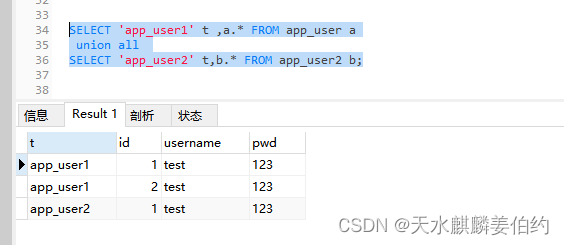
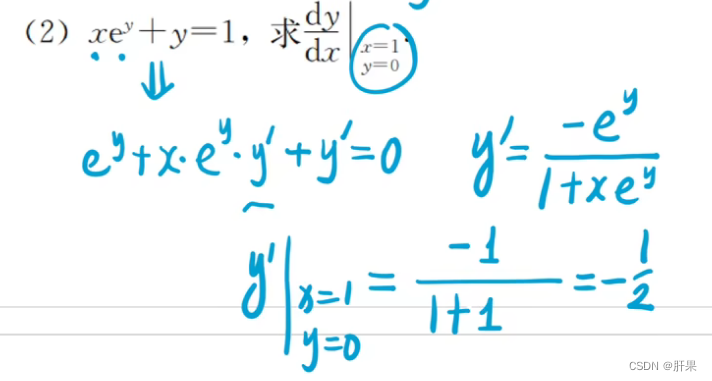在python中,一切都是对象。Python从设计之初就是一门面向对象的语言,它有一个重要的概念,即一切皆对象。
Java虽然也是面向对象编程的语言,但是血统没有Python纯正。比如Java的八种基本数据类型之一int,在持久化的时候,就需要包装成Integer类对象。但是在python中,一切皆对象。数字、字符串、元组、列表、字典、函数、方法、类、模块等等都是对象,包括你的代码。
对象的概念
不同的编程语言以不同的方式定义“对象”。某些语言中,它意味着所有对象必须有属性和方法;另一些语言中,它意味着所有的对象都可以子类化。
在Python中,定义是松散的,某些对象既没有属性也没有方法,而且不是所有的对象都可以子类化。但是Python的万物皆对象从感性上可以解释为:Python 中的一切都可以赋值给变量或者作为参数传递给函数。
Python 的所有对象都有三个特性:(id()、type()、值)
身份:每个对象都有一个唯一的身份标识自己,任何对象的身份都可以使用内建函数 id() 来得到,可以简单的认为这个值是该对象的内存地址。

类型:对象的类型决定了对象可以保存什么类型的值,有哪些属性和方法,可以进行哪些操作,遵循怎样的规则。可以使用内建函数 type() 来查看对象的类型。

值:对象所表示的数据

“身份”、"类型"和"值"在所有对象创建时被赋值。如果对象支持更新操作,则它的值是可变的,否则为只读(数字、字符串、元组等均不可变)。只要对象还存在,这三个特性就一直存在。
从技术上来说,每一个对象有两个标准的头部信息,一个类型标识符来标识类型,还有一个引用的计数器,用于决定是否需要对对象进行回收。
C,C ++或Java,值存储在内存中,并且变量指向该内存位置。(堆内存、栈内存)
在C语言中和python中,变量的存储形式如下:

pythpn存储数据的时候,需要耗费一定的内存去存储和数据相关的信息。而这些信息是C语言的写成的,而当我们去修改变量的值时,相当于重新创建了一个变量,会在自动跑一遍C的底层代码,将数据所有信息更新,而这些底层代码很复杂,不需要我们去写,而是在python设计之初就已经全部写好,我们只要去执行变量赋值的操作就ok。这也是python好用的点之一。
因此,每当您创建一个变量时(比如a = 200),就会在内存中创建一个新的PyObjec它的ref count被设置为1,变量“a”指向它。
内存中的PyObject:
- 类型:整数、字符串、浮点数等
- 引用计数:绑定到该对象的引用的数量ref count
- 值:值/数据/信息
但是什么是ref count呢?
让我们举个例子来理解它。我们有一个类型为integer、值为200的变量“a”。假设我需要另一个名为“b”的变量,其类型为integer,值为200。你已经创建了两个这样的变量
因此,您已经创建了两个这样的变量
a = 200 b = 200
现在,您可能在猜测,对于变量“a”和“b”,内存中必须有2个对象。但事实并非如此。“a”和“b”指向同一个对象。
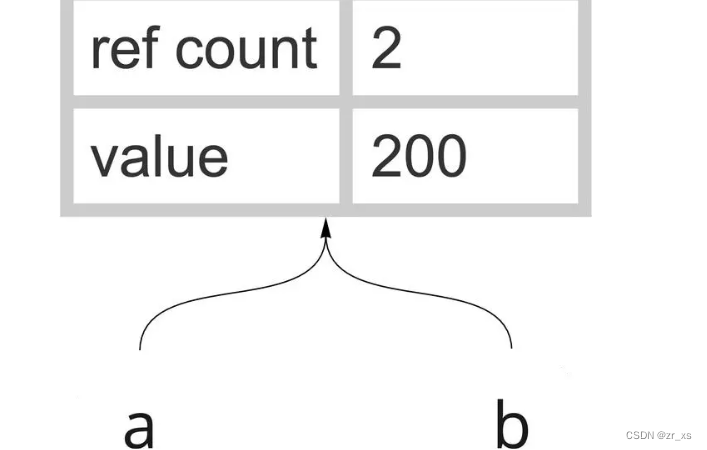
将新对象分配给变量
将新对象分配给现有变量时。前一个对象的ref count减1。
>>> a=1
>>> id(a)
94147440556736
>>> a=2
>>> id(a)
94147440556768
>>>现在,回到前面的问题,当对象的ref count为0时会发生什么。它是否保留在内存中呢?
一旦对象的ref count变为0,垃圾收集器就会将其从内存中删除。
对象相等
== 操作符用于测试两个被引用的对象的值是否相等
is 用于比较两个被引用的对象是否是同一个对象

当操作对象为一个较小的数字或较短的字符串时,又有不同:

这是由于 Python 的缓存机制造成的,小的数字和字符串被缓存并复用,所以 a 和 b 指向同一个对象