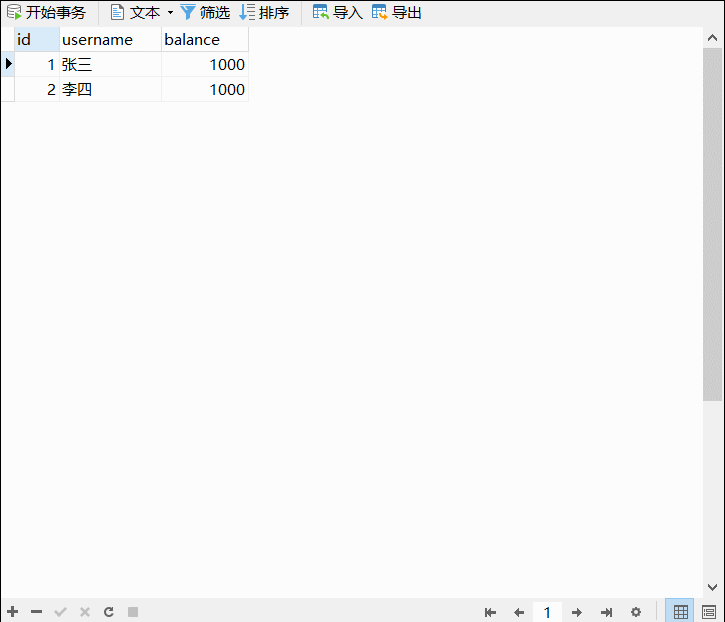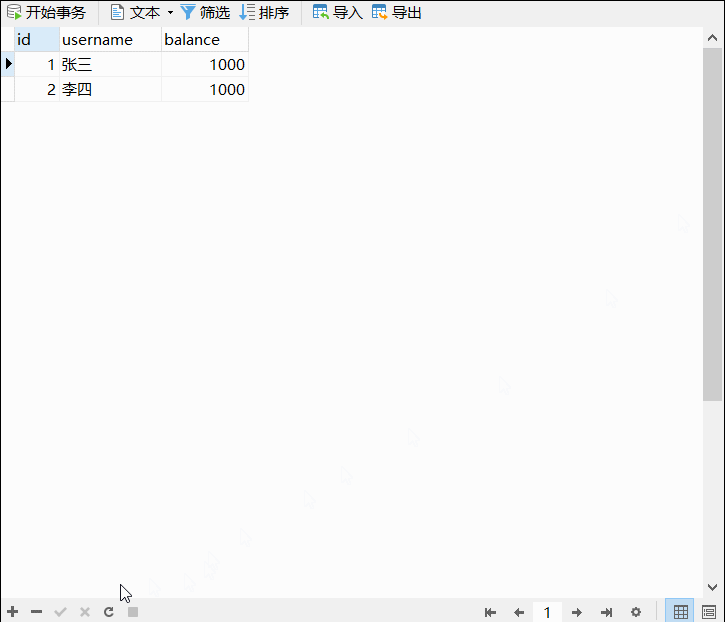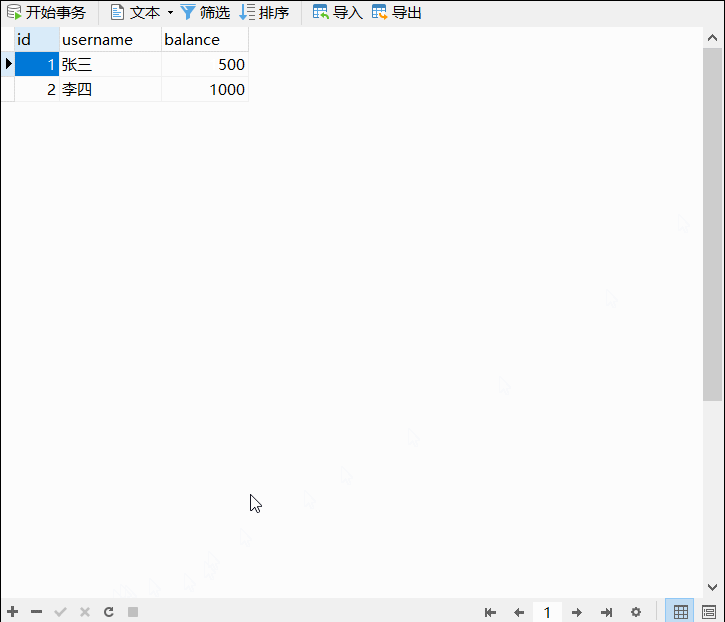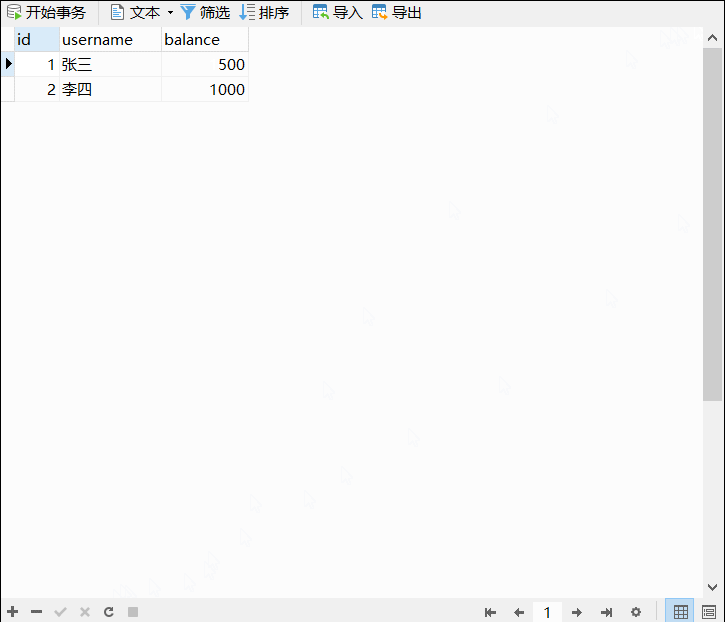
今天同事提了一个问题,还是值得思考的,某个作为数据分发的MySQL库,有时候需要在不同的环境中同步创建数据库,但受工具限制,只能做数据同步,索引这些对象则需要单独创建,该数据库的索引太多,导致生成过程非常地耗时,而且可能会漏掉几个索引,而实际上这些索引并不都是经常需要的,或者可能存在冗余的,因此想问问怎么能清理索引?
这个问题可能非常具有代表性,究其根源,是在设计开发侧,很多情况下,开发人员接到一个需求,开发对应的SQL语句,会根据其经验,选择不同的路径,进而产生不同的影响。
(1)如果是优化经验比较欠缺的同学,目标就是SQL能跑出需要的结果集,不需要管什么非功能的需求,索引?不需要。而往往测试环境数据量很少,性能问题不会成为主要矛盾,能顺利通过测试。出问题,也是上线后,或是业务量积累到一定程度的时候。
(2)如果是具有一定优化经验的同学,可能会根据SQL中用到的条件,创建索引,但是有可能根本就不管这张表之前都创建了什么索引,当前是否有必要再创建一个索引,只是针对正在开发的这条SQL语句,需要创建什么字段的索引,就创建了,可能的结果,就是单就这条SQL的性能测试很可能是通过的,但是一张表上,极端情况很可能索引比字段还多,每个SQL需求对应着一个索引。索引多了,影响的是索引字段增删改维护索引的成本(注意:这里说的是索引字段的增删改,例如update一个非索引字段,不会产生索引维护的操作,因此这是比较严谨的说法,但是insert/delete,通常都是会涉及到所有的字段进而影响所有的索引)。
针对这个问题,清理索引最直观的方式,就是关注一张表的索引是否存在冗余,例如存在索引(a)和(a,b),此时(a,b)索引是可以覆盖(a)索引的,因为复合索引的前导列可以单独用,因此可删除(a)索引。
还可以关注一些索引创建的合理性,例如存在索引(a,b,c)和(a,c),看着是针对不同条件的SQL,但是如果b字段重复值很多(例如存储的性别),区分度很差,(a,b,c)索引和(a,c)索引的性能上应该相差无几,此时可以删除(a,b,c)的索引,因为(a,c)已经可以起到数据的过滤作用,但这种判断就需要结合实际的场景、数据分布、使用频率,来综合考量。
此外,如果是Oracle数据库,可以利用v$object_usage,监控和了解索引的使用情况,以此作为判断索引是否可删除的条件,如果一段时间内,某个索引一直没有调用记录,是不是可以认为具备删除的可能?
SQL> desc v$object_usage;
Name Null? Type
----------------------------------------- -------- ----------------------------
INDEX_NAME NOT NULL VARCHAR2(128)
TABLE_NAME NOT NULL VARCHAR2(128)
MONITORING VARCHAR2(3)
USED VARCHAR2(3)
START_MONITORING VARCHAR2(19)
END_MONITORING VARCHAR2(19)如果是其它数据库没这种监控功能,可以通过历史执行记录的检索,查询使用索引条件的语句是否执行过,或者对应索引的执行计划是否出现过,间接得到判断的线索。
其实,很多时候,如果能将一些优化工作前置,投入产出比就会更加有价值,例如在设计开发阶段,人为创建索引前,看下表中已经创建的索引,考虑下是否可以复用或改造的,或者通过工具平台以及AIGC的支持,当创建新索引时,基于已有索引,提前做判重操作,并给出提示,都可以提前暴露问题,降低改造成本,提高系统可用性,这才是在当前这个环境下,设计人员、开发人员、数据库工程师应该具备的一种能力和思想。
如果您认为这篇文章有些帮助,还请不吝点下文章末尾的"点赞"和"在看",或者直接转发pyq,

近期更新的文章:
《MySQL日志 - Binary log二进制日志介绍》
《最近碰到的一些问题》
《同一主机上启动多台MySQL服务器操作场景》
《一个job问题引出的Oracle官方文档的差错》
《来自二阳人的一些感想》
近期的热文:
《推荐一篇Oracle RAC Cache Fusion的经典论文》
《"红警"游戏开源代码带给我们的震撼》
文章分类和索引:
《公众号1200篇文章分类和索引》