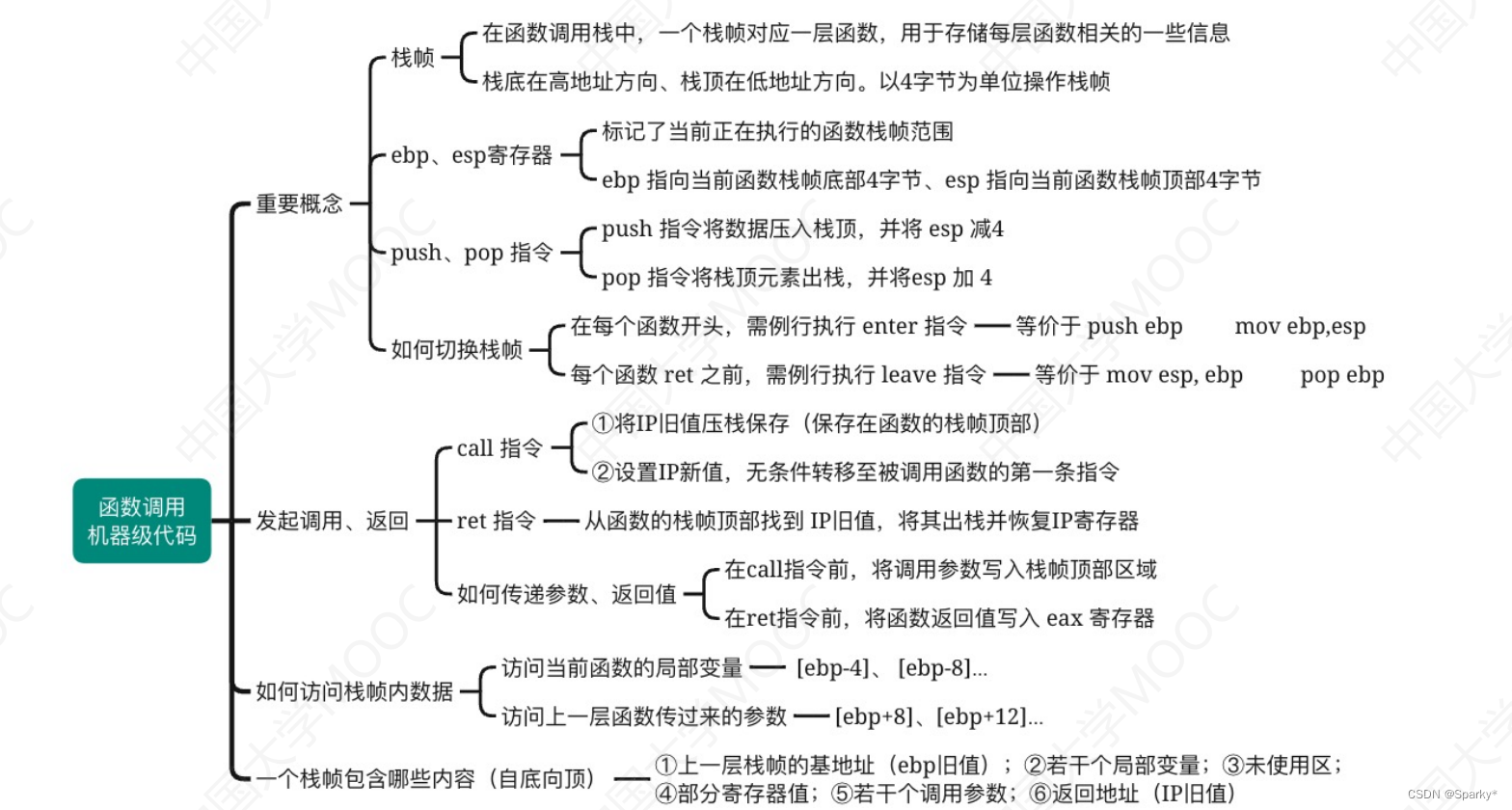
引言
这篇文章主要为大家简单介绍 Java 如何处理千万级数据,
随着大数据时代的到来,数据量持续呈现爆炸式增长。在这种背景下,如何快速、高效地处理和分析千万级甚至更大规模的数据,成为企业和开发者面临的重要挑战。处理大数据不仅可以帮助企业获得有价值的见解,还能优化业务运营和提升用户体验。
Java 作为一种广泛应用于企业级应用开发的编程语言,在处理大数据方面有着较大的优势。Java 的跨平台性、成熟的生态系统、丰富的类库和框架,以及对并发编程的良好支持,使得它能够胜任处理千万级数据的任务。

数据处理算法和数据结构
在处理大数据时,选用合适的数据处理算法和数据结构至关重要。这将为保证数据处理任务的高效执行和优化系统性能奠定基础。
高效的排序算法
-
归并排序(Merge Sort):归并排序是一种分治算法,通过递归方式将待排序数组均匀分成两半,然后将两个有序子序列合并为一个有序序列。归并排序的时间复杂度为 O(n log n),适用于大量数据的排序。
-
快速排序(Quick Sort):快速排序同样采用分治算法(Divide and Conquer)的原理。首先选取一个基准元素,将数组中的元素按照大于或小于基准值进行划分,接着对子数组递归地应用同样的步骤。快速排序在平均情况下具有 O(n log n)的时间复杂度,尤其适用于大数据集。
针对大数据量的数据结构
-
布隆过滤器(Bloom Filter):布隆过滤器是一种空间高效的概率型数据结构,在大量数据场景下用于快速判断一个元素是否存在于集合中。布隆过滤器利用多个哈希函数将元素映射到一个位数组中,虽然存在一定的误报率,但能大大减小数据存储空间需求。
-
跳表(Skip List):跳表是一种扩展了的有序链表,允许在 O(log n)的时间复杂度内进行查找、插入和删除操作。通过维护多层索引,跳表在大量数据的情况下能够提供较好的查询性能,且易于实现。
缓存技术优化数据访问速度
-
LRU 缓存(Least Recently Used Cache):LRU 缓存是一种常用的缓存淘汰算法,当缓存达到最大容量时,优先淘汰最近最少使用的数据。使用 LRU 缓存能够将热点数据保留在缓存中,从而减少数据访问的延迟。在 Java 中可通过 LinkedHashMap 或自定义数据结构实现 LRU 缓存。
并发编程和多线程
Java 多线程处理高并发场景
-
使用 Java 提供的
Thread类直接创建线程对象,通过实现Runnable接口编写任务逻辑,然后调用线程对象的start()方法启动线程。 -
使用
Callable接口编写返回结果的任务逻辑,并通过FutureTask包装后交给线程执行。这种方式可以捕获任务执行过程中的异常,并获得任务的执行结果。 -
利用
ExecutorService接口及其实现类(如ThreadPoolExecutor)创建并管理线程池,高效地运行任务。
线程池管理并发任务
-
了解线程池参数,如核心线程数、最大线程数、工作队列、线程工厂、拒绝策略等,合理设定线程池参数,以满足不同场景下的并发需求。
-
使用 JDK 提供的静态工厂类
Executors快速创建常用类型的线程池,例如固定大小线程池(newFixedThreadPool),可缓存线程池(newCachedThreadPool)或定时任务线程池(newScheduledThreadPool)。 -
考虑优雅地关闭线程池,并在系统退出或资源回收时注销线程池以释放资源。
开源并发库与框架
-
Java 并发库(
java.util.concurrent):Java 并发库提供了大量并发工具类,如CountDownLatch、Semaphore、CyclicBarrier等,用于协调线程间的操作和同步。 -
Akka:Akka 是一个基于消息驱动的并发框架,采用 Actor 模型简化并发编程,高效处理大量并发操作。通过将任务分配给 Actor,用户可以实现弹性、高可用、可扩展的系统。
分布式计算
分布式计算是处理大数据的关键技术之一,在具有海量数据和计算需求的场景中发挥着重要作用。
分布式计算框架与技术
-
Hadoop:Hadoop 是一种用于分布式处理大数据的开源框架,其中 MapReduce 是 Hadoop 的核心编程模型。MapReduce 将大数据处理任务分为 Map 和 Reduce 两个阶段,允许在大量节点上并行执行。Hadoop 还提供了一个分布式文件系统 HDFS,用以存储处理过程中的大数据。
-
Spark:Spark 是一种与 Hadoop 相似的大数据处理框架,提供了弹性分布式数据集(RDD)的概念。Spark 相较于 Hadoop 具有更快的数据处理速度,因为它支持内存级别的缓存。Spark 还提供了支持批处理、流处理、机器学习和图计算等多种应用场景的 API,使开发者能够方便地构建各种大数据处理任务。
划分任务并行化执行
在处理大数据任务时,将任务划分为更小的子任务并在多个计算节点上并行执行通常能显著提高处理速度。这需要针对具体任务设计合适的任务拆分策略,并在分布式环境中协调各个节点的计算和数据交换。基于分布式计算框架,如 Hadoop 和 Spark,可以帮助开发者应对这些挑战,实现简单且高效的任务并行化。
运行环境优化与资源配置
为确保分布式计算任务能够高效执行,需要对运行环境进行优化和合理配置资源。常见的优化手段包括
-
集群硬件资源配置:根据计算任务的需求选择合适的计算节点规格,如 CPU、内存和网络带宽等,并确保计算资源在整个集群中高效分配和使用。
-
数据本地化:尽可能在同一个节点上存储用于计算的数据,以减少数据传输的时间开销。在 Hadoop 中,这可以通过 HDFS 达到;在 Spark 中,这可以通过将 RDD 持久化到内存或磁盘实现。
-
内存管理:根据任务需求为存储空间、计算区域和系统内部分配恰当的内存,以平衡存储空间、计算速度和系统资源占用。
数据存储与检索
数据存储与检索是处理大数据时关键的一环。
选择合适的数据库
-
MySQL:MySQL 是一款流行的关系型数据库管理系统,支持 SQL 语言进行数据查询。通过使用适当的索引和优化查询语句,MySQL 能高效地存储和检索千万级数据。
-
PostgreSQL: PostgreSQL 是一款功能丰富且企业级的开源关系型数据库系统。通过支持自定义存储引擎、事务处理、高并发等特性,PostgreSQL 可以处理大数据环境中的复杂数据操作。
索引提高数据检索速度
-
索引原理:索引实际上是一种数据结构,用于存储表中特定列的值,以加快查询速度。通过索引,数据库能够避免全表扫描,从而大幅提高检索效率。
-
索引类型:常见的索引类型包括 B-Tree(默认)、Hash、R-Tree(空间)等。根据实际数据及需求选择合适的索引类型。
-
注意事项:创建合适的索引对于性能至关重要,但也请注意不要过度建索引。因为索引的维护会带来额外的开销,尤其是在插入、删除和更新操作中。因此,需要在性能优化与资源消耗之间进行权衡。
分库分表与数据水平分割
-
分库分表:在处理大数据时,单一表可能会遇到性能瓶颈。通过分库分表(垂直切分和水平切分),可以将数据划分到多个独立的表或数据库中,提高数据存储和检索性能。
-
分片策略:常见的分片策略包括基于范围的分片、基于哈希的分片、以及基于列表的分片。需要根据实际数据规模和访问模式来选择合适的分片策略。
-
解决跨分片查询:在使用分库分表后,跨分片的查询处理变得复杂。为解决此问题,可以采用应用层进行数据聚合并处理,或使用相应的中间件如 Sharding-JDBC、Sharding-Sphere 等
最佳实践案例
高并发场景下的大数据实时分析
在社交媒体、金融交易或在线游戏等领域,高并发场景下的大数据实时分析尤为关键。使用如 Apache Kafka、Apache Flink 等工具,结合 Java 编程技巧,可以帮助实现实时分析。
以在线游戏为例,需要实时分析玩家行为数据以推送定制化广告。通过数据处理算法将日志数据进行清洗,并根据玩家特征将其分类。利用多线程、线程池技术及高效的排序算法,在海量用户中筛选目标群体,从而提高广告投放的精准度。
海量日志数据的处理与分析
在现代的互联网企业中,服务器会产生大量的日志数据。这些数据需要有效地进行收集、存储、检索和分析,以便于发现潜在问题、优化系统性能和提供数据驱动的业务洞察。
以分布式日志收集系统为例,利用 Java 编写的 Logstash 或 Flume 等工具,对日志数据进行收集、过滤和转换。随后,将数据存储在 Elasticsearch 等搜索引擎或 HBase 等分布式数据库中。最后,通过 Kibana 等可视化工具进行日志数据的展示和分析,帮助运维人员及时发现问题并进行调优。
电商平台海量商品推荐系统实现
在电商平台中,为用户提供个性化的商品推荐至关重要。这需要对用户行为数据、商品属性数据等进行实时高效的处理。
为实现此目标,可以结合 Java 高效处理大数据的技巧,确保算法和数据结构的优化。使用分库分表、数据索引、缓存技术等提高数据访问速度。同时,利用机器学习和数据挖掘技术为用户生成个性化的推荐列表。在实际实现中,可以利用 Spark MLlib 等工具,结合 Java 编程进行海量数据的处理与模型构建。


![Glibc——堆利用机制[拓展]](https://img-blog.csdnimg.cn/036d45c2c56a4e2eac98d2e2586be25c.png)