摘要
尽管mRNA疫苗已用于COVID-19的预防,但仍然面临不稳定和易降解的风险,这是mRNA疫苗存储、配送、效价等面临的重要障碍。先前的研究已表明,增加二级结构可延长mRNA的半衰期,再加上选择优化的密码子,可改善蛋白表达。因此,原则上mRNA的设计算法必须优化二级结构稳定性和密码子的使用。然而,由于同义密码子的存在,使得mRNA设计的工作量非常庞大,例如靶向SARS-CoV-2 Spike蛋白的mRNA就有~10^632种方案,这就带来了难以克服的计算挑战。利用计算语言中类似的概念,我们提供了一种简单且意想不到的解决办法:寻找最佳的mRNA序列类似于在发音相似的备选句子中识别最可能的句子。利用我们的算法(LinearDesign)设计Spike蛋白的mRNA仅需11分钟,并且同时优化稳定性和密码子的使用。在针对COVID-19 和 水痘带状疱疹病毒(varicella-zoster virus)mRNA疫苗,与密码子优化的基准算法相比,LinearDesign大幅度提高了mRNA的半衰期和蛋白的表达,显著增加了抗体的滴度(体内实验中增加了128倍)。该结果揭示了mRNA设计算法还有很大的改进空间,促进了对原本触不可及的高效且稳定的mRNA设计的探索。我们的工作为mRNA疫苗乃至mRNA药物(如单克隆抗体和抗癌药物)的研发带来了“及时雨”(timely tool)。
正文
mRNA疫苗因其可批量生产、安全性和有效性而被认为是预防包括COVID-19在内的可行方法。然而,mRNA分子在化学上不稳定且容易降解,导致蛋白质表达不足,进而降低免疫原性和成药性。这种不稳定性也成为疫苗储存和分发中的主要障碍,mRNA疫苗需要使用冷链,这也就限制了其在发展中国家的使用。因此,人们迫切希望获得一种具有增强稳定性的mRNA分子,可能会具有更高的效力和良好的临床疗效。
虽然化学稳定性很难建模,但之前的研究已经确定了它与次级结构的相关性,这通过热力学折叠稳定性进行量化;改善这种结构稳定性,结合最佳密码子使用,可以增加蛋白质表达。因此,一个合理的mRNA设计算法必须优化两个因素,即结构稳定性和密码子使用,以增强蛋白质表达。
然而,由于搜索空间(search space)呈指数级增长,mRNA(仅考虑编码区)设计问题非常具有挑战性。每个氨基酸由一个三联密码子编码,即三个相邻的核苷酸,但由于遗传密码的冗余性(20个氨基酸对应64个密码子),大多数氨基酸具有多个密码子。这种组合导致候选序列数量极大,难以处理。例如,SARS-CoV-2的刺突蛋白(Spike protein)由1,273个氨基酸组成,可以由约2.4×10^632个mRNA序列编码(图1a)。这带来了无法逾越的计算挑战,并排除了枚举的可能性,因为对于刺突蛋白来说,枚举需要花费10617亿年的时间(图1b)。另一方面,传统的mRNA设计方法,密码子优化(11, 12)仅优化密码子使用,但几乎不会改善稳定性,忽略了高稳定性mRNA存在的巨大空间。优化GC含量具有类似的效果,因为它与脊椎动物中的密码子使用相关(13)。因此,大多数高稳定性mRNA的设计仍然是未知的。
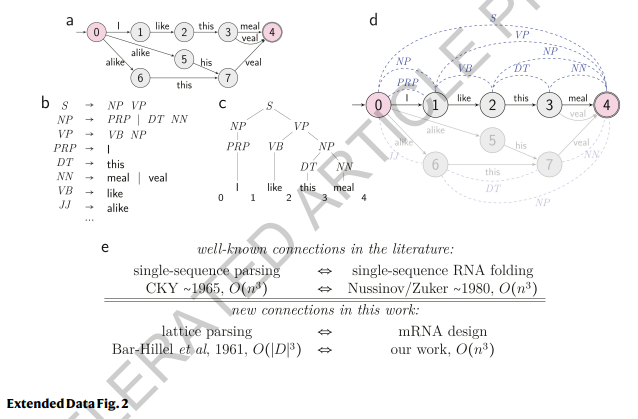
在这里,我们提供了一个简单的算法,LinearDesign,通过意外地将这个具有挑战性的问题归约为计算语言学中经典概念“格子解析”(6)(图1c)来解决。我们展示了在众多类似的备选方案中找到最佳mRNA类似于在众多类似声音的备选句子中找到最有可能的句子。更具体地说,我们使用确定有限状态自动机(deterministic finite-state Automaton, DFA)来构建mRNA设计空间,类似于“词格(word lattice)”(6),它紧凑地编码了指数级的候选mRNA。然后,我们使用格子解析来找到DFA中最稳定的mRNA,或在加权DFA中找到稳定性和密码子最优性之间的最佳平衡。这种结合自然语言的方法使得我们开发了一个高效的算法,可以将计算量控制在mRNA序列长度的平方级。从这个意义上说,我们的工作将庞大的搜索空间转变为一种福音(设计自由),而不是一个障碍。
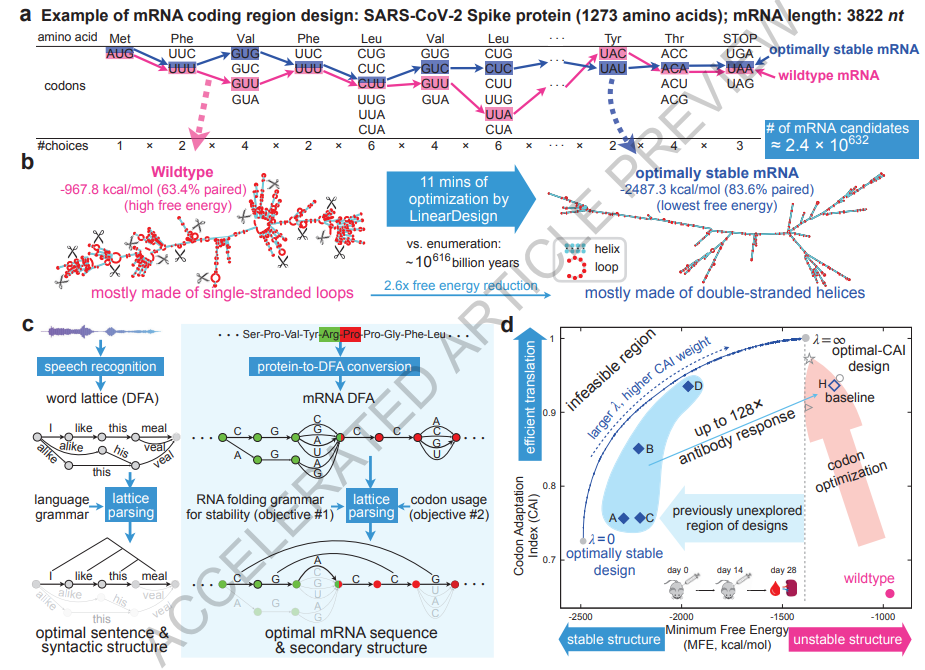
图1
与密码子优化基准相比,我们设计的COVID-19和水痘带状疱疹病毒(VZV)mRNA疫苗在体外化学稳定性、细胞内蛋白质表达和体内免疫原性方面均有显著改善。特别是,COVID-19疫苗相比基准(benchmark)能够实现高达128倍的抗体反应。这一令人惊讶的结果揭示了mRNA设计的巨大潜力,并使得这些先前难以实现但高度稳定且高效的设计得以被探索。因为LinearDesign可以优化编码所有治疗蛋白质的mRNA,包括单克隆抗体(7)和抗癌药物(8)的mRNA,因此,我们的工作不仅为mRNA疫苗提供了及时和有前景的工具,也为已经显示出具有改变医疗保健的巨大潜力的mRNA治疗提供了工具(14)。
构想与算法
先前的工作(5)为mRNA设计建立了两个主要目标,即稳定性和密码子最优性,这两者协同作用以增加蛋白质表达。为了优化稳定性,在给定蛋白质序列的情况下,我们的目标是找到在所有可能编码该蛋白质的mRNA序列中具有最低最小自由能变化(MFE)的mRNA序列。换句话说,对于每个候选mRNA序列,我们使用标准的RNA折叠能量模型(15, 16)筛选MFE能量最低的mRNA序列。因此这是双重最小化的问题(扩展数据图1a)。然而,利用这种朴素的方法将花费数十亿年的时间,因此我们需要一种高效的算法,而不是枚举法。
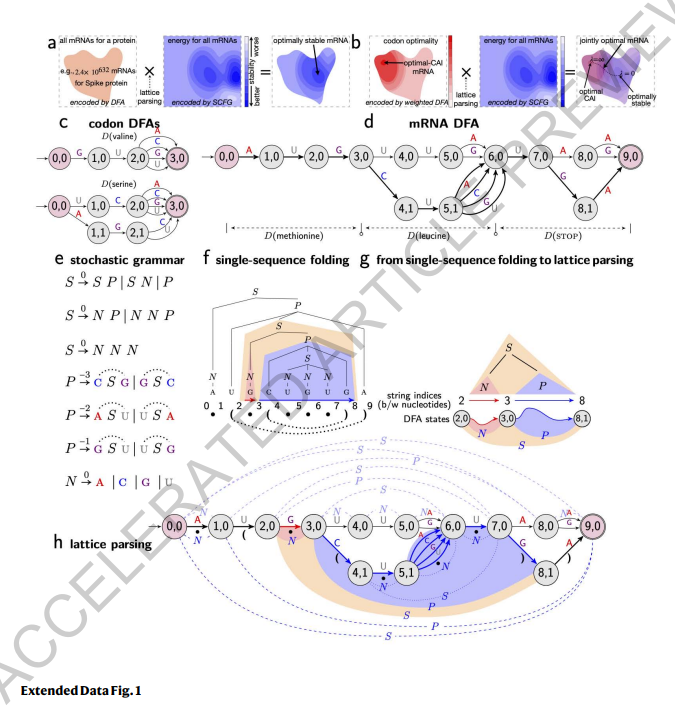
扩展数据图1
接下来,我们旨在共同优化mRNA的稳定性和密码子最优性。后者通常通过密码子适应性指数(Codon Adaptation Index, CAI)(17)来衡量,CAI被定义为mRNA中每个密码子相对适应性的几何平均值。由于CAI的取值范围在0和1之间,但MFE通常与mRNA序列长度成正比,我们将CAI的对数乘以mRNA中的密码子数,并使用一个超参数lambda来平衡MFE和CAI(lambda = 0表示仅考虑MFE)。综合目标函数为MFE - lambda|p| log CAI
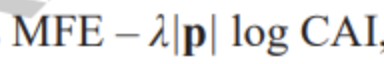
,其中|p|表示蛋白质的长度。有关详细信息,请参阅方法 §1.1 和扩展数据图1b。
接下来,我们使用从自然语言中借鉴的两个概念来描述解决这两个优化问题的方法:确定有限状态自动机(DFA,格子)和格子解析。
设计空间表示:DFA(格子)受计算语言学中对歧义的“词格”表示(扩展数据图2a)启发,我们使用类似的格子或更正式地说,确定有限状态自动机(DFA)来表示每个氨基酸的密码子选择(图2a和扩展数据图1c;有关正式定义,请参阅方法 §1.2)。在为蛋白质序列中的每个氨基酸构建一个密码子DFA后,我们将它们连接成一个单一的mRNA DFA,在起始状态和终止状态之间的每条路径代表一个可能的编码该蛋白质的mRNA序列(图2b和扩展数据图1d)。
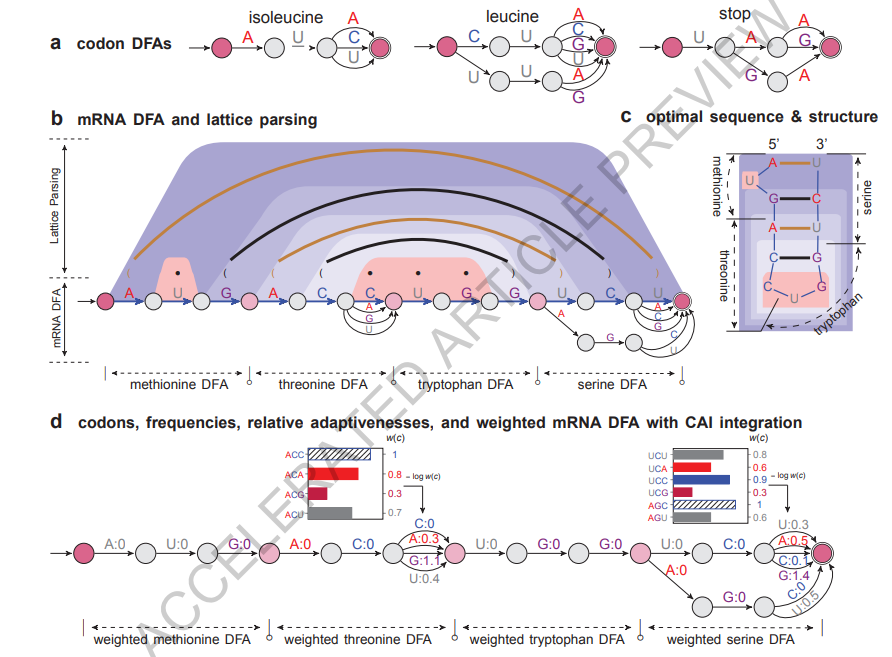
图2
扩展数据图2
目标1(稳定性):格子解析 已知RNA折叠等同于自然语言解析,其中随机上下文无关语法(SCFG)可以表示折叠能量模型(18)(扩展数据图1e-f)。但是对于mRNA设计来说,难点在于:如何将所有的mRNA序列一起在DFA中进行折叠?我们借鉴了“格子解析”(19, 6)的思想,该方法将单个序列解析推广到同时处理格子中的所有句子以找到最有可能的句子(图1c和扩展数据图2)。类似地,我们使用格子解析同时折叠mRNA DFA中的所有序列,以找到最稳定的序列(图2b和扩展数据图1g-h)。值得注意的是,格子解析也是动态规划的一种实例,但搜索空间更大,而单个序列的折叠可以看作是一个单链DFA的格子解析特例。这个过程也可以解释为SCFG-DFA的交集(扩展数据图1a),其中SCFG用于稳定性评分,而DFA则划定了候选集。该算法的运行时间与mRNA序列的长度呈立方关系(方法 §1.3),但在实际应用中,两者仅呈二次方关系(图3a)。
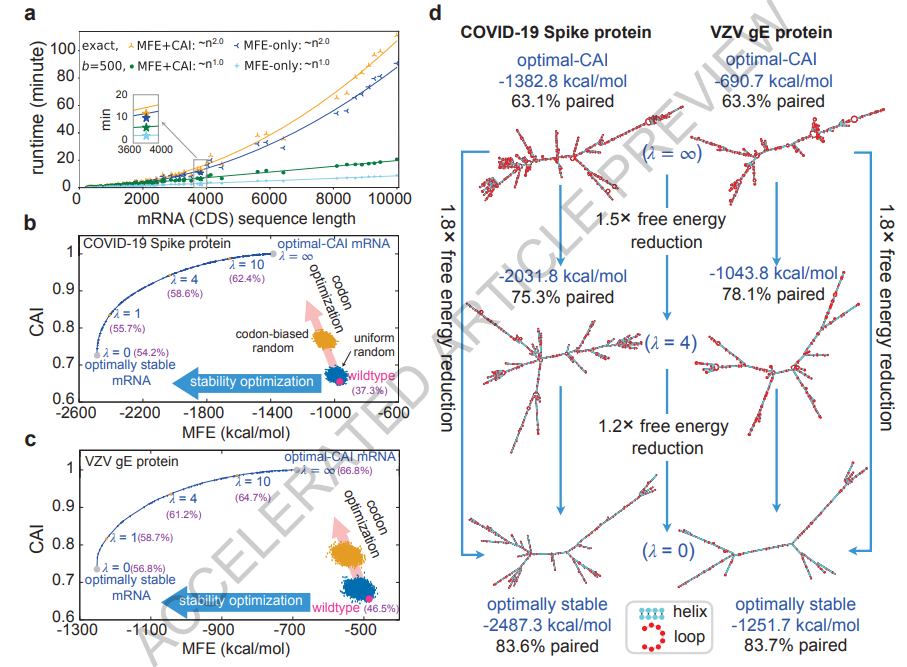
图3
目标2(密码子最优性):带权重的格子解析 我们将确定有限状态自动机(DFA)扩展为带权重的确定有限状态自动机(WDFAs),以便在边权重中集成密码子最优性。由于我们的联合优化公式将CAI因子分解为每个密码子c的相对适应性w(c),我们在每个密码子DFA中设置边权重,使得密码子c的路径成本为-log w(c),这可以解释为与最优密码子的“偏差量”。然后,在带权重的mRNA DFA中,每条起始-终止路径的成本是对应mRNA中每个密码子c的-log w(c)的总和,这与其-log CAI成正比(图2d)。现在,格子解析同时使用随机语法(用于稳定性)和带权重的DFA(用于密码子使用),并解决具有优化保证的联合优化问题,可以将其视为SCFG和WDFA之间的加权交集(20)(扩展数据图1b;方法 §1.4)。
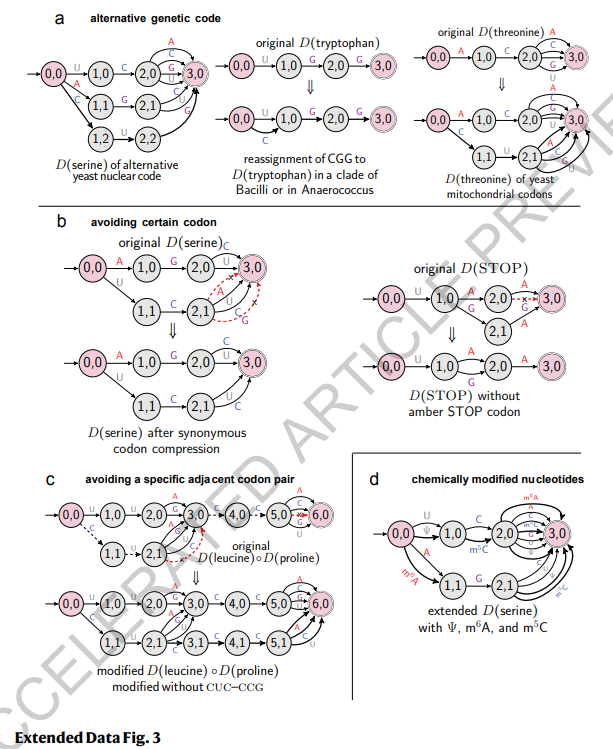
DFA的表现能力 我们的DFA框架非常通用,可以表示替代的遗传密码、修饰核苷酸和编码约束因素。详细信息请参见方法 §1.7,扩展数据图3和补充图5。
扩展数据图3
线性时间近似法 对于长序列,精确的设计算法可能仍然很慢。此外,由于mRNA设计中涉及许多除稳定性和密码子使用之外的因素,次优设计可能也值得在湿实验中进行探索。因此,受先前工作LinearFold(21)的启发,我们开发了一种近似搜索版本,使用波束搜索在线性时间内运行,每一步只保留最有前景的b个项目(b是波束大小)。
相关工作 之前的两项研究也通过动态规划解决了“最稳定的mRNA设计”问题(我们的目标1),但是利用Zuker算法的专门扩展(22, 23)无法兼具密码子最优性(目标2)。相比之下,我们建立了mRNA设计与计算语言学中的格子解析之间的联系,这也是我们工作最具创新性的贡献。这种联系使得我们能够使用更简单、更通用的算法,可以同时优化密码子使用,并利用一个新颖的目标函数将CAI因子分解到个别密码子上。我们还通过体内验证了这些算法设计的mRNA,结果显示两个mRNA疫苗的效果具有显著的改善(图4-5)。详细信息请参见方法 §1.1和§1.8。
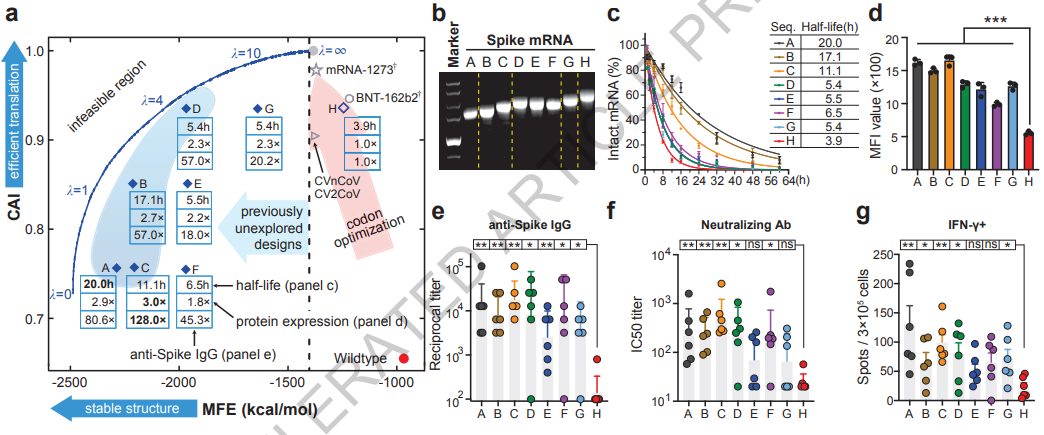
图4
计算机模拟结果和分析
图3a展示了LinearDesign对UniProt蛋白质的运行时间。LinearDesign通过两个优化目标的组合进行展示,即仅MFE(目标1)与MFE+CAI(目标1和2),以及两种搜索模式,即精确搜索与波束搜索(波束大小b=500)。经验证,由于DFA表示和格子解析的便利性,LinearDesign在实际应用中对mRNA序列长度n呈二次方扩展(n<10,000 nt)(补充图7-8)。接下来,我们集成CAI的精确搜索(CAI权重lambda=4)具有相同的实证复杂性,与仅MFE版本相比仅慢约15%,这要归功于我们的DFA表示对于添加CAI的便利性。最后,我们的波束搜索版本(b=500)进一步加快了设计速度,并且与序列长度呈线性扩展,仅MFE的近似搜索在SARS-CoV-2 Spike蛋白上仅需2.7分钟,而精确搜索需要10.7分钟,近似误差(即能量差异%,定义为1 - MFEapprox_design / MFEexact_design)仅为1.2%。实际上,随着序列变得更长,这个百分比趋于稳定,表明波束搜索质量不会随着序列长度的增加而下降(补充图9)。
对于偏好GC的密码子的mRNA(例如人类),传统的密码子优化方法确实可以提高稳定性,但仅略有改善(图3b-c),因为其优化方向(粉色箭头)在很大程度上与稳定性优化方向(蓝色箭头)几乎正交。相比之下,我们的LinearDesign可以直接优化稳定性并找到最稳定的mRNA序列。在COVID Spike蛋白和VZV gE蛋白中,最低的MFE值(l=0)比最优CAI(l=¥)的MFE值低1.8倍。此外,我们的最稳定设计主要具有双链二级结构(图3d),据预测这种结构更不容易降解(5)。通过l在0到¥范围内变化,LinearDesign计算了mRNA设计空间的可行性界限(最优边界)(图3b-c中的蓝色曲线;请参见扩展数据图4中(–¥, 0]中的l)。此外,当密码子偏好偏向AU富集密码子(如酵母)时,密码子优化实际上会导致稳定性的降低。
COVID-19 mRNA疫苗的结果
对于COVID-19 Spike蛋白质,本研究使用了八条mRNA序列。其中七条序列(序列A-G)是使用LinearDesign算法设计的次优分子(使用波束搜索(21, 25))。它们广泛分布在低MFE设计空间中(图4a中MFE £ 1,400 kcal/mol的区域),这是传统密码子优化算法无法达到的。为了更好地理解MFE和CAI参数的生物学影响,我们设计了这些mRNA序列,使它们在MFE(B-C // D-E-F)或CAI(A-C-F // B-E // D-G-H)方面几乎具有相同的值。第八个mRNA序列(序列H)是使用广泛使用的密码子优化算法OptimumGene™设计的基准序列。这个基准序列H已经被用于一种COVID-19 mRNA疫苗,在两个动物模型中显示出高免疫原性,并进入了中国的I期临床试验(与中国疾控中心共同开发;中国临床试验注册:CTR20210542)。所有的mRNA编码了完整的SARS-CoV-2野生型Spike蛋白的相同氨基酸序列,并共享相同的5'-和3'-UTR(有关序列请参见补充信息)。
考虑到由结构化的5'-leader区域可能对翻译效率产生负面影响(5),在运行LinearDesign时,我们在设计中不包含前5个氨基酸,而是使用一种启发式方法选择了前15个核苷酸。另外,长的螺旋结构可能引起不必要的先天免疫反应(27),因此我们在设计中避免了这些结构。这也解释了为什么我们没有研究最低MFE的候选者(最接近最优边界-图4中的蓝色曲线),这些候选者通常包含较长的结构。详见方法§1.10。
除了编码区设计,UTR结构对于翻译也至关重要(28),UTR工程对蛋白质表达具有深远影响(3)。尽管LinearDesign本身并不涉及UTR优化,但它具有一个有趣的特性,即其设计的mRNA分子相对于密码子优化的分子来说更具结构性,与广泛使用的UTR结构形成较少的碱基配对,从而对UTR的结构干扰较小(扩展数据表1)。这个推测在我们设计的不同UTR的VZV mRNA疫苗的实验中得到了验证,LinearDesign设计的mRNA具有更高的蛋白表达水平和免疫反应。这些证据表明LinearDesign设计的有效性不依赖与UTR的选择,这与近期的一项研究结果一致:体内实验表明,利用LinearDesign设计的三个具有不同UTR的mRNA的蛋白表达强度优于基准算法设计的mRNA(见参考文献的图4a);详见方法§1.8。
溶液中的结构紧凑性和化学稳定性
随后我们研究了mRNA分子的结构紧凑性(被假设与折叠自由能变化相关)。具有较低MFE的mRNA分子倾向于包含更多的二级结构,呈现更紧凑的形状和较小的流体动力学尺寸。因此,它在电泳中移动得更快。我们将mRNA样品加载到非变性琼脂糖凝胶上,并发现RNA的迁移速率与序列A-H的MFE具有良好的相关性(图4b),尽管序列A-H具有相似的分子量。具有最低MFE的序列A移动最快,其次是其他序列中具有最低MFE的序列,顺序与它们的MFE值相符。具有最高MFE值的序列H移动最慢。这组数据证明了LinearDesign执行的MFE计算的有效性。
为了评估mRNA的化学稳定性,我们将mRNA加入含有10 mM(图4c)或20 mM(扩展数据图5)Mg2+的缓冲液中,37°C孵育,并在孵育后评估RNA的完整性,类似于先前的研究(29)。序列A-H表现出明显不同的降解速率,且与它们的MFE值具有良好的相关性(图4c和扩展数据图5)。具有最低MFE的序列A显示出最慢的降解速率,其半衰期(T1/2)分别为10 mM和20 mM Mg2+缓冲液中的20.0小时和12.6小时(图4c和扩展数据图5)。相比之下,具有最高MFE值的序列H降解最快,其T1/2分别为10 mM和20 mM Mg2+缓冲液中的3.9小时和3.3小时。这些结果支持低MFE设计更能抵抗在溶液中的降解,具有有利的生物学意义。
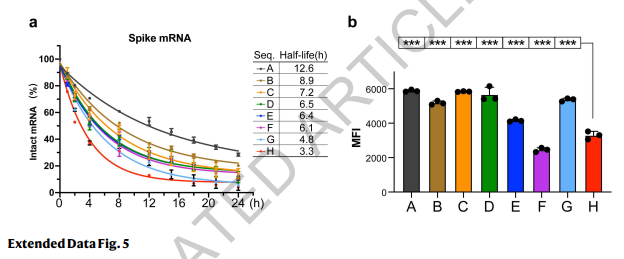
扩展数据图5
细胞内蛋白质表达 对于疫苗产品来说,充分的抗原表达是引发有效免疫反应的关键因素之一。接下来,我们评估了设计的mRNA的蛋白质表达情况。将所有序列A-H转染HEK293细胞后,可以有效地将它们翻译成S蛋白。值得注意的是,所有7个由LinearDesign生成的mRNA(序列A-G)的蛋白质表达水平均比基准序列H显著升高(图4d和补充图12)。具有与H几乎相同的CAI值但更低MFE的D和G序列的蛋白质表达量比H序列高2.3倍,而具有最低MFE的A序列的表达量则提高了2.9倍。总的来说,我们的结果与Mauger等人的研究结果一致,即低MFE和高CAI能够协同提高蛋白质表达水平,但我们能够使用具有比他们更低MFE的mRNA分子来测试这个假设,这要归功于LinearDesign能够探索以前无法到达的设计空间。
体内免疫原性 我们进一步测试了这些设计是否能够在体内赋予优越的免疫原性。通过脂质基载体将序列A-H的mRNA递送至体内,并对细胞免疫和体液免疫反应进行了评估。对于每个mRNA序列,我们在C57BL/6小鼠肌肉均注射两剂疫苗,间隔2周。评估了抗Spike IgG抗体水平、中和抗体(NAbs)水平以及Spike特异性干扰素-γ(IFN-γ)分泌T细胞。LinearDesign生成的所有mRNA分子都能够引发强烈的抗体反应。相比之下,序列H的mRNA几乎无法诱导抗体(图4e-f)。在抗原特异性T细胞反应上也观察到了类似的结果,只有LinearDesign生成的mRNA能够引发强烈的Th1型T细胞反应(图4g)。离最优边界更近序列A-D(图4a中阴影区域),与基准序列H相比,其抗Spike IgG抗体滴度增加了57~128倍,中和抗体的滴度提高了9~20倍。
由于辉瑞/BioNTech的BNT162b2是最广泛采用的COVID-19 mRNA疫苗,我们节选了它的mRNA序列,作为并行对照。为具有可比性,我们建立了新的mRNA分子BNT,其5’和3’UTR序列与序列A-H保持一致,蛋白编码序列采用BNT162b2的蛋白编码序列。BNT162b2的“2P”氨基酸突变(31)被恢复成野生型。该研究的4条序列(A,C,H和BNT)中,与BNT mRNA相比,序列A和C的降解速率显著降低(扩展数据图6)。值得注意的是,BNT和序列H具有非常相近的MFE和CAI(图4a)且具备相似的半衰期。此外,与BNT和序列H相比,序列A和C能诱导产生更高水平的抗Spike IgG抗体和中和抗体(扩展数据图7)。总之,这些数据足以支持我们推断LinearDesign优化的mRNA分子在体外更稳定,进而提高蛋白质的表达,增强免疫原性。
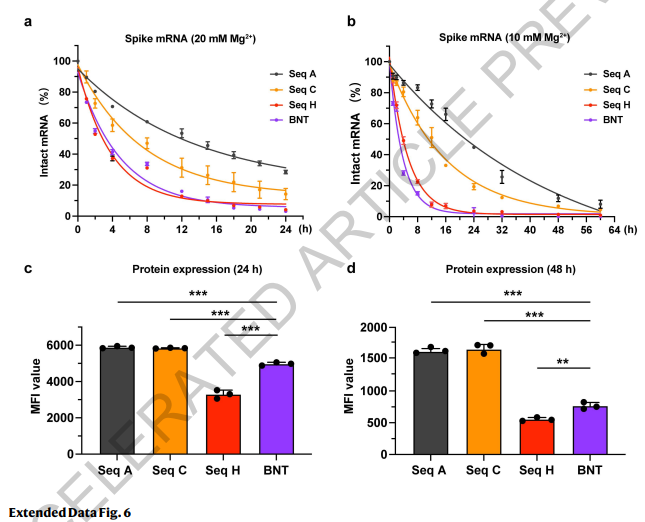
扩展数据图6
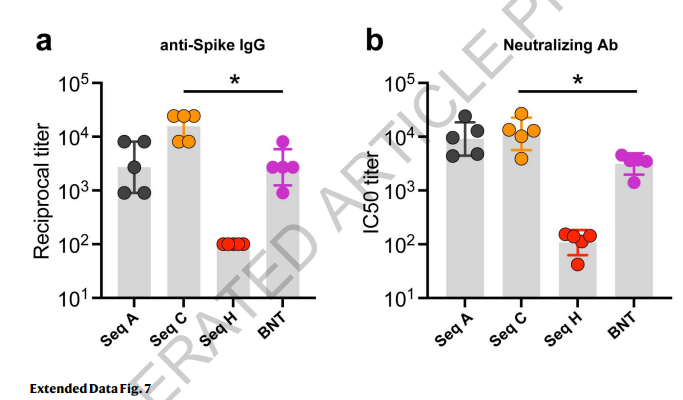
扩展数据图7
VZV mRNA疫苗的结果
为了进一步评估LinearDesign的普适性,我们还将该算法应用于水痘-带状疱疹病毒(VZV)mRNA疫苗的设计。VZV疫苗被认为是降低带状疱疹风险的有效方法(32)。使用与Spike mRNA设计相同的策略(图4a),我们生成了五个编码完整VZV gE蛋白的mRNA序列(gE A-E)。它们广泛分布在之前未被探索的高热稳定性区域(图5a)。这些序列与使用密码子优化工具GeneOptimizer(ThermoFisher Scientific开发)(33)设计的gE-Ther序列进行了基准对比。所有这些mRNA,包括野生型mRNA(gE-WT),共享相同的编码氨基酸序列和5'/3' UTRs。有关序列的详细信息请参阅补充信息。与Spike mRNA数据一致(图4b),具有最低MFE的gE-A mRNA在非变性凝胶中显示出更高的迁移率(图5b),在10 mM Mg2+缓冲液中T1/2为66.5小时(图5c)和在20 mM Mg2+缓冲液中为50.7小时(扩展数据图8a),具有显著较慢的降解速率,这表明与分子的紧凑性与化学稳定性正相关。相比之下,gE-Ther在10 mM和20 mM Mg2+缓冲液中的T1/2分别为10.9小时和5.9小时。我们还注意到,由于长度较短(34),gE mRNA分子的稳定性总体上优于Spike mRNA。此外,转染HEK293细胞后的48小时(图5d)和24小时(扩展数据图8b),大多数由LinearDesign生成的分子(gE B-E)在蛋白质表达方面表现优于gE-Ther和WT。但有趣的是,表现最佳的mRNA分子是gE B-D,它们在蛋白质表达方面表现优于具有最低CAI的gE-A和具有最低MFE的gE-E。这一发现再次强调了同时优化CAI和MFE的重要性。最优分子是那些具有有利的CAI和MFE值的分子,在图5a中我们用浅蓝色阴影区域突出显示了这个“甜点”区域。最后,我们在C57BL/6小鼠中评估了VZV mRNA的免疫原性。LinearDesign设计的mRNA分子(gE-B, C 和E)诱导产生抗gE IgG抗体的水平显著高于gE-Ther和WT(图5e)。
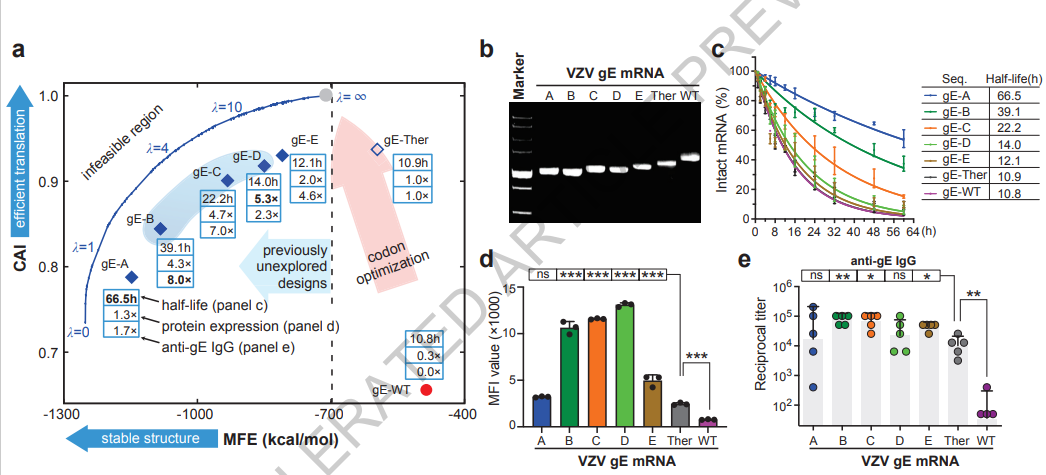
图5

扩展数据图8
讨论
有效的mRNA设计策略对于开发mRNA疫苗至关重要,这些疫苗在当前和未来的流行病中展现出巨大的潜力。然而,由于搜索空间巨大,这是一个极具挑战性的问题。我们提出了一个简单的解决方案,将mRNA设计问题简化为计算语言学中的经典格子解析问题。这种高度出乎意料的类比是这项工作最具创新性的部分,它产生了一个高效的算法,仅需11分钟即可处理SARS-CoV-2蛋白质的设计。该算法还可以同时优化稳定性和密码子使用,这是根据文献和我们的VZV实验中对mRNA设计的重要性所确定的。我们的跨学科方法是近来语言学和生物学之间富有成果的交流之一(35, 36)。本研究全面评估了LinearDesign生成的mRNA序列,并证明其在化学稳定性、蛋白质翻译和体内免疫原性等对疫苗性能至关重要的三个方面上优于常用的密码子优化基准算法。特别是我们针对Spike蛋白的设计,在结合抗原上比密码子优化基准显示出高达128倍的抗体水平增加,我们的VZV mRNA设计,使用不同的UTR组合,也显示出显著的改进。这些结果表明了LinearDesign在不依赖于UTR组合的优化编码区域方面的稳健性。事实上,这两个方向(编码区域设计和UTR工程(3))是互补的,可以在未来的工作中结合起来。值得注意的是,尽管我们设计的mRNA没有使用化学修饰(这种修饰被广泛认为是mRNA疫苗最近成功的关键因素(37,38,10,1,2)),仍然表现出高水平的稳定性、翻译效率和免疫原性,且具有较低的生产成本。另一方面,我们的算法与化学修饰相辅相成,一旦相应的能量模型可用,它可以轻松地适应并享受修饰核苷酸的好处。我们的工作仅考虑了稳定性和密码子使用,但格子表示具有通用性,一旦相关参数可用,也可以适应于优化与mRNA设计相关的其他参数。通过释放以前无法触及的高稳定性和高效序列区域,LinearDesign成为了应对当前和未来大流行病的mRNA疫苗开发的及时且有前景的工具。但更重要的是,这也是mRNA治疗领域分子设计的一般和原理性方法,不仅适用于设计mRNA疫苗,也可以广泛应用于mRNA治疗领域其他分子的设计。我们可以利用此方法设计编码各种治疗性蛋白质的mRNA,如单克隆抗体、细胞因子、酶等,用于治疗疾病。这为开发针对癌症、自身免疫性疾病等的mRNA治疗方法提供了很好的思路。
编者总结:
研究人员开发了一种用于优化mRNA的设计算法,该算法可以提高mRNA的稳定性、翻译效率和免疫原性。利用这种算法设计的mRNA可以产生更高水平和更持久的基因表达,并诱导更强的免疫应答。
这项工作为mRNA在分子设计和医学中的广泛应用奠定了基础。它不仅对当前的新冠疫情有重要意义,也为开发针对其他疾病的mRNA治疗方法提供了很好的参考。这种通用方法使我们可以设计各种具有治疗潜力的mRNA分子来调节人体的生物过程。
阅读原文信息:
https://www.nature.com/articles/s41586-023-06127-z
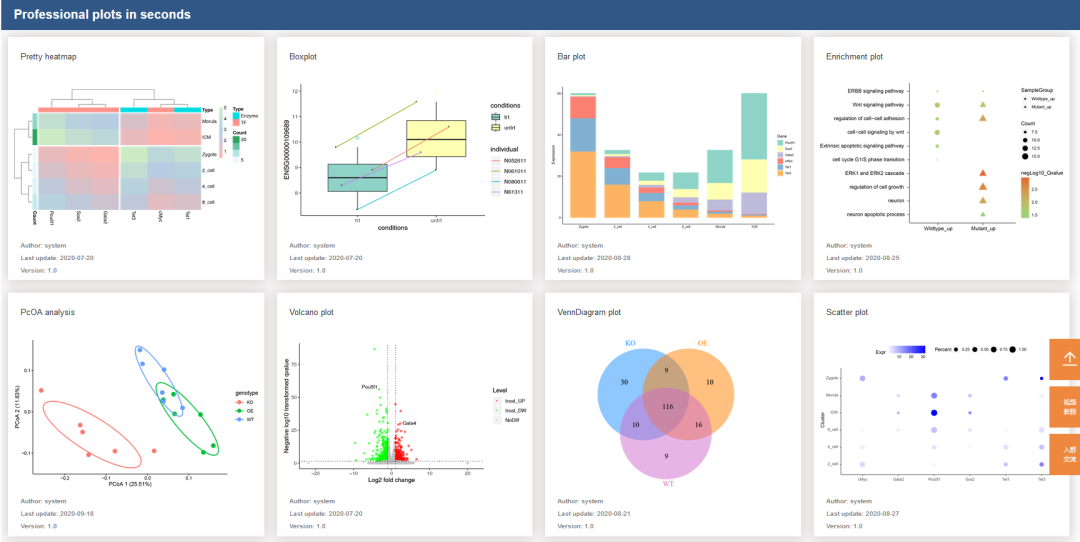
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|




























机器学习