最近一个朋友发现一个比较有趣的网站,他说正常构造一个HTTP请求居然拿不到网站页面的信息,网站页面如下:
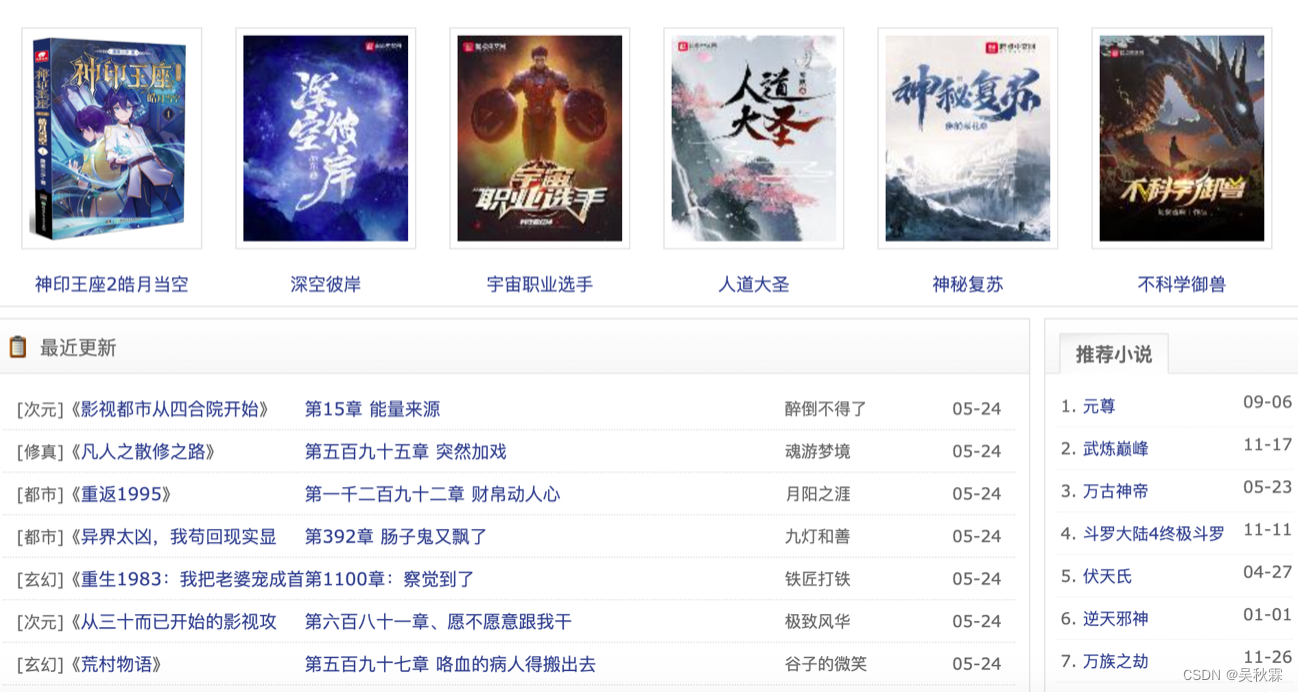
别看它只是一个普普通通的小说网站。随后我在本地环境验证了一下,果不其然得到了以下信息:
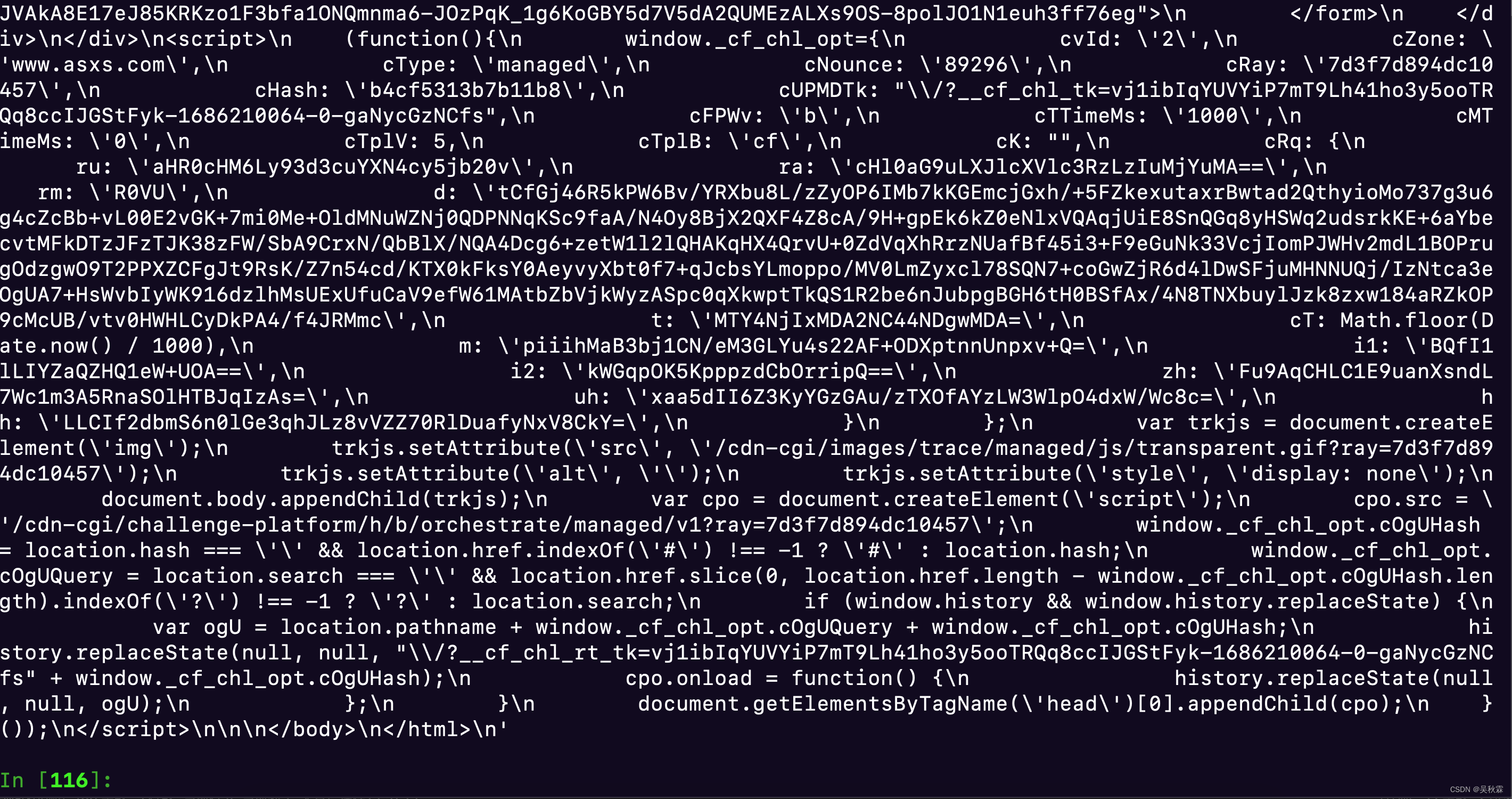
从上面反馈的信息中来看的话,倒是跟之前碰到的一个境外网站有着一点异曲同工之妙
没错!它这个反馈信息就是Cloudflare的防护页面。这个页面要求验证是否为真实用户,以防止机器人或恶意攻击
之前有一段时间研究了一下Bot自动化攻击智能阻断与防护相关的一些东西。发现像现在的一些安全厂商很多都拥有多机制阻断和防护爬虫的风控类产品,我们都知道以前的反爬虫产品大多都是基于规则的,是有天然缺陷的。Cloudflare针对爬虫的防护机制如下:
1、JS环境检测与行为分析:网站可以通过JavaScript监测和分析用户的行为模式,包括鼠标移动、点击、键盘输入等。要继续访问网站,客户端必须执行JS代码,然后重新发送经过验证的请求。这种机制可防止简单的爬虫,因为它们通常不能执行JavaScript代码
2、IP封禁:Cloudflare可以封禁恶意爬虫使用的IP地址。它维护一个全球性的恶意IP地址数据库,并使用这些数据来自动封禁或限制具有恶意行为的IP地址的访问
3、人机识别:Cloudflare通过人机识别来区分正常的用户和爬虫。这可以包括识别用户的行为模式、验证用户的身份(例如,通过验证码)或要求用户执行特定的交互行为
4、异常流量分析:Cloudflare使用机器学习和数据分析来检测异常的访问模式和流量模式。如果请求的频率或模式与正常用户行为相比异常,Cloudflare可以将其标记为恶意爬虫,并阻止相关的请求
5、签名识别:Cloudflare使用预定义的规则和模式识别技术来检测已知的爬虫和恶意行为。这些规则可以基于HTTP头部、请求模式、用户代理等来进行匹配和识别
6、WAF:Cloudflare的WAF功能可以检测和防御常见的Web应用程序攻击,包括针对爬虫的攻击,例如SQL注入、跨站点脚本(XSS)等。WAF可以根据规则和模式匹配来识别和阻止恶意爬虫的行为
接下来,要想正常拿到上面说的到网站页面数据。很简单!只需要使用Docker运行一个容器就可以了。命令如下:
docker run -d \
--name=flaresolverr \
-p 8191:8191 \
-e LOG_LEVEL=info \
--restart unless-stopped \
ghcr.io/flaresolverr/flaresolverr:latest

容器启动以后,会开启8191端口。通过这个端口发送http请求,让它将请求转发给目标网站,就可以绕过Cloudflare防护:
import json
import requests
url = 'http://localhost:8191/v1'
payload = json.dumps({
"cmd": "request.get",
"url": 'https://www.asxs.com/',
"maxTimeout": 60000
})
headers = {'Content-Type': 'application/json'}
response = requests.post(url, headers=headers, data=payload)
print(response.json()['solution']['response'])
通过上述代码,就能正常获取到页面数据了,效果图如下所示:
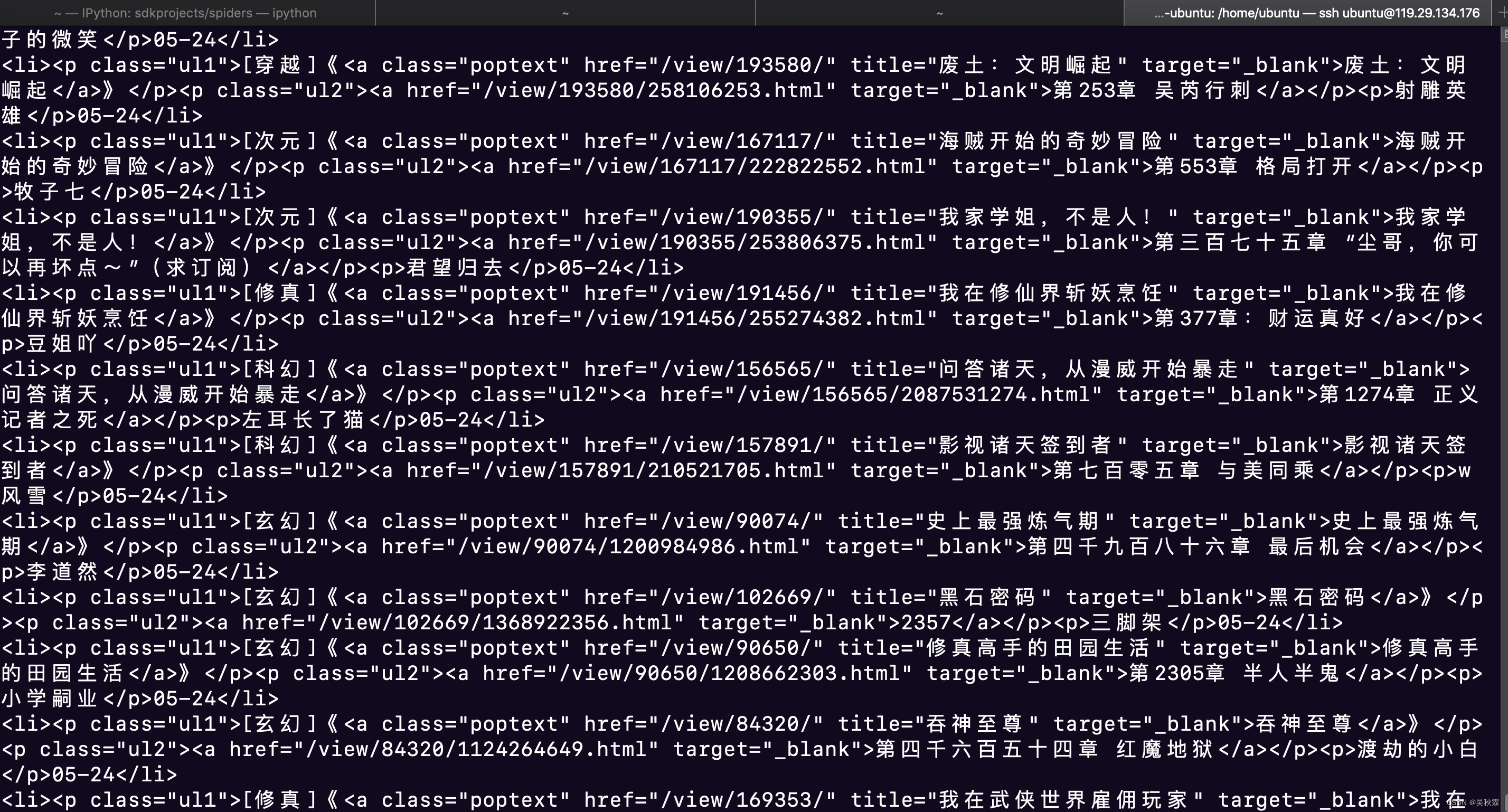
为什么启动了这个容器之后就可以绕过CloudFlare的防护了?关键原因就在这个项目中:FlareSolverr。我们看一下源代码可以发现FlareSolverr 就是一个代理服务器,内置了一个浏览器,处理我们发送的请求。
可能有些人会觉得多此一举,为什么不直接自己使用Selenium模拟请求呢???
我仔细看了一下这个项目的源码,并且总结了一下FlareSolverr这个项目的亮点,主要体现在以下几个方面:
1、动态解析和执行 JavaScript:FlareSolverr 能够解析和执行Cloudflare的JS 代码,这样就可以模拟浏览器行为并执行页面中的 JavaScript,以获取真实的网页内容。这是相对传统的静态解析方式(比如直接获取页面源码)的一种突破
2、自动化处理验证页面:它在容器内部运行一个Webdriver的服务,用于自动处理 Cloudflare 验证页面。这种自动化处理方式相对于手动模拟浏览器操作更加高效和方便,减少了人工干预的需要
3、缓存和复用验证结果:FlareSolverr具有缓存机制,可以将已经解析和验证过的网站结果缓存起来,并在后续的请求中进行复用。这样可以减少重复的验证过程,提高访问速度和效率
那么我们再说到为什么不直接使用Selenium。因为尽管FlareSolverr 和使用Selenium模拟浏览器都可以绕过 Cloudflare 验证页面,但两者之间我感觉是存在一些本质的区别的:
1、集成度和依赖性:这个项目算是一个专门为解决Cloudflare绕过而设计的工具,它可以作为独立的服务部署,对外提供 API 接口(而使用 Selenium 需要自行搭建浏览器环境并编写脚本进行模拟操作)
2、环境隔离和资源消耗:这个项目使用了容器化技术,在独立的环境中执行验证操作,避免了对本地环境的影响(而使用 Selenium 需要在本地搭建浏览器环境,可能占用较多的系统资源 )
3、验证处理方式:这个项目使用自动化的方式处理验证页面,可以自动识别和完成验证操作(而使用 Selenium需要编写脚本来模拟用户操作,可能需要更多的代码编写和维护工作 )
总体而言的话,FlareSolverr在处理 Cloudflare绕过上面提供了一种更加集成化、自动化和高效的解决方案,相对于手动模拟浏览器操作或使用Selenium等方式,可以节省开发和维护的成本,并提供更好的性能和可靠性
好了,到这里又到了跟大家说再见的时候了。创作不易,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章