
}
}
throw new RuntimeException("OSS删除异常");
}
/**
* 文件夹批量下载
* */
public void downFileAll(String fileName,File tempFile){
OSS ossClient = this.getClient();
ossClient.getObject(new GetObjectRequest(bucketName, fileName), tempFile);
ossClient.shutdown();
}
}
以上基本功能差不多实现,项目全部功能代码上传了资源,需要的可以自行下载:https://download.csdn.net/download/weixin_43832166/87880779