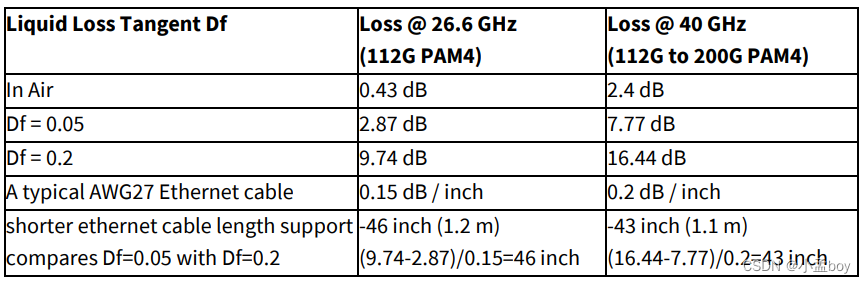
1、InfluxDB基本数据结构
| 数据结构 | 含义 |
|---|---|
| database | 数据库 |
| measurement | 数据库中的表 |
| retention policy | 保存策略:让InfluxDB能够知道可以丢弃哪些数据,设置数据自动清除时间,从而更高效的处理数据 |
| points | 表里面的一行数据 |
points的数据结构
| 数据结构 | 含义 |
|---|---|
| time | 每个数据记录时间,是数据库中的主索引(会自动生成) |
| fields | 各种记录值(没有索引的属性)也就是记录的值 |
| tags | 各种有索引的属性 |
| series | 表示这个表里面的数据,可以在图表上画成几条线:通过tags排列组合算出来。 |
2、InfluxQL语法
2.1 SELECT语句
SELECT语句从一个或多个measurement中查询数据。
SELECT <field_key>[,<field_key>,<tag_key>] FROM <measurement_name>[,<measurement_name>]
SELECT语句需要一个SELECT子句和一个FROM子句。
SELECT子句
SELECT子句支持多种指定数据的格式:
SELECT * 返回所有的field和tag。
SELECT “<field_key>” 返回一个特定的field。
SELECT “<field_key>”,“<field_key>” 返回多个field。
SELECT “<field_key>”,“<tag_key>” 返回一个特定的field和一个特定的tag,当SELECT子句包含tag时,它必须至少指定一个field。
SELECT “<field_key>”::field,“<tag_key>”::tag 返回一个特定的field和一个特定的tag。::[field | tag]语法指定了标识符的类型,使用这个语法是为了区分具有相同名字的field key和tag key。
除此之外,SELECT子句支持的功能还有:算术运算、函数、转换操作和正则表达式。
FROM子句
FROM子句支持多种指定measurement的格式:
FROM <measurement_name>从一个measurement中返回数据。如果您使用CLI查询数据,那么访问的measurement属于USE指定的数据库,并且使用的是默认保留策略。如果您使用的是HTTP API,那么measurement属于参数db指定的数据库,同样,使用的是默认(DEFAULT)的保留策略。
FROM <measurement_name>,<measurement_name>从多个measurement中返回数据。
FROM <database_name>.<retention_policy_name>.<measurement_name>从一个被完全限定的measurement中返回数据。通过明确指定measurement的数据库和保留策略来完全限定一个measurement。
FROM <database_name>…<measurement_name>从用户指定的一个数据库并使用默认保留策略的measurement中返回数据。
除此之外,FROM子句还支持的功能:正则表达式。
引号
如果标识符包含除了[A-z,0-9,_]之外的字符,或者以数字开头,又或者是InfluxQL关键字,那么它们必须使用双引号。虽然并不总是需要,但是我们建议您为标识符加上双引号。
说明 这里关于引号的语法与行协议中的不同。
示例
查询单个measurement中的所有field和tag
SELECT * FROM "h2o_feet"
name: h2o_feet
--------------
time level description location water_level
2015-08-18T00:00:00Z below 3 feet santa_monica 2.064
2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12
[...]
2015-09-18T21:36:00Z between 3 and 6 feet santa_monica 5.066
2015-09-18T21:42:00Z between 3 and 6 feet santa_monica 4.938
该语句从h2o_feet这个measurement中查询所有的field和tag。
如果您使用CLI,请确保在执行上面的查询前,先输入USE NOAA_water_database,CLI将查询被USE指定的数据库并且保留策略是默认的数据。如果您使用的是HTTP API,那么请确保将参数db设为NOAA_water_database,如果没有设置参数rp,那么HTTP API将自动使用该数据库的默认保留策略。
查询单个measurement中的特定的field和tag
SELECT "level description","location","water_level" FROM "h2o_feet"
name: h2o_feet
--------------
time level description location water_level
2015-08-18T00:00:00Z below 3 feet santa_monica 2.064
2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12
[...]
2015-09-18T21:36:00Z between 3 and 6 feet santa_monica 5.066
2015-09-18T21:42:00Z between 3 and 6 feet santa_monica 4.938
该查询选择了两个field:level description和water_level,和一个tag:location。
说明 当SELECT子句包含tag时,它必须至少指定一个field。
查询单个measurement中的带标识符类型的特定的field和tag
SELECT "level description"::field,"location"::tag,"water_level"::field FROM "h2o_feet"
name: h2o_feet
--------------
time level description location water_level
2015-08-18T00:00:00Z below 3 feet santa_monica 2.064
2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12
[...]
2015-09-18T21:36:00Z between 3 and 6 feet santa_monica 5.066
2015-09-18T21:42:00Z between 3 and 6 feet santa_monica 4.938
该查询选择了两个field:level description和water_level,和一个tag:location。::[field | tag]语法明确指出了该标识符是field还是tag。当field key和tag key的名字相同时,请使用::[field | tag]来区分它们。大多数情况下,并不需要使用该语法。
查询单个measurement中的所有field
SELECT *::field FROM "h2o_feet"
name: h2o_feet
--------------
time level description water_level
2015-08-18T00:00:00Z below 3 feet 2.064
2015-08-18T00:00:00Z between 6 and 9 feet 8.12
[...]
2015-09-18T21:36:00Z between 3 and 6 feet 5.066
2015-09-18T21:42:00Z between 3 and 6 feet 4.938
该查询从h2o_feet中选择了所有的field。SELECT子句支持将*和::这两个语法结合使用。
查询单个measurement中的特定的field并进行基本运算
SELECT ("water_level"*2)+4 from "h2o_feet"
name: h2o_feet
--------------
time water_level
2015-08-18T00:00:00Z20.24
2015-08-18T00:00:00Z8.128
[...]
2015-09-18T21:36:00Z14.132
2015-09-18T21:42:00Z13.876
查询多个measurement中的所有数据
SELECT * FROM "h2o_feet","h2o_pH"
name: h2o_feet
--------------
time level description location pH water_level
2015-08-18T00:00:00Z below 3 feet santa_monica 2.064
2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12
[...]
2015-09-18T21:36:00Z between 3 and 6 feet santa_monica 5.066
2015-09-18T21:42:00Z between 3 and 6 feet santa_monica 4.938
name: h2o_pH
------------
time level description location pH water_level
2015-08-18T00:00:00Z santa_monica 6
2015-08-18T00:00:00Z coyote_creek 7
[...]
2015-09-18T21:36:00Z santa_monica 8
2015-09-18T21:42:00Z santa_monica 7
该查询从两个measurement(h2o_feet和h2o_pH)中选择所有的field和tag,多个measurement之间用逗号(,)隔开。
查询完全限定的measurement中的所有数据
SELECT * FROM "NOAA_water_database"."autogen"."h2o_feet"
name: h2o_feet
--------------
time level description location water_level
2015-08-18T00:00:00Z below 3 feet santa_monica 2.064
2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12
[...]
2015-09-18T21:36:00Z between 3 and 6 feet santa_monica 5.066
2015-09-18T21:42:00Z between 3 and 6 feet santa_monica 4.938
该查询从h2o_feet中选择了所有数据,h2o_feet是属于数据库NOAA_water_database和保留策略autogen的measurement。
如果使用CLI,可以用这种完全限定measurement的方式来代替USE指定的数据库和指定DEFAULT之外的保留策略。如果使用HTTP API,可以通过完全限定measurement的方式,代替设置参数db和rp。
查询特定数据库的measurement中的所有数据
SELECT * FROM "NOAA_water_database".."h2o_feet"
name: h2o_feet
--------------
time level description location water_level
2015-08-18T00:00:00Z below 3 feet santa_monica 2.064
2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12
[...]
2015-09-18T21:36:00Z between 3 and 6 feet santa_monica 5.066
2015-09-18T21:42:00Z between 3 and 6 feet santa_monica 4.938
该查询从h2o_feet中选择了所有数据,h2o_feet是属于数据库NOAA_water_database和默认(DEFAULT)保留策略的measurement。…表示指定数据库的默认保留策略。
如果使用CLI,可以这种指定数据库的方式来代替USE指定的数据库。如果使用HTTP API,同样可以通过指定数据库,代替设置参数db。
SELECT语句的常见问题
在SELECT子句中查询tag key
一个查询在SELECT子句中必须至少包含一个field key才能返回结果。如果SELECT子句中只包含一个或多个tag key,那么该查询会返回一个空的结果。这种返回结果的要求是系统存储数据的方式导致的。
示例
下面的查询不返回任何数据,因为它在SELECT子句中只给定了一个tag key(location):
SELECT "location" FROM "h2o_feet"
想要返回跟tag key location相关的数据,查询中的SELECT子句必须至少包含一个field key(water_level):
SELECT "water_level","location" FROM "h2o_feet" LIMIT 3
name: h2o_feet
time water_level location
-----------------------
2015-08-18T00:00:00Z8.12 coyote_creek
2015-08-18T00:00:00Z2.064 santa_monica
[...]
2015-09-18T21:36:00Z5.066 santa_monica
2015-09-18T21:42:00Z4.938 santa_monica
2.2 WHERE语句
WHERE子句根据field、tag和/或timestamp来过滤数据。
SELECT_clause FROM_clause WHERE <conditional_expression> [(AND|OR) <conditional_expression> […]]
WHERE子句支持在field、tag和timestamp上的条件表达式(conditional_expression)。
field
field_key [‘string’ | boolean | float | integer]
WHERE子句支持对field value进行比较,field value可以是字符串、布尔值、浮点数或者整数。
在WHERE子句中,请对字符串类型的field value用单引号括起来。如果字符串类型的field value没有使用引号或者使用了双引号,那么不会返回任何查询结果,在大多数情况下,也不会返回错误。支持的操作符:
| 操作符 | 含义 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| > | 大于 |
| >= | 大于或等于 |
| < | 小于 |
| <= | 小于或等于 |
除此之外,还支持的功能:算术运算和正则表达式。
tag
tag_key [‘tag_value’]
在WHERE子句中,请对tag value用单引号括起来。如果tag value没有使用引号或者使用了双引号,那么不会返回任何查询结果,在大多数情况下,也不会返回错误。支持的操作符:
| 操作符 | 含义 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
除此之外,还支持的功能:算术运算和正则表达式。
timestamp
对于大多数SELECT语句,默认的时间范围是从1677-09-21 00:12:43.145224194 UTC到2262-04-11T23:47:16.854775806Z UTC。对于带GROUP BY time()子句的SELECT语句,默认的时间范围是从1677-09-21 00:12:43.145224194 UTC到now()。
示例
查询field value满足一定条件的数据。
> SELECT * FROM "h2o_feet" WHERE "water_level" > 8
name: h2o_feet
--------------
time level description location water_level
2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12
2015-08-18T00:06:00Z between 6 and 9 feet coyote_creek 8.005
[...]
2015-09-18T00:12:00Z between 6 and 9 feet coyote_creek 8.189
2015-09-18T00:18:00Z between 6 and 9 feet coyote_creek 8.084
该查询返回h2o_feet中的数据,这些数据满足条件:field key water_level的值大于8。
查询field value满足一定条件的数据(field value是字符串类型)
> SELECT * FROM "h2o_feet" WHERE "level description" = 'below 3 feet'
name: h2o_feet
--------------
time level description location water_level
2015-08-18T00:00:00Z below 3 feet santa_monica 2.064
2015-08-18T00:06:00Z below 3 feet santa_monica 2.116
[...]
2015-09-18T14:06:00Z below 3 feet santa_monica 2.999
2015-09-18T14:36:00Z below 3 feet santa_monica 2.907
该查询返回h2o_feet中的数据,这些数据满足条件:field key level description的值等于字符串below 3 feet。在WHERE子句中,需要用单引号将字符串类型的field value括起来。
查询field value满足一定条件的数据(WHERE子句包含基本运算)
> SELECT * FROM "h2o_feet" WHERE "water_level" + 2 > 11.9
name: h2o_feet
--------------
time level description location water_level
2015-08-29T07:06:00Z at or greater than 9 feet coyote_creek 9.902
2015-08-29T07:12:00Z at or greater than 9 feet coyote_creek 9.938
2015-08-29T07:18:00Z at or greater than 9 feet coyote_creek 9.957
2015-08-29T07:24:00Z at or greater than 9 feet coyote_creek 9.964
2015-08-29T07:30:00Z at or greater than 9 feet coyote_creek 9.954
2015-08-29T07:36:00Z at or greater than 9 feet coyote_creek 9.941
2015-08-29T07:42:00Z at or greater than 9 feet coyote_creek 9.925
2015-08-29T07:48:00Z at or greater than 9 feet coyote_creek 9.902
2015-09-02T23:30:00Z at or greater than 9 feet coyote_creek 9.902
该查询返回h2o_feet中的数据,这些数据满足条件:field key water_level的值加上2大于11.9。请注意,InfluxDB®遵循标准的算术运算顺序。可查看数学运算符章节了解更多相关信息。
查询tag value满足一定条件的数据
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica'
name: h2o_feet
--------------
time water_level
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
[...]
2015-09-18T21:36:00Z 5.066
2015-09-18T21:42:00Z 4.938
该查询返回h2o_feet中的数据,这些数据满足条件:tag key location的值是santa_monica。在WHERE子句中,需要用单引号将字符串类型的tag value括起来。
查询field value和tag value都满足一定条件的数据
> SELECT "water_level" FROM "h2o_feet" WHERE "location" <> 'santa_monica' AND ("water_level" < -0.59 OR "water_level" > 9.95)
name: h2o_feet
--------------
time water_level
2015-08-29T07:18:00Z 9.957
2015-08-29T07:24:00Z 9.964
2015-08-29T07:30:00Z 9.954
2015-08-29T14:30:00Z -0.61
2015-08-29T14:36:00Z -0.591
2015-08-30T15:18:00Z -0.594
该查询返回h2o_feet中的数据,这些数据满足条件:tag key location的值不等于santa_monica,并且,field key water_level的值小于-0.59或大于9.95。WHERE子句支持操作符AND和OR,并支持用括号将它们的逻辑分开。
查询timestamp满足一定条件的数据
> SELECT * FROM "h2o_feet" WHERE time > now() - 7d
该查询返回h2o_feet中的数据,这些数据满足条件:timestamp在过去7天内。本页面中的时间语法章节将详细介绍WHERE子句中支持的时间语法。
WHERE子句的常见问题
WHERE子句出现异常则没有结果返回
在大多数情况下,引起这个问题的原因是tag value或字符串类型的field value缺少单引号。如果tag value或字符串类型的field value没有使用引号或者使用了双引号,那么不会返回任何查询结果,在大多数情况下,也不会返回错误。
下面的代码块中,前两个查询分别尝试没有用引号或者尝试用双引号来指定tag value:santa_monica,这两个查询不会返回任何结果。第三个查询使用了单引号将santa_monica括起来(这是支持的语法),返回了预期的结果。
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = santa_monica
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = "santa_monica"
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica'
name: h2o_feet
--------------
time water_level
2015-08-18T00:00:00Z 2.064
[...]
2015-09-18T21:42:00Z 4.938
下面的代码块中,前两个查询分别尝试没有用引号或者尝试用双引号来指定字符串类型的field value:at or greater than 9 feet。第一个查询返回错误,因为该field value包含空格。第二个查询没有返回任何结果。第三个查询使用了单引号将at or greater than 9 feet括起来(这是支持的语法),返回了预期的结果。
> SELECT "level description" FROM "h2o_feet" WHERE "level description" = at or greater than 9 feet
ERR: error parsing query: found than, expected ; at line 1, char 86
> SELECT "level description" FROM "h2o_feet" WHERE "level description" = "at or greater than 9 feet"
> SELECT "level description" FROM "h2o_feet" WHERE "level description" = 'at or greater than 9 feet'
name: h2o_feet
--------------
time level description
2015-08-26T04:00:00Z at or greater than 9 feet
[...]
2015-09-15T22:42:00Z at or greater than 9 feet
2.3 GROUP BY子句
GROUP BY子句按用户指定的tag或者时间区间对查询结果进行分组
GROUP BY tags
GROUP BY 按用户指定的tag对查询结果进行分组。
SELECT_clause FROM_clause [WHERE_clause] GROUP BY [*|<tag_key>[,<tag_key]]
GROUP BY * 按所有tag对查询结果进行分组。
GROUP BY <tag_key>按指定的一个tag对查询结果进行分组。
GROUP BY <tag_key>,<tag_key>按多个tag对查询结果进行分组,tag key的顺序对结果无影响。
如果查询语句中包含一个WHERE子句,那么GROUP BY子句必须放在该WHERE子句后面。
除此之外,GROUP BY子句还支持的功能:正则表达式。
示例
按单个tag对查询结果进行分组
SELECT MEAN("water_level") FROM "h2o_feet" GROUP BY "location"
name: h2o_feet
tags: location=coyote_creek
time mean
--------
1970-01-01T00:00:00Z5.359342451341401
name: h2o_feet
tags: location=santa_monica
time mean
--------
1970-01-01T00:00:00Z3.530863470081006
该查询使用了InfluxQL中的一个函数计算measurement h2o_feet中每个location的water_level的平均值。 InfluxDB®返回两个序列的结果:每个location的值对应一个序列。
按多个tag对查询结果进行分组
SELECT MEAN("index") FROM "h2o_quality" GROUP BY location,randtag
name: h2o_quality
tags: location=coyote_creek, randtag=1
time mean
--------
1970-01-01T00:00:00Z50.69033760186263
name: h2o_quality
tags: location=coyote_creek, randtag=2
time mean
--------
1970-01-01T00:00:00Z49.661867544220485
name: h2o_quality
tags: location=coyote_creek, randtag=3
time mean
--------
1970-01-01T00:00:00Z49.360939907550076
name: h2o_quality
tags: location=santa_monica, randtag=1
time mean
--------
1970-01-01T00:00:00Z49.132712456344585
name: h2o_quality
tags: location=santa_monica, randtag=2
time mean
--------
1970-01-01T00:00:00Z50.2937984496124
name: h2o_quality
tags: location=santa_monica, randtag=3
time mean
--------
1970-01-01T00:00:00Z49.99919903884662
该查询使用了InfluxQL中的一个函数计算measurement h2o_quality中每个location和randtag的组合的index的平均值,其中,location有2个不同的值,randtag有3个不同的值,总共有6个不同的组合。在GROUP BY子句中,用逗号将多个tag隔开。
按所有tag对查询结果进行分组
SELECT MEAN("index") FROM "h2o_quality" GROUP BY *
name: h2o_quality
tags: location=coyote_creek, randtag=1
time mean
--------
1970-01-01T00:00:00Z50.69033760186263
name: h2o_quality
tags: location=coyote_creek, randtag=2
time mean
--------
1970-01-01T00:00:00Z49.661867544220485
name: h2o_quality
tags: location=coyote_creek, randtag=3
time mean
--------
1970-01-01T00:00:00Z49.360939907550076
name: h2o_quality
tags: location=santa_monica, randtag=1
time mean
--------
1970-01-01T00:00:00Z49.132712456344585
name: h2o_quality
tags: location=santa_monica, randtag=2
time mean
--------
1970-01-01T00:00:00Z50.2937984496124
name: h2o_quality
tags: location=santa_monica, randtag=3
time mean
--------
1970-01-01T00:00:00Z49.99919903884662
该查询使用了InfluxQL中的一个函数计算measurement h2o_quality中每个tag的组合的index的平均值。
说明 该查询的结果与上面例子中的查询结果相同,这是因为在h2o_quality中,只有两个tag key:location和randtag。
GROUP BY time intervals
GROUP BY time() 按用户指定的时间间隔对查询结果进行分组。
SELECT (<field_key>) FROM_clause WHERE <time_range> GROUP BY time(<time_interval>),[tag_key][fill(<fill_option>)]
基本的GROUP BY time()查询需要在SELECT子句中包含一个InfluxQL函数,并且在WHERE子句中包含时间范围。请注意,GROUP BY子句必须放在WHERE子句后面。
time(time_interval):子句中的time_interval(时间间隔)是一个持续时间(duration),决定了InfluxDB按多大的时间间隔将查询结果进行分组。例如,当time_interval为5m时,那么在WHERE子句中指定的时间范围内,将查询结果按5分钟进行分组。
fill(<fill_option>):可选,它会改变不含数据的时间间隔的返回值。
覆盖范围
基本的GROUP BY time()查询依赖time_interval和 InfluxDB 的预设时间边界来确定每个时间间隔内的原始数据和查询返回的时间戳。
基本语法示例
下面的示例将使用如下数据:
SELECT "water_level","location" FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z'
name: h2o_feet
--------------
time water_level location
2015-08-18T00:00:00Z8.12 coyote_creek
2015-08-18T00:00:00Z2.064 santa_monica
2015-08-18T00:06:00Z8.005 coyote_creek
2015-08-18T00:06:00Z2.116 santa_monica
2015-08-18T00:12:00Z7.887 coyote_creek
2015-08-18T00:12:00Z2.028 santa_monica
2015-08-18T00:18:00Z7.762 coyote_creek
2015-08-18T00:18:00Z2.126 santa_monica
2015-08-18T00:24:00Z7.635 coyote_creek
2015-08-18T00:24:00Z2.041 santa_monica
2015-08-18T00:30:00Z7.5 coyote_creek
2015-08-18T00:30:00Z2.051 santa_monica
将查询结果按12分钟的时间间隔进行分组
SELECT COUNT("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' GROUP BY time(12m)
name: h2o_feet
--------------
time count
2015-08-18T00:00:00Z2
2015-08-18T00:12:00Z2
2015-08-18T00:24:00Z2
该查询使用了InfluxQL中的一个函数计算measurement h2o_feet中location = coyote_creek的water_level的数据点数,并将结果按12分钟为间隔进行分组。
每个时间戳所对应的结果代表一个12分钟间隔所对应的结果。第一个时间戳的计数(count)涵盖了从2015-08-18T00:00:00Z到2015-08-18T00:12:00Z的原始数据(不包括2015-08-18T00:12:00Z)。第二个时间戳的计数涵盖了从2015-08-18T00:12:00Z到2015-08-18T00:24:00的原始数据(不包括2015-08-18T00:24:00)。
将查询结果按12分钟的时间间隔和一个tag key进行分组
SELECT COUNT("water_level") FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' GROUP BY time(12m),"location"
name: h2o_feet
tags: location=coyote_creek
time count
---------
2015-08-18T00:00:00Z2
2015-08-18T00:12:00Z2
2015-08-18T00:24:00Z2
name: h2o_feet
tags: location=santa_monica
time count
---------
2015-08-18T00:00:00Z2
2015-08-18T00:12:00Z2
2015-08-18T00:24:00Z2
该查询使用了InfluxQL中的一个函数计算water_level的数据点数,并将结果按tag location和12分钟间隔进行分组。请注意,在GROUP BY子句中,用逗号将时间间隔和tag key隔开。
该查询返回两个序列:每个location的值对应一个序列。每个时间戳所对应的结果代表一个12分钟间隔所对应的结果。第一个时间戳的计数(count)涵盖了从2015-08-18T00:00:00Z到2015-08-18T00:12:00Z的原始数据(不包括2015-08-18T00:12:00Z)。第二个时间戳的计数涵盖了从2015-08-18T00:12:00Z到2015-08-18T00:24:00的原始数据(不包括2015-08-18T00:24:00)。
基本语法的常见问题
查询结果中出现时间戳和值
使用基本语法,InfluxDB 依赖GROUP BY time()中的时间间隔和系统的预设时间边界来确定每个时间间隔内的原始数据和查询返回的时间戳。
示例
原始数据:
SELECT "water_level" FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:18:00Z'
name: h2o_feet
--------------
time water_level
2015-08-18T00:00:00Z8.12
2015-08-18T00:06:00Z8.005
2015-08-18T00:12:00Z7.887
2015-08-18T00:18:00Z7.762
查询和结果:
以下查询覆盖的时间范围是12分钟,并将结果按12分钟的间隔进行分组,但是它返回了两个结果:
SELECT COUNT("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-08-18T00:06:00Z' AND time <'2015-08-18T00:18:00Z' GROUP BY time(12m)
name: h2o_feet
time count
---------
2015-08-18T00:00:00Z1<-----Note that this timestamp occurs before the start of the query's time range
2015-08-18T00:12:00Z 1
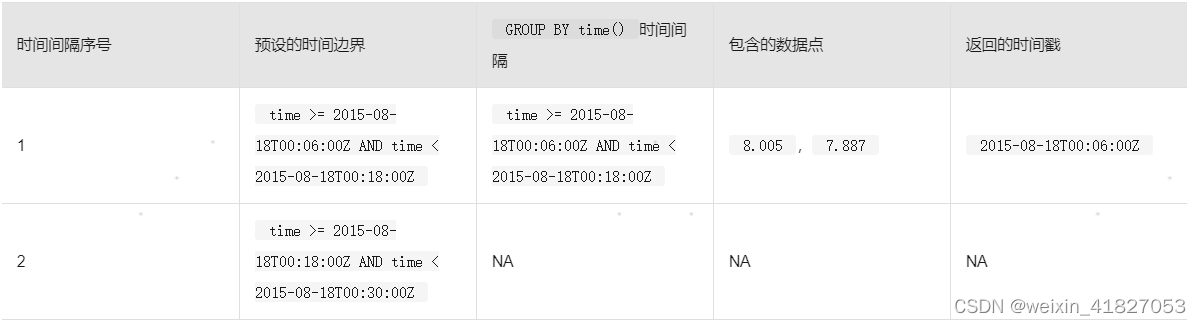
说明 InfluxDB®对GROUP BY的时间间隔使用预设的四舍五入时间边界,不依赖于WHERE子句中任何时间条件。在计算结果的时候,所有返回数据的时间戳必须在查询中明确规定的时间范围内,但是GROUP BY的时间间隔将会基于预设的时间边界。
下面的表格展示了结果中预设的时间边界、相关的GROUP BY time()时间间隔、包含的数据点以及每个GROUP BY time()间隔所对应的实际返回的时间戳。
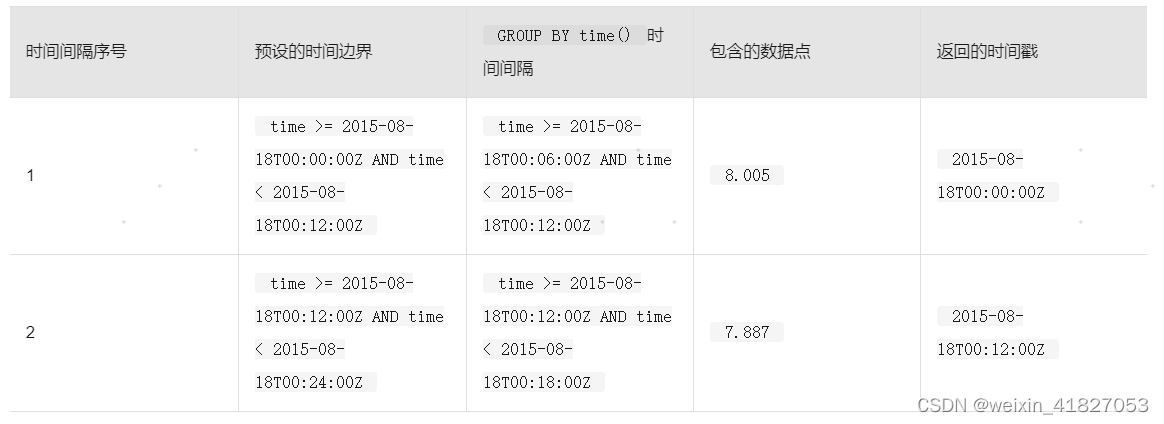
第一个预设的12分钟时间边界从00:00开始,刚好在12:00前结束。只有一个数据点(8.005),同时落在查询的第一个GROUP BY time()时间间隔和第一个时间边界内。请注意,虽然返回的时间戳发生在查询的时间范围开始之前,但是查询结果排除了在查询时间范围之前发生的数据。
第二个预设的12分钟时间边界从12:00开始,刚好在24:00前结束。只有一个数据点(7.887),同时落在查询的第二个GROUP BY time()时间间隔和第二个时间边界内。
高级GROUP BY time()语法允许用户修改 InfluxDB 的预设时间边界的开始时间。在高级语法章节中的示例将继续这里展示的查询,它将预设的时间边界向前偏移6分钟,以便 InfluxDB 返回:
name: h2o_feet
time count
---------
2015-08-18T00:06:00Z2
高级的GROUP BY time()语法
SELECT (<field_key>) FROM_clause WHERE <time_range> GROUP BY time(<time_interval>,<offset_interval>),[tag_key][fill(<fill_option>)]
高级语法描述
高级的GROUP BY time()查询需要在SELECT子句中包含一个InfluxQL函数,并且在WHERE子句中包含时间范围。请注意,GROUP BY子句必须放在WHERE子句后面。
-
time(time_interval,offset_interval):关于time_interval的详情,请查看基本的GROUP BY time()语法。
offset_interval(偏移间隔)是一个持续时间(duration),它将 InfluxDB 的预设时间边界向前或向后偏移。offset_interval可以是正数或者负数。 -
fill(<fill_option>):可选,它会改变不含数据的时间间隔的返回值。
覆盖范围:
高级的GROUP BY time()查询依赖time_interval、offset_interval和 InfluxDB 的预设时间边界来确定每个时间间隔内的原始数据和查询返回的时间戳。
高级语法示例
下面的示例将使用如下数据:
SELECT "water_level" FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:54:00Z'
name: h2o_feet
--------------
time water_level
2015-08-18T00:00:00Z8.12
2015-08-18T00:06:00Z8.005
2015-08-18T00:12:00Z7.887
2015-08-18T00:18:00Z7.762
2015-08-18T00:24:00Z7.635
2015-08-18T00:30:00Z7.5
2015-08-18T00:36:00Z7.372
2015-08-18T00:42:00Z7.234
2015-08-18T00:48:00Z7.11
2015-08-18T00:54:00Z6.982
将查询结果按18分钟的时间间隔进行分组并将预设时间边界向前偏移
SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-08-18T00:06:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(18m,6m)
name: h2o_feet
time mean
--------
2015-08-18T00:06:00Z7.884666666666667
2015-08-18T00:24:00Z7.502333333333333
2015-08-18T00:42:00Z7.108666666666667
该查询使用了InfluxQL中的一个函数计算water_level的平均值,将结果按18分钟的时间间隔进行分组,并将预设时间边界向前偏移6分钟。
对于没有offset_interval的查询,时间边界和返回的时间戳依旧沿用InfluxDB®预设的时间边界。我们先来看看没有offset_interval的查询结果
SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-08-18T00:06:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(18m)
name: h2o_feet
time mean
--------
2015-08-18T00:00:00Z7.946
2015-08-18T00:18:00Z7.6323333333333325
2015-08-18T00:36:00Z7.238666666666667
2015-08-18T00:54:00Z6.982
对于没有offset_interval的查询,时间边界和返回的时间戳依旧沿用 InfluxDB 预设的时间边界
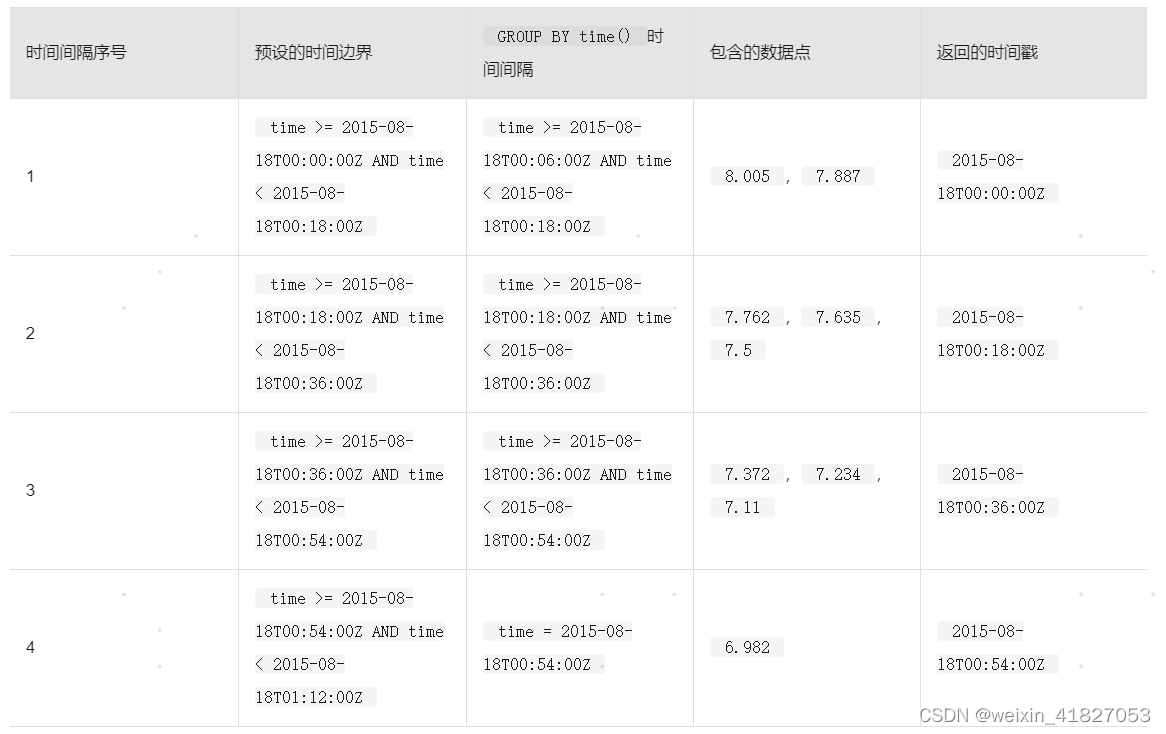
第一个预设的18分钟时间边界从00:00开始,刚好在18:00前结束。有两个数据点(8.005和7.887),同时落在查询的第一个GROUP BY time()时间间隔和第一个时间边界内。请注意,虽然返回的时间戳发生在查询的时间范围开始之前,但是查询结果排除了在查询时间范围之前发生的数据。
第二个预设的18分钟时间边界从18:00开始,刚好在36:00前结束。有三个数据点(7.762,7.635和7.5),同时落在查询的第二个GROUP BY time()时间间隔和第二个时间边界内。在这种情况下,边界时间范围和间隔时间范围是相同的。
第四个预设的18分钟时间边界从54:00开始,刚好在01:12:00前结束。只有一个数据点(6.982),同时落在查询的第四个GROUP BY time()时间间隔和第四个时间边界内。
对于有offset_interval的查询,时间边界和返回的时间戳符合指定的偏移时间边界:
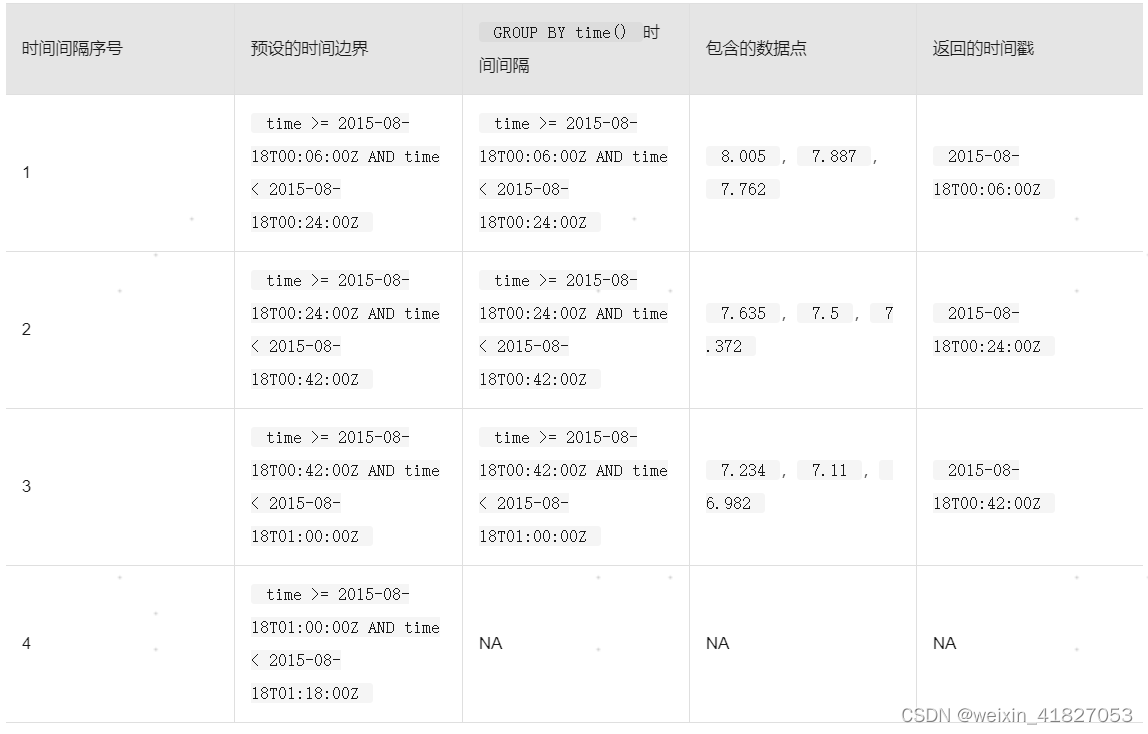
这个6分钟的偏移间隔将预设边界的时间范围向前偏移6分钟,使得边界的时间范围跟相关的GROUP BY time()间隔的时间范围始终相同。使用偏移间隔,每个时间间隔对三个数据点进行计算,并且返回的时间戳与边界时间范围的开始和GROUP BY time()时间范围的开始都相匹配。
请注意,offset_interval强制使第四个时间边界超过该查询的时间范围,因此,该查询不会返回最后一个时间间隔的数据。
将查询结果按18分钟的时间间隔进行分组并将预设时间边界向后偏移
SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-08-18T00:06:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(18m,-12m)
name: h2o_feet
time mean
--------
2015-08-18T00:06:00Z7.884666666666667
2015-08-18T00:24:00Z7.502333333333333
2015-08-18T00:42:00Z7.108666666666667
该查询使用了InfluxQL中的一个函数计算water_level的平均值,将结果按18分钟的时间间隔进行分组,并将预设时间边界向后偏移12分钟。
说明 该示例与前面第一个例子(将查询结果按18分钟的时间间隔进行分组并将预设时间边界向前偏移)的查询结果相同,但是,在该示例中,使用了一个负数的offset_interval,而在前面的示例中offset_interval是一个正数。这两个查询之间没有性能差异。在选择没有正负offset_interval时,请选择最直观的数值。
对于没有offset_interval的查询,时间边界和返回的时间戳依旧沿用 InfluxDB 预设的时间边界。没有offset_interval的查询结果:
SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-08-18T00:06:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(18m)
name: h2o_feet
time mean
--------
2015-08-18T00:00:00Z7.946
2015-08-18T00:18:00Z7.6323333333333325
2015-08-18T00:36:00Z7.238666666666667
2015-08-18T00:54:00Z6.982
对于没有offset_interval的查询,时间边界和返回的时间戳依旧沿用InfluxDB®预设的时间边界:
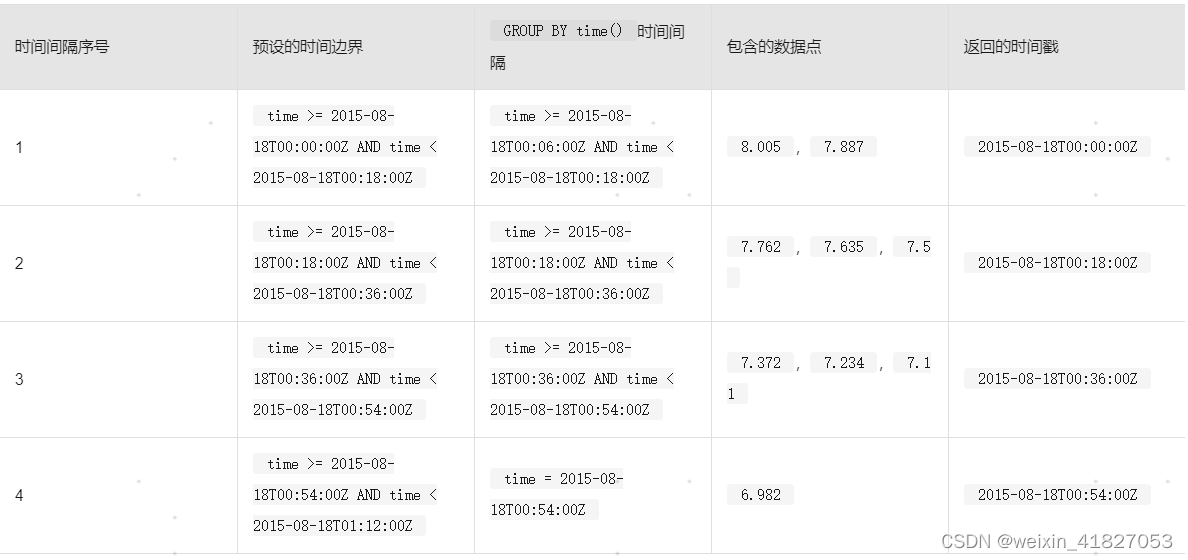
第一个预设的18分钟时间边界从00:00开始,刚好在18:00前结束。有两个数据点(8.005和7.887),同时落在查询的第一个GROUP BY time()时间间隔和第一个时间边界内。请注意,虽然返回的时间戳发生在查询的时间范围开始之前,但是查询结果排除了在查询时间范围之前发生的数据。
第二个预设的18分钟时间边界从18:00开始,刚好在36:00前结束。有三个数据点(7.762,7.635和7.5),同时落在查询的第二个GROUP BY time()时间间隔和第二个时间边界内。在这种情况下,边界时间范围和间隔时间范围是相同的。
第四个预设的18分钟时间边界从54:00开始,刚好在01:12:00前结束。只有一个数据点(6.982),同时落在查询的第四个GROUP BY time()时间间隔和第四个时间边界内。
对于有offset_interval的查询,时间边界和返回的时间戳符合指定的偏移时间边界:
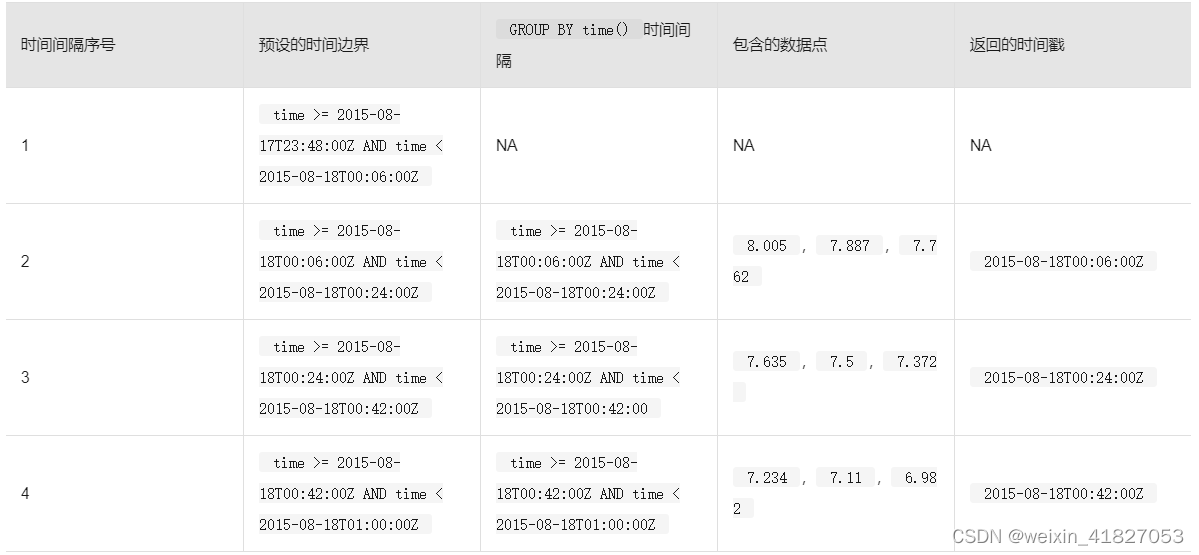
这个负12分钟的偏移间隔将预设边界的时间范围向后偏移12分钟,使得边界的时间范围跟相关的GROUP BY time()间隔的时间范围始终相同。使用偏移间隔,每个时间间隔对三个数据点进行计算,并且返回的时间戳与边界时间范围的开始和GROUP BY time()时间范围的开始都相匹配。
请注意,offset_interval强制使第一个时间边界超过该查询的时间范围,因此,该查询不会返回第一个时间间隔的数据。
将查询结果按12分钟的时间间隔进行分组并将预设时间边界向前偏移
这个例子是基本语法的常见问题章节中示例的延续。
SELECT COUNT("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-08-18T00:06:00Z' AND time <'2015-08-18T00:18:00Z' GROUP BY time(12m,6m)
name: h2o_feet
time count
---------
2015-08-18T00:06:00Z2
该查询使用了InfluxQL中的一个函数计算water_level的数据点数,将结果按12分钟的时间间隔进行分组,并将预设时间边界向前偏移6分钟。
对于没有offset_interval的查询,时间边界和返回的时间戳依旧沿用 InfluxDB 预设的时间边界。没有offset_interval的查询结果:
SELECT COUNT("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-08-18T00:06:00Z' AND time <'2015-08-18T00:18:00Z' GROUP BY time(12m)
name: h2o_feet
time count
---------
2015-08-18T00:00:00Z1
2015-08-18T00:12:00Z1
对于没有offset_interval的查询,时间边界和返回的时间戳依旧沿用 InfluxDB 预设的时间边界:
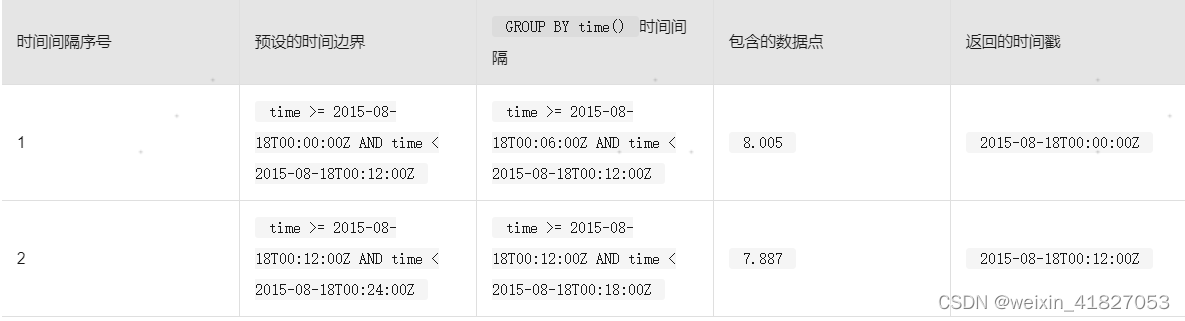
第一个预设的12分钟时间边界从00:00开始,刚好在12:00前结束。只有一个数据点(8.005),同时落在查询的第一个GROUP BY time()时间间隔和第一个时间边界内。请注意,虽然返回的时间戳发生在查询的时间范围开始之前,但是查询结果排除了在查询时间范围之前发生的数据。
第二个预设的12分钟时间边界从12:00开始,刚好在24:00前结束。只有一个数据点(7.887),同时落在查询的第二个GROUP BY time()时间间隔和第二个时间边界内。
对于有offset_interval的查询,时间边界和返回的时间戳符合指定的偏移时间边界:
这个6分钟的偏移间隔将预设边界的时间范围向前偏移6分钟,使得边界的时间范围跟相关的GROUP BY time()间隔的时间范围始终相同。使用偏移间隔,该查询返回一个结果,并且返回的时间戳与边界时间范围的开始和GROUP BY time()时间范围的开始都相匹配。
请注意,offset_interval强制使第二个时间边界超过该查询的时间范围,因此,该查询不会返回第二个时间间隔的数据。
GROUP BY time intervals和fill()
fill()(填充函数)改变不包含数据的时间间隔的返回值。
语法
SELECT (<field_key>) FROM_clause WHERE <time_range> GROUP BY time(time_interval,[<offset_interval])[,tag_key][fill(<fill_option>)]
语法描述
对于不包含数据的GROUP BY time()时间间隔,默认将null作为它在输出列中的返回值。如果想要改变不包含数据的时间间隔的返回值,可以使用fill()。请注意,如果您GROUP BY多个对象(例如,tag和时间间隔),那么fill()必须放在GROUP BY子句后面。
fill_option
- 任意数值:对于没有数据点的时间间隔,返回这个给定的数值。
- linear:对于没有数据点的时间间隔,返回线性插值的结果。
- none:对于没有数据点的时间间隔,不返回任何时间戳和值。
- null:对于没有数据点的时间间隔,返回时间戳,并且返回null作为该时间戳所对应的值,这跟默认的情况相同。
- previous:对于没有数据点的时间间隔,返回前一个时间间隔的值。
示例1:没有使用fill(100)
SELECT MAX("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-09-18T16:00:00Z' AND time <='2015-09-18T16:42:00Z' GROUP BY time(12m)
name: h2o_feet
--------------
time max
2015-09-18T16:00:00Z3.599
2015-09-18T16:12:00Z3.402
2015-09-18T16:24:00Z3.235
2015-09-18T16:36:00Z
示例2:使用fill(100)
SELECT MAX("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-09-18T16:00:00Z' AND time <='2015-09-18T16:42:00Z' GROUP BY time(12m) fill(100)
name: h2o_feet
--------------
ime max
2015-09-18T16:00:00Z3.599
2015-09-18T16:12:00Z3.402
2015-09-18T16:24:00Z3.235
2015-09-18T16:36:00Z100
fill(100)改变了没有数据点的时间间隔的值。第四个时间间隔本来没有数据显示,但是使用了fill(100)后,返回值变为了100。
示例3:没有使用fill(linear)
SELECT MEAN("tadpoles") FROM "pond" WHERE time >='2016-11-11T21:00:00Z' AND time <='2016-11-11T22:06:00Z' GROUP BY time(12m)
name: pond
time mean
--------
2016-11-11T21:00:00Z1
2016-11-11T21:12:00Z
2016-11-11T21:24:00Z3
2016-11-11T21:36:00Z
2016-11-11T21:48:00Z
2016-11-11T22:00:00Z6
示例4:使用fill(linear)
SELECT MEAN("tadpoles") FROM "pond" WHERE time >='2016-11-11T21:00:00Z' AND time <='2016-11-11T22:06:00Z' GROUP BY time(12m) fill(linear)
name: pond
time mean
--------
2016-11-11T21:00:00Z1
2016-11-11T21:12:00Z2
2016-11-11T21:24:00Z3
2016-11-11T21:36:00Z4
2016-11-11T21:48:00Z5
2016-11-11T22:00:00Z6
fill(linear)将没有数据点的时间间隔的返回值更改为线性插值的结果。
说明 示例二中的数据并不在数据库NOAA_water_database中。为了可以使用fill(linear),创建一个有更少常规数据的数据集。
示例5:没有使用fill(none)
SELECT MAX("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-09-18T16:00:00Z' AND time <='2015-09-18T16:42:00Z' GROUP BY time(12m)
name: h2o_feet
--------------
time max
2015-09-18T16:00:00Z3.599
2015-09-18T16:12:00Z3.402
2015-09-18T16:24:00Z3.235
2015-09-18T16:36:00Z
示例6:使用fill(none)
SELECT MAX("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-09-18T16:00:00Z' AND time <='2015-09-18T16:42:00Z' GROUP BY time(12m) fill(none)
name: h2o_feet
--------------
time max
2015-09-18T16:00:00Z3.599
2015-09-18T16:12:00Z3.402
2015-09-18T16:24:00Z3.235
fill(null)对于没有数据点的时间间隔,既不返回时间戳,也不返回值。
示例7:没有使用fill(null)
SELECT MAX("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-09-18T16:00:00Z' AND time <='2015-09-18T16:42:00Z' GROUP BY time(12m)
name: h2o_feet
--------------
time max
2015-09-18T16:00:00Z3.599
2015-09-18T16:12:00Z3.402
2015-09-18T16:24:00Z3.235
2015-09-18T16:36:00Z
示例8:使用fill(null)
SELECT MAX("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-09-18T16:00:00Z' AND time <='2015-09-18T16:42:00Z' GROUP BY time(12m) fill(null)
name: h2o_feet
--------------
time max
2015-09-18T16:00:00Z3.599
2015-09-18T16:12:00Z3.402
2015-09-18T16:24:00Z3.235
2015-09-18T16:36:00Z
fill(null)对于没有数据点的时间间隔,返回null作为它的值。使用fill(null)的查询结果跟没有使用fill(null)的结果一样。
示例9:没有使用fill(previous)
SELECT MAX("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-09-18T16:00:00Z' AND time <='2015-09-18T16:42:00Z' GROUP BY time(12m)
name: h2o_feet
--------------
time max
2015-09-18T16:00:00Z3.599
2015-09-18T16:12:00Z3.402
2015-09-18T16:24:00Z3.235
2015-09-18T16:36:00Z
示例10:使用fill(previous)
> SELECT MAX("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >='2015-09-18T16:00:00Z' AND time <='2015-09-18T16:42:00Z' GROUP BY time(12m) fill(previous)
name: h2o_feet
--------------
time max
2015-09-18T16:00:00Z3.599
2015-09-18T16:12:00Z3.402
2015-09-18T16:24:00Z3.235
2015-09-18T16:36:00Z3.235
fill(previous)将没有数据点的时间间隔的返回值更改为3.235,跟上一个时间间隔的返回值一样。
fill()的常见问题
在查询时间范围内没有数据的情况下使用fill()
目前,如果在查询的时间范围内没有数据,那么查询会忽略fill()。这是符合预期的结果。
示例:
以下查询不会返回任何数据,因为water_level在查询的时间范围内没有任何数据点。请注意,fill(800)对以下查询结果无影响。
SELECT MEAN(“water_level”) FROM “h2o_feet” WHERE “location”=‘coyote_creek’ AND time >=‘2015-09-18T22:00:00Z’ AND time <=‘2015-09-18T22:18:00Z’ GROUP BY time(12m) fill(800)
在前一个结果不在查询时间范围内的情况下使用fill(previous)
如果前一个时间间隔超出查询的时间范围,那么fill(previous)不会填充该时间间隔所对应的值。
示例:
以下查询覆盖的时间范围是从2015-09-18T16:24:00Z到2015-09-18T16:54:00Z。请注意,fill(previous)使用2015-09-18T16:24:00Z的结果来填充2015-09-18T16:36:00Z对应的值。
SELECT MAX("water_level") FROM "h2o_feet" WHERE location ='coyote_creek' AND time >='2015-09-18T16:24:00Z' AND time <='2015-09-18T16:54:00Z' GROUP BY time(12m) fill(previous)
name: h2o_feet
--------------
time max
2015-09-18T16:24:00Z3.235
2015-09-18T16:36:00Z3.235
2015-09-18T16:48:00Z4
下一个查询将缩短以上查询的时间范围,现在,查询覆盖的时间范围变为从2015-09-18T16:36:00Z到2015-09-18T16:54:00Z。请注意,fill(previous)不会使用2015-09-18T16:24:00Z的结果来填充2015-09-18T16:36:00Z对应的值,因为2015-09-18T16:24:00Z不在查询较短的时间范围内。
SELECT MAX("water_level") FROM "h2o_feet" WHERE location ='coyote_creek' AND time >='2015-09-18T16:36:00Z' AND time <='2015-09-18T16:54:00Z' GROUP BY time(12m) fill(previous)
name: h2o_feet
--------------
time max
2015-09-18T16:36:00Z
2015-09-18T16:48:00Z4
在前一个或后一个结果不在查询时间范围内的情况下使用fill(linear)
如果前一个或后一个时间间隔超出查询的时间范围,那么fill(linear)不会填充(fill)该时间间隔所对应的值。
示例:
以下查询覆盖的时间范围是从2016-11-11T21:24:00Z到2016-11-11T22:06:00Z。请注意,fill(linear)使用2016-11-11T21:24:00Z和2016-11-11T22:00:00Z这两个时间间隔的值来填充2016-11-11T21:36:00Z和2016-11-11T21:48:00Z分别所对应的值。
SELECT MEAN("tadpoles") FROM "pond" WHERE time >'2016-11-11T21:24:00Z' AND time <='2016-11-11T22:06:00Z' GROUP BY time(12m) fill(linear)
name: pond
time mean
--------
2016-11-11T21:24:00Z3
2016-11-11T21:36:00Z4
2016-11-11T21:48:00Z5
2016-11-11T22:00:00Z6
下一个查询将缩短以上查询的时间范围,现在,查询覆盖的时间范围变为从2016-11-11T21:36:00Z到2016-11-11T22:06:00Z。请注意,fill(linear)不会填充2016-11-11T21:36:00Z和2016-11-11T21:48:00Z所对应的值,因为2016-11-11T21:24:00Z不在查询较短的时间范围内,InfluxDB 无法进行线性插值计算。
SELECT MEAN("tadpoles") FROM "pond" WHERE time >='2016-11-11T21:36:00Z' AND time <='2016-11-11T22:06:00Z' GROUP BY time(12m) fill(linear)
name: pond
time mean
--------
2016-11-11T21:36:00Z
2016-11-11T21:48:00Z
2016-11-11T22:00:00Z6
说明 以上示例数据并不在数据库NOAA_water_database中。为了可以使用fill(linear),创建一个有更少常规数据的数据集。
2.4 INTO子句
INTO子句将查询结果写入到用户指定的measurement中。
语法
SELECT_clause INTO <measurement_name> FROM_clause [WHERE_clause] [GROUP_BY_clause]
语法描述
INTO子句支持多种指定measurement的格式:
- INTO <measurement_name>将数据写入到一个指定的measurement。如果您使用CLI写入数据,那么写入数据的measurement属于”USE”指定的数据库,并且使用的是默认(DEFAULT)的保留策略。如果您使用的是HTTP API,那么写入数据的measurement属于参数db指定的数据库,同样,使用的是默认(DEFAULT)的保留策略。
- INTO <database_name>.<retention_policy_name>.<measurement_name>将数据写入到一个完全限定的measurement。通过明确指定measurement的数据库和保留策略来完全限定一个measurement。
- INTO <database_name>…<measurement_name>将数据写入到一个measurement,这个measurement属于一个用户指定的数据库并使用默认保留策略。
- INTO <database_name>.<retention_policy_name>.:MEASUREMENT FROM /<regular_expression>/将数据写入到与FROM子句中正则表达式相匹配的所有在用户指定的数据库和保留策略中的measurement。:MEASUREMENT是FROM子句中每个匹配的measurement的反向引用(backreference)。
示例
重命名数据库
SELECT * INTO "copy_NOAA_water_database"."autogen".:MEASUREMENT FROM "NOAA_water_database"."autogen"./.*/ GROUP BY *
name: result
time written
---- -------
0 76290
在InfluxDB®中不能直接重命名数据库,所以INTO子句的一个常见用例是将数据从一个数据库移动到另外一个数据库。以上查询将数据库NOAA_water_database的保留策略autogen中的所有数据写入到数据库copy_NOAA_water_database的保留策略autogen中。
反向引用语法(:MEASUREMENT)将源数据库中measurement的名字维持在目标数据库中不变。请注意,在执行INTO查询之前,数据库NOAA_water_database及其保留策略autogen都必须已经存在。有关如何管理数据库和保留策略,请查看数据库管理章节。
GROUP BY *子句将源数据库中的tag保留在目标数据库中。以下查询并不为tag维护序列的上下文,tag将作为field保存在目标数据库(copy_NOAA_water_database)中:
SELECT * INTO “copy_NOAA_water_database”.“autogen”.:MEASUREMENT FROM “NOAA_water_database”.“autogen”./.*/
当移动大量数据时,我们建议按顺序对不同的measurement运行INTO查询,并且使用WHERE子句中的时间边界。这样可以防止系统内存不足。下面的代码块提供了这类查询的示例语法:
SELECT *
INTO <destination_database>.<retention_policy_name>.<measurement_name>
FROM <source_database>.<retention_policy_name>.<measurement_name>
WHERE time > now() - 100w and time < now() - 90w GROUP BY *
SELECT *
INTO <destination_database>.<retention_policy_name>.<measurement_name>
FROM <source_database>.<retention_policy_name>.<measurement_name>}
WHERE time > now() - 90w and time < now() - 80w GROUP BY *
SELECT *
INTO <destination_database>.<retention_policy_name>.<measurement_name>
FROM <source_database>.<retention_policy_name>.<measurement_name>
WHERE time > now() - 80w and time < now() - 70w GROUP BY *
将查询结果写入measurement
SELECT "water_level" INTO "h2o_feet_copy_1" FROM "h2o_feet" WHERE "location" = 'coyote_creek'
name: result
------------
time written
1970-01-01T00:00:00Z 7604
SELECT * FROM "h2o_feet_copy_1"
name: h2o_feet_copy_1
---------------------
time water_level
2015-08-18T00:00:00Z 8.12
[...]
2015-09-18T16:48:00Z 4
该查询将它的结果写入到一个新的measurement:h2o_feet_copy_1。如果您使用CLI写入数据,那么数据会写入到USE指定的数据库,并且使用的是默认(DEFAULT)的保留策略。如果您使用的是HTTP API,那么数据会写入到参数db指定的数据库,并且使用参数rp指定的保留策略。如果没有设置参数rp,HTTP API自动将数据写入到数据库的默认保留策略中。
返回结果显示InfluxDB®写入到h2o_feet_copy_1中的数据点个数(7604)。返回结果中的时间戳是没有意义的, InfluxDB 使用epoch 0(即1970-01-01T00:00:00Z)作为空时间戳。
将查询结果写入完全限定的measurement
SELECT "water_level" INTO "where_else"."autogen"."h2o_feet_copy_2" FROM "h2o_feet" WHERE "location" = 'coyote_creek'
name: result
------------
time written
1970-01-01T00:00:00Z 7604
SELECT * FROM "where_else"."autogen"."h2o_feet_copy_2"
name: h2o_feet_copy_2
---------------------
time water_level
2015-08-18T00:00:00Z 8.12
[...]
2015-09-18T16:48:00Z 4
该查询将它的结果写入到一个新的measurement:h2o_feet_copy_2。InfluxDB®将数据写入到数据库where_else的保留策略autogen中。请注意,在执行INTO查询前,数据库where_else及其保留策略autogen都必须已经存在。有关如何管理数据库和保留策略,请查看数据库管理章节。
返回结果显示InfluxDB®写入到h2o_feet_copy_2中的数据点个数(7604)。返回结果中的时间戳是没有意义的,InfluxDB®使用epoch 0(即1970-01-01T00:00:00Z)作为空时间戳。
将聚合结果写入measurement(降采样)
SELECT MEAN("water_level") INTO "all_my_averages" FROM "h2o_feet" WHERE "location" = 'coyote_creek' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m)
name: result
------------
time written
1970-01-01T00:00:00Z 3
SELECT * FROM "all_my_averages"
name: all_my_averages
---------------------
time mean
2015-08-18T00:00:00Z 8.0625
2015-08-18T00:12:00Z 7.8245
2015-08-18T00:24:00Z 7.5675
该查询使用了一个InfluxQL函数和一个GROUP BY time()子句将数据进行聚合,并且将结果写入到measurement all_my_averages。
返回结果显示 InfluxDB 写入到all_my_averages中的数据点个数(3)。返回结果中的时间戳是没有意义的,InfluxDB 使用epoch 0(即1970-01-01T00:00:00Z)作为空时间戳。
该查询是降采样(downsampling)的一个示例:获取更高精度的数据并将这些数据聚合到较低精度,然后将较低精度的数据存储到数据库。降采样是INTO子句的一个常见用例。
数据写入
将多个measurement的聚合结果写入一个不同的数据库(使用反向引用进行降采样)。
SELECT MEAN(*) INTO "where_else"."autogen".:MEASUREMENT FROM /.*/ WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:06:00Z' GROUP BY time(12m)
name: result
time written
---- -------
1970-01-01T00:00:00Z 5
SELECT * FROM "where_else"."autogen"./.*/
name: average_temperature
time mean_degrees mean_index mean_pH mean_water_level
---- ------------ ---------- ------- ----------------
2015-08-18T00:00:00Z 78.5
name: h2o_feet
time mean_degrees mean_index mean_pH mean_water_level
---- ------------ ---------- ------- ----------------
2015-08-18T00:00:00Z 5.07625
name: h2o_pH
time mean_degrees mean_index mean_pH mean_water_level
---- ------------ ---------- ------- ----------------
2015-08-18T00:00:00Z 6.75
name: h2o_quality
time mean_degrees mean_index mean_pH mean_water_level
---- ------------ ---------- ------- ----------------
2015-08-18T00:00:00Z 51.75
name: h2o_temperature
time mean_degrees mean_index mean_pH mean_water_level
---- ------------ ---------- ------- ----------------
2015-08-18T00:00:00Z 63.75
该查询使用了一个InfluxQL函数和一个GROUP BY time()子句将数据进行聚合,它将与FROM子句中正则表达式匹配的所有measurement中的数据进行聚合,并将结果写入到数据库where_else和查询策略autogen中有相同名字的measurement。请注意,在执行INTO查询前,数据库where_else及其保留策略autogen都必须已经存在。
返回结果显示InfluxDB®写入到数据库where_else和查询策略autogen中的数据点个数(5)。返回结果中的时间戳是没有意义的,InfluxDB®使用epoch 0(即1970-01-01T00:00:00Z)作为空时间戳。
该查询是使用反向引用进行降采样(downsampling with backreferencing)的一个示例:从多个measurement中获取更高精度的数据并将这些数据聚合到较低精度,然后将较低精度的数据存储到数据库。使用反向引用进行降采样是INTO子句的一个常见用例。
INTO子句的常见问题
数据丢失
如果一个INTO查询在SELECT子句中包含tag key,那么查询将当前measurement中的tag转换为目标measurement的field,这可能会导致 InfluxDB 覆盖以前由tag value区分的数据点。请注意,此行为不适用于使用TOP()或BOTTOM()函数的查询。
为了将当前measurement中的tag保留为目标measurement中的tag,可以在INTO查询中加上GROUP BY子句:GROUP BY相关的tag key或者GROUP BY *。
使用INTO子句自动查询
本文档中的INTO子句章节展示了如何使用INTO子句手动实现查询。通过连续查询(CQ),可以使INTO子句自动查询实时数据。连续查询其中一个用途就是使降采样的过程自动化。
2.5 ORDER BY time DESC
InfluxDB默认按递增的时间顺序返回结果。第一个返回的数据点,其时间戳是最早的,而最后一个返回的数据点,其时间戳是最新的。ORDER BY time DESC将默认的时间顺序调转,使得InfluxDB首先返回有最新时间戳的数据点,也就是说,按递减的时间顺序返回结果。
语法
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] ORDER BY time DESC
语法描述
如果查询语句中包含GROUP BY子句,那么ORDER BY time DESC必须放在GROUP BY子句后面。如果查询语句中包含WHERE子句并且没有GROUP BY子句,那么ORDER BY time DESC必须放在WHERE子句后面。
示例
首先返回最新的点
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' ORDER BY time DESC
name: h2o_feet
time water_level
---- -----------
2015-09-18T21:42:00Z 4.938
2015-09-18T21:36:00Z 5.066
[...]
2015-08-18T00:06:00Z 2.116
2015-08-18T00:00:00Z 2.064
该查询首先从measurement h2o_feet中返回具有最新时间戳的数据点。如果以上查询语句中没有ORDER by time DESC,那么会首先返回时间戳为2015-08-18T00:00:00Z的数据点,最后返回时间戳为2015-09-18T21:42:00Z的数据点。
首先返回最新的点并且包含GROUP BY time()子句
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:42:00Z' GROUP BY time(12m) ORDER BY time DESC
name: h2o_feet
time mean
---- ----
2015-08-18T00:36:00Z 4.6825
2015-08-18T00:24:00Z 4.80675
2015-08-18T00:12:00Z 4.950749999999999
2015-08-18T00:00:00Z 5.07625
该查询使用了一个InfluxQL函数和GROUP BY子句中的时间间隔,计算查询时间范围内每12分钟的water_level的平均值。ORDER BY time DESC语句使得最新12分钟间隔的结果会首先返回。如果以上查询语句中没有ORDER by time DESC,那么会首先返回时间戳为2015-08-18T00:00:00Z的数据点,最后返回时间戳为2015-08-18T00:36:00Z的数据点。
2.6 LIMIT及SLIMIT子句
LIMIT和SLIMIT分别限制每个查询返回的数据点个数和序列个数。
LIMIT子句
LIMIT 返回指定measurement中的前N个数据点。
语法
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] LIMIT
语法描述
N表示从指定measurement中返回的数据点个数。如果N大于measurement中所有数据点的个数,InfluxDB将返回该measurement中的所有数据点。请注意,LIMIT子句必须按照上述语法中的顺序使用。
示例
限制返回的数据点个数
> SELECT "water_level","location" FROM "h2o_feet" LIMIT 3
name: h2o_feet
time water_level location
---- ----------- --------
2015-08-18T00:00:00Z 8.12 coyote_creek
2015-08-18T00:00:00Z 2.064 santa_monica
2015-08-18T00:06:00Z 8.005 coyote_creek
该查询从measurement h2o_feet中返回三个最早的数据点(由时间戳决定)。
限制返回的数据点个数并且包含GROUP BY子句
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:42:00Z' GROUP BY *,time(12m) LIMIT 2
name: h2o_feet
tags: location=coyote_creek
time mean
---- ----
2015-08-18T00:00:00Z 8.0625
2015-08-18T00:12:00Z 7.8245
name: h2o_feet
tags: location=santa_monica
time mean
---- ----
2015-08-18T00:00:00Z 2.09
2015-08-18T00:12:00Z 2.077
该查询使用了一个InfluxQL函数和一个GROUP BY子句,计算每个tag以及查询时间范围内每12分钟的water_level的平均值。LIMIT 2表示该查询请求的是两个最早的12分钟间隔的平均值(由时间戳决定)。
请注意,如果以上查询语句中没有使用LIMIT 2,那么每个序列会返回四个数据点:在查询的时间范围内每隔十二分钟有一个数据点。
SLIMIT子句
SLIMIT 返回指定measurement的前N个序列中的每一个数据点。
语法
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] GROUP BY *[,time(<time_interval>)] [ORDER_BY_clause] SLIMIT
语法描述
N表示从指定measurement中返回的序列个数。如果N大于measurement中所有序列的个数,InfluxDB将返回该measurement中的所有序列。请注意,SLIMIT子句必须按照上述语法中的顺序使用。
示例
限制返回的序列个数
> SELECT "water_level" FROM "h2o_feet" GROUP BY * SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time water_level
---- -----
2015-08-18T00:00:00Z 8.12
2015-08-18T00:06:00Z 8.005
2015-08-18T00:12:00Z 7.887
[...]
2015-09-18T16:12:00Z 3.402
2015-09-18T16:18:00Z 3.314
2015-09-18T16:24:00Z 3.235
该查询从measurement h2o_feet的一个序列中返回所有water_level数据点。
限制返回的序列个数并且包含GROUP BY time()子句
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:42:00Z' GROUP BY *,time(12m) SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time mean
---- ----
2015-08-18T00:00:00Z 8.0625
2015-08-18T00:12:00Z 7.8245
2015-08-18T00:24:00Z 7.5675
2015-08-18T00:36:00Z 7.303
该查询使用了一个InfluxQL函数和GROUP BY子句中的时间间隔,计算查询时间范围内每12分钟的water_level的平均值。SLIMIT 1表示该查询请求的是measurement h2o_feet中的一个序列。
请注意,如果以上查询语句中没有使用SLIMIT 1,那么查询将返回measurement h2o_feet中的两个序列:location=coyote_creek和location=santa_monica。
LIMIT和SLIMIT
将SLIMIT 放在LIMIT 的后面,则返回指定measurement的N个序列中的前N个数据点。
语法
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] GROUP BY *[,time(<time_interval>)] [ORDER_BY_clause] LIMIT SLIMIT
语法描述
-
N1表示从measurement中返回的数据点个数。如果N1大于measurement中所有数据点的个数,InfluxDB®将返回该measurement中的所有数据点。
-
N2表示从指定measurement中返回的序列个数。如果N2大于measurement中所有序列的个数,InfluxDB®将返回该measurement中的所有序列。
请注意,LIMIT和SLIMIT子句必须按照上述语法中的顺序使用。
示例
限制返回的数据点个数和序列个数
> SELECT "water_level" FROM "h2o_feet" GROUP BY * LIMIT 3 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time water_level
---- -----------
2015-08-18T00:00:00Z 8.12
2015-08-18T00:06:00Z 8.005
2015-08-18T00:12:00Z 7.887
该查询从measurement h2o_feet的一个序列中返回三个最早的数据点。
限制返回的数据点个数和序列个数,并且包含GROUP BY time()子句
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:42:00Z' GROUP BY *,time(12m) LIMIT 2 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time mean
---- ----
2015-08-18T00:00:00Z 8.0625
2015-08-18T00:12:00Z 7.8245
该查询使用了一个InfluxQL函数和GROUP BY子句中的时间间隔,计算查询时间范围内每12分钟的water_level的平均值。LIMIT 2请求两个最早的12分钟间隔的平均值(由时间戳决定),SLIMIT 1请求measurement h2o_feet中的一个序列。
注意:如果以上查询语句中没有使用LIMIT 2 SLIMIT 1,那么查询将返回measurement h2o_feet中的两个序列,并且,每个序列返回四个数据点。
2.7 OFFSET及SOFFSET语句
OFFSET和SOFFSET分别标记数据点和序列返回的位置。
OFFSET子句
OFFSET 表示从查询结果中的第N个数据点开始返回。
语法
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] LIMIT_clause OFFSET [SLIMIT_clause]
语法描述
N表示从第N个数据点开始返回。使用OFFSET子句需要先使用LIMIT子句,在没有LIMIT子句的情况下使用OFFSET子句,可能会导致出现不一致的查询结果。
注释:如果WHERE子句包含时间范围,InfluxDB将不会返回任何结果,OFFSET子句可能会导致InfluxDB返回时间戳不在该时间范围内的数据点。
示例
标记数据点返回的位置
> SELECT "water_level","location" FROM "h2o_feet" LIMIT 3 OFFSET 3
name: h2o_feet
time water_level location
---- ----------- --------
2015-08-18T00:06:00Z 2.116 santa_monica
2015-08-18T00:12:00Z 7.887 coyote_creek
2015-08-18T00:12:00Z 2.028 santa_monica
该查询从measurement h2o_feet中返回第四、第五和第六个数据点。如果以上查询语句中没有使用OFFSET 3,那么查询将返回该measurement的第一、第二和第三个数据点。
标记数据点返回的位置并且包含多个子句
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:42:00Z' GROUP BY *,time(12m) ORDER BY time DESC LIMIT 2 OFFSET 2 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time mean
---- ----
2015-08-18T00:12:00Z 7.8245
2015-08-18T00:00:00Z 8.0625
这个例子非常复杂,所以我们逐个子句来分析:
- SELECT子句指定了一个InfluxQL函数;
- FROM子句指定了measurement;
- WHERE子句指定了查询的时间范围;
- GROUP BY子句将查询结果按所有tag(*)和12分钟的时间间隔进行分组;
- ORDER BY time DESC子句按递减的时间顺序返回结果;
- LIMIT 2子句将返回的数据点个数限制为2;
- OFFSET 2子句使查询结果的前两个平均值不返回;
- SLIMIT 1子句将返回的序列个数限制为1。
如果以上查询语句中没有使用OFFSET 2,那么查询将返回结果中的前两个平均值:
name: h2o_feet
tags: location=coyote_creek
time mean
---- ----
2015-08-18T00:36:00Z 7.303
2015-08-18T00:24:00Z 7.5675
SOFFSET子句
SOFFSET 表示从查询结果中的第N个序列开始返回。
语法
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] GROUP BY *[,time(time_interval)] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] SLIMIT_clause SOFFSET
语法描述
N表示从第N个序列开始返回。使用SOFFSET子句需要先使用SLIMIT子句,在没有SLIMIT子句的情况下使用SOFFSET子句,可能会导致出现不一致的查询结果。
注释:如果N大于序列的个数,InfluxDB将不会返回任何结果。
示例
标记序列返回的位置
> SELECT "water_level" FROM "h2o_feet" GROUP BY * SLIMIT 1 SOFFSET 1
name: h2o_feet
tags: location=santa_monica
time water_level
---- -----------
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
[...]
2015-09-18T21:36:00Z 5.066
2015-09-18T21:42:00Z 4.938
该查询返回measurement为h2o_feet、tag为location = santa_monica的序列中的数据。如果以上查询语句中没有使用SOFFSET 1,那么查询将返回measurement为h2o_feet、tag为location = coyote_creek的序列中的数据。
标记序列返回的位置并且包含多个子句
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:42:00Z' GROUP BY *,time(12m) ORDER BY time DESC LIMIT 2 OFFSET 2 SLIMIT 1 SOFFSET 1
name: h2o_feet
tags: location=santa_monica
time mean
---- ----
2015-08-18T00:12:00Z 2.077
2015-08-18T00:00:00Z 2.09
这个例子非常复杂,所以我们逐个子句来分析:
SELECT子句指定了一个InfluxQL函数;
- FROM子句指定了measurement;
- WHERE子句指定了查询的时间范围;
- GROUP BY子句将查询结果按所有tag(*)和12分钟的时间间隔进行分组;
- ORDER BY time DESC子句按递减的时间顺序返回结果;
- LIMIT 2子句将返回的数据点个数限制为2;
- OFFSET 2子句使查询结果的前两个平均值不返回;
- SLIMIT 1子句将返回的序列个数限制为1;
- SOFFSET 1子句使查询结果中第一个序列的数据不返回。
如果以上查询语句中没有使用SOFFSET 1,那么查询将返回另外一个序列的结果:
name: h2o_feet
tags: location=coyote_creek
time mean
---- ----
2015-08-18T00:12:00Z 7.8245
2015-08-18T00:00:00Z 8.0625
2.8 时区子句
tz()子句返回指定时区的UTC偏移量。
语法
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause] tz(‘<time_zone>’)
语法描述
nfluxDB默认以UTC格式存储和返回时间戳。tz()子句包含UTC偏移量,或者UTC夏令时(Daylight Savings Time,简称DST)偏移量(如果适用的话),在查询返回的时间戳中。返回的时间戳必须是RFC3339格式才能显示UTC偏移量或者UTC夏令时偏移量。参数time_zone遵循Internet Assigned Numbers Authority time zone database(互联网号码分配局时区数据库)的TZ语法,需要用单引号将它括起来。
示例
返回芝加哥时区的UTC偏移量
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:18:00Z' tz('America/Chicago')
name: h2o_feet
time water_level
---- -----------
2015-08-17T19:00:00-05:00 2.064
2015-08-17T19:06:00-05:00 2.116
2015-08-17T19:12:00-05:00 2.028
2015-08-17T19:18:00-05:00 2.126
该查询结果中,时间戳包含了美国/芝加哥(America/Chicago)的时区的UTC偏移量(-05:00)。
2.9 时间语法
对于大多数SELECT语句,默认的时间范围是从1677-09-21 00:12:43.145224194 UTC到2262-04-11T23:47:16.854775806Z UTC。对于包含GROUP BY time()子句的SELECT语句,默认的时间范围是从1677-09-21 00:12:43.145224194 UTC到now()。以下章节将详细介绍如何在SELECT语句的WHERE子句中指定其它的时间范围。
绝对时间
使用日期-时间字符串(date-time string)和epoch时间来指定绝对时间。
语法
SELECT_clause FROM_clause WHERE time [‘<rfc3339_date_time_string>’ | ‘<rfc3339_like_date_time_string>’ | <epoch_time>] [AND [‘<rfc3339_date_time_string>’ | ‘<rfc3339_like_date_time_string>’ | <epoch_time>] […]]
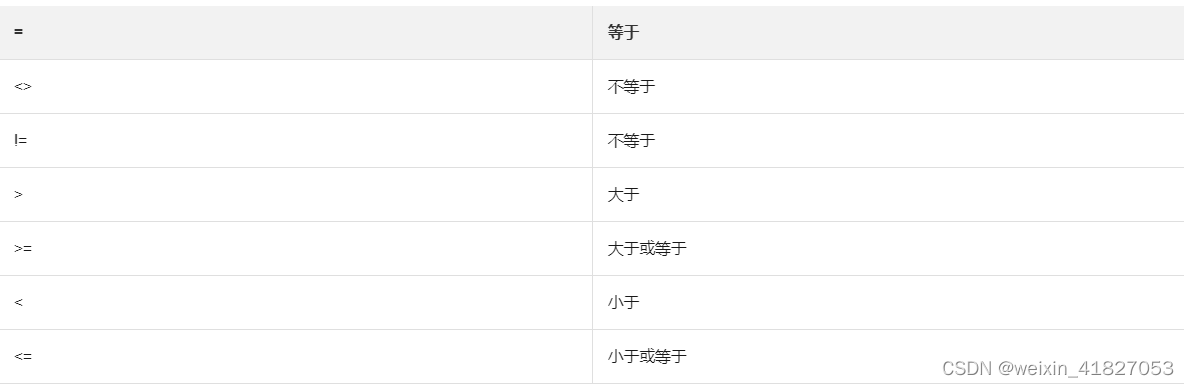
语法描述
支持的操作符如下表所示。
目前,InfluxDB 不支持在WHERE子句中的绝对时间使用OR。
rfc3339_date_time_string
YYYY-MM-DDTHH:MM:SS.nnnnnnnnnZ
.nnnnnnnnn是可选的,如果没有指定的话,默认设为.000000000。RFC3339格式的日期-时间字符串(RFC3339 date-time string)需要用单引号括起来。
rfc3339_like_date_time_string
YYYY-MM-DD HH:MM:SS.nnnnnnnnn
HH:MM:SS.nnnnnnnnn.nnnnnnnnn是可选的,如果没有指定的话,默认设为00:00:00.000000000。类似RFC3339格式的日期-时间字符串(RFC3339-like date-time string)需要用单引号括起来。
epoch_time
epoch时间是自1970年1月1日星期四00:00:00(UTC)以来所经过的时间。在默认情况下,InfluxDB假设所有epoch格式的时间戳都是以纳秒为单位。通过在epoch格式的时间戳末尾加上一个表示时间精度的字符,可以表示除纳秒外的时间精度。
基本运算
所有时间戳格式支持基本的算术运算。可以将带有时间精度的时间戳加上(+)或者减去(-)一个时间。请注意,InfluxQL需要用一个空格将+或-和时间戳隔开。
示例
用RFC3339格式的日期-时间字符串指定一个时间范围
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00.000000000Z' AND time <= '2015-08-18T00:12:00Z'
name: h2o_feet
time water_level
---- -----------
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
2015-08-18T00:12:00Z 2.028
该查询返回时间戳在2015年8月18日00:00:00.000000000和2015年8月18日00:12:00之间的数据。第一个时间戳的纳米精度(.000000000)是可选的。
请注意,RFC3339格式的日期-时间字符串需要用单引号括起来。
用类似RFC3339格式的日期-时间字符串指定一个时间范围
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18' AND time <= '2015-08-18 00:12:00'
name: h2o_feet
time water_level
---- -----------
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
2015-08-18T00:12:00Z 2.028
该查询返回时间戳在2015年8月18日00:00:00和2015年8月18日00:12:00之间的数据。第一个日期-时间字符串没有包含时间, InfluxDB会假设时间是00:00:00。
请注意,类似RFC3339格式的日期-时间字符串需要用单引号括起来。
用epoch格式的时间戳指定一个时间范围
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= 1439856000000000000 AND time <= 1439856720000000000
name: h2o_feet
time water_level
---- -----------
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
2015-08-18T00:12:00Z 2.028
该查询返回时间戳在2015年8月18日00:00:00和2015年8月18日00:12:00之间的数据。在默认情况下,InfluxDB假设epoch格式的时间戳以纳秒为单位。
用其它时间精度的epoch格式的时间戳指定一个时间范围
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= 1439856000s AND time <= 1439856720s
name: h2o_feet
time water_level
---- -----------
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 2.116
2015-08-18T00:12:00Z 2.028
该查询返回时间戳在2015年8月18日00:00:00和2015年8月18日00:12:00之间的数据。时间戳末尾的s表示该时间戳以秒为单位。
对类似RFC3339格式的日期-时间字符串进行基本运算
> SELECT "water_level" FROM "h2o_feet" WHERE time > '2015-09-18T21:24:00Z' + 6m
name: h2o_feet
time water_level
---- -----------
2015-09-18T21:36:00Z 5.066
2015-09-18T21:42:00Z 4.938
该查询返回时间戳在2015年8月18日21:24:00后6分钟之后的数据,即在2015年8月18日21:30:00之后的数据。请注意,需要用空格分别将时间戳和+、+和6m隔开。
对epoch格式的时间戳进行基本运算
> SELECT "water_level" FROM "h2o_feet" WHERE time > 24043524m - 6m
name: h2o_feet
time water_level
---- -----------
2015-09-18T21:24:00Z 5.013
2015-09-18T21:30:00Z 5.01
2015-09-18T21:36:00Z 5.066
2015-09-18T21:42:00Z 4.938
该查询返回时间戳在2015年8月18日21:24:00前6分钟之后的数据,即在2015年8月18日21:18:00之后的数据。请注意,需要用空格分别将时间戳和-、-和6m隔开。
相对时间
使用now()查询时间戳相对于服务器本地时间戳的数据。
语法
SELECT_clause FROM_clause WHERE time now() [[ - | + ] <duration_literal>] [(AND|OR) now() […]]
语法描述
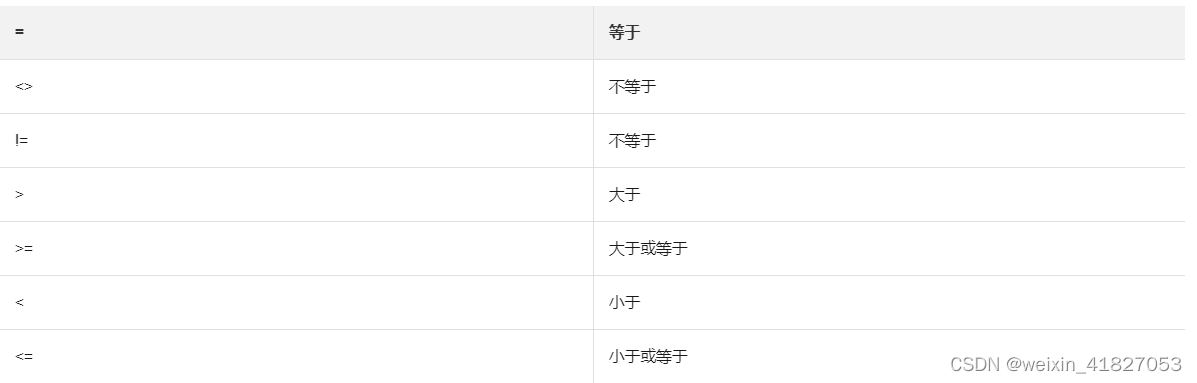
now()是在服务器上执行查询时该服务器的Unix时间。-或+和duration_literal之间必须要用空格隔开。
-
支持的操作符如下表所示。
-
duration_literal
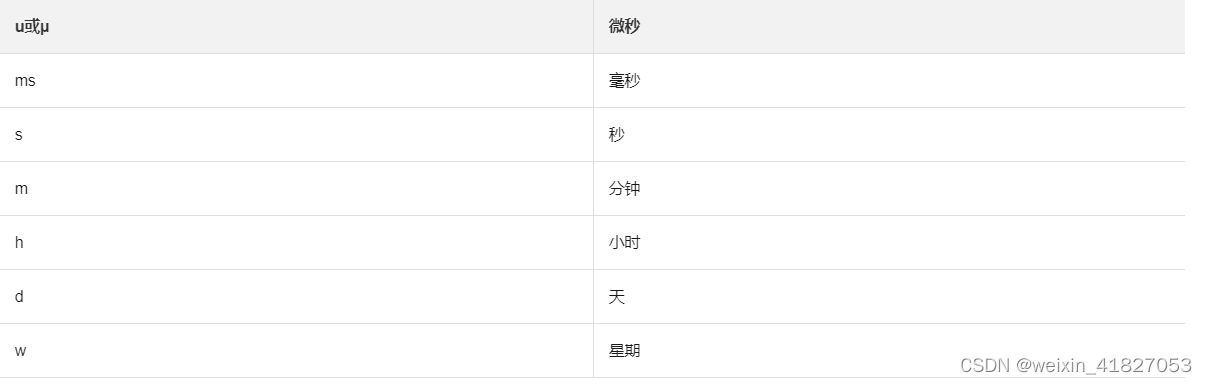
示例
用相对时间指定时间范围
SELECT “water_level” FROM “h2o_feet” WHERE time > now() - 1h
该查询返回过去一个小时内的数据。需要用空格分别将now()和-、-和1h隔开。
用绝对时间和相对时间指定时间范围
> SELECT "level description" FROM "h2o_feet" WHERE time > '2015-09-18T21:18:00Z' AND time < now() + 1000d
name: h2o_feet
time level description
---- -----------------
2015-09-18T21:24:00Z between 3 and 6 feet
2015-09-18T21:30:00Z between 3 and 6 feet
2015-09-18T21:36:00Z between 3 and 6 feet
2015-09-18T21:42:00Z between 3 and 6 feet
该查询返回时间戳在2015年9月18日21:18:00和now()之后的1000天之间的数据。需要用空格分别将now()和+、+和1000d隔开。
时间语法的常见问题
使用OR选择多个时间间隔
InfluxDB不支持在WHERE子句中使用OR来指定多个时间间隔。
在带有GROUP BY time()的查询语句中,查询发生在now()之后的数据
对于大多数SELECT语句,默认的时间范围是从1677-09-21 00:12:43.145224194 UTC到2262-04-11T23:47:16.854775806Z UTC。对于包含GROUP BY time()子句的SELECT语句,默认的时间范围是从1677-09-21 00:12:43.145224194 UTC到now()。
若想查询发生在now()之后的数据,包含GROUP BY time()子句的SELECT语句必须在WHERE子句中提供一个时间上限(upper bound)。
示例
使用CLI向数据库NOAA_water_database中写入一个发生在now()之后的数据点:
INSERT h2o_feet,location=santa_monica water_level=3.1 1587074400000000000
运行一个带有GROUP BY time()的查询,涵盖时间戳在2015-09-18T21:30:00Z和now()之后的180个星期之间的数据:
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location"='santa_monica' AND time >= '2015-09-18T21:30:00Z' AND time <= now() + 180w GROUP BY time(12m) fill(none)
name: h2o_feet
time mean
---- ----
2015-09-18T21:24:00Z 5.01
2015-09-18T21:36:00Z 5.002
2020-04-16T22:00:00Z 3.1
注意:WHERE子句必须提供一个时间上限来覆盖默认的now()上限。以下查询仅仅是将时间下限(lower bound)重新设置为now(),使得查询的时间范围在now()和now()之间,所以没有返回任何数据:
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location"='santa_monica' AND time >= now() GROUP BY time(12m) fill(none)
>
配置返回的时间戳
CLI默认返回epoch格式的时间戳,并且精确到纳秒,可通过命令precision 来指定其它的时间格式。HTTP API默认返回RFC3339格式的时间戳,可通过参数epoch来指定其它的时间格式。
2.10 正则表达式
InfluxQL支持在以下场景中使用正则表达式:
- 在SELECT子句中的field key和tag key。
- 在FROM子句中的measurement。
- 在WHERE子句中的tag value和字符串类型的field value。
- 在GROUP BY子句中的tag key。
目前,InfluxQL不支持在WHERE子句、数据库和保留策略中使用正则表达式去匹配非字符串类型的field value。
注释:正则表达式比较比字符串比较更加消耗计算资源;带有正则表达式的查询比那些不带的性能要低一些。
语法
SELECT /<regular_expression_field_key>/ FROM /<regular_expression_measurement>/ WHERE [<tag_key> /<regular_expression_tag_value>/ | <field_key> /<regular_expression_field_value>/] GROUP BY /<regular_expression_tag_key>/
语法描述
正则表达式被字符/包围,并使用Golang的正则表达式语法。
支持的操作符:
| =~ | 匹配 |
| !~ | 不匹配 |
示例
在SELECT子句中使用正则表达式指定field key和tag key
> SELECT /l/ FROM "h2o_feet" LIMIT 1
name: h2o_feet
time level description location water_level
---- ----------------- -------- -----------
2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12
该查询返回所有包含字符l的field key和tag key。请注意,在SELECT子句中的正则表达式必须至少匹配一个field key,才能返回与正则表达式匹配的tag key所对应的结果。
目前,没有语法可以区分SELECT子句中field key的正则表达式和tag key的正则表达式,不支持语法/<regular_expression>/::[field | tag]。
在SELECT子句中使用正则表达式指定带函数的field key
> SELECT DISTINCT(/level/) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00.000000000Z' AND time <= '2015-08-18T00:12:00Z'
name: h2o_feet
time distinct_level description distinct_water_level
---- -------------------------- --------------------
2015-08-18T00:00:00Z below 3 feet 2.064
2015-08-18T00:00:00Z 2.116
2015-08-18T00:00:00Z 2.028
该查询使用了一个InfluxQL函数,返回每个包含level的field key所对应的去重后的field value。
在FROM子句中使用正则表达式指定measurement
> SELECT MEAN("degrees") FROM /temperature/
name: average_temperature
time mean
---- ----
1970-01-01T00:00:00Z 79.98472932232272
name: h2o_temperature
time mean
---- ----
1970-01-01T00:00:00Z 64.98872722506226
该查询使用了一个InfluxQL函数,计算数据库NOAA_water_database中每个名字包含temperature的measurement的degrees的平均值。
在WHERE子句中使用正则表达式指定tag value
> SELECT MEAN(water_level) FROM "h2o_feet" WHERE "location" =~ /[m]/ AND "water_level" > 3
name: h2o_feet
time mean
---- ----
1970-01-01T00:00:00Z 4.47155532049926
该查询使用了一个InfluxQL函数,计算满足条件的water_level的平均值,需满足的条件是:location的tag value包含m并且water_level大于3。
在WHERE子句中使用正则表达式指定没有值的tag
> SELECT * FROM "h2o_feet" WHERE "location" !~ /./
>
该查询从measurement h2o_feet中选择数据,这些数据需满足条件:tag location中不包含数据。因为数据库NOAA_water_database里面每个数据点都有location对应的tag value,所以该查询不返回任何结果。
不使用正则表达式也可以执行相同的查询,请查阅FAQ章节获得更多相关信息。
在WHERE子句中使用正则表达式指定具有值的tag
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location" =~ /./
name: h2o_feet
time mean
---- ----
1970-01-01T00:00:00Z 4.442107025822523
该查询使用了一个InfluxQL函数,计算满足条件的water_level的平均值,需满足的条件是:location具有tag value。
在WHERE子句中使用正则表达式指定field value
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND "level description" =~ /between/
name: h2o_feet
time mean
---- ----
1970-01-01T00:00:00Z 4.47155532049926
该查询使用了一个InfluxQL函数,计算满足条件的water_level的平均值,需满足的条件是:level description的field value包含between。
在GROUP BY子句中使用正则表达式指定tag key
> SELECT FIRST("index") FROM "h2o_quality" GROUP BY /l/
name: h2o_quality
tags: location=coyote_creek
time first
---- -----
2015-08-18T00:00:00Z 41
name: h2o_quality
tags: location=santa_monica
time first
---- -----
2015-08-18T00:00:00Z 99
该查询使用了一个InfluxQL函数,查询每个tag key包含l的tag所对应的index的第一个值。
2.11 数据类型和转换
SELECT子句支持使用语法::指定field的类型和基本的类型转换操作。
数据类型
field value可以是浮点数、整数、字符串或者布尔值。语法::允许用户在查询中指定field value的数据类型。
注释:通常,不需要在SELECT子句指定field value的数据类型。在大多数情况下,InfluxDB拒绝任何尝试将field value写入到之前接受不同数据类型field value的field。在不同的shard group中,field value的数据类型可能不同,在这些情况下,可能需要在SELECT子句中指定field value的数据类型。
语法
SELECT_clause <field_key>:: FROM_clause
语法描述
type可以是float,integer,string或boolean。在大多数情况下,如果field_key没有存储指定type的数据,那么InfluxDB将不会返回任何数据。请参见转换获得更多相关信息。
示例
> SELECT "water_level"::float FROM "h2o_feet" LIMIT 4
name: h2o_feet
--------------
time water_level
2015-08-18T00:00:00Z 8.12
2015-08-18T00:00:00Z 2.064
2015-08-18T00:06:00Z 8.005
2015-08-18T00:06:00Z 2.116
该查询返回field key water_level为浮点型的数据。
转换
语法::允许用户在查询中执行基本的类型转换。目前,InfluxDB支持field value从整数转换成浮点数,或者从浮点数转换成整数。
语法
SELECT_clause <field_key>:: FROM_clause
语法描述
type可以是float或integer。如果查询试图把整数或浮点数转换成字符串或布尔值,那么InfluxDB将不会返回任何数据。
示例
将浮点型的field value转换成整型
> SELECT "water_level"::integer FROM "h2o_feet" LIMIT 4
name: h2o_feet
--------------
time water_level
2015-08-18T00:00:00Z 8
2015-08-18T00:00:00Z 2
2015-08-18T00:06:00Z 8
2015-08-18T00:06:00Z 2
该查询将浮点型的water_level转换成整型,然后返回。
将浮点型的field value转换成字符串(不支持该功能)
> SELECT "water_level"::string FROM "h2o_feet" LIMIT 4
>
因为不支持将浮点型的field value转换成字符串,所以该查询不返回任何数据。
2.12 合并
在InfluxDB中,查询自动将序列合并。
示例
数据库NOAA_water_database中的measurement的h2o_feet是两个序列的一部分。第一个序列由measurement h2o_feet和tag location = coyote_creek组成。第二个序列由measurement h2o_feet和tag location = santa_monica组成。
以下查询在计算water_level的平均值时自动将这两个序列合并:
> SELECT MEAN("water_level") FROM "h2o_feet"
name: h2o_feet
--------------
time mean
1970-01-01T00:00:00Z 4.442107025822521
如果您只想要计算第一个序列的water_level的平均值,请在WHERE子句中指定相关的tag:
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location" = 'coyote_creek'
name: h2o_feet
--------------
time mean
1970-01-01T00:00:00Z 5.359342451341401
如果您想要计算每个序列的water_level的平均值,请加上GROUP BY子句:
> SELECT MEAN("water_level") FROM "h2o_feet" GROUP BY "location"
name: h2o_feet
tags: location=coyote_creek
time mean
---- ----
1970-01-01T00:00:00Z 5.359342451341401
name: h2o_feet
tags: location=santa_monica
time mean
---- ----
1970-01-01T00:00:00Z 3.530863470081006
2.13 多个语句
在查询中请使用分号(;)将多个SELECT语句隔开。
示例
CLI
在InfluxDB®的CLI中:
> SELECT MEAN("water_level") FROM "h2o_feet"; SELECT "water_level" FROM "h2o_feet" LIMIT 2
name: h2o_feet
time mean
---- ----
1970-01-01T00:00:00Z 4.442107025822522
name: h2o_feet
time water_level
---- -----------
2015-08-18T00:00:00Z 8.12
2015-08-18T00:00:00Z 2.064
HTTP API
使用InfluxDB®的HTTP API:
{
"results": [
{
"statement_id": 0,
"series": [
{
"name": "h2o_feet",
"columns": [
"time",
"mean"
],
"values": [
[
"1970-01-01T00:00:00Z",
4.442107025822522
]
]
}
]
},
{
"statement_id": 1,
"series": [
{
"name": "h2o_feet",
"columns": [
"time",
"water_level"
],
"values": [
[
"2015-08-18T00:00:00Z",
8.12
],
[
"2015-08-18T00:00:00Z",
2.064
]
]
}
]
}
]
}
2.14 子查询
子查询是嵌套在另一个查询的FROM子句中的查询。使用子查询将查询作为条件应用在另一个查询中。子查询提供类似嵌套函数和SQL HAVING子句的功能。
语法
SELECT_clause FROM ( SELECT_statement ) […]
语法描述
InfluxDB®首先执行子查询,然后执行主查询。
主查询包含着子查询,至少需要SELECT子句和FROM子句。主查询支持本文档中列出的所有子句。
子查询在主查询的FROM子句中,需要用括号将子查询括起来。子查询支持本文档中列出的所有子句。
InfluxQL支持在主查询中有多个嵌套的子查询,示例语法如下:
SELECT_clause FROM ( SELECT_clause FROM ( SELECT_statement ) […] ) […]
示例
计算多个MAX()值的SUM()
> SELECT SUM("max") FROM (SELECT MAX("water_level") FROM "h2o_feet" GROUP BY "location")
name: h2o_feet
time sum
---- ---
1970-01-01T00:00:00Z 17.169
该查询返回每个location中water_level的最大值的总和。
InfluxDB®首先执行子查询,计算每个location的water_level的最大值:
> SELECT MAX("water_level") FROM "h2o_feet" GROUP BY "location"
name: h2o_feet
tags: location=coyote_creek
time max
---- ---
2015-08-29T07:24:00Z 9.964
name: h2o_feet
tags: location=santa_monica
time max
---- ---
2015-08-29T03:54:00Z 7.205
然后,InfluxDB执行主查询,计算这些最大值的总和:9.964 + 7.205 = 17.169。请注意,该主查询指定max(而不是water_level)作为SUM()函数中的field key。
计算两个field的差值的MEAN()
> SELECT MEAN("difference") FROM (SELECT "cats" - "dogs" AS "difference" FROM "pet_daycare")
name: pet_daycare
time mean
---- ----
1970-01-01T00:00:00Z 1.75
该查询返回measurement pet_daycare中cats数量和dogs数量的差异的平均值。
InfluxDB®首先执行子查询,计算field cats中的值和field dogs中的值的差异,并将输出列命名为difference:
> SELECT "cats" - "dogs" AS "difference" FROM "pet_daycare"
name: pet_daycare
time difference
---- ----------
2017-01-20T00:55:56Z -1
2017-01-21T00:55:56Z -49
2017-01-22T00:55:56Z 66
2017-01-23T00:55:56Z -9
然后,InfluxDB®执行主查询,计算这些差值的平均值。请注意,该主查询指定difference作为MEAN()函数中的field key。
计算多个MEAN()值并在这些值上加上条件
> SELECT "all_the_means" FROM (SELECT MEAN("water_level") AS "all_the_means" FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m) ) WHERE "all_the_means" > 5
name: h2o_feet
time all_the_means
---- -------------
2015-08-18T00:00:00Z 5.07625
该查询返回water_level的所有大于5的平均值。
InfluxDB®首先执行子查询,计算从2015-08-18T00:00:00Z到2015-08-18T00:30:00Z water_level的平均值,并将结果按12分钟的时间间隔进行分组,同时将输出列命名为all_the_means:
> SELECT MEAN("water_level") AS "all_the_means" FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m)
name: h2o_feet
time all_the_means
---- -------------
2015-08-18T00:00:00Z 5.07625
2015-08-18T00:12:00Z 4.950749999999999
2015-08-18T00:24:00Z 4.80675
然后,InfluxDB®执行主查询,只返回那些大于5的平均值。请注意,该主查询指定all_the_means作为SELECT子句中的field key。
计算多个DERIVATIVE()值的SUM()
> SELECT SUM("water_level_derivative") AS "sum_derivative" FROM (SELECT DERIVATIVE(MEAN("water_level")) AS "water_level_derivative" FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m),"location") GROUP BY "location"
name: h2o_feet
tags: location=coyote_creek
time sum_derivative
---- --------------
1970-01-01T00:00:00Z -0.4950000000000001
name: h2o_feet
tags: location=santa_monica
time sum_derivative
---- --------------
1970-01-01T00:00:00Z -0.043999999999999595
该查询返回每个location中water_level的平均值的导数之和。
InfluxDB®首先执行子查询,计算以12分钟为间隔获取的water_level的平均值的导数,它对每个location都进行了计算,并将输出列命名为water_level_derivative:
> SELECT DERIVATIVE(MEAN("water_level")) AS "water_level_derivative" FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m),"location"
name: h2o_feet
tags: location=coyote_creek
time water_level_derivative
---- ----------------------
2015-08-18T00:12:00Z -0.23800000000000043
2015-08-18T00:24:00Z -0.2569999999999997
name: h2o_feet
tags: location=santa_monica
time water_level_derivative
---- ----------------------
2015-08-18T00:12:00Z -0.0129999999999999
2015-08-18T00:24:00Z -0.030999999999999694
然后,InfluxDB®执行主查询,计算每个location的water_level_derivative的总和。请注意,该主查询指定water_level_derivative(而不是water_level或derivative)作为SUM()函数中的field key。
子查询的常见问题
在子查询中有多个SELECT语句
InfluxQL支持在主查询中有多个嵌套的子查询:
SELECT_clause FROM ( SELECT_clause FROM ( SELECT_statement ) [...] ) [...]
------------------ ----------------
Subquery 1 Subquery 2
InfluxQL不支持在子查询中有多个SELECT语句:
SELECT_clause FROM (SELECT_statement; SELECT_statement) […]
如果在子查询中有多个SELECT语句,那么系统会返回解析错误。
3、InfluxQL函数
3.1 聚合函数
本文档主要介绍了聚合函数(Aggregations)的语法结构、语法说明以及使用示例。
COUNT()
返回非空的field value的个数。
语法
SELECT COUNT([*|<field_key>|/<regular_expression>/])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
嵌套语法
SELECT COUNT(DISTINCT([*|<field_key>|/<regular_expression>/]))[…]
语法说明
COUNT(field_key):返回field key对应的field value的个数。
COUNT(/regular_expression/):返回与正则表达式匹配的每个field key对应的field value的个数。
COUNT(*):返回在measurement中每个field key对应的field value的个数。
COUNT():支持所有数据类型的field value。InfluxQL支持将DISTINCT()函数嵌套在COUNT()函数里。
示例1:计算指定field key对应的field value的个数
SELECT COUNT("water_level") FROM "h2o_feet"
name: h2o_feet
time count
---------
1970-01-01T00:00:00Z15258
该查询返回measurement h2o_feet中field key water_level对应的非空field value的个数。
示例2:计算measurement中每个field key对应的field value的个数
SELECT COUNT(*) FROM "h2o_feet"
name: h2o_feet
time count_level description count_water_level
--------------------------------------------
1970-01-01T00:00:00Z1525815258
该查询返回measurement h2o_feet中每个field key对应的非空field value的个数。measurement h2o_feet中有两个field key:level description和water_level。
示例3:计算与正则表达式匹配的每个field key对应的field value的个数
SELECT COUNT(/water/) FROM "h2o_feet"
name: h2o_feet
time count_water_level
---------------------
1970-01-01T00:00:00Z15258
该查询返回measurement h2o_feet中每个包含单词water的field key对应的非空field value的个数。
示例4:计算指定field key对应的field value的个数并包含多个子句
SELECT COUNT("water_level") FROM "h2o_feet" WHERE time >='2015-08-17T23:48:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(200) LIMIT 7 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time count
---------
2015-08-17T23:48:00Z200
2015-08-18T00:00:00Z2
2015-08-18T00:12:00Z2
2015-08-18T00:24:00Z2
2015-08-18T00:36:00Z2
2015-08-18T00:48:00Z2
该查询返回field key water_level对应的非空field value的个数,它涵盖的时间范围在2015-08-17T23:48:00Z和2015-08-18T00:54:00Z之间,并将查询结果按12分钟的时间间隔和每个tag进行分组,同时,该查询用200填充没有数据的时间间隔,并将返回的数据点个数和序列个数分别限制为7和1。
示例五:计算指定field key对应的不同field value的个数
SELECT COUNT(DISTINCT("level description")) FROM "h2o_feet"
name: h2o_feet
time count
---------
1970-01-01T00:00:00Z4
该查询返回measurement h2o_feet中field key level description对应的不同field value的个数。
COUNT()的常见问题
大多数InfluxQL函数对于没有数据的时间间隔返回null值,如果不想返回null,可以使用fill()函数,fill(<fill_option>)将null值替换成fill_option。对于没有数据的时间间隔,COUNT()返回0,而fill(<fill_option>)可以将0替换成fill_option。
示例
> SELECT COUNT("water_level") FROM "h2o_feet" WHERE time >='2015-09-18T21:24:00Z' AND time <='2015-09-18T21:54:00Z' GROUP BY time(12m)
name: h2o_feet
time count
---------
2015-09-18T21:24:00Z2
2015-09-18T21:36:00Z2
2015-09-18T21:48:00Z0
> SELECT COUNT("water_level") FROM "h2o_feet" WHERE time >='2015-09-18T21:24:00Z' AND time <='2015-09-18T21:54:00Z' GROUP BY time(12m) fill(800000)
name: h2o_feet
time count
---------
2015-09-18T21:24:00Z2
2015-09-18T21:36:00Z2
2015-09-18T21:48:00Z800000
上述代码块中的第一个查询没有使用fill(),最后一个时间间隔中没有数据,因此该时间间隔返回的值是0。第二个查询使用了fill(800000),它将最后一个时间间隔的返回值0替换成800000。
DISTINCT()
返回不同的field value。
语法
SELECT DISTINCT([*|<field_key>|/<regular_expression>/]) FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
嵌套语法
SELECT COUNT(DISTINCT([*|<field_key>|/<regular_expression>/]))[…]
语法说明
DISTINCT(field_key):返回field key对应的不同的field value。
DISTINCT(/regular_expression/):返回与正则表达式匹配的每个field key对应的不同的field value。
DISTINCT(*):返回在measurement中每个field key对应的不同的field value。
DISTINCT():支持所有数据类型的field value。InfluxQL支持将DISTINCT()函数嵌套在COUNT()函数里。
示例1:列出指定field key对应的不同的field value
SELECT DISTINCT("level description") FROM "h2o_feet"
name: h2o_feet
time distinct
------------
1970-01-01T00:00:00Z between 6 and 9 feet
1970-01-01T00:00:00Z below 3 feet
1970-01-01T00:00:00Z between 3 and 6 feet
1970-01-01T00:00:00Z at or greater than 9 feet
该查询返回measurement h2o_feet中field key level description对应的不同field value。
示例2:列出measurement中每个field key对应的不同的field value
SELECT DISTINCT(*) FROM "h2o_feet"
name: h2o_feet
time distinct_level description distinct_water_level
--------------------------------------------------
1970-01-01T00:00:00Z between 6 and 9 feet 8.12
1970-01-01T00:00:00Z between 3 and 6 feet 8.005
1970-01-01T00:00:00Z at or greater than 9 feet 7.887
1970-01-01T00:00:00Z below 3 feet 7.762
[...]
该查询返回measurement h2o_feet中每个field key对应的不同的field value。measurement h2o_feet中有两个field key:level description和water_level。
示例3:列出与正则表达式匹配的每个field key对应的不同的field value
SELECT DISTINCT(/description/) FROM "h2o_feet"
name: h2o_feet
time distinct_level description
------------------------------
1970-01-01T00:00:00Z below 3 feet
1970-01-01T00:00:00Z between 6 and 9 feet
1970-01-01T00:00:00Z between 3 and 6 feet
1970-01-01T00:00:00Z at or greater than 9 feet
该查询返回measurement h2o_feet中每个包含单词description的field key对应的不同的field value。
示例4:列出指定field key对应的不同的field value并包含多个子句
> SELECT DISTINCT("level description") FROM "h2o_feet" WHERE time >='2015-08-17T23:48:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(12m),* SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time distinct
------------
2015-08-18T00:00:00Z between 6 and 9 feet
2015-08-18T00:12:00Z between 6 and 9 feet
2015-08-18T00:24:00Z between 6 and 9 feet
2015-08-18T00:36:00Z between 6 and 9 feet
2015-08-18T00:48:00Z between 6 and 9 feet
该查询返回field key level description对应的不同的field value,它涵盖的时间范围在2015-08-17T23:48:00Z和2015-08-18T00:54:00Z之间,并将查询结果按12分钟的时间间隔和每个tag进行分组,同时,该查询将返回的序列个数限制为1。
示例5:计算指定field key对应的不同field value的个数
SELECT COUNT(DISTINCT("level description")) FROM "h2o_feet"
name: h2o_feet
time count
---------
1970-01-01T00:00:00Z4
该查询返回measurement h2o_feet中field key level description对应的不同field value的个数。
DISTINCT()的常见问题
在INTO子句中使用DISTINCT()可能会导致TSDB For InfluxDB®覆盖目标measurement中的数据点。DISTINCT()通常返回多个具有相同时间戳的结果;TSDB For InfluxDB®假设在相同序列中并具有相同时间戳的数据点是重复数据点,并简单地用目标measurement中最新的数据点覆盖重复数据点。
示例
下面代码块中的第一个查询使用了DISTINCT(),并返回四个结果。请注意,每个结果都有相同的时间戳。第二个查询将INTO子句添加到查询中,并将查询结果写入measurement distincts。最后一个查询选择measurement distincts中所有数据。因为原来的四个结果是重复的(它们在相同的序列,有相同的时间戳),所以最后一个查询只返回一个数据点。当系统遇到重复数据点时,它会用最近的数据点覆盖之前的数据点。
SELECT DISTINCT("level description") FROM "h2o_feet"
name: h2o_feet
time distinct
------------
1970-01-01T00:00:00Z below 3 feet
1970-01-01T00:00:00Z between 6 and 9 feet
1970-01-01T00:00:00Z between 3 and 6 feet
1970-01-01T00:00:00Z at or greater than 9 feet
SELECT DISTINCT("level description") INTO "distincts" FROM "h2o_feet"
name: result
time written
-----------
1970-01-01T00:00:00Z4
SELECT * FROM "distincts"
name: distincts
time distinct
------------
1970-01-01T00:00:00Z at or greater than 9 feet
INTEGRAL()
返回field value曲线下的面积,即关于field value的积分。
语法
SELECT INTEGRAL([*|<field_key>|/<regular_expression>/][,])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
InfluxDB计算field value曲线下的面积,并将这些结果转换为每个unit的总面积。参数unit的值是一个整数,单位为时间,这个参数是可选的。如果查询没有指定unit的值,那么unit默认为1秒。
INTEGRAL(field_key):返回field key对应的field value曲线下的面积。
INTEGRAL(/regular_expression/):返回与正则表达式匹配的每个field key对应的field value曲线下的面积。
INTEGRAL(*):返回在measurement中每个field key对应的field value曲线下的面积。
INTEGRAL():不支持fill()。INTEGRAL()支持数据类型为int64和float64的field value。
示例1:计算指定field key对应的field value的积分
SELECT INTEGRAL("water_level") FROM "h2o_feet" WHERE "location"='santa_monica' AND time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z'
name: h2o_feet
time integral
------------
1970-01-01T00:00:00Z3732.66
该查询返回measurement h2o_feet中field key water_level对应的field value曲线下的面积(以秒为单位)。
示例2:计算指定field key对应的field value的积分并指定unit
SELECT INTEGRAL("water_level",1m) FROM "h2o_feet" WHERE "location"='santa_monica' AND time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z'
name: h2o_feet
time integral
------------
1970-01-01T00:00:00Z62.211
该查询返回measurement h2o_feet中field key water_level对应的field value曲线下的面积(以分钟为单位)。
示例3:计算measurement中每个field key对应的field value的积分并指定unit
SELECT INTEGRAL(*,1m) FROM "h2o_feet" WHERE "location"='santa_monica' AND time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z'
name: h2o_feet
time integral_water_level
------------------------
1970-01-01T00:00:00Z62.211
该查询返回measurement h2o_feet中每个存储数值的field key对应的field value曲线下的面积(以分钟为单位)。measurement h2o_feet中只有一个数值类型的field:water_level。
示例4:计算与正则表达式匹配的每个field key对应的field value的积分并指定unit
SELECT INTEGRAL(/water/,1m) FROM "h2o_feet" WHERE "location"='santa_monica' AND time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z'
name: h2o_feet
time integral_water_level
------------------------
1970-01-01T00:00:00Z62.211
该查询返回measurement h2o_feet中每个存储数值并包含单词water的field key对应的field value曲线下的面积(以分钟为单位)。
示例5:计算指定field key对应的field value的积分并包含多个子句
SELECT INTEGRAL("water_level",1m) FROM "h2o_feet" WHERE "location"='santa_monica' AND time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' GROUP BY time(12m) LIMIT 1
name: h2o_feet
time integral
------------
2015-08-18T00:00:00Z24.972
该查询返回measurement h2o_feet中field key water_level对应的field value曲线下的面积(以分钟为单位),它涵盖的时间范围在2015-08-18T00:00:00Z和2015-08-18T00:30:00Z之间,并将查询结果按12分钟的时间间隔进行分组。同时,该查询将返回的数据点个数限制为1。
MEAN()
返回field value的平均值。
语法
SELECT MEAN([*|<field_key>|/<regular_expression>/])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
MEAN(field_key):返回field key对应的field value的平均值。
MEAN(/regular_expression/):返回与正则表达式匹配的每个field key对应的field value的平均值。
MEAN(*):返回在measurement中每个field key对应的field value的平均值。
MEAN():支持数据类型为int64和float64的field value。
示例1:计算指定field key对应的field value的平均值
SELECT MEAN("water_level") FROM "h2o_feet"
name: h2o_feet
time mean
--------
1970-01-01T00:00:00Z4.442107025822522
该查询返回measurement h2o_feet中field key water_level对应的field value的平均值。
示例2:计算measurement中每个field key对应的field value的平均值
SELECT MEAN(*) FROM "h2o_feet"
name: h2o_feet
time mean_water_level
--------------------
1970-01-01T00:00:00Z4.442107025822522
该查询返回measurement h2o_feet中每个存储数值的field key对应的field value的平均值。measurement h2o_feet中只有一个数值类型的field:water_level。
示例3:计算与正则表达式匹配的每个field key对应的field value的平均值
SELECT MEAN(/water/) FROM "h2o_feet"
name: h2o_feet
time mean_water_level
--------------------
1970-01-01T00:00:00Z4.442107025822523
该查询返回measurement h2o_feet中每个存储数值并包含单词water的field key对应的field value的平均值。
示例4:计算指定field key对应的field value的平均值并包含多个子句
SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >='2015-08-17T23:48:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(9.01) LIMIT 7 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time mean
--------
2015-08-17T23:48:00Z9.01
2015-08-18T00:00:00Z8.0625
2015-08-18T00:12:00Z7.8245
2015-08-18T00:24:00Z7.5675
2015-08-18T00:36:00Z7.303
2015-08-18T00:48:00Z7.046
该查询返回measurement h2o_feet中field key water_level对应的field value的平均值,它涵盖的时间范围在2015-08-17T23:48:00Z和2015-08-18T00:30:00Z之间,并将查询结果按12分钟的时间间隔和每个tag进行分组,同时,该查询用9.01填充没有数据的时间间隔,并将返回的数据点个数和序列个数分别限制为7和1。
MEDIAN()
返回排好序的field value的中位数。
语法
SELECT MEDIAN([*|<field_key>|/<regular_expression>/])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
MEDIAN(field_key):返回field key对应的field value的中位数。
MEDIAN(/regular_expression/):返回与正则表达式匹配的每个field key对应的field value的中位数。
MEDIAN(*):返回在measurement中每个field key对应的field value的中位数。
MEDIAN()支持数据类型为int64和float64的field value。
说明 MEDIAN()近似于PERCENTILE(field_key, 50),除非field key包含的field value个数为偶数,那么这时候MEDIAN()将返回两个中间值的平均数。
示例1:计算指定field key对应的field value的中位数
SELECT MEDIAN("water_level") FROM "h2o_feet"
name: h2o_feet
time median
----------
1970-01-01T00:00:00Z4.124
该查询返回measurement h2o_feet中field key water_level对应的field value的中位数。
示例2:计算measurement中每个field key对应的field value的中位数
SELECT MEDIAN(*) FROM "h2o_feet"
name: h2o_feet
time median_water_level
----------------------
1970-01-01T00:00:00Z4.124
该查询返回measurement h2o_feet中每个存储数值的field key对应的field value的中位数。measurement h2o_feet中只有一个数值类型的field:water_level。
示例3:计算与正则表达式匹配的每个field key对应的field value的中位数
SELECT MEDIAN(/water/) FROM "h2o_feet"
name: h2o_feet
time median_water_level
----------------------
1970-01-01T00:00:00Z4.124
该查询返回measurement h2o_feet中每个存储数值并包含单词water的field key对应的field value的中位数。
示例4:计算指定field key对应的field value的中位数并包含多个子句
SELECT MEDIAN("water_level") FROM "h2o_feet" WHERE time >='2015-08-17T23:48:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(700) LIMIT 7 SLIMIT 1 SOFFSET 1
name: h2o_feet
tags: location=santa_monica
time median
----------
2015-08-17T23:48:00Z700
2015-08-18T00:00:00Z2.09
2015-08-18T00:12:00Z2.077
2015-08-18T00:24:00Z2.0460000000000003
2015-08-18T00:36:00Z2.0620000000000003
2015-08-18T00:48:00Z700
该查询返回measurement h2o_feet中field key water_level对应的field value的中位数,它涵盖的时间范围在2015-08-17T23:48:00Z和2015-08-18T00:54:00Z之间,并将查询结果按12分钟的时间间隔和每个tag进行分组,同时,该查询用700填充没有数据的时间间隔,将返回的数据点个数和序列个数分别限制为7和1,并将返回的序列偏移一个(即第一个序列的数据不返回)。
MODE()
返回field value中出现频率最高的值。
语法
SELECT MODE([*|<field_key>|/<regular_expression>/])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
MODE(field_key):返回field key对应的field value中出现频率最高的值。
MODE(/regular_expression/):返回与正则表达式匹配的每个field key对应的field value中出现频率最高的值。
MODE(*):返回在measurement中每个field key对应的field value中出现频率最高的值。
MODE():支持所有数据类型的field value。
说明 如果出现频率最高的值有两个或多个并且它们之间有关联,那么MODE()返回具有最早时间戳的field value。
示例1:计算指定field key对应的field value中出现频率最高的值
SELECT MODE("level description") FROM "h2o_feet"
name: h2o_feet
time mode
--------
1970-01-01T00:00:00Z between 3 and 6 feet
该查询返回measurement h2o_feet中field key level description对应的field value中出现频率最高的值。
示例2:计算measurement中每个field key对应的field value中出现频率最高的值
SELECT MODE(*) FROM "h2o_feet"
name: h2o_feet
time mode_level description mode_water_level
------------------------------------------
1970-01-01T00:00:00Z between 3 and 6 feet 2.69
该查询返回measurement h2o_feet中每个field key对应的field value中出现频率最高的值。measurement h2o_feet中有两个field key:level description和water_level。
示例3:计算与正则表达式匹配的每个field key对应的field value中出现频率最高的值
SELECT MODE(/water/) FROM "h2o_feet"
name: h2o_feet
time mode_water_level
--------------------
1970-01-01T00:00:00Z2.69
该查询返回measurement h2o_feet中每个包含单词water的field key对应的field value中出现频率最高的值。
示例4:计算指定field key对应的field value中出现频率最高的值并包含多个子句
SELECT MODE("level description") FROM "h2o_feet" WHERE time >='2015-08-17T23:48:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(12m),* LIMIT 3 SLIMIT 1 SOFFSET 1
name: h2o_feet
tags: location=santa_monica
time mode
--------
2015-08-17T23:48:00Z
2015-08-18T00:00:00Z below 3 feet
2015-08-18T00:12:00Z below 3 feet
该查询返回measurement h2o_feet中field key water_level对应的field value中出现频率最高的值,它涵盖的时间范围在2015-08-17T23:48:00Z和2015-08-18T00:54:00Z之间,并将查询结果按12分钟的时间间隔和每个tag进行分组,同时,该查询将返回的数据点个数和序列个数分别限制为3和1,并将返回的序列偏移一个(即第一个序列的数据不返回)。
SPREAD()
返回field value中最大值和最小值之差。
语法
SELECT SPREAD([*|<field_key>|/<regular_expression>/])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
SPREAD(field_key):返回field key对应的field value中最大值和最小值之差。
SPREAD(/regular_expression/):返回与正则表达式匹配的每个field key对应的field value中最大值和最小值之差。
SPREAD(*):返回在measurement中每个field key对应的field value中最大值和最小值之差。
SPREAD():支持数据类型为int64和float64的field value。
示例1:计算指定field key对应的field value中最大值和最小值之差
SELECT SPREAD("water_level") FROM "h2o_feet"
name: h2o_feet
time spread
----------
1970-01-01T00:00:00Z10.574
该查询返回measurement h2o_feet中field key water_level对应的field value中最大值和最小值之差。
示例2:计算measurement中每个field key对应的field value中最大值和最小值之差
SELECT SPREAD(*) FROM "h2o_feet"
name: h2o_feet
time spread_water_level
----------------------
1970-01-01T00:00:00Z10.574
该查询返回measurement h2o_feet中每个存储数值的field key对应的field value中最大值和最小值之差。measurement h2o_feet中只有一个数值类型的field:water_level。
示例3:计算与正则表达式匹配的每个field key对应的field value中最大值和最小值之差
SELECT SPREAD(/water/) FROM "h2o_feet"
name: h2o_feet
time spread_water_level
----------------------
1970-01-01T00:00:00Z10.574
该查询返回measurement h2o_feet中每个存储数值并包含单词water的field key对应的field value中最大值和最小值之差。
示例4:计算指定field key对应的field value中最大值和最小值之差并包含多个子句
SELECT SPREAD("water_level") FROM "h2o_feet" WHERE time >='2015-08-17T23:48:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(18) LIMIT 3 SLIMIT 1 SOFFSET 1
name: h2o_feet
tags: location=santa_monica
time spread
----------
2015-08-17T23:48:00Z18
2015-08-18T00:00:00Z0.052000000000000046
2015-08-18T00:12:00Z0.09799999999999986
该查询返回measurement h2o_feet中field key water_level对应的field value中最大值和最小值之差,它涵盖的时间范围在2015-08-17T23:48:00Z和2015-08-18T00:54:00Z之间,并将查询结果按12分钟的时间间隔和每个tag进行分组,同时,该查询用18填充没有数据的时间间隔,将返回的数据点个数和序列个数分别限制为3和1,并将返回的序列偏移一个(即第一个序列的数据不返回)。
STDDEV()
返回field value的标准差。
语法
SELECT STDDEV([*|<field_key>|/<regular_expression>/])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
STDDEV(field_key):返回field key对应的field value的标准差。
STDDEV(/regular_expression/):返回与正则表达式匹配的每个field key对应的field value的标准差。
STDDEV(*):返回在measurement中每个field key对应的field value的标准差。
STDDEV():支持数据类型为int64和float64的field value。
示例1:计算指定field key对应的field value的标准差
SELECT STDDEV("water_level") FROM "h2o_feet"
name: h2o_feet
time stddev
----------
1970-01-01T00:00:00Z2.279144584196141
该查询返回measurement h2o_feet中field key water_level对应的field value的标准差。
示例2:计算measurement中每个field key对应的field value的标准差
SELECT STDDEV(*) FROM "h2o_feet"
name: h2o_feet
time stddev_water_level
----------------------
1970-01-01T00:00:00Z2.279144584196141
该查询返回measurement h2o_feet中每个存储数值的field key对应的field value的标准差。measurement h2o_feet中只有一个数值类型的field:water_level。
示例3:计算与正则表达式匹配的每个field key对应的field value的标准差
SELECT STDDEV(/water/) FROM "h2o_feet"
name: h2o_feet
time stddev_water_level
----------------------
1970-01-01T00:00:00Z2.279144584196141
该查询返回measurement h2o_feet中每个存储数值并包含单词water的field key对应的field value的标准差。
示例4:计算指定field key对应的field value的标准差并包含多个子句
SELECT STDDEV("water_level") FROM "h2o_feet" WHERE time >='2015-08-17T23:48:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(18000) LIMIT 2 SLIMIT 1 SOFFSET 1
name: h2o_feet
tags: location=santa_monica
time stddev
----------
2015-08-17T23:48:00Z18000
2015-08-18T00:00:00Z0.03676955262170051
该查询返回measurement h2o_feet中field key water_level对应的field value的标准差,它涵盖的时间范围在2015-08-17T23:48:00Z和2015-08-18T00:54:00Z之间,并将查询结果按12分钟的时间间隔和每个tag进行分组,同时,该查询用18000填充没有数据的时间间隔,将返回的数据点个数和序列个数分别限制为2和1,并将返回的序列偏移一个(即第一个序列的数据不返回)。
SUM()
返回field value的总和。
语法
SELECT SUM([*|<field_key>|/<regular_expression>/])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
SUM(field_key):返回field key对应的field value的总和。
SUM(/regular_expression/):返回与正则表达式匹配的每个field key对应的field value的总和。
SUM(*):返回在measurement中每个field key对应的field value的总和。
SUM():支持数据类型为int64和float64的field value。
示例1:计算指定field key对应的field value的总和
SELECT SUM("water_level") FROM "h2o_feet"
name: h2o_feet
time sum
-------
1970-01-01T00:00:00Z67777.66900000004
该查询返回measurement h2o_feet中field key water_level对应的field value的总和。
示例2:计算measurement中每个field key对应的field value的总和
SELECT SUM(*) FROM "h2o_feet"
name: h2o_feet
time sum_water_level
-------------------
1970-01-01T00:00:00Z67777.66900000004
该查询返回measurement h2o_feet中每个存储数值的field key对应的field value的总和。measurement h2o_feet中只有一个数值类型的field:water_level。
示例3:计算与正则表达式匹配的每个field key对应的field value的总和
SELECT SUM(/water/) FROM "h2o_feet"
name: h2o_feet
time sum_water_level
-------------------
1970-01-01T00:00:00Z67777.66900000004
该查询返回measurement h2o_feet中每个存储数值并包含单词water的field key对应的field value的总和。
示例4:计算指定field key对应的field value的总和并包含多个子句
SELECT SUM("water_level") FROM "h2o_feet" WHERE time >='2015-08-17T23:48:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(18000) LIMIT 4 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time sum
-------
2015-08-17T23:48:00Z18000
2015-08-18T00:00:00Z16.125
2015-08-18T00:12:00Z15.649
2015-08-18T00:24:00Z15.135
该查询返回measurement h2o_feet中field key water_level对应的field value的总和,它涵盖的时间范围在2015-08-17T23:48:00Z和2015-08-18T00:54:00Z之间,并将查询结果按12分钟的时间间隔和每个tag进行分组,同时,该查询用18000填充没有数据的时间间隔,并将返回的数据点个数和序列个数分别限制为4和1。
3.2 选择函数
本文档主要介绍了选择函数(Selectors)的语法结构、语法说明以及使用示例。
BOTTOM()
返回最小的N个field value。
语法
SELECT BOTTOM(<field_key>[,<tag_key(s)>],)[,<tag_key(s)>|<field_key(s)>][INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
BOTTOM(field_key,N):返回field key对应的最小的N个值。
BOTTOM(field_key,tag_key(s),N):返回tag key的N个tag value对应的field key的最小值。
BOTTOM(field_key,N),tag_key(s),field_key(s):返回括号中的field key对应的最小的N个值,以及相关的tag和/或field。
BOTTOM():支持数据类型为int64和float64的field value。
说明 如果最小值有两个或多个相等的值,BOTTOM()返回具有最早时间戳的field value。当BOTTOM()函数与INTO子句一起使用时,BOTTOM()与其它InfluxQL函数不同。
示例1:选择指定field key对应的最小的三个值
SELECT BOTTOM("water_level",3) FROM "h2o_feet"
name: h2o_feet
time bottom
----------
2015-08-29T14:30:00Z-0.61
2015-08-29T14:36:00Z-0.591
2015-08-30T15:18:00Z-0.594
该查询返回measurement h2o_feet中field key water_level对应的最小的三个值。
示例2:选择两个tag对应的field key的最小值
SELECT BOTTOM("water_level","location",2) FROM "h2o_feet"
name: h2o_feet
time bottom location
------------------
2015-08-29T10:36:00Z-0.243 santa_monica
2015-08-29T14:30:00Z-0.61 coyote_creek
该查询返回tag key location的两个tag value对应的field key water_level的最小值。
示例3:选择指定field key对应的最小的四个值以及相关的tag和field
SELECT BOTTOM("water_level",4),"location","level description" FROM "h2o_feet"
name: h2o_feet
time bottom location level description
-----------------------------------
2015-08-29T14:24:00Z-0.587 coyote_creek below 3 feet
2015-08-29T14:30:00Z-0.61 coyote_creek below 3 feet
2015-08-29T14:36:00Z-0.591 coyote_creek below 3 feet
2015-08-30T15:18:00Z-0.594 coyote_creek below 3 feet
该查询返回field key water_level对应的最小的四个值,以及相关的tag key location和field key level description的值。
示例4:选择指定field key对应的最小的三个值并包含多个子句
SELECT BOTTOM("water_level",3),"location" FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(24m) ORDER BY time DESC
name: h2o_feet
time bottom location
------------------
2015-08-18T00:48:00Z1.991 santa_monica
2015-08-18T00:54:00Z2.054 santa_monica
2015-08-18T00:54:00Z6.982 coyote_creek
2015-08-18T00:24:00Z2.041 santa_monica
2015-08-18T00:30:00Z2.051 santa_monica
2015-08-18T00:42:00Z2.057 santa_monica
2015-08-18T00:00:00Z2.064 santa_monica
2015-08-18T00:06:00Z2.116 santa_monica
2015-08-18T00:12:00Z2.028 santa_monica
该查询返回在2015-08-18T00:00:00Z和2015-08-18T00:54:00Z之间的每个24分钟间隔内,field key water_level对应的最小的三个值,并且以递减的时间戳顺序返回结果。
说明 GROUP BY time()子句不会覆盖数据点的原始时间戳。
BOTTOM()的常见问题
问题一:BOTTOM()和GROUP BY time()子句同时使用
对于同时带有BOTTOM()和GROUP BY time()子句的查询,将返回每个GROUP BY time()时间间隔的指定个数的数据点。对于大多数GROUP BY time()查询,返回的时间戳表示GROUP BY time()时间间隔的开始时间,但是,带有BOTTOM()函数的GROUP BY time()查询则不一样,它们保留原始数据点的时间戳。
示例:以下查询返回每18分钟GROUP BY time()间隔对应的两个数据点。请注意,返回的时间戳是数据点的原始时间戳;它们不会被强制要求必须匹配GROUP BY time()间隔的开始时间。
SELECT BOTTOM("water_level",2) FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica' GROUP BY time(18m)
name: h2o_feet
time bottom
----------
__
2015-08-18T00:00:00Z2.064|
2015-08-18T00:12:00Z2.028|<-------Smallest points for the first time interval
--
__
2015-08-18T00:24:00Z2.041|
2015-08-18T00:30:00Z2.051|<-------Smallest points for the second time interval
--
问题二:BOTTOM()和具有少于N个tag value的tag key
使用语法SELECT BOTTOM(<field_key>,<tag_key>,)的查询可以返回比预期少的数据点。如果tag key有X个tag value,但是查询指定的是N个tag value,如果X小于N,那么查询将返回X个数据点。
示例:以下查询请求的是tag key location的三个tag value对于的water_level的最小值。因为tag key location只有两个tag value(santa_monica和coyote_creek),所以该查询返回两个数据点而不是三个。
SELECT BOTTOM("water_level","location",3) FROM "h2o_feet"
name: h2o_feet
time bottom location
------------------
2015-08-29T10:36:00Z-0.243 santa_monica
2015-08-29T14:30:00Z-0.61 coyote_creek
问题三:BOTTOM()、tag和INTO子句
当使用INTO子句但没有使用GROUP BY tag子句时,大多数InfluxQL函数将原始数据中的tag转换为新写入数据中的field。这种行为同样适用于BOTTOM()函数除非BOTTOM()中包含tag key作为参数:BOTTOM(field_key,tag_key(s),N)。在这些情况下,系统会将指定的tag保留为新写入数据中的tag。
示例:下面代码块中的第一个查询返回tag key location的两个tag value对应的field key water_level的最小值,并且,它这些结果写入measurement bottom_water_levels中。第二个查询展示了InfluxDB将tag location保留为measurement bottom_water_levels中的tag。
> SELECT BOTTOM("water_level","location",2) INTO "bottom_water_levels" FROM "h2o_feet"
name: result
time written
-----------
1970-01-01T00:00:00Z2
> SHOW TAG KEYS FROM "bottom_water_levels"
name: bottom_water_levels
tagKey
------
location
FIRST()
返回具有最早时间戳的field value。
语法
SELECT FIRST(<field_key>)[,<tag_key(s)>|<field_key(s)>][INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
FIRST(field_key):返回field key对应的具有最早时间戳的field value。
FIRST(/regular_expression/):返回与正则表达式匹配的每个field key对应的具有最早时间戳的field value。
FIRST(*):返回在measurement中每个field key对应的具有最早时间戳的field value。
FIRST(field_key),tag_key(s),field_key(s):返回括号中的field key对应的具有最早时间戳的field value,以及相关的tag和/或field。
FIRST():支持所有数据类型的field value。
示例1:选择指定field key对应的具有最早时间戳的field value
SELECT FIRST("level description") FROM "h2o_feet"
name: h2o_feet
time first
---------
2015-08-18T00:00:00Z between 6 and 9 feet
该查询返回measurement h2o_feet中field key level description对应的具有最早时间戳的field value。
示例2:选择measurement中每个field key对应的具有最早时间戳的field value
SELECT FIRST(*) FROM "h2o_feet"
name: h2o_feet
time first_level description first_water_level
--------------------------------------------
1970-01-01T00:00:00Z between 6 and 9 feet 8.12
该查询返回measurement h2o_feet中每个field key对应的具有最早时间戳的field value。measurement h2o_feet中有两个field key:level description和water_level。
示例3:选择与正则表达式匹配的每个field key对应的具有最早时间戳的field value
SELECT FIRST(/level/) FROM "h2o_feet"
name: h2o_feet
time first_level description first_water_level
--------------------------------------------
1970-01-01T00:00:00Z between 6 and 9 feet 8.12
该查询返回measurement h2o_feet中每个包含单词level的field key对应的具有最早时间戳的field value。
示例4:选择指定field key对应的具有最早时间戳的field value以及相关的tag和field
SELECT FIRST("level description"),"location","water_level" FROM "h2o_feet"
name: h2o_feet
time first location water_level
----------------------------
2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12
该查询返回measurement h2o_feet中field key level description对应的具有最早时间戳的field value,以及相关的tag key location和field key water_level的值。
示例5:选择指定field key对应的具有最早时间戳的field value并包含多个子句
SELECT FIRST("water_level") FROM "h2o_feet" WHERE time >='2015-08-17T23:48:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(9.01) LIMIT 4 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time first
---------
2015-08-17T23:48:00Z9.01
2015-08-18T00:00:00Z8.12
2015-08-18T00:12:00Z7.887
2015-08-18T00:24:00Z7.635
该查询返回measurement h2o_feet中field key water_level对应的具有最早时间戳的field value,它涵盖的时间范围在2015-08-17T23:48:00Z和2015-08-18T00:54:00Z之间,并将查询结果按12分钟的时间间隔和每个tag进行分组,同时,该查询用9.01填充没有数据的时间间隔,并将返回的数据点个数和序列个数分别限制为4和1。
说明 GROUP BY time()子句会覆盖数据点的原始时间戳。查询结果中的时间戳表示每12分钟时间间隔的开始时间,其中,第一个数据点涵盖的时间间隔在2015-08-17T23:48:00Z和2015-08-18T00:00:00Z之间,最后一个数据点涵盖的时间间隔在2015-08-18T00:24:00Z和2015-08-18T00:36:00Z之间。
LAST()
返回具有最新时间戳的field value。
语法
SELECT LAST(<field_key>)[,<tag_key(s)>|<field_keys(s)>][INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
LAST(field_key):返回field key对应的具有最新时间戳的field value。
LAST(/regular_expression/):返回与正则表达式匹配的每个field key对应的具有最新时间戳的field value。
LAST(*):返回在measurement中每个field key对应的具有最新时间戳的field value。
LAST(field_key),tag_key(s),field_key(s):返回括号中的field key对应的具有最新时间戳的field value,以及相关的tag和/或field。
LAST():支持所有数据类型的field value。
示例1:选择指定field key对应的具有最新时间戳的field value
SELECT LAST("level description") FROM "h2o_feet"
name: h2o_feet
time last
--------
2015-09-18T21:42:00Z between 3 and 6 feet
该查询返回measurement h2o_feet中field key level description对应的具有最新时间戳的field value。
示例2:选择measurement中每个field key对应的具有最新时间戳的field value
SELECT LAST(*) FROM "h2o_feet"
name: h2o_feet
time last_level description last_water_level
--------------------------------------------
2015-09-18T21:42:00Z between 3 and 6 feet 4.938
该查询返回measurement h2o_feet中每个field key对应的具有最新时间戳的field value。measurement h2o_feet中有两个field key:level description和water_level。
示例3:选择与正则表达式匹配的每个field key对应的具有最新时间戳的field value
SELECT LAST(/level/) FROM "h2o_feet"
name: h2o_feet
time last_level description last_water_level
--------------------------------------------
2015-09-18T21:42:00Z between 3 and 6 feet 4.938
该查询返回measurement h2o_feet中每个包含单词level的field key对应的具有最新时间戳的field value。
示例4:选择指定field key对应的具有最新时间戳的field value以及相关的tag和field
SELECT LAST("level description"),"location","water_level" FROM "h2o_feet"
name: h2o_feet
time last location water_level
---------------------------
2015-09-18T21:42:00Z between 3 and 6 feet santa_monica 4.938
该查询返回measurement h2o_feet中field key level description对应的具有最新时间戳的field value,以及相关的tag key location和field key water_level的值。
示例5:选择指定field key对应的具有最新时间戳的field value并包含多个子句
SELECT LAST("water_level") FROM "h2o_feet" WHERE time >='2015-08-17T23:48:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(9.01) LIMIT 4 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time last
--------
2015-08-17T23:48:00Z9.01
2015-08-18T00:00:00Z8.005
2015-08-18T00:12:00Z7.762
2015-08-18T00:24:00Z7.5
该查询返回measurement h2o_feet中field key water_level对应的具有最新时间戳的field value,它涵盖的时间范围在2015-08-17T23:48:00Z和2015-08-18T00:54:00Z之间,并将查询结果按12分钟的时间间隔和每个tag进行分组,同时,该查询用9.01填充没有数据的时间间隔,并将返回的数据点个数和序列个数分别限制为4和1。
说明 GROUP BY time()子句会覆盖数据点的原始时间戳。查询结果中的时间戳表示每12分钟时间间隔的开始时间,其中,第一个数据点涵盖的时间间隔在2015-08-17T23:48:00Z和2015-08-18T00:00:00Z之间,最后一个数据点涵盖的时间间隔在2015-08-18T00:24:00Z和2015-08-18T00:36:00Z之间。
MAX()
返回field value的最大值。
语法
SELECT MAX(<field_key>)[,<tag_key(s)>|<field__key(s)>][INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
MAX(field_key):返回field key对应的field value的最大值。
MAX(/regular_expression/):返回与正则表达式匹配的每个field key对应的field value的最大值。
MAX(*):返回在measurement中每个field key对应的field value的最大值。
MAX(field_key),tag_key(s),field_key(s):返回括号中的field key对应的field value的最大值,以及相关的tag和/或field。
MAX():支持数据类型为int64和float64的field value。
示例1:选择指定field key对应的field value的最大值
SELECT MAX("water_level") FROM "h2o_feet"
name: h2o_feet
time max
-------
2015-08-29T07:24:00Z9.964
该查询返回measurement h2o_feet中field key water_level对应的field value的最大值。
示例2:选择measurement中每个field key对应的field value的最大值
SELECT MAX(*) FROM "h2o_feet"
name: h2o_feet
time max_water_level
-------------------
2015-08-29T07:24:00Z9.964
该查询返回measurement h2o_feet中每个存储数值的field key对应的field value的最大值。measurement h2o_feet中只有一个数值类型的field:water_level。
示例3:选择与正则表达式匹配的每个field key对应的field value的最大值
SELECT MAX(/water/) FROM "h2o_feet"
name: h2o_feet
time max_water_level
-------------------
2015-08-29T07:24:00Z9.964
该查询返回measurement h2o_feet中每个存储数值并包含单词water的field key对应的field value的最大值。
示例4:选择指定field key对应的field value的最大值以及相关的tag和field
SELECT MAX("water_level"),"location","level description" FROM "h2o_feet"
name: h2o_feet
time max location level description
--------------------------------
2015-08-29T07:24:00Z9.964 coyote_creek at or greater than 9 feet
该查询返回measurement h2o_feet中field key water_level对应的field value的最大值,以及相关的tag key location和field key level description的值。
示例5:选择指定field key对应的field value的最大值并包含多个子句
SELECT MAX("water_level") FROM "h2o_feet" WHERE time >='2015-08-17T23:48:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(9.01) LIMIT 4 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time max
-------
2015-08-17T23:48:00Z9.01
2015-08-18T00:00:00Z8.12
2015-08-18T00:12:00Z7.887
2015-08-18T00:24:00Z7.635
该查询返回measurement h2o_feet中field key water_level对应的field value的最大值,它涵盖的时间范围在2015-08-17T23:48:00Z和2015-08-18T00:54:00Z之间,并将查询结果按12分钟的时间间隔和每个tag进行分组,同时,该查询用9.01填充没有数据的时间间隔,并将返回的数据点个数和序列个数分别限制为4和1。
说明 GROUP BY time()子句会覆盖数据点的原始时间戳。查询结果中的时间戳表示每12分钟时间间隔的开始时间,其中,第一个数据点涵盖的时间间隔在2015-08-17T23:48:00Z和2015-08-18T00:00:00Z之间,最后一个数据点涵盖的时间间隔在2015-08-18T00:24:00Z和2015-08-18T00:36:00Z之间。
MIN()
返回field value的最小值。
语法
SELECT MIN(<field_key>)[,<tag_key(s)>|<field_key(s)>][INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
MIN(field_key):返回field key对应的field value的最小值。
MIN(/regular_expression/):返回与正则表达式匹配的每个field key对应的field value的最小值。
MIN(*):返回在measurement中每个field key对应的field value的最小值。
MIN(field_key),tag_key(s),field_key(s):返回括号中的field key对应的field value的最小值,以及相关的tag和/或field。
MIN():支持数据类型为int64和float64的field value。
示例1:选择指定field key对应的field value的最小值
SELECT MIN("water_level") FROM "h2o_feet"
name: h2o_feet
time min
-------
2015-08-29T14:30:00Z-0.61
该查询返回measurement h2o_feet中field key water_level对应的field value的最小值。
示例2:选择measurement中每个field key对应的field value的最小值
SELECT MIN(*) FROM "h2o_feet"
name: h2o_feet
time min_water_level
-------------------
2015-08-29T14:30:00Z-0.61
该查询返回measurement h2o_feet中每个存储数值的field key对应的field value的最小值。measurement h2o_feet中只有一个数值类型的field:water_level。
示例3:选择与正则表达式匹配的每个field key对应的field value的最小值
SELECT MIN(/water/) FROM "h2o_feet"
name: h2o_feet
time min_water_level
-------------------
2015-08-29T14:30:00Z-0.61
该查询返回measurement h2o_feet中每个存储数值并包含单词water的field key对应的field value的最小值。
示例4:选择指定field key对应的field value的最小值以及相关的tag和field
SELECT MIN("water_level"),"location","level description" FROM "h2o_feet"
name: h2o_feet
time min location level description
--------------------------------
2015-08-29T14:30:00Z-0.61 coyote_creek below 3 feet
该查询返回measurement h2o_feet中field key water_level对应的field value的最小值,以及相关的tag key location和field key level description的值。
示例5:选择指定field key对应的field value的最小值并包含多个子句
SELECT MIN("water_level") FROM "h2o_feet" WHERE time >='2015-08-17T23:48:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(12m),* fill(9.01) LIMIT 4 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time min
-------
2015-08-17T23:48:00Z9.01
2015-08-18T00:00:00Z8.005
2015-08-18T00:12:00Z7.762
2015-08-18T00:24:00Z7.5
该查询返回measurement h2o_feet中field key water_level对应的field value的最小值,它涵盖的时间范围在2015-08-17T23:48:00Z和2015-08-18T00:54:00Z之间,并将查询结果按12分钟的时间间隔和每个tag进行分组,同时,该查询用9.01填充没有数据的时间间隔,并将返回的数据点个数和序列个数分别限制为4和1。
说明 GROUP BY time()子句会覆盖数据点的原始时间戳。查询结果中的时间戳表示每12分钟时间间隔的开始时间,其中,第一个数据点涵盖的时间间隔在2015-08-17T23:48:00Z和2015-08-18T00:00:00Z之间,最后一个数据点涵盖的时间间隔在2015-08-18T00:24:00Z和2015-08-18T00:36:00Z之间。
PERCENTILE()
返回第N个百分位数的field value。
语法
SELECT PERCENTILE(<field_key>,)[,<tag_key(s)>|<field_key(s)>][INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
PERCENTILE(field_key,N):返回指定field key对应的第N个百分位数的field value。
PERCENTILE(/regular_expression/,N):返回与正则表达式匹配的每个field key对应的第N个百分位数的field value。
PERCENTILE(*,N):返回在measurement中每个field key对应的第N个百分位数的field value。
PERCENTILE(field_key,N),tag_key(s),field_key(s):返回括号中的field key对应的第N个百分位数的field value,以及相关的tag和/或field。N必须是0到100之间的整数或浮点数。PERCENTILE()支持数据类型为int64和float64的field value。
示例1:选择指定field key对应的第五个百分位数的field value
SELECT PERCENTILE("water_level",5) FROM "h2o_feet"
name: h2o_feet
time percentile
--------------
2015-08-31T03:42:00Z1.122
该查询返回的field value大于measurement h2o_feet中field key water_level对应的所有field value中的百分之五。
示例2:选择measurement中每个field key对应的第五个百分位数的field value
SELECT PERCENTILE(*,5) FROM "h2o_feet"
name: h2o_feet
time percentile_water_level
--------------------------
2015-08-31T03:42:00Z1.122
该查询返回的field value大于measurement h2o_feet中每个存储数值的field key对应的所有field value中的百分之五。measurement h2o_feet中只有一个数值类型的field:water_level。
示例3:选择与正则表达式匹配的每个field key对应的第五个百分位数的field value
SELECT PERCENTILE(/water/,5) FROM "h2o_feet"
name: h2o_feet
time percentile_water_level
--------------------------
2015-08-31T03:42:00Z1.122
该查询返回的field value大于measurement h2o_feet中每个存储数值并包含单词water的field key对应的所有field value中的百分之五。
示例4:选择指定field key对应的第五个百分位数的field value以及相关的tag和field
SELECT PERCENTILE("water_level",5),"location","level description" FROM "h2o_feet"
name: h2o_feet
time percentile location level description
---------------------------------------
2015-08-31T03:42:00Z1.122 coyote_creek below 3 feet
该查询返回的field value大于measurement h2o_feet中field key water_level对应的所有field value中的百分之五,以及相关的tag key location和field key level description的值。
示例五:选择指定field key对应的第20个百分位数的field value并包含多个子句
SELECT PERCENTILE("water_level",20) FROM "h2o_feet" WHERE time >='2015-08-17T23:48:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(24m) fill(15) LIMIT 2
name: h2o_feet
time percentile
--------------
2015-08-17T23:36:00Z15
2015-08-18T00:00:00Z2.064
该查询返回的field value大于measurement h2o_feet中field key water_level对应的所有field value中的百分之二十,它涵盖的时间范围在2015-08-17T23:48:00Z和2015-08-18T00:54:00Z之间,并将查询结果按24分钟的时间间隔进行分组,同时,该查询用15填充没有数据的时间间隔,并将返回的数据点个数限制为2。
说明 GROUP BY time()子句会覆盖数据点的原始时间戳。查询结果中的时间戳表示每24分钟时间间隔的开始时间,其中,第一个数据点涵盖的时间间隔在2015-08-17T23:36:00Z和2015-08-18T00:00:00Z之间,最后一个数据点涵盖的时间间隔在2015-08-18T00:00:00Z和2015-08-18T00:24:00Z之间。
PERCENTILE()的常见问题
问题一:PERCENTILE()与其它InfluxQL函数进行对比
-
PERCENTILE(<field_key>,100)相当于MAX(<field_key>)。
-
PERCENTILE(<field_key>, 50)近似于MEDIAN(<field_key>),除非field key包含的field value有偶数个,那么这时候MEDIAN()将返回两个中间值的平均数。
-
PERCENTILE(<field_key>,0)不等于MIN(<field_key>),PERCENTILE(<field_key>,0)会返回null。
SAMPLE()
返回包含N个field value的随机样本。SAMPLE()使用reservoir sampling来生成随机数据点。
语法
SELECT SAMPLE(<field_key>,)[,<tag_key(s)>|<field_key(s)>][INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
SAMPLE(field_key,N):返回指定field key对应的N个随机选择的field value。
SAMPLE(/regular_expression/,N):返回与正则表达式匹配的每个field key对应的N个随机选择的field value。
SAMPLE(*,N):返回在measurement中每个field key对应的N个随机选择的field value。
SAMPLE(field_key,N),tag_key(s),field_key(s):返回括号中的field key对应的N个随机选择的field value,以及相关的tag和/或field。N必须是整数。SAMPLE()支持所有数据类型的field value。
示例1:选择指定field key对应的field value的随机样本
SELECT SAMPLE("water_level",2) FROM "h2o_feet"
name: h2o_feet
time sample
----------
2015-09-09T21:48:00Z5.659
2015-09-18T10:00:00Z6.939
该查询返回measurement h2o_feet中field key water_level对应的两个随机选择的数据点。
示例2:选择measurement中每个field key对应的field value的随机样本
SELECT SAMPLE(*,2) FROM "h2o_feet"
name: h2o_feet
time sample_level description sample_water_level
----------------------------------------------
2015-08-25T17:06:00Z3.284
2015-09-03T04:30:00Z below 3 feet
2015-09-03T20:06:00Z between 3 and 6 feet
2015-09-08T21:54:00Z3.412
该查询返回measurement h2o_feet中每个field key对应的两个随机选择的数据点。measurement h2o_feet中有两个field key:level description和water_level。
示例3:选择与正则表达式匹配的每个field key对应的field value的随机样本
SELECT SAMPLE(/level/,2) FROM "h2o_feet"
name: h2o_feet
time sample_level description sample_water_level
----------------------------------------------
2015-08-30T05:54:00Z between 6 and 9 feet
2015-09-07T01:18:00Z7.854
2015-09-09T20:30:00Z7.32
2015-09-13T19:18:00Z between 3 and 6 feet
该查询返回measurement h2o_feet中每个包含单词level的field key对应的两个随机选择的数据点。
示例4:选择指定field key对应的field value的随机样本以及相关的tag和field
SELECT SAMPLE("water_level",2),"location","level description" FROM "h2o_feet"
name: h2o_feet
time sample location level description
-----------------------------------
2015-08-29T10:54:00Z5.689 coyote_creek between 3 and 6 feet
2015-09-08T15:48:00Z6.391 coyote_creek between 6 and 9 feet
该查询返回measurement h2o_feet中field key water_level对应的两个随机选择的数据点,以及相关的tag key location和field key level description的值。
示例5:选择指定field key对应field value的随机样本并包含多个子句
SELECT SAMPLE("water_level",1) FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica' GROUP BY time(18m)
name: h2o_feet
time sample
----------
2015-08-18T00:12:00Z2.028
2015-08-18T00:30:00Z2.051
该查询返回measurement h2o_feet中field key water_level对应的一个随机选择的数据点,它涵盖的时间范围在2015-08-18T00:00:00Z和2015-08-18T00:30:00Z之间,并将查询结果按18分钟的时间间隔进行分组。
说明 GROUP BY time()子句不会覆盖数据点的原始时间戳。
SAMPLE()的常见问题
问题一:SAMPLE()和GROUP BY time()子句同时使用
对于同时带有SAMPLE()和GROUP BY time()子句的查询,将返回每个GROUP BY time()时间间隔的指定个数(N)的数据点。对于大多数GROUP BY time()查询,返回的时间戳表示GROUP BY time()时间间隔的开始时间,但是,带有SAMPLE()函数的GROUP BY time()查询则不一样,它们保留原始数据点的时间戳。
示例:以下查询返回每18分钟GROUP BY time()间隔对应的两个随机选择的数据点。请注意,返回的时间戳是数据点的原始时间戳;它们不会被强制要求必须匹配GROUP BY time()间隔的开始时间。
SELECT SAMPLE("water_level",2) FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica' GROUP BY time(18m)
name: h2o_feet
time sample
----------
__
2015-08-18T00:06:00Z2.116|
2015-08-18T00:12:00Z2.028|<-------Randomly-selected points for the first time interval
--
__
2015-08-18T00:18:00Z2.126|
2015-08-18T00:30:00Z2.051|<-------Randomly-selected points for the second time interval
--
TOP()
返回最大的N个field value。
语法
SELECT TOP(<field_key>[,<tag_key(s)>],)[,<tag_key(s)>|<field_key(s)>][INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
语法说明
TOP(field_key,N):返回field key对应的最大的N个值。
TOP(field_key,tag_key(s),N):返回tag key的N个tag value对应的field key的最大值。
TOP(field_key,N),tag_key(s),field_key(s):返回括号中的field key对应的最大的N个值,以及相关的tag和/或field。
TOP():支持数据类型为int64和float64的field value。
说明 如果最大值有两个或多个并且它们之间有关联,TOP()返回具有最早时间戳的field value。 当TOP()函数与INTO子句一起使用时,TOP()与其它InfluxQL函数不同。
示例1:选择指定field key对应的最大的三个值
SELECT TOP("water_level",3) FROM "h2o_feet"
name: h2o_feet
time top
-------
2015-08-29T07:18:00Z9.957
2015-08-29T07:24:00Z9.964
2015-08-29T07:30:00Z9.954
该查询返回measurement h2o_feet中field key water_level对应的最大的三个值。
示例2:选择两个tag对应的field key的最大值
SELECT TOP("water_level","location",2) FROM "h2o_feet"
name: h2o_feet
time top location
---------------
2015-08-29T03:54:00Z7.205 santa_monica
2015-08-29T07:24:00Z9.964 coyote_creek
该查询返回tag key location的两个tag value对应的field key water_level的最大值。
示例3:选择指定field key对应的最大的四个值以及相关的tag和field
SELECT TOP("water_level",4),"location","level description" FROM "h2o_feet"
name: h2o_feet
time top location level description
--------------------------------
2015-08-29T07:18:00Z9.957 coyote_creek at or greater than 9 feet
2015-08-29T07:24:00Z9.964 coyote_creek at or greater than 9 feet
2015-08-29T07:30:00Z9.954 coyote_creek at or greater than 9 feet
2015-08-29T07:36:00Z9.941 coyote_creek at or greater than 9 feet
该查询返回field key water_level对应的最大的四个值,以及相关的tag key location和field key level description的值。
示例4:选择指定field key对应的最大的三个值并包含多个子句
SELECT TOP("water_level",3),"location" FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:54:00Z' GROUP BY time(24m) ORDER BY time DESC
name: h2o_feet
time top location
---------------
2015-08-18T00:48:00Z7.11 coyote_creek
2015-08-18T00:54:00Z6.982 coyote_creek
2015-08-18T00:54:00Z2.054 santa_monica
2015-08-18T00:24:00Z7.635 coyote_creek
2015-08-18T00:30:00Z7.5 coyote_creek
2015-08-18T00:36:00Z7.372 coyote_creek
2015-08-18T00:00:00Z8.12 coyote_creek
2015-08-18T00:06:00Z8.005 coyote_creek
2015-08-18T00:12:00Z7.887 coyote_creek
该查询返回在2015-08-18T00:00:00Z和2015-08-18T00:54:00Z之间的每个24分钟间隔内,field key water_level对应的最大的三个值,并且以递减的时间戳顺序返回结果。
说明 GROUP BY time()子句不会覆盖数据点的原始时间戳。
TOP()的常见问题
问题1:TOP()和GROUP BY time()子句同时使用
对于同时带有TOP()和GROUP BY time()子句的查询,将返回每个GROUP BY time()时间间隔的指定个数的数据点。对于大多数GROUP BY time()查询,返回的时间戳表示GROUP BY time()时间间隔的开始时间,但是,带有TOP()函数的GROUP BY time()查询则不一样,它们保留原始数据点的时间戳。
示例:以下查询返回每18分钟GROUP BY time()间隔对应的两个数据点。请注意,返回的时间戳是数据点的原始时间戳;它们不会被强制要求必须匹配GROUP BY time()间隔的开始时间。
SELECT TOP("water_level",2) FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica' GROUP BY time(18m)
name: h2o_feet
time top
----------
__
2015-08-18T00:00:00Z2.064|
2015-08-18T00:06:00Z2.116|<-------Greatest points for the first time interval
--
__
2015-08-18T00:18:00Z2.126|
2015-08-18T00:30:00Z2.051|<-------Greatest points for the second time interval
--
问题2:TOP()和具有少于N个tag value的tag key
使用语法SELECT TOP(<field_key>,<tag_key>,)的查询可以返回比预期少的数据点。如果tag key有X个tag value,但是查询指定的是N个tag value,如果X小于N,那么查询将返回X个数据点。
示例:以下查询请求的是tag key location的三个tag value对于的water_level的最大值。因为tag key location只有两个tag value(santa_monica和coyote_creek),所以该查询返回两个数据点而不是三个。
> SELECT TOP("water_level","location",3) FROM "h2o_feet"
name: h2o_feet
time top location
---------------
2015-08-29T03:54:00Z7.205 santa_monica
2015-08-29T07:24:00Z9.964 coyote_creek
问题3:TOP()、tag和INTO子句
当使用INTO子句但没有使用GROUP BY tag子句时,大多数InfluxQL函数将原始数据中的tag转换为新写入数据中的field。这种行为同样适用于TOP()函数,除非TOP()中包含tag key作为参数:TOP(field_key,tag_key(s),N)。在这些情况下,系统会将指定的tag保留为新写入数据中的tag。
示例:下面代码块中的第一个查询返回tag key location的两个tag value对应的field key water_level的最大值,并且,它这些结果写入measurement top_water_levels中。第二个查询展示了TSDB For InfluxDB®将tag location保留为measurement top_water_levels中的tag。
SELECT TOP("water_level","location",2) INTO "top_water_levels" FROM "h2o_feet"
name: result
time written
-----------
1970-01-01T00:00:00Z2
> SHOW TAG KEYS FROM "top_water_levels"
name: top_water_levels
tagKey
------
location
3.3 转换函数
本文档主要介绍了转换函数(Transformations)的语法结构、语法说明以及使用示例。
ABS()
返回field value的绝对值。
基本语法
SELECT ABS([*|<field_key>])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
基本语法说明
ABS(field_key):返回field key对应的field value的绝对值。
ABS(*):返回在measurement中每个field key对应的field value的绝对值。
ABS():支持数据类型为int64和float64的field value。
基本语法支持group by tags的GROUP BY子句,但是不支持group by time。
基本语法示例1:计算指定field key对应的field value的绝对值
SELECT ABS("a") FROM "data" WHERE time >='2018-06-24T12:00:00Z' AND time <='2018-06-24T12:05:00Z'
name: data
time abs
-------
15298416000000000001.33909108671076
15298416600000000000.774984088561186
15298417200000000000.921037167720451
15298417800000000001.73880754843378
15298418400000000000.905980032168252
15298419000000000000.891164752631417
该查询返回measurement data中field key a对应的field value的绝对值。
基本语法示例2:计算measurement中每个field key对应的field value的绝对值
SELECT ABS(*) FROM "data" WHERE time >='2018-06-24T12:00:00Z' AND time <='2018-06-24T12:05:00Z'
name: data
time abs_a abs_b
--------------
15298416000000000001.339091086710760.163643058925645
15298416600000000000.7749840885611860.137034364053949
15298417200000000000.9210371677204510.482943221384294
15298417800000000001.738807548433780.0729732928756677
15298418400000000000.9059800321682521.77857552719844
15298419000000000000.8911647526314170.741147445214238
该查询返回measurement data中每个存储数值的field key对应的field value的绝对值。measurement data中有两个数值类型的field:a和b。
基本语法示例3:计算指定field key对应的field value的绝对值并包含多个子句
SELECT ABS("a") FROM "data" WHERE time >='2018-06-24T12:00:00Z' AND time <='2018-06-24T12:05:00Z' ORDER BY time DESC LIMIT 4 OFFSET 2
name: data
time abs
-------
15298417800000000001.73880754843378
15298417200000000000.921037167720451
15298416600000000000.774984088561186
15298416000000000001.33909108671076
该查询返回measurement data中field key a对应的field value的绝对值,它涵盖的时间范围在2018-06-24T12:00:00Z和2018-06-24T12:05:00Z之间,并且以递减的时间戳顺序返回结果,同时,该查询将返回的数据点个数限制为4,并将返回的数据点偏移两个(即前两个数据点不返回)。
高级语法
SELECT ABS(([*|<field_key>]))[INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
高级语法描述
高级语法需要一个GROUP BY time()子句和一个嵌套的InfluxQL函数。查询首先计算在指定的GROUP BY time()间隔内嵌套函数的结果,然后计算这些结果的绝对值。
ABS()支持以下嵌套函数:
-
COUNT()
-
MEAN()
-
MEDIAN()
-
MODE()
-
SUM()
-
FIRST()
-
LAST()
-
MIN()
-
MAX()
-
PERCENTILE()
高级语法示例:计算平均值的绝对值
SELECT ABS(MEAN("a")) FROM "data" WHERE time >='2018-06-24T12:00:00Z' AND time <='2018-06-24T13:00:00Z' GROUP BY time(12m)
time abs
-------
15298416000000000000.3960977256302787
15298423200000000000.0010541018316373302
15298430400000000000.04494733240283668
15298437600000000000.2553594777104415
15298444800000000000.20382988543108413
15298452000000000000.790836070736962
该查询返回field key a对应的每12分钟的时间间隔的field value的平均值的绝对值。
为了得到这些结果,TSDB For InfluxDB®首先计算field key a对应的每12分钟的时间间隔的field value的平均值。这一步跟同时使用MEAN()函数和GROUP BY time()子句、但不使用ABS()的情形一样:
SELECT MEAN("a") FROM "data" WHERE time >='2018-06-24T12:00:00Z' AND time <='2018-06-24T13:00:00Z' GROUP BY time(12m)
name: data
time mean
--------
1529841600000000000-0.3960977256302787
15298423200000000000.0010541018316373302
15298430400000000000.04494733240283668
15298437600000000000.2553594777104415
15298444800000000000.20382988543108413
1529845200000000000-0.790836070736962
然后,InfluxDB计算这些平均值的绝对值。
ACOS()
返回field value的反余弦(以弧度表示)。field value必须在-1和1之间。
基本语法
SELECT ACOS([*|<field_key>])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
基本语法说明
-
ACOS(field_key):返回field key对应的field value的反余弦。
-
ACOS(*):返回在measurement中每个field key对应的field value的反余弦。
-
ACOS():支持数据类型为int64和float64的field value,并且field value必须在-1和1之间。
基本语法支持group by tags的GROUP BY子句,但是不支持group by time。请查看高级语法章节了解如何使用ACOS()和GROUP BY time()子句。
基本语法示例
下面的示例将使用如下模拟的公园占有率(相对于总空间)的数据。需要注意的重要事项是,所有的field value都在ACOS()函数的可计算范围里(-1到1):
SELECT "of_capacity" FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z'
name: park_occupancy
time capacity
------------
2017-05-01T00:00:00Z0.83
2017-05-02T00:00:00Z0.3
2017-05-03T00:00:00Z0.84
2017-05-04T00:00:00Z0.22
2017-05-05T00:00:00Z0.17
2017-05-06T00:00:00Z0.77
2017-05-07T00:00:00Z0.64
2017-05-08T00:00:00Z0.72
2017-05-09T00:00:00Z0.16
示例1:计算指定field key对应的field value的反余弦
SELECT ACOS("of_capacity") FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z'
name: park_occupancy
time acos
--------
2017-05-01T00:00:00Z0.591688642426544
2017-05-02T00:00:00Z1.266103672779499
2017-05-03T00:00:00Z0.5735131044230969
2017-05-04T00:00:00Z1.3489818562981022
2017-05-05T00:00:00Z1.399966657665792
2017-05-06T00:00:00Z0.6919551751263169
2017-05-07T00:00:00Z0.8762980611683406
2017-05-08T00:00:00Z0.7669940078618667
2017-05-09T00:00:00Z1.410105673842986
该查询返回measurement park_occupancy中field key of_capacity对应的field value的反余弦。
示例2:计算measurement中每个field key对应的field value的反余弦
SELECT ACOS(*) FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z'
name: park_occupancy
time acos_of_capacity
-----------------
2017-05-01T00:00:00Z0.591688642426544
2017-05-02T00:00:00Z1.266103672779499
2017-05-03T00:00:00Z0.5735131044230969
2017-05-04T00:00:00Z1.3489818562981022
2017-05-05T00:00:00Z1.399966657665792
2017-05-06T00:00:00Z0.6919551751263169
2017-05-07T00:00:00Z0.8762980611683406
2017-05-08T00:00:00Z0.7669940078618667
2017-05-09T00:00:00Z1.410105673842986
该查询返回measurement park_occupancy中每个存储数值的field key对应的field value的反余弦。measurement park_occupancy中只有一个数值类型的field:of_capacity。
示例3:计算指定field key对应的field value的反余弦并包含多个子句
SELECT ACOS("of_capacity") FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z' ORDER BY time DESC LIMIT 4 OFFSET 2
name: park_occupancy
time acos
--------
2017-05-07T00:00:00Z0.8762980611683406
2017-05-06T00:00:00Z0.6919551751263169
2017-05-05T00:00:00Z1.399966657665792
2017-05-04T00:00:00Z1.3489818562981022
该查询返回measurement park_occupancy中field key of_capacity对应的field value的反余弦,它涵盖的时间范围在2017-05-01T00:00:00Z和2017-05-09T00:00:00Z之间,并且以递减的时间戳顺序返回结果,同时,该查询将返回的数据点个数限制为4,并将返回的数据点偏移两个(即前两个数据点不返回)。
高级语法
SELECT ACOS(([*|<field_key>]))[INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
高级语法说明
高级语法需要一个GROUP BY time()子句和一个嵌套的InfluxQL函数。查询首先计算在指定的GROUP BY time()间隔内嵌套函数的结果,然后计算这些结果的反余弦。
ACOS()支持以下嵌套函数:
-
COUNT()
-
MEAN()
-
MEDIAN()
-
MODE()
-
SUM()
-
FIRST()
-
LAST()
-
MIN()
-
MAX()
-
PERCENTILE()
高级语法示例:计算平均值的反余弦
SELECT ACOS(MEAN("of_capacity")) FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z' GROUP BY time(3d)
name: park_occupancy
time acos
--------
2017-04-30T00:00:00Z0.9703630732143733
2017-05-03T00:00:00Z1.1483422646081407
2017-05-06T00:00:00Z0.7812981174487247
2017-05-09T00:00:00Z1.410105673842986
该查询返回field key of_capacity对应的每三天的时间间隔的field value的平均值的反余弦。
为了得到这些结果,InfluxDB®首先计算field key of_capacity对应的每三天的时间间隔的field value的平均值。这一步跟同时使用MEAN()函数和GROUP BY time()子句、但不使用ACOS()的情形一样:
SELECT MEAN("of_capacity") FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z' GROUP BY time(3d)
name: park_occupancy
time mean
--------
2017-04-30T00:00:00Z0.565
2017-05-03T00:00:00Z0.41
2017-05-06T00:00:00Z0.71
2017-05-09T00:00:00Z0.16
然后,InfluxDB®计算这些平均值的反余弦。
ASIN()
返回field value的反正弦(以弧度表示)。field value必须在-1和1之间。
基本语法
SELECT ASIN([*|<field_key>])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
基本语法说明
-
ASIN(field_key):返回field key对应的field value的反正弦。
-
ASIN(*):返回在measurement中每个field key对应的field value的反正弦。
-
ASIN():支持数据类型为int64和float64的field value,并且field value必须在-1和1之间。
基本语法支持group by tags的GROUP BY子句,但是不支持group by time。请查看高级语法章节了解如何使用ASIN()和GROUP BY time()子句。
基本语法示例
下面的示例将使用如下模拟的公园占有率(相对于总空间)的数据。需要注意的重要事项是,所有的field value都在ASIN()函数的可计算范围里(-1到1):
> SELECT "of_capacity" FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z'
name: park_occupancy
time capacity
------------
2017-05-01T00:00:00Z0.83
2017-05-02T00:00:00Z0.3
2017-05-03T00:00:00Z0.84
2017-05-04T00:00:00Z0.22
2017-05-05T00:00:00Z0.17
2017-05-06T00:00:00Z0.77
2017-05-07T00:00:00Z0.64
2017-05-08T00:00:00Z0.72
2017-05-09T00:00:00Z0.16
示例1:计算指定field key对应的field value的反正弦
SELECT ASIN("of_capacity") FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z'
name: park_occupancy
time asin
--------
2017-05-01T00:00:00Z0.9791076843683526
2017-05-02T00:00:00Z0.3046926540153975
2017-05-03T00:00:00Z0.9972832223717997
2017-05-04T00:00:00Z0.22181447049679442
2017-05-05T00:00:00Z0.1708296691291045
2017-05-06T00:00:00Z0.8788411516685797
2017-05-07T00:00:00Z0.6944982656265559
2017-05-08T00:00:00Z0.8038023189330299
2017-05-09T00:00:00Z0.1606906529519106
该查询返回measurement park_occupancy中field key of_capacity对应的field value的反正弦。
示例2:计算measurement中每个field key对应的field value的反正弦
SELECT ASIN(*) FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z'
name: park_occupancy
time asin_of_capacity
-----------------
2017-05-01T00:00:00Z0.9791076843683526
2017-05-02T00:00:00Z0.3046926540153975
2017-05-03T00:00:00Z0.9972832223717997
2017-05-04T00:00:00Z0.22181447049679442
2017-05-05T00:00:00Z0.1708296691291045
2017-05-06T00:00:00Z0.8788411516685797
2017-05-07T00:00:00Z0.6944982656265559
2017-05-08T00:00:00Z0.8038023189330299
2017-05-09T00:00:00Z0.1606906529519106
该查询返回measurement park_occupancy中每个存储数值的field key对应的field value的反正弦。measurement park_occupancy中只有一个数值类型的field:of_capacity。
示例3:计算指定field key对应的field value的反正弦并包含多个子句
SELECT ASIN("of_capacity") FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z' ORDER BY time DESC LIMIT 4 OFFSET 2
name: park_occupancy
time asin
--------
2017-05-07T00:00:00Z0.6944982656265559
2017-05-06T00:00:00Z0.8788411516685797
2017-05-05T00:00:00Z0.1708296691291045
2017-05-04T00:00:00Z0.22181447049679442
该查询返回measurement park_occupancy中field key of_capacity对应的field value的反正弦,它涵盖的时间范围在2017-05-01T00:00:00Z和2017-05-09T00:00:00Z之间,并且以递减的时间戳顺序返回结果,同时,该查询将返回的数据点个数限制为4,并将返回的数据点偏移两个(即前两个数据点不返回)。
高级语法
SELECT ASIN(([*|<field_key>]))[INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
高级语法说明
高级语法需要一个GROUP BY time()子句和一个嵌套的InfluxQL函数。查询首先计算在指定的GROUP BY time()间隔内嵌套函数的结果,然后计算这些结果的反正弦。
ASIN()支持以下嵌套函数:
-
COUNT()
-
MEAN()
-
MEDIAN()
-
MODE()
-
SUM()
-
FIRST()
-
LAST()
-
MIN()
-
MAX()
-
PERCENTILE()
高级语法示例:计算平均值的反正弦
> SELECT ASIN(MEAN("of_capacity")) FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z' GROUP BY time(3d)
name: park_occupancy
time asin
--------
2017-04-30T00:00:00Z0.6004332535805232
2017-05-03T00:00:00Z0.42245406218675574
2017-05-06T00:00:00Z0.7894982093461719
2017-05-09T00:00:00Z0.1606906529519106
该查询返回field key of_capacity对应的每三天的时间间隔的field value的平均值的反正弦。
为了得到这些结果,InfluxDB®首先计算field key of_capacity对应的每三天的时间间隔的field value的平均值。这一步跟同时使用MEAN()函数和GROUP BY time()子句、但不使用ASIN()的情形一样:
> SELECT MEAN("of_capacity") FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z' GROUP BY time(3d)
name: park_occupancy
time mean
--------
2017-04-30T00:00:00Z0.565
2017-05-03T00:00:00Z0.41
2017-05-06T00:00:00Z0.71
2017-05-09T00:00:00Z0.16
然后,InfluxDB®计算这些平均值的反正弦。
ATAN()
返回field value的反正切(以弧度表示)。field value必须在-1和1之间。
基本语法
SELECT ATAN([*|<field_key>])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
基本语法说明
-
ATAN(field_key):返回field key对应的field value的反正切。
-
ATAN(*):返回在measurement中每个field key对应的field value的反正切。
-
ATAN():支持数据类型为int64和float64的field value,并且field value必须在-1和1之间。
基本语法支持group by tags的GROUP BY子句,但是不支持group by time。请查看高级语法章节了解如何使用ATAN()和GROUP BY time()子句。
基本语法示例
下面的示例将使用如下模拟的公园占有率(相对于总空间)的数据。需要注意的重要事项是,所有的field value都在ATAN()函数的可计算范围里(-1到1):
> SELECT "of_capacity" FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z'
name: park_occupancy
time capacity
------------
2017-05-01T00:00:00Z0.83
2017-05-02T00:00:00Z0.3
2017-05-03T00:00:00Z0.84
2017-05-04T00:00:00Z0.22
2017-05-05T00:00:00Z0.17
2017-05-06T00:00:00Z0.77
2017-05-07T00:00:00Z0.64
2017-05-08T00:00:00Z0.72
2017-05-09T00:00:00Z0.16
示例1:计算指定field key对应的field value的反正切
SELECT ATAN("of_capacity") FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z'
name: park_occupancy
time atan
--------
2017-05-01T00:00:00Z0.6927678353971222
2017-05-02T00:00:00Z0.2914567944778671
2017-05-03T00:00:00Z0.6986598247214632
2017-05-04T00:00:00Z0.2165503049760893
2017-05-05T00:00:00Z0.16839015714752992
2017-05-06T00:00:00Z0.6561787179913948
2017-05-07T00:00:00Z0.5693131911006619
2017-05-08T00:00:00Z0.6240230529767568
2017-05-09T00:00:00Z0.1586552621864014
该查询返回measurement park_occupancy中field key of_capacity对应的field value的反正切。
示例2:计算measurement中每个field key对应的field value的反正切
SELECT ATAN(*) FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z'
name: park_occupancy
time atan_of_capacity
-----------------
2017-05-01T00:00:00Z0.6927678353971222
2017-05-02T00:00:00Z0.2914567944778671
2017-05-03T00:00:00Z0.6986598247214632
2017-05-04T00:00:00Z0.2165503049760893
2017-05-05T00:00:00Z0.16839015714752992
2017-05-06T00:00:00Z0.6561787179913948
2017-05-07T00:00:00Z0.5693131911006619
2017-05-08T00:00:00Z0.6240230529767568
2017-05-09T00:00:00Z0.1586552621864014
该查询返回measurement park_occupancy中每个存储数值的field key对应的field value的反正切。measurement park_occupancy中只有一个数值类型的field:of_capacity。
示例3:计算指定field key对应的field value的反正切并包含多个子句
SELECT ATAN("of_capacity") FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z' ORDER BY time DESC LIMIT 4 OFFSET 2
name: park_occupancy
time atan
--------
2017-05-07T00:00:00Z0.5693131911006619
2017-05-06T00:00:00Z0.6561787179913948
2017-05-05T00:00:00Z0.16839015714752992
2017-05-04T00:00:00Z0.2165503049760893
该查询返回measurement park_occupancy中field key of_capacity对应的field value的反正切,它涵盖的时间范围在2017-05-01T00:00:00Z和2017-05-09T00:00:00Z之间,并且以递减的时间戳顺序返回结果,同时,该查询将返回的数据点个数限制为4,并将返回的数据点偏移两个(即前两个数据点不返回)。
高级语法
SELECT ATAN(([*|<field_key>]))[INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
高级语法说明
高级语法需要一个GROUP BY time()子句和一个嵌套的InfluxQL函数。查询首先计算在指定的GROUP BY time()间隔内嵌套函数的结果,然后计算这些结果的反正切。
ATAN()支持以下嵌套函数:
-
COUNT()
-
MEAN()
-
MEDIAN()
-
MODE()
-
SUM()
-
FIRST()
-
LAST()
-
MIN()
-
MAX()
-
PERCENTILE()
高级语法示例:计算平均值的反正切
> SELECT ATAN(MEAN("of_capacity")) FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z' GROUP BY time(3d)
name: park_occupancy
time atan
--------
2017-04-30T00:00:00Z0.5142865412694495
2017-05-03T00:00:00Z0.3890972310552784
2017-05-06T00:00:00Z0.6174058917515726
2017-05-09T00:00:00Z0.1586552621864014
该查询返回field key of_capacity对应的每三天的时间间隔的field value的平均值的反正切。
为了得到这些结果,InfluxDB®首先计算field key of_capacity对应的每三天的时间间隔的field value的平均值。这一步跟同时使用MEAN()函数和GROUP BY time()子句、但不使用ATAN()的情形一样:
> SELECT MEAN("of_capacity") FROM "park_occupancy" WHERE time >='2017-05-01T00:00:00Z' AND time <='2017-05-09T00:00:00Z' GROUP BY time(3d)
name: park_occupancy
time mean
--------
2017-04-30T00:00:00Z0.565
2017-05-03T00:00:00Z0.41
2017-05-06T00:00:00Z0.71
2017-05-09T00:00:00Z0.16
然后,InfluxDB®计算这些平均值的反正切。
ATAN2()
返回以弧度表示的y/x的反正切。
基本语法
SELECT ATAN2([*|<field_key>| num ],[<field_key>| num ])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
基本语法说明
-
ATAN2(field_key_y, field_key_x)返回field key “field_key_y”对应的field value除以field key “field_key_x”对应的field value的反正切。
-
ATAN2(*, field_key_x)
返回在measurement中每个field key对应的field value除以field key “field_key_x”对应的field value的反正切。 -
ATAN2()支持数据类型为int64和float64的field value。
基本语法支持group by tags的GROUP BY子句,但是不支持group by time。请查看高级语法章节了解如何使用ATAN2()和GROUP BY time()子句。
基本语法示例
下面的示例将使用如下模拟的飞行数据:
> SELECT "altitude_ft","distance_ft" FROM "flight_data" WHERE time >='2018-05-16T12:01:00Z' AND time <='2018-05-16T12:10:00Z'
name: flight_data
time altitude_ft distance_ft
--------------------------
2018-05-16T12:01:00Z102650094
2018-05-16T12:02:00Z254953576
2018-05-16T12:03:00Z403355208
2018-05-16T12:04:00Z557958579
2018-05-16T12:05:00Z706561213
2018-05-16T12:06:00Z858964807
2018-05-16T12:07:00Z1018067707
2018-05-16T12:08:00Z1177769819
2018-05-16T12:09:00Z1332172452
2018-05-16T12:10:00Z1488575881
示例一:计算field_key_y除以field_key_x的反正切
> SELECT ATAN2("altitude_ft","distance_ft") FROM "flight_data" WHERE time >='2018-05-16T12:01:00Z' AND time <='2018-05-16T12:10:00Z'
name: flight_data
time atan2
---------
2018-05-16T12:01:00Z0.020478631571881498
2018-05-16T12:02:00Z0.04754142349303296
2018-05-16T12:03:00Z0.07292147724575364
2018-05-16T12:04:00Z0.09495251193874832
2018-05-16T12:05:00Z0.11490822875441563
2018-05-16T12:06:00Z0.13176409347584003
2018-05-16T12:07:00Z0.14923587589682233
2018-05-16T12:08:00Z0.1671059946640312
2018-05-16T12:09:00Z0.18182893717409565
2018-05-16T12:10:00Z0.1937028631495223
该查询返回field key altitude_ft对应的field value除以field key distance_ft对应的field value的反正切。这两个field key都在measurement flight_data中。
示例二:计算measurement中每个field key除以field_key_x的反正切
> SELECT ATAN2(*,"distance_ft") FROM "flight_data" WHERE time >='2018-05-16T12:01:00Z' AND time <='2018-05-16T12:10:00Z'
name: flight_data
time atan2_altitude_ft atan2_distance_ft
--------------------------------------
2018-05-16T12:01:00Z0.0204786315718814980.7853981633974483
2018-05-16T12:02:00Z0.047541423493032960.7853981633974483
2018-05-16T12:03:00Z0.072921477245753640.7853981633974483
2018-05-16T12:04:00Z0.094952511938748320.7853981633974483
2018-05-16T12:05:00Z0.114908228754415630.7853981633974483
2018-05-16T12:06:00Z0.131764093475840030.7853981633974483
2018-05-16T12:07:00Z0.149235875896822330.7853981633974483
2018-05-16T12:08:00Z0.16710599466403120.7853981633974483
2018-05-16T12:09:00Z0.181828937174095650.7853981633974483
2018-05-16T12:10:00Z0.193702863149522340.7853981633974483
该查询返回measurement flight_data中每个存储数值的field key对应的field value除以field key distance_ft对应的field value的反正切。measurement flight_data中有两个数值类型的field:altitude_ft和distance_ft。
示例三:计算field value的反正切并包含多个子句
> SELECT ATAN2("altitude_ft","distance_ft") FROM "flight_data" WHERE time >='2018-05-16T12:01:00Z' AND time <='2018-05-16T12:10:00Z' ORDER BY time DESC LIMIT 4 OFFSET 2
name: flight_data
time atan2
---------
2018-05-16T12:08:00Z0.1671059946640312
2018-05-16T12:07:00Z0.14923587589682233
2018-05-16T12:06:00Z0.13176409347584003
2018-05-16T12:05:00Z0.11490822875441563
该查询返回field key altitude_ft对应的field value除以field key distance_ft对应的field value的反正切,它涵盖的时间范围在2018-05-16T12:10:00Z和2018-05-16T12:10:00Z之间,并且以递减的时间戳顺序返回结果,同时,该查询将返回的数据点个数限制为4,并将返回的数据点偏移两个(即前两个数据点不返回)。
**** 高级语法
SELECT ATAN2(<function()>,<function()>)[INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
高级语法说明
高级语法需要一个GROUP BY time()子句和一个嵌套的InfluxQL函数。查询首先计算在指定的GROUP BY time()间隔内嵌套函数的结果,然后计算这些结果的反正切(ATAN2())。
ATAN2()支持以下嵌套函数:
-
COUNT()
-
MEAN()
-
MEDIAN()
-
MODE()
-
SUM()
-
FIRST()
-
LAST()
-
MIN()
-
MAX()
-
PERCENTILE()
高级语法示例:计算平均值的反正切
> SELECT ATAN2(MEAN("altitude_ft"), MEAN("distance_ft")) FROM "flight_data" WHERE time >='2018-05-16T12:01:00Z' AND time <='2018-05-16T13:01:00Z' GROUP BY time(12m)
name: flight_data
time atan2
---------
2018-05-16T12:00:00Z0.133815587896842
2018-05-16T12:12:00Z0.2662716308351908
2018-05-16T12:24:00Z0.2958845306108965
2018-05-16T12:36:00Z0.23783439588429497
2018-05-16T12:48:00Z0.1906803720242831
2018-05-16T13:00:00Z0.17291511946158172
该查询返回field key altitude_ft对应的field value的平均值除以field key distance_ft对应的field value的平均值的反正切。平均值是按每12分钟的时间间隔计算的。
为了得到这些结果,InfluxDB®首先计算field key altitude_ft和distance_ft对应的每12分钟的时间间隔的field value的平均值。这一步跟同时使用MEAN()函数和GROUP BY time()子句、但不使用ATAN2()的情形一样:
> SELECT MEAN("altitude_ft"), MEAN("distance_ft") FROM "flight_data" WHERE time >='2018-05-16T12:01:00Z' AND time <='2018-05-16T13:01:00Z' GROUP BY time(12m)
name: flight_data
time mean mean_1
--------------
2018-05-16T12:00:00Z867464433.181818181816
2018-05-16T12:12:00Z26419.83333333333296865.25
2018-05-16T12:24:00Z40337.416666666664132326.41666666666
2018-05-16T12:36:00Z41149.583333333336169743.16666666666
2018-05-16T12:48:00Z41230.416666666664213600.91666666666
2018-05-16T13:00:00Z41184.5235799
然后,InfluxDB®计算这些平均值的反正切。
CEIL()
返回大于指定值的最小整数。
基本语法
SELECT CEIL([*|<field_key>])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
基本语法说明
-
CEIL(field_key)返回field key对应的大于field value的最小整数。
-
CEIL(*)返回在measurement中每个field key对应的大于field value的最小整数。
-
CEIL()支持数据类型为int64和float64的field value。
基本语法支持group by tags的GROUP BY子句,但是不支持group by time。请查看高级语法章节了解如何使用CEIL()和GROUP BY time()子句。
基本语法示例
下面的示例将使用NOAA_water_database数据集的如下数据:
> SELECT "water_level" FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica'
name: h2o_feet
time water_level
---------------
2015-08-18T00:00:00Z2.064
2015-08-18T00:06:00Z2.116
2015-08-18T00:12:00Z2.028
2015-08-18T00:18:00Z2.126
2015-08-18T00:24:00Z2.041
2015-08-18T00:30:00Z2.051
示例一:计算指定field key对应的大于field value的最小整数
> SELECT CEIL("water_level") FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica'
name: h2o_feet
time ceil
--------
2015-08-18T00:00:00Z3
2015-08-18T00:06:00Z3
2015-08-18T00:12:00Z3
2015-08-18T00:18:00Z3
2015-08-18T00:24:00Z3
2015-08-18T00:30:00Z3
该查询返回measurement h2o_feet中field key water_level对应的大于field value的最小整数。
示例二:计算measurement中每个field key对应的大于field value的最小整数
> SELECT CEIL(*) FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica'
name: h2o_feet
time ceil_water_level
--------------------
2015-08-18T00:00:00Z3
2015-08-18T00:06:00Z3
2015-08-18T00:12:00Z3
2015-08-18T00:18:00Z3
2015-08-18T00:24:00Z3
2015-08-18T00:30:00Z3
该查询返回measurement h2o_feet中每个存储数值的field key对应的大于field value的最小整数。measurement h2o_feet只有一个数值类型的field:water_level。
示例三:计算指定field key对应的大于field value的最小整数并包含多个子句
> SELECT CEIL("water_level") FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica' ORDER BY time DESC LIMIT 4 OFFSET 2
name: h2o_feet
time ceil
--------
2015-08-18T00:18:00Z3
2015-08-18T00:12:00Z3
2015-08-18T00:06:00Z3
2015-08-18T00:00:00Z3
该查询返回field key water_level对应的大于field value的最小整数,它涵盖的时间范围在2015-08-18T00:00:00Z和2015-08-18T00:30:00Z之间,并且以递减的时间戳顺序返回结果,同时,该查询将返回的数据点个数限制为4,并将返回的数据点偏移两个(即前两个数据点不返回)。
高级语法
SELECT CEIL(([*|<field_key>|/<regular_expression>/]))[INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
高级语法描述
高级语法需要一个GROUP BY time()子句和一个嵌套的InfluxQL函数。查询首先计算在指定的GROUP BY time()间隔内嵌套函数的结果,然后将CEIL()应用于这些结果。
CEIL()支持以下嵌套函数:
-
COUNT()
-
MEAN()
-
MEDIAN()
-
MODE()
-
SUM()
-
FIRST()
-
LAST()
-
MIN()
-
MAX()
-
PERCENTILE()
高级语法示例:计算大于平均值的最小整数
> SELECT CEIL(MEAN("water_level")) FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica' GROUP BY time(12m)
name: h2o_feet
time ceil
--------
2015-08-18T00:00:00Z3
2015-08-18T00:12:00Z3
2015-08-18T00:24:00Z3
该查询返回每12分钟的时间间隔对应的大于water_level平均值的最小整数。
为了得到这些结果,InfluxDB®首先计算每12分钟的时间间隔对应的大于water_level的平均值。这一步跟同时使用MEAN()函数和GROUP BY time()子句、但不使用CEIL()的情形一样:
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica' GROUP BY time(12m)
name: h2o_feet
time mean
--------
2015-08-18T00:00:00Z2.09
2015-08-18T00:12:00Z2.077
2015-08-18T00:24:00Z2.0460000000000003
然后,InfluxDB®计算大于这些平均值的最小整数。
COS()
返回field value的余弦值。
基本语法
SELECT COS([*|<field_key>])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
基本语法说明
-
COS(field_key)返回field key对应的field value的余弦值。
-
COS(*)返回在measurement中每个field key对应的field value的余弦值。
-
COS()支持数据类型为int64和float64的field value。
基本语法支持group by tags的GROUP BY子句,但是不支持group by time。请查看高级语法章节了解如何使用COS()和GROUP BY time()子句。
基本语法示例
下面的示例将使用NOAA_water_database数据集的如下数据:
> SELECT "water_level" FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica'
name: h2o_feet
time water_level
---------------
2015-08-18T00:00:00Z2.064
2015-08-18T00:06:00Z2.116
2015-08-18T00:12:00Z2.028
2015-08-18T00:18:00Z2.126
2015-08-18T00:24:00Z2.041
2015-08-18T00:30:00Z2.051
示例一:计算指定field key对应的field value的余弦值
> SELECT COS("water_level") FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica'
name: h2o_feet
time cos
-------
2015-08-18T00:00:00Z-0.47345017433543124
2015-08-18T00:06:00Z-0.5185922462666872
2015-08-18T00:12:00Z-0.4414407189100776
2015-08-18T00:18:00Z-0.5271163912192579
2015-08-18T00:24:00Z-0.45306786455514825
2015-08-18T00:30:00Z-0.4619598230611262
该查询返回measurement h2o_feet中field key water_level对应的field value的余弦值。
示例二:计算measurement中每个field key对应的field value的余弦值
> SELECT COS(*) FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica'
name: h2o_feet
time cos_water_level
-------------------
2015-08-18T00:00:00Z-0.47345017433543124
2015-08-18T00:06:00Z-0.5185922462666872
2015-08-18T00:12:00Z-0.4414407189100776
2015-08-18T00:18:00Z-0.5271163912192579
2015-08-18T00:24:00Z-0.45306786455514825
2015-08-18T00:30:00Z-0.4619598230611262
该查询返回measurement h2o_feet中每个存储数值的field key对应的field value的余弦值。measurement h2o_feet中只有一个数值类型的field:water_level。
COS()
返回field value的余弦值。
基本语法
SELECT COS([*|<field_key>])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
基本语法说明
-
COS(field_key)返回field key对应的field value的余弦值。
-
COS(*)返回在measurement中每个field key对应的field value的余弦值。
-
COS()支持数据类型为int64和float64的field value。
基本语法支持group by tags的GROUP BY子句,但是不支持group by time。请查看高级语法章节了解如何使用COS()和GROUP BY time()子句。
基本语法示例
下面的示例将使用NOAA_water_database数据集的如下数据:
> SELECT "water_level" FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica'
name: h2o_feet
time water_level
---------------
2015-08-18T00:00:00Z2.064
2015-08-18T00:06:00Z2.116
2015-08-18T00:12:00Z2.028
2015-08-18T00:18:00Z2.126
2015-08-18T00:24:00Z2.041
2015-08-18T00:30:00Z2.051
示例一:计算指定field key对应的field value的余弦值
> SELECT COS("water_level") FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica'
name: h2o_feet
time cos
-------
2015-08-18T00:00:00Z-0.47345017433543124
2015-08-18T00:06:00Z-0.5185922462666872
2015-08-18T00:12:00Z-0.4414407189100776
2015-08-18T00:18:00Z-0.5271163912192579
2015-08-18T00:24:00Z-0.45306786455514825
2015-08-18T00:30:00Z-0.4619598230611262
该查询返回measurement h2o_feet中field key water_level对应的field value的余弦值。
示例二:计算measurement中每个field key对应的field value的余弦值
> SELECT COS(*) FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica'
name: h2o_feet
time cos_water_level
-------------------
2015-08-18T00:00:00Z-0.47345017433543124
2015-08-18T00:06:00Z-0.5185922462666872
2015-08-18T00:12:00Z-0.4414407189100776
2015-08-18T00:18:00Z-0.5271163912192579
2015-08-18T00:24:00Z-0.45306786455514825
2015-08-18T00:30:00Z-0.4619598230611262
该查询返回measurement h2o_feet中每个存储数值的field key对应的field value的余弦值。measurement h2o_feet中只有一个数值类型的field:water_level。
高级语法
SELECT COS(([*|<field_key>]))[INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
高级语法描述
高级语法需要一个GROUP BY time()子句和一个嵌套的InfluxQL函数。查询首先计算在指定的GROUP BY time()间隔内嵌套函数的结果,然后计算这些结果的余弦值。
COS()支持以下嵌套函数:
-
COUNT()
-
MEAN()
-
MEDIAN()
-
MODE()
-
SUM()
-
FIRST()
-
LAST()
-
MIN()
-
MAX()
-
PERCENTILE()
高级语法示例:计算平均值的余弦值
> SELECT COS(MEAN("water_level")) FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica' GROUP BY time(12m)
name: h2o_feet
time cos
-------
2015-08-18T00:00:00Z-0.49618891270599885
2015-08-18T00:12:00Z-0.4848605136571181
2015-08-18T00:24:00Z-0.4575195627907578
该查询返回field key water_level对应的每12分钟的时间间隔的field value的平均值的余弦值。
为了得到这些结果,InfluxDB®首先计算field key water_level对应的每12分钟的时间间隔的field value的平均值。这一步跟同时使用MEAN()函数和GROUP BY time()子句、但不使用COS()的情形一样:
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica' GROUP BY time(12m)
name: h2o_feet
time mean
--------
2015-08-18T00:00:00Z2.09
2015-08-18T00:12:00Z2.077
2015-08-18T00:24:00Z2.0460000000000003
然后,InfluxDB®计算这些平均值的余弦值。
CUMULATIVE_SUM()
返回field value的累积总和。
基本语法
SELECT CUMULATIVE_SUM([*|<field_key>|/<regular_expression>/])[INTO_clause] FROM_clause [WHERE_clause][GROUP_BY_clause][ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
基本语法说明
-
CUMULATIVE_SUM(field_key)返回field key对应的field value的累积总和。
-
CUMULATIVE_SUM(/regular_expression/)返回与正则表达式匹配的每个field key对应的field value的累积总和。
-
CUMULATIVE_SUM(*)返回在measurement中每个field key对应的field value的累积总和。
-
CUMULATIVE_SUM()支持数据类型为int64和float64的field value。
基本语法支持group by tags的GROUP BY子句,但是不支持group by time。请查看高级语法章节了解如何使用CUMULATIVE_SUM()和GROUP BY time()子句。
基本语法示例
下面的示例将使用NOAA_water_database数据集的如下数据:
> SELECT "water_level" FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica'
name: h2o_feet
time water_level
---------------
2015-08-18T00:00:00Z2.064
2015-08-18T00:06:00Z2.116
2015-08-18T00:12:00Z2.028
2015-08-18T00:18:00Z2.126
2015-08-18T00:24:00Z2.041
2015-08-18T00:30:00Z2.051
示例一:计算指定field key对应的field value的累积总和
> SELECT CUMULATIVE_SUM("water_level") FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica'
name: h2o_feet
time cumulative_sum
------------------
2015-08-18T00:00:00Z2.064
2015-08-18T00:06:00Z4.18
2015-08-18T00:12:00Z6.208
2015-08-18T00:18:00Z8.334
2015-08-18T00:24:00Z10.375
2015-08-18T00:30:00Z12.426
该查询返回measurement h2o_feet中field key water_level对应的field value的累积总和。
示例二:计算measurement中每个field key对应的field value的累积总和
> SELECT CUMULATIVE_SUM(*) FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica'
name: h2o_feet
time cumulative_sum_water_level
------------------------------
2015-08-18T00:00:00Z2.064
2015-08-18T00:06:00Z4.18
2015-08-18T00:12:00Z6.208
2015-08-18T00:18:00Z8.334
2015-08-18T00:24:00Z10.375
2015-08-18T00:30:00Z12.426
该查询返回measurement h2o_feet中每个存储数值的field key对应的field value的累积总和。measurement h2o_feet中只有一个数值类型的field:water_level。
示例三:计算与正则表达式匹配的每个field key对应的field value的累积总和
> SELECT CUMULATIVE_SUM(/water/) FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica'
name: h2o_feet
time cumulative_sum_water_level
------------------------------
2015-08-18T00:00:00Z2.064
2015-08-18T00:06:00Z4.18
2015-08-18T00:12:00Z6.208
2015-08-18T00:18:00Z8.334
2015-08-18T00:24:00Z10.375
2015-08-18T00:30:00Z12.426
该查询返回measurement h2o_feet中每个存储数值并包含单词water的field key对应的field value的累积总和。
示例四:计算指定field key对应的field value的累积总和并包含多个子句
> SELECT CUMULATIVE_SUM("water_level") FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica' ORDER BY time DESC LIMIT 4 OFFSET 2
name: h2o_feet
time cumulative_sum
------------------
2015-08-18T00:18:00Z6.218
2015-08-18T00:12:00Z8.246
2015-08-18T00:06:00Z10.362
2015-08-18T00:00:00Z12.426
该查询返回measurement h2o_feet中field key water_level对应的field value的累积总和,它涵盖的时间范围在2015-08-18T00:00:00Z和2015-08-18T00:30:00Z之间,并且以递减的时间戳顺序返回结果,同时,该查询将返回的数据点个数限制为4,并将返回的数据点偏移两个(即前两个数据点不返回)。
高级语法
SELECT CUMULATIVE_SUM(([*|<field_key>|/<regular_expression>/]))[INTO_clause] FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause][LIMIT_clause][OFFSET_clause][SLIMIT_clause][SOFFSET_clause]
高级语法描述
高级语法需要一个GROUP BY time()子句和一个嵌套的InfluxQL函数。查询首先计算在指定的GROUP BY time()间隔内嵌套函数的结果,然后计算这些结果的累积总和。
CUMULATIVE_SUM()支持以下嵌套函数:
-
COUNT()
-
MEAN()
-
MEDIAN()
-
MODE()
-
SUM()
-
FIRST()
-
LAST()
-
MIN()
-
MAX()
-
PERCENTILE()
高级语法示例:计算平均值的累积总和
> SELECT CUMULATIVE_SUM(MEAN("water_level")) FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica' GROUP BY time(12m)
name: h2o_feet
time cumulative_sum
------------------
2015-08-18T00:00:00Z2.09
2015-08-18T00:12:00Z4.167
2015-08-18T00:24:00Z6.213
该查询返回field key water_level对应的每12分钟的时间间隔的field value的平均值的累积总和。
为了得到这些结果,InfluxDB®首先计算field key water_level对应的每12分钟的时间间隔的field value的平均值。这一步跟同时使用MEAN()函数和GROUP BY time()子句、但不使用CUMULATIVE_SUM()的情形一样:
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >='2015-08-18T00:00:00Z' AND time <='2015-08-18T00:30:00Z' AND "location"='santa_monica' GROUP BY time(12m)
name: h2o_feet
time mean
--------
2015-08-18T00:00:00Z2.09
2015-08-18T00:12:00Z2.077
2015-08-18T00:24:00Z2.0460000000000003
然后,InfluxDB®计算这些平均值的累积总和。最终查询结果中的第二个数据点(4.167)是2.09和2.077的总和,第三个数据点(6.213)是2.09、2.077和2.0460000000000003的总和。