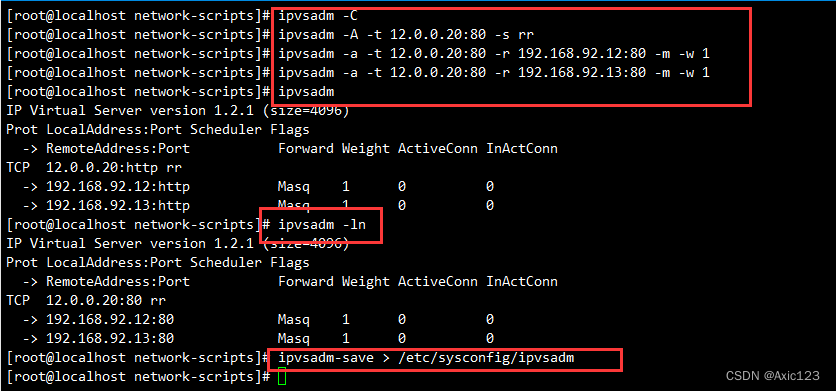
与传统的监督学习不一样,这一篇主要是讲述自编码器模型的,是无监督学习,并且用于的任务不是分类或者回归,而是异常值的监测。
案例背景
需要从一堆网络流量特征监控的数据中寻找哪些可能是异常情况。
听着像分类问题对吧,但是和分类问题有很大不同,一是训练方式不一样,二是异常值情况通常是很少的,所以不能做分类模型,要做自监督模型。
自编码器是什么我就不多介绍了,总之原理就是把数据拿来编码压缩然后解码还原,比较重构还原出来的数据和原来的数据的差异,差的多的,误差大的,就可能是异常值。
代码实现
导入包
import pandas as pd
from pandas.plotting import scatter_matrix
import numpy as np
import pickle
import h5py
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import tensorflow as tf
from tensorflow.keras.models import Model, load_model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from tensorflow.keras import regularizers
from tensorflow.keras.utils import plot_model
%matplotlib inline
sns.set(style='whitegrid', palette='muted', font_scale=1.5)
RANDOM_SEED = 42
LABELS = ['normal.', 'ipsweep.']
1.准备数据
1.1读取数据
读取,查看训练集数据
kddCupTrain = pd.read_csv('kddCupTrain.csv',header=None)
kddCupTest = pd.read_csv('kddCupTest.csv',header=None)
print("Shape of kddCupTrain: ",kddCupTrain.shape)
print("There are any missing values: ", kddCupTrain.isnull().values.any())
kddCupTrain.head(3)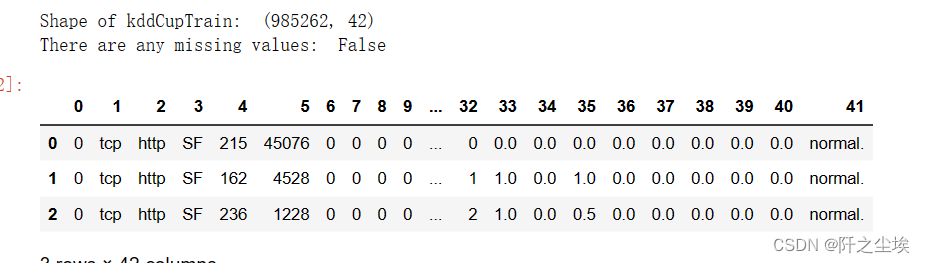
可以看到有40列特征,最后一列是标签。
查看测试集
print("Shape of kddCupTest: ",kddCupTest.shape)
print("There are any missing values: ", kddCupTest.isnull().values.any())
kddCupTest.head(3)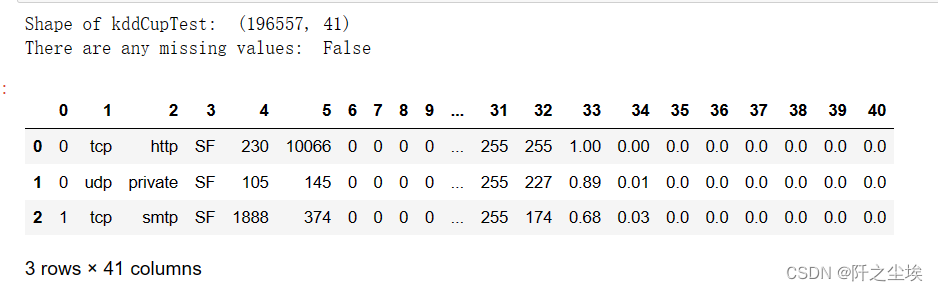
查看响应变量y的信息
#将 kddCupTrain 数据集的第41列重命名为 'Class' 并且应用到原数据集中
kddCupTrain.rename(columns={41:'Class'}, inplace=True)
#使用 pandas.factorize() 函数将 'Class' 列中的值转化为数值编码,并返回编码后的结果和唯一值列表
codes,uniques=pd.factorize(kddCupTrain['Class'])
#打印出唯一的类别标签
print(uniques)
#将 'Class' 列的数值编码更新到原数据集中
kddCupTrain['Class'] = codes
#统计每个类别的样本数量并按数量从大到小排序,然后打印
count_classes = kddCupTrain['Class'].value_counts(sort = True)
print(count_classes)
画个图看看
count_classes.plot.bar(figsize=(5,3)) #画图 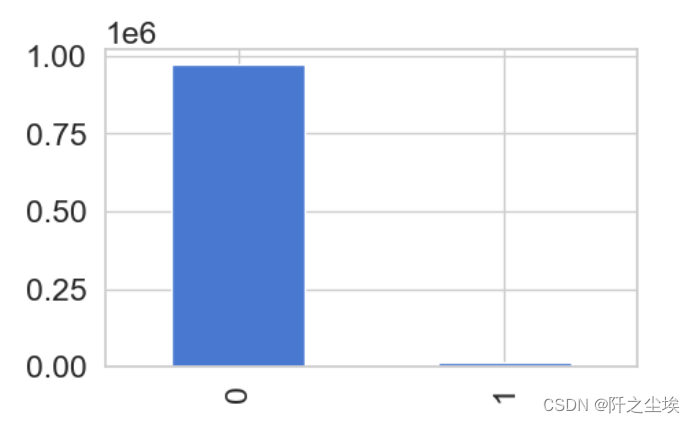
可以看到是极度不平衡的数据。
取出y
y = kddCupTrain['Class']
kddCupTrain = kddCupTrain.drop(['Class'], axis=1)
1.2删除无用信息列
#取值唯一的变量删除(如果有一列的值全部一样,也就是取值唯一的特征变量就可以删除了,因为每个样本没啥区别,对模型就没啥用)
for col in kddCupTrain.columns:
if len(kddCupTrain[col].value_counts())==1:
print(col)
kddCupTrain.drop(col,axis=1,inplace=True)
这两列删除了
测试集也进行删除
kddCupTest=kddCupTest[kddCupTrain.columns]
print(kddCupTrain.shape,kddCupTest.shape)
1.3训练集和测试集都进行独立热编码
kddCupTrain=pd.get_dummies(kddCupTrain)
kddCupTest=pd.get_dummies(kddCupTest)
print(kddCupTrain.shape,kddCupTest.shape)
开通看到数据独立热编码后维度不一样,需要统一一下
统一数据维度
for col in kddCupTrain.columns:
if col not in kddCupTest.columns:
kddCupTest[col]=0
kddCupTest=kddCupTest[kddCupTrain.columns]
print(kddCupTrain.shape,kddCupTest.shape)查看训练集前三行
kddCupTrain.head(3)
测试集前三行
kddCupTest.head(3) 
1.4数据标准化
#数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(kddCupTrain)
X_s = scaler.transform(kddCupTrain)
X_test_s = scaler.transform(kddCupTest)
print('训练数据形状:')
print(X_s.shape,y.shape)
print('测试数据形状:')
print(X_test_s.shape)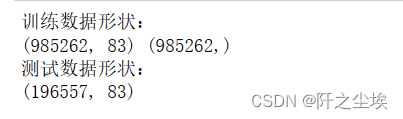
查看数据信息(验证是不是标准化了)
print(X_s.mean())
print(X_s.std(ddof=0))
1.5将数据拆分为训练子集和验证子集
#划分训练集和验证集
from sklearn.model_selection import train_test_split
X_train,X_val,y_train,y_val=train_test_split(X_s,y,test_size=0.2,random_state=RANDOM_SEED)查看形状
print('Train: shape X',X_train.shape,', shape Y',y_train.shape)
print('Val: shape X',X_val.shape,', shape Y',y_val.shape)
1.6. 分离“正常”实例
X_trainNorm = X_train[y_train == 0]
X_valNorm = X_val[y_val == 0]
print(X_trainNorm.shape,X_valNorm.shape)
2. 构建模型
2.1.选择自编码器的架构
自己选择几层几个神经元。我这里是4个隐藏层,编码压缩从83到40到20,然后再解码从20到40到83还原。看这个层的张量形状就能看出来。
input_dim = X_trainNorm.shape[1]
layer1_dim = 40
encoder_dim = 20
input_layer = Input(shape=(input_dim, ))
encoder1 = Dense(layer1_dim, activation="relu")(input_layer)
encoder2 = Dense(encoder_dim, activation="relu")(encoder1)
decoder1 = Dense(layer1_dim, activation='relu')(encoder2)
decoder2 = Dense(input_dim, activation='linear')(decoder1)
print('input_layer: ',input_layer)
print('encoder1',encoder1)
print('encoder2',encoder2)
print('decoder1',decoder1)
print('decoder2',decoder2)
查看模型信息。
autoencoder = Model(inputs=input_layer, outputs=decoder2)
autoencoder.summary()
对模型进行可视化,画出来
plot_model(autoencoder, to_file='fraud_encoder1.png',show_shapes=True,show_layer_names=True)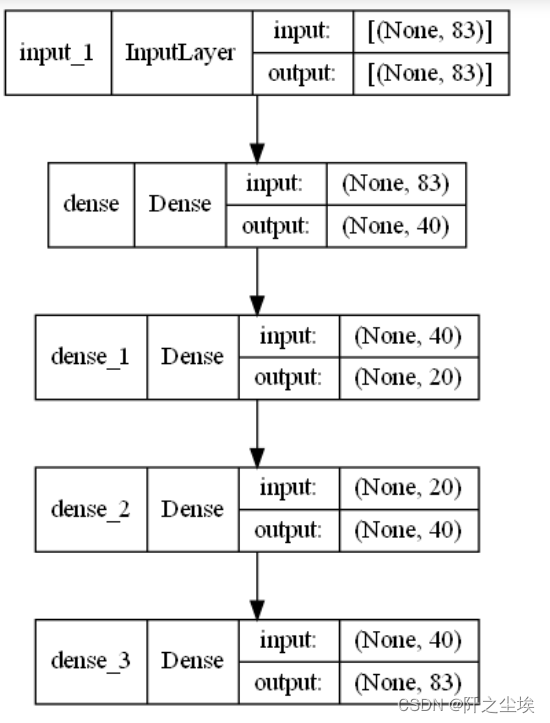
2.2. 拟合模型
批量大小64,训练轮数50.
nb_epoch = 50
batch_size = 64
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
checkpointer = ModelCheckpoint(filepath="model.h5",verbose=0,save_best_only=True)
earlystopping = EarlyStopping(monitor='val_loss', patience=5, verbose=0) # 'patience' number of not improving epochs
history = autoencoder.fit(X_trainNorm, X_trainNorm,epochs=nb_epoch, batch_size=batch_size,shuffle=True,
validation_data=(X_valNorm, X_valNorm),
verbose=1,callbacks=[checkpointer, #tensorboard,
earlystopping]).history
有早停机制,所以24轮就停下来了。
查看损失图
plt.plot(history['loss'])
plt.plot(history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper right'); 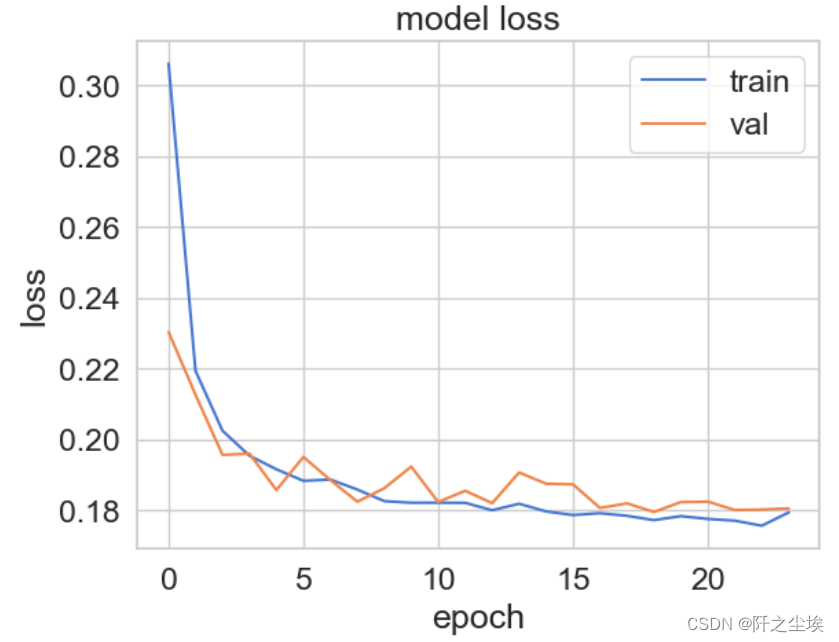
3. 评估
3.1. 从文件加载安装的自动编码器
autoencoder = load_model('model.h5')3.2. 重建
对验证集数据进行评价 (下面的图都是验证集的)
重构预测
testPredictions = autoencoder.predict(X_val)
X_val.shape,testPredictions.shape
真实数据和预测重构的数据形状一样,下面计算对比他们的误差。
3.3. 评估
testMSE = mean_squared_error(X_val.transpose(), testPredictions.transpose(), multioutput='raw_values')
error_df = pd.DataFrame({'reconstruction_error': testMSE,'true_class': y_val})
error_df.head()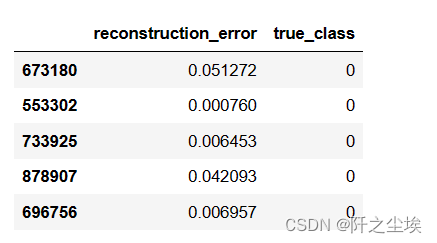
描述性统计一下
error_df.reconstruction_error.describe() 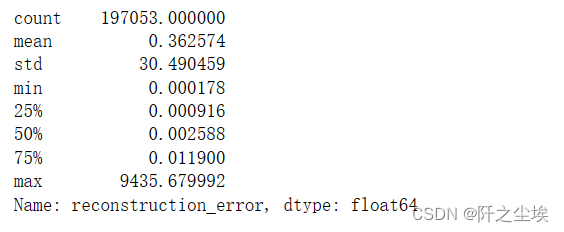
画图查看正常的情况重构误差的分布。
fig = plt.figure(figsize=(5,3),dpi=128)
ax = fig.add_subplot(111)
normal_error_df = error_df[(error_df['true_class']== 0) & (error_df['reconstruction_error'] < 10)]
ax.hist(normal_error_df.reconstruction_error.values, bins=10); 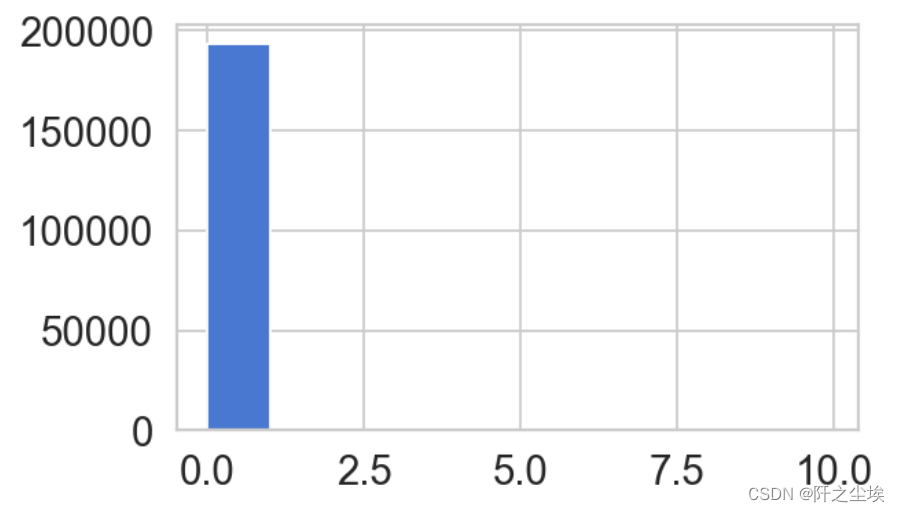
可以看到误差基本都是0附近,说明正常情况下的重构误差都很小。
查看异常值的重构误差分布
fig = plt.figure(figsize=(5,3),dpi=128)
ax = fig.add_subplot(111)
fraud_error_df = error_df[(error_df['true_class']== 1) & (error_df['reconstruction_error'] < 10)]
ax.hist(fraud_error_df.reconstruction_error.values, bins=10);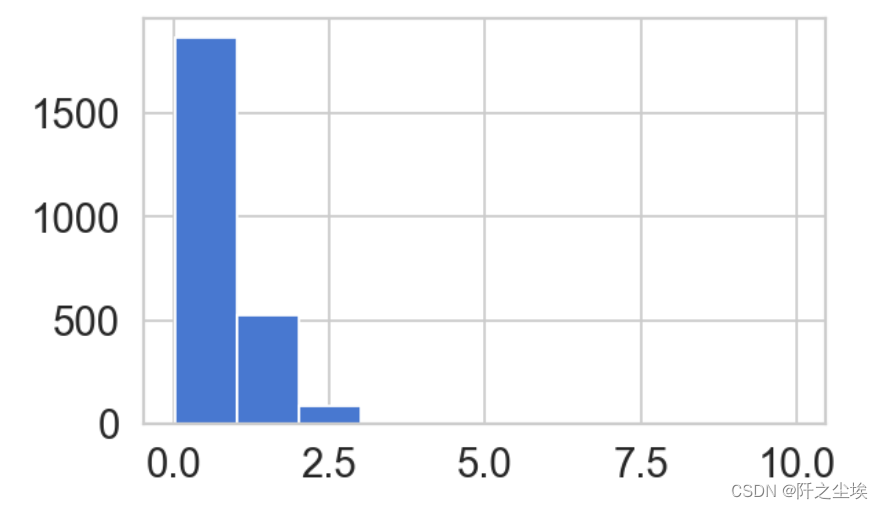
可以看到误差分布没那么极端了,有很多样本重构后有较大的误差,说明异常情况下的重构误差都会偏大。
计算AUC值
from sklearn.metrics import (confusion_matrix, auc, roc_curve, cohen_kappa_score, accuracy_score)
fpr, tpr, thresholds = roc_curve(error_df.true_class, error_df.reconstruction_error)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(7,4),dpi=128)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, label='AUC = %0.4f'% roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([-0.001, 1])
plt.ylim([0, 1.001])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show();
3.4 预测效果
threshold = normal_error_df.reconstruction_error.quantile(q=0.995)
threshold![]()
找到误差5%的分位数水平作为阈值,重构误差大于这个值就认为是异常情况。
筛序一下极端情况,方便画图
error_df=error_df[error_df['reconstruction_error']<3500]groups = error_df.groupby('true_class')
fig, ax = plt.subplots()
for name, group in groups:
if name == 1:
MarkerSize = 7 ; Color = 'orangered' ; Label = 'Fraud' ; Marker = 'd'
else:
MarkerSize = 3.5 ; Color = 'b' ; Label = 'Normal' ; Marker = 'o'
ax.plot(group.index, group.reconstruction_error, linestyle='',color=Color,label=Label,ms=MarkerSize,marker=Marker)
ax.hlines(threshold, ax.get_xlim()[0], ax.get_xlim()[1], colors="r", zorder=100, label='Threshold')
ax.legend(loc='upper left', bbox_to_anchor=(0.95, 1))
plt.title("Probabilities of fraud for different classes")
plt.ylabel("Reconstruction error") ; plt.xlabel("Data point index")
plt.show()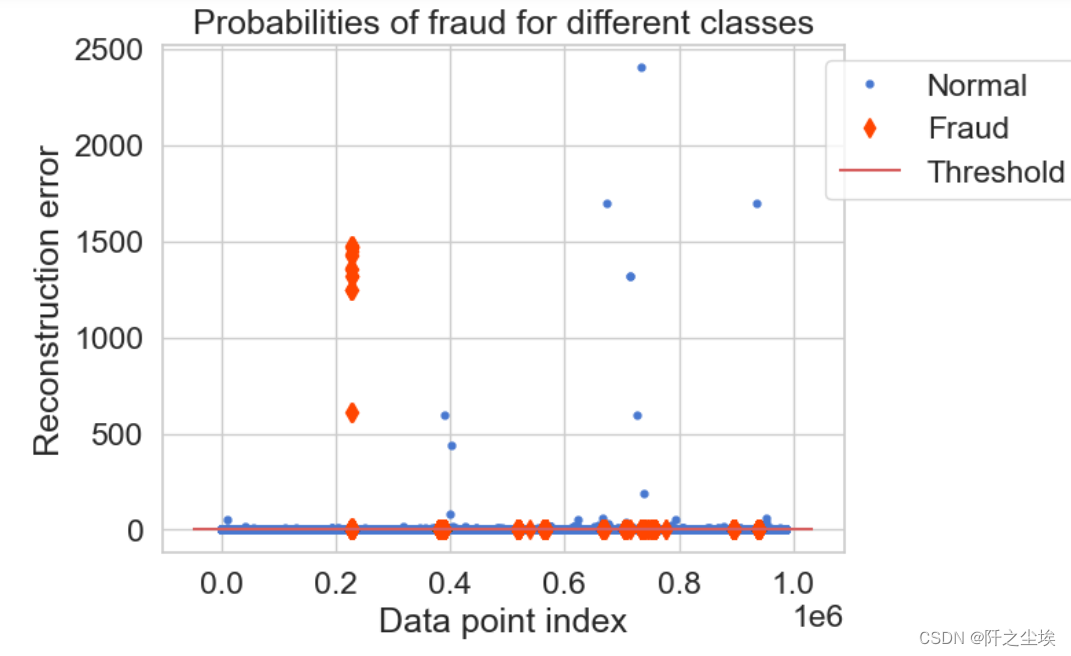
可以看到,大于阈值的情况,有一些事正常的,也有异常的,分类没那么准确。
画混淆矩阵来进一步观察
y_pred = [1 if e > threshold else 0 for e in error_df.reconstruction_error.values]
conf_matrix = confusion_matrix(error_df.true_class, y_pred)
print(conf_matrix)
plt.figure(figsize=(5, 5),dpi=108)
sns.heatmap(conf_matrix, xticklabels=LABELS, yticklabels=LABELS, annot=True, fmt="d");
plt.title("Confusion matrix")
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.show() 
计算科恩指标和准确率
cohen_kappa_score(error_df.true_class, y_pred),accuracy_score(error_df.true_class, y_pred)![]()
准确率还是高达98的,但是由于样本的极度不平衡,科恩指标较小。
4.测试集的预测,创建提交
预测重构
testPredictions = autoencoder.predict(X_test_s)
X_test_s.shape,testPredictions.shape计算误差
testMSE = mean_squared_error(X_test_s.transpose(), testPredictions.transpose(), multioutput='raw_values')
result_df = pd.DataFrame({'reconstruction_error': testMSE}) 画个图看看
result_df.plot.box()
有很多极大值,说明可能这些误差大的样本就是异常情况。
储存,就可以提交了
result_df.to_csv('result.csv')(如果需要变成分类的结果(是否为异常值),就按照上面算出阈值,然后加一个判断映射为分类变量就行)