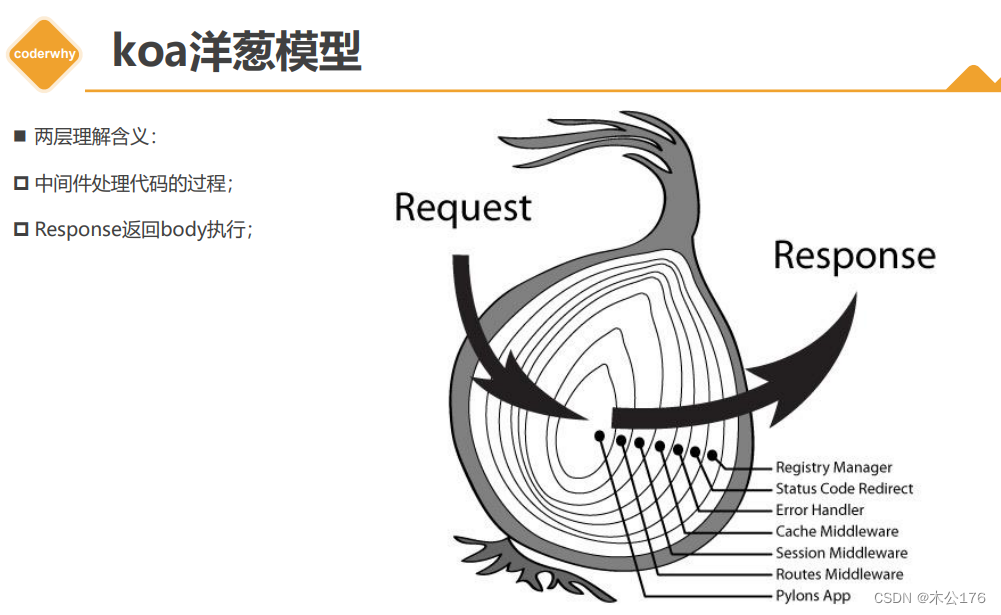
目录
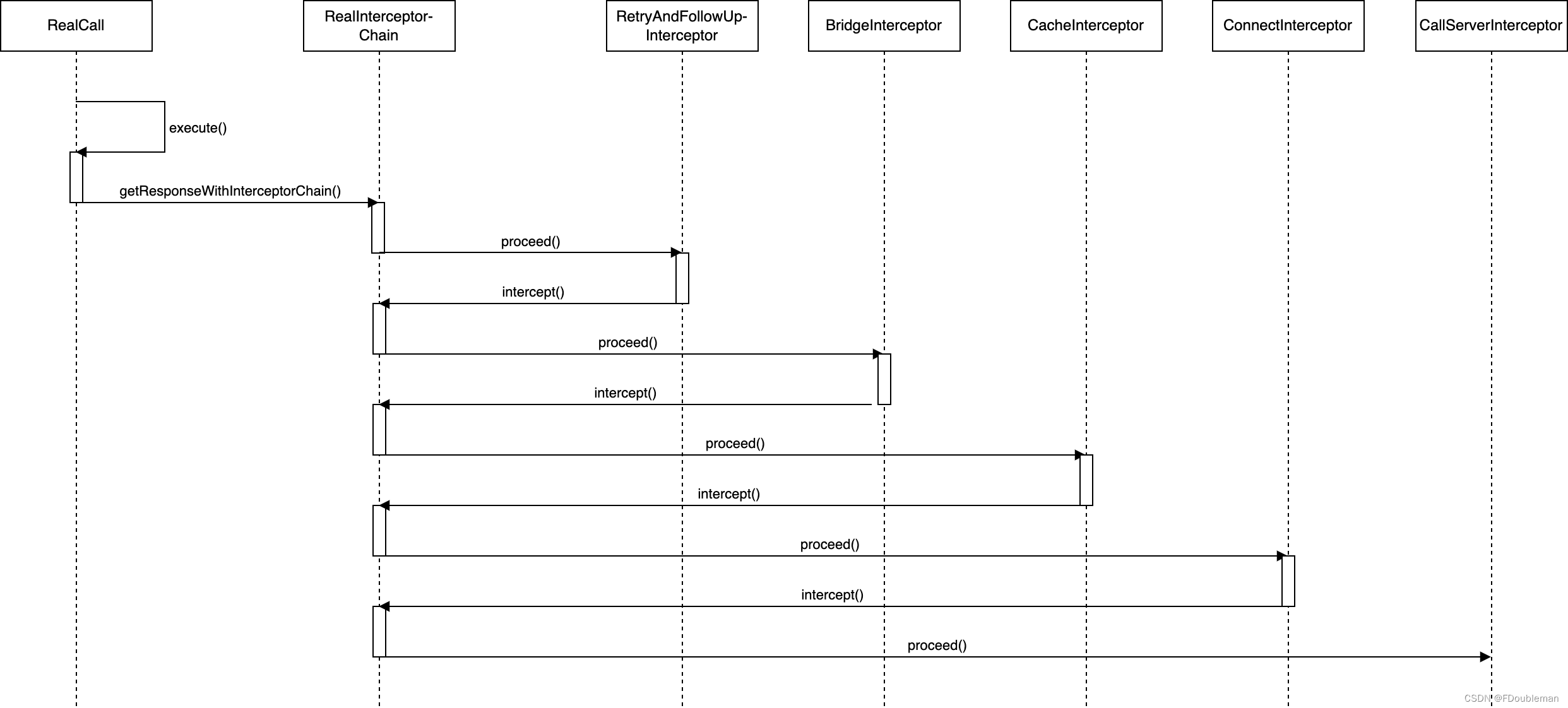
六、动态内存实例
七、 I/0内存
八、DMA原理及映射
8.1 DMA 工作原理
8.2 DMA映射
1.一致性DMA映射
2. 流式DMA映射
3,分散/聚集映射
4.DMA池
5,回弹缓冲区
九、 DMA统一编程接口
十、习题
书接上回:
http://t.csdn.cn/n35ip
六、动态内存实例
在学习了动态内存分配的知识后,我们可以把虚拟串口驱动中的全局变量尽可能地用动态内存来替代,这在一个驱动支持多个设备的时候是比较常见的,特别是在设备是动态添加的情况下,不过在本例中,并没有充分体现动态内存的优点。涉及的主要修改代码如下:
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/cdev.h>
#include <linux/kfifo.h>
#include <linux/ioctl.h>
#include <linux/uaccess.h>
#include <linux/slab.h>
#include <linux/wait.h>
#include <linux/sched.h>
#include <linux/poll.h>
#include <linux/aio.h>
#include <linux/interrupt.h>
#include <linux/random.h>
#include "vser.h"
#define VSER_MAJOR 256
#define VSER_MINOR 0
#define VSER_DEV_CNT 1
#define VSER_DEV_NAME "vser"
#define VSER_FIFO_SIZE 32
struct vser_dev {
struct kfifo fifo;
wait_queue_head_t rwqh;
struct fasync_struct *fapp;
atomic_t available;
unsigned int baud;
struct option opt;
struct cdev cdev;
};
static struct vser_dev *vsdev;
static void vser_work(struct work_struct *work);
DECLARE_WORK(vswork, vser_work);
static int vser_fasync(int fd, struct file *filp, int on);
static int vser_open(struct inode *inode, struct file *filp)
{
if (atomic_dec_and_test(&vsdev->available))
return 0;
else {
atomic_inc(&vsdev->available);
return -EBUSY;
}
}
static int vser_release(struct inode *inode, struct file *filp)
{
vser_fasync(-1, filp, 0);
atomic_inc(&vsdev->available);
return 0;
}
static ssize_t vser_read(struct file *filp, char __user *buf, size_t count, loff_t *pos)
{
int ret;
int len;
char tbuf[VSER_FIFO_SIZE];
len = count > sizeof(tbuf) ? sizeof(tbuf) : count;
spin_lock(&vsdev->rwqh.lock);
if (kfifo_is_empty(&vsdev->fifo)) {
if (filp->f_flags & O_NONBLOCK) {
spin_unlock(&vsdev->rwqh.lock);
return -EAGAIN;
}
if (wait_event_interruptible_locked(vsdev->rwqh, !kfifo_is_empty(&vsdev->fifo))) {
spin_unlock(&vsdev->rwqh.lock);
return -ERESTARTSYS;
}
}
len = kfifo_out(&vsdev->fifo, tbuf, len);
spin_unlock(&vsdev->rwqh.lock);
ret = copy_to_user(buf, tbuf, len);
return len - ret;
}
static ssize_t vser_write(struct file *filp, const char __user *buf, size_t count, loff_t *pos)
{
int ret;
int len;
char *tbuf[VSER_FIFO_SIZE];
len = count > sizeof(tbuf) ? sizeof(tbuf) : count;
ret = copy_from_user(tbuf, buf, len);
return len - ret;
}
static long vser_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
if (_IOC_TYPE(cmd) != VS_MAGIC)
return -ENOTTY;
switch (cmd) {
case VS_SET_BAUD:
vsdev->baud = arg;
break;
case VS_GET_BAUD:
arg = vsdev->baud;
break;
case VS_SET_FFMT:
if (copy_from_user(&vsdev->opt, (struct option __user *)arg, sizeof(struct option)))
return -EFAULT;
break;
case VS_GET_FFMT:
if (copy_to_user((struct option __user *)arg, &vsdev->opt, sizeof(struct option)))
return -EFAULT;
break;
default:
return -ENOTTY;
}
return 0;
}
static unsigned int vser_poll(struct file *filp, struct poll_table_struct *p)
{
int mask = POLLOUT | POLLWRNORM;
poll_wait(filp, &vsdev->rwqh, p);
spin_lock(&vsdev->rwqh.lock);
if (!kfifo_is_empty(&vsdev->fifo))
mask |= POLLIN | POLLRDNORM;
spin_unlock(&vsdev->rwqh.lock);
return mask;
}
static ssize_t vser_aio_read(struct kiocb *iocb, const struct iovec *iov, unsigned long nr_segs, loff_t pos)
{
size_t read = 0;
unsigned long i;
ssize_t ret;
for (i = 0; i < nr_segs; i++) {
ret = vser_read(iocb->ki_filp, iov[i].iov_base, iov[i].iov_len, &pos);
if (ret < 0)
break;
read += ret;
}
return read ? read : -EFAULT;
}
static ssize_t vser_aio_write(struct kiocb *iocb, const struct iovec *iov, unsigned long nr_segs, loff_t pos)
{
size_t written = 0;
unsigned long i;
ssize_t ret;
for (i = 0; i < nr_segs; i++) {
ret = vser_write(iocb->ki_filp, iov[i].iov_base, iov[i].iov_len, &pos);
if (ret < 0)
break;
written += ret;
}
return written ? written : -EFAULT;
}
static int vser_fasync(int fd, struct file *filp, int on)
{
return fasync_helper(fd, filp, on, &vsdev->fapp);
}
static irqreturn_t vser_handler(int irq, void *dev_id)
{
schedule_work(&vswork);
return IRQ_HANDLED;
}
static void vser_work(struct work_struct *work)
{
char data;
get_random_bytes(&data, sizeof(data));
data %= 26;
data += 'A';
spin_lock(&vsdev->rwqh.lock);
if (!kfifo_is_full(&vsdev->fifo))
if(!kfifo_in(&vsdev->fifo, &data, sizeof(data)))
printk(KERN_ERR "vser: kfifo_in failure\n");
if (!kfifo_is_empty(&vsdev->fifo)) {
spin_unlock(&vsdev->rwqh.lock);
wake_up_interruptible(&vsdev->rwqh);
kill_fasync(&vsdev->fapp, SIGIO, POLL_IN);
} else
spin_unlock(&vsdev->rwqh.lock);
}
static struct file_operations vser_ops = {
.owner = THIS_MODULE,
.open = vser_open,
.release = vser_release,
.read = vser_read,
.write = vser_write,
.unlocked_ioctl = vser_ioctl,
.poll = vser_poll,
.aio_read = vser_aio_read,
.aio_write = vser_aio_write,
.fasync = vser_fasync,
};
static int __init vser_init(void)
{
int ret;
dev_t dev;
dev = MKDEV(VSER_MAJOR, VSER_MINOR);
ret = register_chrdev_region(dev, VSER_DEV_CNT, VSER_DEV_NAME);
if (ret)
goto reg_err;
vsdev = kzalloc(sizeof(struct vser_dev), GFP_KERNEL);
if (!vsdev) {
ret = -ENOMEM;
goto mem_err;
}
ret = kfifo_alloc(&vsdev->fifo, VSER_FIFO_SIZE, GFP_KERNEL);
if (ret)
goto fifo_err;
cdev_init(&vsdev->cdev, &vser_ops);
vsdev->cdev.owner = THIS_MODULE;
vsdev->baud = 115200;
vsdev->opt.datab = 8;
vsdev->opt.parity = 0;
vsdev->opt.stopb = 1;
ret = cdev_add(&vsdev->cdev, dev, VSER_DEV_CNT);
if (ret)
goto add_err;
init_waitqueue_head(&vsdev->rwqh);
ret = request_irq(167, vser_handler, IRQF_TRIGGER_HIGH | IRQF_SHARED, "vser", &vsdev);
if (ret)
goto irq_err;
atomic_set(&vsdev->available, 1);
return 0;
irq_err:
cdev_del(&vsdev->cdev);
add_err:
unregister_chrdev_region(dev, VSER_DEV_CNT);
reg_err:
kfifo_free(&vsdev->fifo);
fifo_err:
kfree(vsdev);
mem_err:
return ret;
}
static void __exit vser_exit(void)
{
dev_t dev;
dev = MKDEV(VSER_MAJOR, VSER_MINOR);
free_irq(167, &vsdev);
cdev_del(&vsdev->cdev);
unregister_chrdev_region(dev, VSER_DEV_CNT);
kfifo_free(&vsdev->fifo);
kfree(vsdev);
}
module_init(vser_init);
module_exit(vser_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Kevin Jiang <jiangxg@farsight.com.cn>");
MODULE_DESCRIPTION("A simple character device driver");
MODULE_ALIAS("virtual-serial");
代码第30行将以前的全局 vsfifo 的定义放到 struct vser_dev 结构中,代码第 39行将以前的 vsdev 对象改成了对象指针。代码第232行使用 kzalloc 来动态分配 struct vser_dev结构对象,因为对内存的分配没有特殊的要求,所以内存分配掩码为 GFP_KERNEL。代码第238 行使用 kfifo_alloc 动分配 FIFO需要的内存空间,大小由 VSER_FIFO_SIZE指定,内存分配掩码同样为GFP_KERNEL。在模块清除函数中,代码第 284 行和第285行分别释放了 FIFO的内存和struct vser_dev 对象的内存。
七、 I/0内存
在类似于ARM 的体系结构中,硬件的访问是通过一组特殊功能寄存器 (SFR)的操作来实现的。它们和内存统一编址,访问上和内存基本一致,但是有特殊的意义,即可以通过访问它们来控制硬件设备(I/O设备),所以在 Linux 内核中也叫作IO内存。这些I/0内存的物理地址都可以通过芯片手册来查询,但是我们知道,在内核中应该使用虚拟地址,而不是物理地址,因此对这部分内存的访问必须要经过映射才行。对于这部分内存的访问,内核提供了一组 API,主要的如下。
request_mem_region(start,n,name)
release_mem_region(start,n)
void __iomem *ioremap(phys_addr_t offset,unsigned long size);
void iounmap(void __iomem *addr);
u8 readb(const volatile void __iomem *addr);
u16 readw(const volatile void __iomem *addr);
u32 readl (const volatile void __fomem *addr);
void writeb(u8 b, volatile void __iomem *addr);
void writew(u16 b, volatile void __iomem *addr);
void writel(u32 b, volatile vod __iomem *addr);
ioread8 (addr)
ioread16(addr)
ioread32(addr)
iowrite8(v, addr)
iowrite16(v,addr)
iowrite32(v,addr)
ioread8_rep(p,dst, count)
ioread16_rep(p,dst, count)
ioread32_rep(p, dst, count)
iowrite8_rep(p, src, count)
iowrite16_rep(p,src, count)
iowrite32_rep(p,src, count)
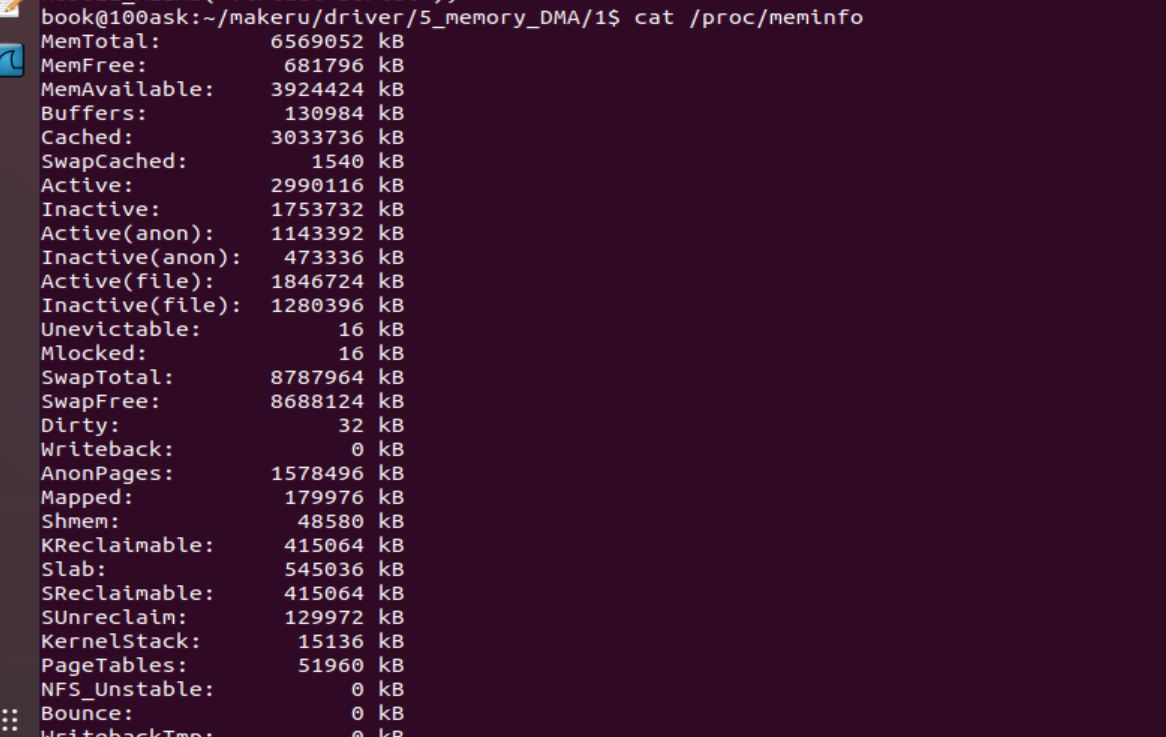
request_mem_region:用于创建一个从start 开始的n字节物理内存资源,名字为name并标记为忙状态,也就是向内核申请一段 I/O 内存空间的使用权。返回值为创建的资源对象地址,类型为struct resource*,NULL表示失败。在使用一段I/O内存之前,一般先使用该函数进行申请,相当于国家对一块领土宣誓主权,这样可以阻止其他驱动申请这块I/O内存资源。创建的资源都可以在“/proc/meminfo”文件中看到。
release_mem_region:用于释放之前创建(或申请)的I/O内存资源
ioremap:映射从offset 开始的size字节IO内存,返回值为对应的虚拟地址,NULL表示映射失败。
iounmap:解除之前的I/O内存映射。
readb、readw和readl分别按1个字节2个字节和4个字节读取映射之后地址为 addr
的I/O内存,返回值为读取的 I/O 内存内容。writeb、writew和writel分别按1个字节、2个字节和4个字节将b写入到映射之后地址为addr的I/O内存。
ioread8、ioread16、ioread32、iowrite8、iowrite16和iowrite32 是 I/O内存读写的另外种形式。加“rep”的变体是连续读写 count 个单元。
有了这组 API 后,我们就可以来操作硬件了。为了简单,以FS4412 上的4个 LED灯为例来进行说明。相关的原理图如图所示。
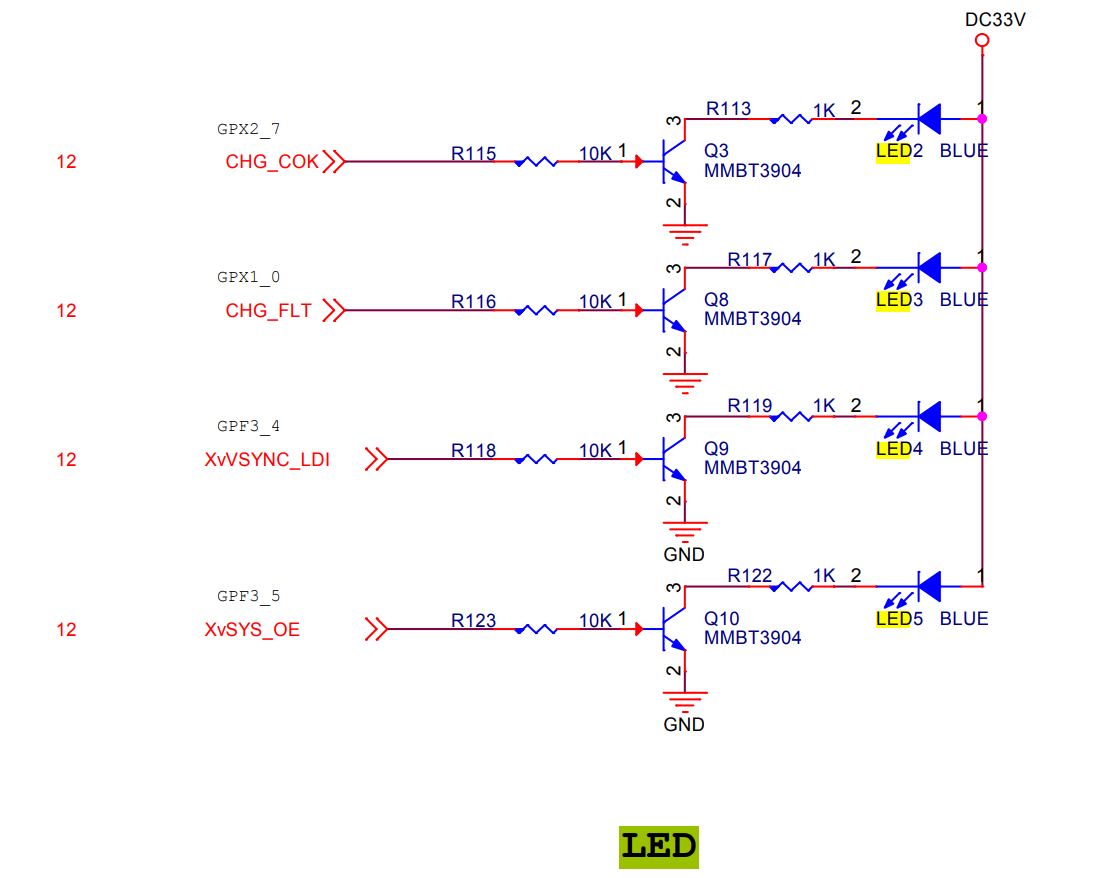
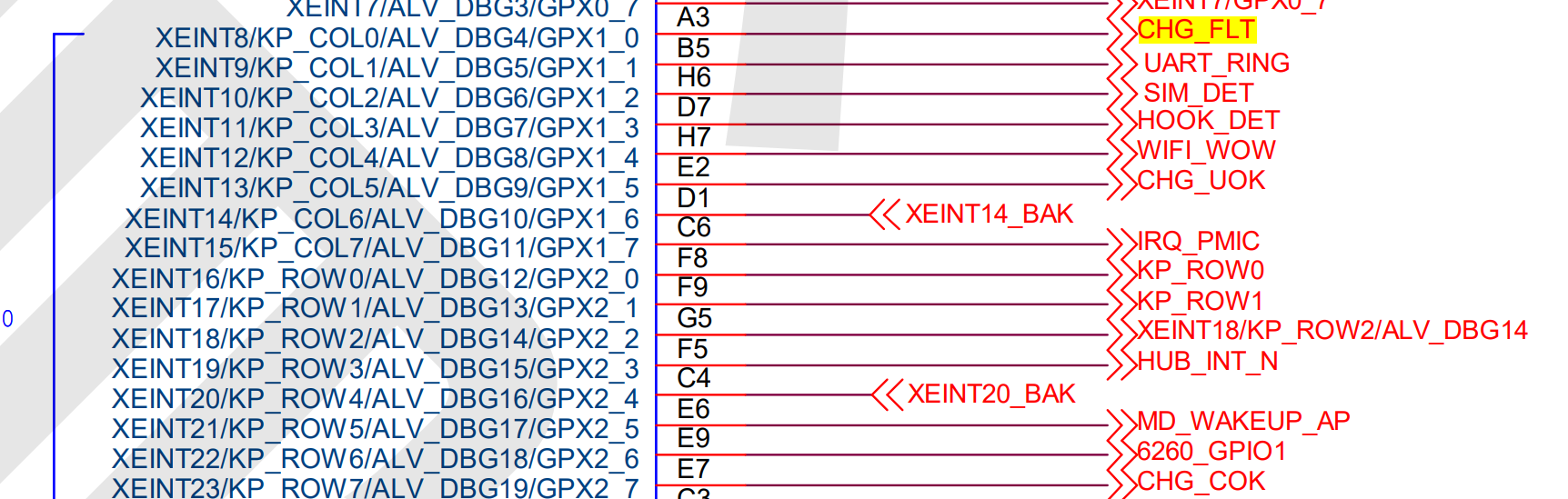

查看原理图,可以获得以下信息: FS4412 目标板上的4个LED灯LED2、LED3、LED4和LED5分别接到了 Exynos4412 CPU的GPX2.7、GPX1.0、GPE3.4和GPF3.5管脚上,并且是高电平点亮,低电平熄灭。

GPX2.7 管脚对应的配置寄存器为 GPX2CON,其地址为 0x11000C40,要配置 GPX2.7管脚为输出模式,则 bit31:bit28 位应设置为 0x1。GPX2.7 管脚对应的数据寄存器为GPX2DAT,其地址为0x11000C44,要使管脚输出高电平,则 bit7 应设置为1,要使管脚输出低电平,则 bit7 应设置为 0。其他的 LED灯,都可以按照该方式进行类似的操作,在此不再赘述。
根据上面的分析,可以编写相应的驱动程序,代码如下
#ifndef _FSLED_H
#define _FSLED_H
#define FSLED_MAGIC 'f'
#define FSLED_ON _IOW(FSLED_MAGIC, 0, unsigned int)
#define FSLED_OFF _IOW(FSLED_MAGIC, 1, unsigned int)
#define LED2 0
#define LED3 1
#define LED4 2
#define LED5 3
#endif
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/cdev.h>
#include <linux/ioctl.h>
#include <linux/uaccess.h>
#include <linux/io.h>
#include <linux/ioport.h>
#include "fsled.h"
#define FSLED_MAJOR 256
#define FSLED_MINOR 0
#define FSLED_DEV_CNT 1
#define FSLED_DEV_NAME "fsled"
#define GPX2_BASE 0x11000C40
#define GPX1_BASE 0x11000C20
#define GPF3_BASE 0x114001E0
struct fsled_dev {
unsigned int __iomem *gpx2con;
unsigned int __iomem *gpx2dat;
unsigned int __iomem *gpx1con;
unsigned int __iomem *gpx1dat;
unsigned int __iomem *gpf3con;
unsigned int __iomem *gpf3dat;
atomic_t available;
struct cdev cdev;
};
static struct fsled_dev fsled;
static int fsled_open(struct inode *inode, struct file *filp)
{
if (atomic_dec_and_test(&fsled.available))
return 0;
else {
atomic_inc(&fsled.available);
return -EBUSY;
}
}
static int fsled_release(struct inode *inode, struct file *filp)
{
writel(readl(fsled.gpx2dat) & ~(0x1 << 7), fsled.gpx2dat);
writel(readl(fsled.gpx1dat) & ~(0x1 << 0), fsled.gpx1dat);
writel(readl(fsled.gpf3dat) & ~(0x3 << 4), fsled.gpf3dat);
atomic_inc(&fsled.available);
return 0;
}
static long fsled_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
if (_IOC_TYPE(cmd) != FSLED_MAGIC)
return -ENOTTY;
switch (cmd) {
case FSLED_ON:
switch(arg) {
case LED2:
writel(readl(fsled.gpx2dat) | (0x1 << 7), fsled.gpx2dat);
break;
case LED3:
writel(readl(fsled.gpx1dat) | (0x1 << 0), fsled.gpx1dat);
break;
case LED4:
writel(readl(fsled.gpf3dat) | (0x1 << 4), fsled.gpf3dat);
break;
case LED5:
writel(readl(fsled.gpf3dat) | (0x1 << 5), fsled.gpf3dat);
break;
default:
return -ENOTTY;
}
break;
case FSLED_OFF:
switch(arg) {
case LED2:
writel(readl(fsled.gpx2dat) & ~(0x1 << 7), fsled.gpx2dat);
break;
case LED3:
writel(readl(fsled.gpx1dat) & ~(0x1 << 0), fsled.gpx1dat);
break;
case LED4:
writel(readl(fsled.gpf3dat) & ~(0x1 << 4), fsled.gpf3dat);
break;
case LED5:
writel(readl(fsled.gpf3dat) & ~(0x1 << 5), fsled.gpf3dat);
break;
default:
return -ENOTTY;
}
break;
default:
return -ENOTTY;
}
return 0;
}
static struct file_operations fsled_ops = {
.owner = THIS_MODULE,
.open = fsled_open,
.release = fsled_release,
.unlocked_ioctl = fsled_ioctl,
};
static int __init fsled_init(void)
{
int ret;
dev_t dev;
dev = MKDEV(FSLED_MAJOR, FSLED_MINOR);
ret = register_chrdev_region(dev, FSLED_DEV_CNT, FSLED_DEV_NAME);
if (ret)
goto reg_err;
memset(&fsled, 0, sizeof(fsled));
atomic_set(&fsled.available, 1);
cdev_init(&fsled.cdev, &fsled_ops);
fsled.cdev.owner = THIS_MODULE;
ret = cdev_add(&fsled.cdev, dev, FSLED_DEV_CNT);
if (ret)
goto add_err;
fsled.gpx2con = ioremap(GPX2_BASE, 8);
fsled.gpx1con = ioremap(GPX1_BASE, 8);
fsled.gpf3con = ioremap(GPF3_BASE, 8);
if (!fsled.gpx2con || !fsled.gpx1con || !fsled.gpf3con) {
ret = -EBUSY;
goto map_err;
}
fsled.gpx2dat = fsled.gpx2con + 1;
fsled.gpx1dat = fsled.gpx1con + 1;
fsled.gpf3dat = fsled.gpf3con + 1;
writel((readl(fsled.gpx2con) & ~(0xF << 28)) | (0x1 << 28), fsled.gpx2con);
writel((readl(fsled.gpx1con) & ~(0xF << 0)) | (0x1 << 0), fsled.gpx1con);
writel((readl(fsled.gpf3con) & ~(0xFF << 16)) | (0x11 << 16), fsled.gpf3con);
writel(readl(fsled.gpx2dat) & ~(0x1 << 7), fsled.gpx2dat);
writel(readl(fsled.gpx1dat) & ~(0x1 << 0), fsled.gpx1dat);
writel(readl(fsled.gpf3dat) & ~(0x3 << 4), fsled.gpf3dat);
return 0;
map_err:
if (fsled.gpf3con)
iounmap(fsled.gpf3con);
if (fsled.gpx1con)
iounmap(fsled.gpx1con);
if (fsled.gpx2con)
iounmap(fsled.gpx2con);
add_err:
unregister_chrdev_region(dev, FSLED_DEV_CNT);
reg_err:
return ret;
}
static void __exit fsled_exit(void)
{
dev_t dev;
dev = MKDEV(FSLED_MAJOR, FSLED_MINOR);
iounmap(fsled.gpf3con);
iounmap(fsled.gpx1con);
iounmap(fsled.gpx2con);
cdev_del(&fsled.cdev);
unregister_chrdev_region(dev, FSLED_DEV_CNT);
}
module_init(fsled_init);
module_exit(fsled_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Kevin Jiang <jiangxg@farsight.com.cn>");
MODULE_DESCRIPTION("A simple character device driver for LEDs on FS4412 board");
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/ioctl.h>
#include <fcntl.h>
#include <errno.h>
#include "fsled.h"
int main(int argc, char *argv[])
{
int fd;
int ret;
int num = LED2;
fd = open("/dev/led", O_RDWR);
if (fd == -1)
goto fail;
while (1) {
ret = ioctl(fd, FSLED_ON, num);
if (ret == -1)
goto fail;
usleep(500000);
ret = ioctl(fd, FSLED_OFF, num);
if (ret == -1)
goto fail;
usleep(500000);
num = (num + 1) % 4;
}
fail:
perror("led test");
exit(EXIT_FAILURE);
}
在“fsled.c”文件中,代码第 21 行至第 23 行定义了 SFR 寄存器的基地址,这些地址都是通过查手册得到的。代码第 26 行至第 31 行,定义了分别用来保存6个 SFR 映射后的虚拟地址的成员。代码第 133 行至第 140行是 SFR 的映射操作,因为CON 寄存器和DAT 寄存器是连续的,所以这里每次连续映射了 8个字节(注意,这里在映射之前并没有调用request_mem_region,是因为内核中的其他驱动申请了这部分 I/O内存空间)。代码第 142行至第 144 行,是对应的 DAT 寄存器的虚拟地址计算,这里利用了指向unsigned int类型的指针加1刚好地址值加4的特点。代码第 146行至第 152行,将对应的管脚配置为输出,并且输出低电平。这里使用了较多的位操作,主要思想就是先将原来寄存器的内容读出来,然后清除相应的位,接着设置相应的位,最后再写回寄存器中。代码第175 行至第 177 行,在块卸载时解除映射。代码第 58 行至第 105行是点灯和灭灯的具体实现,首先判断了命令是否合法,然后根据是点灯还是灭灯来对单个的 LED进行具体的操作,其中arg 是要操作的 LED灯的编号。代码第50行至第52行在关闭设备文件时将所有 LED 灯熄灭。
在“testc”文件中,首先打开了LED设备,然后在while 循环中先点亮一个LED灯延时 0.5 秒后又熄灭这个LED 灯,再延时0.5秒,最后调整操作 LED 灯的编号。如此循环往复,LED灯被轮流点亮、熄灭。
八、DMA原理及映射
8.1 DMA 工作原理
DMA(Direct Memory Access,直接内存存取)是现代计算机中的一个重要特色,通过图7.7 可以比较清晰地明白其工作原理。
DMAC是 DMA 控制器,外设是一个可以收发数据的设备,比如网卡或串口CPU是一个ARM 体系结构的处理器,要将内存中的一块数据通过外设发送出去,如假定没有DMAC 的参与,那么CPU 首先通过 LDR 指令将数据读入到 CPU 的寄存器中后再通过STR 指令写入到外设的发送FIFO 中。因为外设的 FIFO不会很大(对于串口言通常只有几十个字节),如果要发送的数据很多,那么 CPU 一次只能搬移较少的一部分数据到外设的发送FIFO中。等外设将 FIFO 中的数据发送完成(或者一部分)后,外设产生一个中断,告知CPU发送FIFO不为满,CPU 将继续搬移剩下的数据到外设的发送FIFO中。整个过程中,CPU 需要不停搬移数据,会产生多次中断,这给 CPU 带来不小的负担,数据量很大时,这个问题非常突出。如果有 DMAC 参与,CPU 的参与将大大减少。其工作方式是这样的:CPU 只需要告诉 DMAC 要将某个内存起始处的若干个字节搬移到某个具体外设的发送 FIFO 中,然后启动 DMAC 控制器开始数据搬移,CPU就可以去做其他的事了。DMAC 会在存储器总线空闲时搬移数据,当所有的数据搬移完成,DMAC 产生一个中断,通知CPU 数据搬移完成。整个过程中,CPU 只是告知了源地址、目的地址和传输的字节数,再启动 DMAC,最后响应了一次中断而已。在数据量非常大的情况下,无疑这种方式会大大减轻 CPU 的负担,使 CPU 可以去做别的事情,提高了工作效率。DMAC如同CPU 的一个专门负责数据传送的助理一样。
从上面也可以知道,DMAC 要工作,需要知道几个重要的信息,那就是源地址、目的地址、传输字节数和传输方向。传输方向通常有以下四种。
(1)内存到内存:
(2)内存到外设;
(3)外设到内存
(4)外设到外设;
但不是所有的DMAC都支持这四个传输方向,比如ARM的PL330就不支持外设到外设的传输。
接下来讨论地址问题。CPU 发出的地址是物理地址,这是根据硬件设计所决定的地址,可以通过原理图和芯片手册来获得此地址。驱动开发者在 Linux 驱动代码中使用的地址为虚拟地址,通过对 MMU 编程,可以将这个虚拟地址映射到一个对应的物理地址上。最后是 DMAC看到的内存或外设的地址,这个叫总线地址,在大多数的系统中,总线地址和物理地址相同。很显然,CPU 在告知 DMAC 源地址和目的地址时,应该使用物理地址、而不是虚拟地址,因为 DMAC 通常不经过MMU。也就是说,我们在驱动中必须要将虚拟地址转换成对应的物理地址,然后再进行DMA的操作。
最后就是提取一致性的问题,现代的 CPU 内部通常都有高速缓存( cache),它可以在很大程度上提高效率。高速缓存访问速度相比于内存来说要快得多、但是容量不能很大。下而以读数据为例来说明缓存的工作方式。CPU 要去读取内存中的一段数据,首先要在高速缓存中查找是否有要读取的数据,如果有则称为缓存命中,那么 CPU 直接从缓存中获得数据,就不用再去访问慢速的内存了。如果高速缓存中没有需要的数据,那么CPU 再从内存中获取数据,同时将数据的副本放在高速缓存中,下次再访问同样的数据就可以直接从高速缓存中获取。基于程序的空间局部性和时间局部性原理,缓存的命中率通常比较高,这就大大提高了效率。但由此也引入了非常多的问题,在 DMA 传输中就存在一个典型的不一致问题。假设 DMAC按照CPU的要求将外设接收 FIFO中的数据移到了指定的内存中,但是因为高速缓存的原因,CPU 将会从缓存中获取数据,而不是从内存中获取数据,这就造成了不一致问题。同样的问题在写方向上也存在,在 ARM 体系结构中,写方向使用的是 write bufter,和cache 类似。为此,驱动程序必要保证用于DMA操作的内存关闭高速缓存这一特性。
8.2 DMA映射
DMA 映射的主要工作是找到一块适用于 DMA 操作的内存,返回其虚拟地址和总线地址并关闭高速缓存等,它是和体系结构相关的操作,后面的讨论都以ARM为例。DMA映射主要有以下几种方式。
1.一致性DMA映射
#define dma_alloc_coherent (d, s, h, f) dma_alloc_attrs(d, s, h, f, NULL)
static inline void *dma_alloc_attrs(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t flag,
struct dma_attrs *attrs);dma_alloc_coherent返回用于DMA操作的内存(DMA冲区)虚拟地址,第一个参数d是 DMA 设备,第二个参数s 是需的 DMA 冲区大小,第三个参数 h是得到的DMA 缓冲区的总线地址,第四个参数 f是内存分配掩码。在 ARM体系结构中,内核地址空间中的0xFFC00000 到 0xFFEFFFFF 共计3MB 的地址空间专门用于此类映射,它可以保证这段范围所映射到的物理内存能用于 DMA 操作,并且cache 是关团的。因为ARM的cache和MMU联系很紧密,所以通过这种方法来映射的 DMA 冲区大小应该是页大小的整数倍,如果 DMA 缓冲区远小于一页,应该考虑 DMA 池。这种射的优点是一旦DMA 缓冲区建立,就再也不用担心 cache 的一致性问题,它通常适合于DMA 缓冲区要存在于整个驱动程序的生存周期的情况。但是我们也看到,这个缓冲区只有 3MB,多个驱动都长期使用的话,最终会被分配完,导致其他驱动没有空间可以建立映射。要释放DMA 映射,需使用以下宏。
#define dma_free_coherent(d, s, c, h) dma free_attrs(d, s, c, h, NULL)
static inline void dma_free_attrs(struct device *dev, size_t size,
void *cpu_addr, dma_addr_t dma_handle,
struct dma_attrs *attrs);
其中,参数。是之前映射得到的虚拟地址。
2. 流式DMA映射
如果用于DMA操作的缓冲区不是驱动分配的,而是由内核的其他代码传递过来的,那么就需要进行流式DMA映射。比如,一个SD 卡的驱动,上层的内核代码要通过SPI设备驱动(假设 SD卡是 SPI总线连接的)来读取 SD 卡中的数据,那么上层的内核代码会传递一个缓冲区指针,而对于该缓冲区就应该建立流式 DMA 映射。
dma_map_single(d, a, s,r)
dma_unmap_single(d,a,s,r) dma_map_single: 建立流式 DMA 映射,参数 d是 DMA 设备,参数 a是上层传递来的缓冲区地址,参数S是大小,参数r是 DMA 传输方向。传输方向可以是 DMA_MEM_TO_MEM、DMA_MEM_TO_DEV、DMA_DEV_TO_MEM和DMA_DEV_TO_DEV,但不是所有的 DMAC 都支持这些方向,要查看相应的手册。
dma_unmap_single:解除流式DMA 映射。
流式DMA 映射不会长期占用一致性映射的空间,并且开销比较小,所以一般推荐使用这种方式。但是流式DMA 映射也会存在一个问题,那就是上层所给的缓冲区所对应的物理内存不一定可以用作 DMA操作。好在ARM体系结构没有像ISA总线那样的DMA内存区域限制,只要能保证虚拟内存所对应的物理内存是连续的即可,也就是说,使用常规内存这部分直接映射的内存即可。
在ARM 体系结构中,流式映射其实是通过使 cache 无效和写通操作来实现的,如果是读方向,那么DMA操作完成后,CPU 在读内存之前只要操作 cache,使这部分内存所对应的cache无效即可,这会导致CPU 在ache 中查找数据时 cache 不被命中,从而强制CPU到内存中去获取数据。对于写方向,则是设置为写通的方式,即保证 CPU 的数据会更新到DMA缓冲区中。
3,分散/聚集映射
磁盘设备通常支持分散/聚集 IO操作,例如 readv 和 writev 系统调用所生的集群磁盘 I/O 请求。对于写操作就是把虚拟地址分散的各个缓冲区的数据写入到磁盘,对于读操作就是把磁盘的数据读取到分散的各个缓冲区中。如果使用流式 DMA 映射,那就需要依次映射每一个缓冲区,DMA 操作完成后再映射下一个。这会给驱动编程造成一些麻烦如果能够一次映射多个分散的缓冲区,显然会方便得多。分散/聚集映射就是完成该任务的,主要的函数原型如下。
int dma_map_sg(struct device *dev,struct scatterlist *sg, int nents ,enum dma_data_direction dir);
void dma_unmap_sg(struct devlce *dev, sruct scatterlist *sg, int nents, enum dma_data_direction dir);
dma_map_sg:分散/聚集映射。第一个参数dev是DMA设备。第二个参数是一个指向struct scatterlist 类型数组的首元素的指针,数组中的每一个元素都描述了一个缓冲区,包括缓冲区对应的物理页框信息、缓冲区在物理页框中的偏移、缓冲区的长度和映射后得到的DMA总线地址等,围绕这个参数还有很多相关的函数,其中sg_set_buf比较常用,它用于初始化 struct scatterlist 结构中的物理页面信息,更多的函数请参考“include/linux/scatterlist.h”头文件。第三个参数 nents 是缓冲区的个数。第四个参数则是DMA的传输方向。该函数将会遍历sg数组中的每一个元素,然后对每一个缓冲区做流式DMA映射。
dma_unmap_sg:解除分散/聚集映射,各参数的含义同上
总的说来,分散/聚集映射就是一次性做多个流式 DMA 映射,为分散/聚集 I/O提供了较好的支持,也增加了编程的便利性。
4.DMA池
在讨论一致性DMA映射时,我们曾说到一致性 DMA映射适合映射比较大的缓冲区,通常是页大小的整数倍,而较小的 DMA 缓冲区则用DMA 池更适合。DMA 池和 slab配器的工作原理非常相似,就连函数接口名字也非常相似。DMA 池就是预先分配一个大的DMA 缓冲区,然后再在这个大的缓冲区中分配和释放较小的缓冲区。涉及的主要接口函数原型如下。
struct dma_pool *dma_pool_create (const char *name, struct device *dev,size_t size,size_t align, size_t boundary);
void *dma_pool_alloc(struct dma_pool *pool, gfp_t mem_flags, dma_addr_t *handle);
void dma_pool_free(struct dma_pool *pool, void *vaddr, dma_addr_t dma);
void dma_pool_destroy(struct dma_pool *pool);
dma_pool_create:创建DMA 池。第一个参数 name 是 DMA 池的名字;第二个参数是DMA 设备;第三个参数是 DMA 池的大小;第四个参数 align 是对齐值;第五个参数是边界值,设为0则由大小和对齐值来自动决定边界。函数返回DMA 池对象地址,NULL表示失败,该函数不能用于中断上下文。
dma_pool_alloc:从DMA池pool中分配一块DMA 缓冲区,mem_flags为分配掩码,handle 是回传的 DMA 总线地址。函数返回虚拟地址,NULL 表示失败。
dma_pool_free:释放 DMA 缓冲区到 DMA 池pool中。vaddr 是虚拟地址,dma 是
DMA 总线地址。
dma_pool_destroy:销毁DMA 池pool
5,回弹缓冲区
在讨论流式 DMA 映射时,我们曾说到上层所传递的缓冲区所对应的物理内存应该能够执行 DMA 操作才可以。对于像ISA 这样的总线设备而言,我们前面说过,其 DMA内存区只有低 16MB 区域,很难保证上层传递的缓冲区物理地址落在这个范围内,这就要回弹缓冲区来解决这个问题。其思路也很简单,就是在驱动中分配一块能够用于 DMA操作的缓冲区,如果是写操作,那么将上层传递下来的数据先复制到 DMA 缓冲区中(回弹缓冲区),然后再用回弹缓冲区来完成 DMA 操作。如果是读方向,那就先用回弹缓冲区完成数据的读取操作,然后再把回弹缓冲区的内容复制到上层的缓冲区中。也就是说,回弹缓冲区是一个中转站,虽然这基本抵消了DMA 带来的性能提升,但也是无奈之举。
九、 DMA统一编程接口
在早期的 Linux 内核源码中,嵌入式处理器的 DMA 部分代码是不统一的,也就是各SoC 都有自己的一套DMA编程接口(某些驱动还保了原有的接口),为了改变这一局面,内核开发了一个统一的DMA 子系统--dmaengine。它是一个软件框架,为上层的DMA 应用提供了统一的编程接口,屏蔽了底层不同 DMAC 的控制细节,大大提高了通用性,也使得上层的DMA操作变得更加容易。使用dmaengine 完成DMA数据传输,基本需要以下几个步骤。
(1)分配一个DMA 通道:
(2) 设置一些传输参数:
(3)获取一个传输描述符
(4)提交传输:
(5)启动所有挂起的传输,传输完成后回调函数被调用。
下面分别介绍这些函数所涉及的 API。
struct dma_chan *dma_request_channel(dma_cap_mask_t mask, dma_filter_fn filter_fn, void *filter_param);
typedef bool (*dma_filter_fn) (struct dma_chan *chan, void *filter_param);
int dmaengine_slave_config(struct dma_chan *chan, struct dma_slave_config *config);
struct dma_async_tx_descriptor *(*chan->device->device_prep_slave_sg) (struct dma_chan *chan, struct scatterlist *sgl,
unsigned int sg_len, enum dma_data_direction direction,unsigned long flags);
dma_cookie_t dmaengine_submit(struct dma_async_tx_descriptor *desc);
void dma_async_issue_pending (struct dma_chan *chan);
dma_request_channel:申请一个DMA 通道。第一个参数 mask 描述要申请通道的能力要求掩码,比如指定该通道要满足内存到内存传输的能力。第二个参数 filter_fn 是通道匹配过滤函数,用于指定获取某一满足要求的具体通道。第三个参数 flter_param 是传给过滤函数的参数。
dma_filter_fn;通道过滤函数的类型。
dmaengine_slave_config: 对通道进行配置。第一个参数 chan 是要配置的通道,第二个参数 config 是具体的配置信息,包括地址、方向和突发长度等。
device_prop_slave_sg:创建1个用于分散/聚集DMA操作的描述符。第一个参数chan是使用的通道:第二个参数就是使用dma_map_sg 初始化好的 struct scatterlist 数据;第三个参数sg_len是 DMA缓冲区的个数; 第四个参数 drecion 是传输的方向,第五个参数flags是DMA 传输控制的一些标志,比如 DMA_PREP_INTERRUPT 表示在传输完成后要调用回调涵数,更多的标志请参见 include/linux/dmaengine.h。和 device_prep_slave_sg类似的函数还有很多,这里不一一列举,可以通过函数的名字知道其作用,参数也基本一致。
dmaengine_submit: 提交刚才创建的传输描述符 desc,即提交传输,但是传输并没有
开始。
dma_async_issue_pending:启动通道 chan 上挂起的传输
下面以一个内存到内存的 DMA 传输实例来具体说明 dmaengine 的编程方法:
/*
* Copyright(c) 2004 - 2006 Intel Corporation. All rights reserved.
*
* This program is free software; you can redistribute it and/or modify it
* under the terms of the GNU General Public License as published by the Free
* Software Foundation; either version 2 of the License, or (at your option)
* any later version.
*
* This program is distributed in the hope that it will be useful, but WITHOUT
* ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
* FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for
* more details.
*
* You should have received a copy of the GNU General Public License along with
* this program; if not, write to the Free Software Foundation, Inc., 59
* Temple Place - Suite 330, Boston, MA 02111-1307, USA.
*
* The full GNU General Public License is included in this distribution in the
* file called COPYING.
*/
#ifndef LINUX_DMAENGINE_H
#define LINUX_DMAENGINE_H
#include <linux/device.h>
#include <linux/err.h>
#include <linux/uio.h>
#include <linux/bug.h>
#include <linux/scatterlist.h>
#include <linux/bitmap.h>
#include <linux/types.h>
#include <asm/page.h>
/**
* typedef dma_cookie_t - an opaque DMA cookie
*
* if dma_cookie_t is >0 it's a DMA request cookie, <0 it's an error code
*/
typedef s32 dma_cookie_t;
#define DMA_MIN_COOKIE 1
#define DMA_MAX_COOKIE INT_MAX
static inline int dma_submit_error(dma_cookie_t cookie)
{
return cookie < 0 ? cookie : 0;
}
/**
* enum dma_status - DMA transaction status
* @DMA_COMPLETE: transaction completed
* @DMA_IN_PROGRESS: transaction not yet processed
* @DMA_PAUSED: transaction is paused
* @DMA_ERROR: transaction failed
*/
enum dma_status {
DMA_COMPLETE,
DMA_IN_PROGRESS,
DMA_PAUSED,
DMA_ERROR,
};
/**
* enum dma_transaction_type - DMA transaction types/indexes
*
* Note: The DMA_ASYNC_TX capability is not to be set by drivers. It is
* automatically set as dma devices are registered.
*/
enum dma_transaction_type {
DMA_MEMCPY,
DMA_XOR,
DMA_PQ,
DMA_XOR_VAL,
DMA_PQ_VAL,
DMA_INTERRUPT,
DMA_SG,
DMA_PRIVATE,
DMA_ASYNC_TX,
DMA_SLAVE,
DMA_CYCLIC,
DMA_INTERLEAVE,
/* last transaction type for creation of the capabilities mask */
DMA_TX_TYPE_END,
};
/**
* enum dma_transfer_direction - dma transfer mode and direction indicator
* @DMA_MEM_TO_MEM: Async/Memcpy mode
* @DMA_MEM_TO_DEV: Slave mode & From Memory to Device
* @DMA_DEV_TO_MEM: Slave mode & From Device to Memory
* @DMA_DEV_TO_DEV: Slave mode & From Device to Device
*/
enum dma_transfer_direction {
DMA_MEM_TO_MEM,
DMA_MEM_TO_DEV,
DMA_DEV_TO_MEM,
DMA_DEV_TO_DEV,
DMA_TRANS_NONE,
};
/**
* Interleaved Transfer Request
* ----------------------------
* A chunk is collection of contiguous bytes to be transfered.
* The gap(in bytes) between two chunks is called inter-chunk-gap(ICG).
* ICGs may or maynot change between chunks.
* A FRAME is the smallest series of contiguous {chunk,icg} pairs,
* that when repeated an integral number of times, specifies the transfer.
* A transfer template is specification of a Frame, the number of times
* it is to be repeated and other per-transfer attributes.
*
* Practically, a client driver would have ready a template for each
* type of transfer it is going to need during its lifetime and
* set only 'src_start' and 'dst_start' before submitting the requests.
*
*
* | Frame-1 | Frame-2 | ~ | Frame-'numf' |
* |====....==.===...=...|====....==.===...=...| ~ |====....==.===...=...|
*
* == Chunk size
* ... ICG
*/
/**
* struct data_chunk - Element of scatter-gather list that makes a frame.
* @size: Number of bytes to read from source.
* size_dst := fn(op, size_src), so doesn't mean much for destination.
* @icg: Number of bytes to jump after last src/dst address of this
* chunk and before first src/dst address for next chunk.
* Ignored for dst(assumed 0), if dst_inc is true and dst_sgl is false.
* Ignored for src(assumed 0), if src_inc is true and src_sgl is false.
*/
struct data_chunk {
size_t size;
size_t icg;
};
/**
* struct dma_interleaved_template - Template to convey DMAC the transfer pattern
* and attributes.
* @src_start: Bus address of source for the first chunk.
* @dst_start: Bus address of destination for the first chunk.
* @dir: Specifies the type of Source and Destination.
* @src_inc: If the source address increments after reading from it.
* @dst_inc: If the destination address increments after writing to it.
* @src_sgl: If the 'icg' of sgl[] applies to Source (scattered read).
* Otherwise, source is read contiguously (icg ignored).
* Ignored if src_inc is false.
* @dst_sgl: If the 'icg' of sgl[] applies to Destination (scattered write).
* Otherwise, destination is filled contiguously (icg ignored).
* Ignored if dst_inc is false.
* @numf: Number of frames in this template.
* @frame_size: Number of chunks in a frame i.e, size of sgl[].
* @sgl: Array of {chunk,icg} pairs that make up a frame.
*/
struct dma_interleaved_template {
dma_addr_t src_start;
dma_addr_t dst_start;
enum dma_transfer_direction dir;
bool src_inc;
bool dst_inc;
bool src_sgl;
bool dst_sgl;
size_t numf;
size_t frame_size;
struct data_chunk sgl[0];
};
/**
* enum dma_ctrl_flags - DMA flags to augment operation preparation,
* control completion, and communicate status.
* @DMA_PREP_INTERRUPT - trigger an interrupt (callback) upon completion of
* this transaction
* @DMA_CTRL_ACK - if clear, the descriptor cannot be reused until the client
* acknowledges receipt, i.e. has has a chance to establish any dependency
* chains
* @DMA_PREP_PQ_DISABLE_P - prevent generation of P while generating Q
* @DMA_PREP_PQ_DISABLE_Q - prevent generation of Q while generating P
* @DMA_PREP_CONTINUE - indicate to a driver that it is reusing buffers as
* sources that were the result of a previous operation, in the case of a PQ
* operation it continues the calculation with new sources
* @DMA_PREP_FENCE - tell the driver that subsequent operations depend
* on the result of this operation
*/
enum dma_ctrl_flags {
DMA_PREP_INTERRUPT = (1 << 0),
DMA_CTRL_ACK = (1 << 1),
DMA_PREP_PQ_DISABLE_P = (1 << 2),
DMA_PREP_PQ_DISABLE_Q = (1 << 3),
DMA_PREP_CONTINUE = (1 << 4),
DMA_PREP_FENCE = (1 << 5),
};
/**
* enum dma_ctrl_cmd - DMA operations that can optionally be exercised
* on a running channel.
* @DMA_TERMINATE_ALL: terminate all ongoing transfers
* @DMA_PAUSE: pause ongoing transfers
* @DMA_RESUME: resume paused transfer
* @DMA_SLAVE_CONFIG: this command is only implemented by DMA controllers
* that need to runtime reconfigure the slave channels (as opposed to passing
* configuration data in statically from the platform). An additional
* argument of struct dma_slave_config must be passed in with this
* command.
* @FSLDMA_EXTERNAL_START: this command will put the Freescale DMA controller
* into external start mode.
*/
enum dma_ctrl_cmd {
DMA_TERMINATE_ALL,
DMA_PAUSE,
DMA_RESUME,
DMA_SLAVE_CONFIG,
FSLDMA_EXTERNAL_START,
};
/**
* enum sum_check_bits - bit position of pq_check_flags
*/
enum sum_check_bits {
SUM_CHECK_P = 0,
SUM_CHECK_Q = 1,
};
/**
* enum pq_check_flags - result of async_{xor,pq}_zero_sum operations
* @SUM_CHECK_P_RESULT - 1 if xor zero sum error, 0 otherwise
* @SUM_CHECK_Q_RESULT - 1 if reed-solomon zero sum error, 0 otherwise
*/
enum sum_check_flags {
SUM_CHECK_P_RESULT = (1 << SUM_CHECK_P),
SUM_CHECK_Q_RESULT = (1 << SUM_CHECK_Q),
};
/**
* dma_cap_mask_t - capabilities bitmap modeled after cpumask_t.
* See linux/cpumask.h
*/
typedef struct { DECLARE_BITMAP(bits, DMA_TX_TYPE_END); } dma_cap_mask_t;
/**
* struct dma_chan_percpu - the per-CPU part of struct dma_chan
* @memcpy_count: transaction counter
* @bytes_transferred: byte counter
*/
struct dma_chan_percpu {
/* stats */
unsigned long memcpy_count;
unsigned long bytes_transferred;
};
/**
* struct dma_chan - devices supply DMA channels, clients use them
* @device: ptr to the dma device who supplies this channel, always !%NULL
* @cookie: last cookie value returned to client
* @completed_cookie: last completed cookie for this channel
* @chan_id: channel ID for sysfs
* @dev: class device for sysfs
* @device_node: used to add this to the device chan list
* @local: per-cpu pointer to a struct dma_chan_percpu
* @client_count: how many clients are using this channel
* @table_count: number of appearances in the mem-to-mem allocation table
* @private: private data for certain client-channel associations
*/
struct dma_chan {
struct dma_device *device;
dma_cookie_t cookie;
dma_cookie_t completed_cookie;
/* sysfs */
int chan_id;
struct dma_chan_dev *dev;
struct list_head device_node;
struct dma_chan_percpu __percpu *local;
int client_count;
int table_count;
void *private;
};
/**
* struct dma_chan_dev - relate sysfs device node to backing channel device
* @chan: driver channel device
* @device: sysfs device
* @dev_id: parent dma_device dev_id
* @idr_ref: reference count to gate release of dma_device dev_id
*/
struct dma_chan_dev {
struct dma_chan *chan;
struct device device;
int dev_id;
atomic_t *idr_ref;
};
/**
* enum dma_slave_buswidth - defines bus with of the DMA slave
* device, source or target buses
*/
enum dma_slave_buswidth {
DMA_SLAVE_BUSWIDTH_UNDEFINED = 0,
DMA_SLAVE_BUSWIDTH_1_BYTE = 1,
DMA_SLAVE_BUSWIDTH_2_BYTES = 2,
DMA_SLAVE_BUSWIDTH_4_BYTES = 4,
DMA_SLAVE_BUSWIDTH_8_BYTES = 8,
};
/**
* struct dma_slave_config - dma slave channel runtime config
* @direction: whether the data shall go in or out on this slave
* channel, right now. DMA_MEM_TO_DEV and DMA_DEV_TO_MEM are
* legal values.
* @src_addr: this is the physical address where DMA slave data
* should be read (RX), if the source is memory this argument is
* ignored.
* @dst_addr: this is the physical address where DMA slave data
* should be written (TX), if the source is memory this argument
* is ignored.
* @src_addr_width: this is the width in bytes of the source (RX)
* register where DMA data shall be read. If the source
* is memory this may be ignored depending on architecture.
* Legal values: 1, 2, 4, 8.
* @dst_addr_width: same as src_addr_width but for destination
* target (TX) mutatis mutandis.
* @src_maxburst: the maximum number of words (note: words, as in
* units of the src_addr_width member, not bytes) that can be sent
* in one burst to the device. Typically something like half the
* FIFO depth on I/O peripherals so you don't overflow it. This
* may or may not be applicable on memory sources.
* @dst_maxburst: same as src_maxburst but for destination target
* mutatis mutandis.
* @device_fc: Flow Controller Settings. Only valid for slave channels. Fill
* with 'true' if peripheral should be flow controller. Direction will be
* selected at Runtime.
* @slave_id: Slave requester id. Only valid for slave channels. The dma
* slave peripheral will have unique id as dma requester which need to be
* pass as slave config.
*
* This struct is passed in as configuration data to a DMA engine
* in order to set up a certain channel for DMA transport at runtime.
* The DMA device/engine has to provide support for an additional
* command in the channel config interface, DMA_SLAVE_CONFIG
* and this struct will then be passed in as an argument to the
* DMA engine device_control() function.
*
* The rationale for adding configuration information to this struct
* is as follows: if it is likely that most DMA slave controllers in
* the world will support the configuration option, then make it
* generic. If not: if it is fixed so that it be sent in static from
* the platform data, then prefer to do that. Else, if it is neither
* fixed at runtime, nor generic enough (such as bus mastership on
* some CPU family and whatnot) then create a custom slave config
* struct and pass that, then make this config a member of that
* struct, if applicable.
*/
struct dma_slave_config {
enum dma_transfer_direction direction;
dma_addr_t src_addr;
dma_addr_t dst_addr;
enum dma_slave_buswidth src_addr_width;
enum dma_slave_buswidth dst_addr_width;
u32 src_maxburst;
u32 dst_maxburst;
bool device_fc;
unsigned int slave_id;
};
/**
* enum dma_residue_granularity - Granularity of the reported transfer residue
* @DMA_RESIDUE_GRANULARITY_DESCRIPTOR: Residue reporting is not support. The
* DMA channel is only able to tell whether a descriptor has been completed or
* not, which means residue reporting is not supported by this channel. The
* residue field of the dma_tx_state field will always be 0.
* @DMA_RESIDUE_GRANULARITY_SEGMENT: Residue is updated after each successfully
* completed segment of the transfer (For cyclic transfers this is after each
* period). This is typically implemented by having the hardware generate an
* interrupt after each transferred segment and then the drivers updates the
* outstanding residue by the size of the segment. Another possibility is if
* the hardware supports scatter-gather and the segment descriptor has a field
* which gets set after the segment has been completed. The driver then counts
* the number of segments without the flag set to compute the residue.
* @DMA_RESIDUE_GRANULARITY_BURST: Residue is updated after each transferred
* burst. This is typically only supported if the hardware has a progress
* register of some sort (E.g. a register with the current read/write address
* or a register with the amount of bursts/beats/bytes that have been
* transferred or still need to be transferred).
*/
enum dma_residue_granularity {
DMA_RESIDUE_GRANULARITY_DESCRIPTOR = 0,
DMA_RESIDUE_GRANULARITY_SEGMENT = 1,
DMA_RESIDUE_GRANULARITY_BURST = 2,
};
/* struct dma_slave_caps - expose capabilities of a slave channel only
*
* @src_addr_widths: bit mask of src addr widths the channel supports
* @dstn_addr_widths: bit mask of dstn addr widths the channel supports
* @directions: bit mask of slave direction the channel supported
* since the enum dma_transfer_direction is not defined as bits for each
* type of direction, the dma controller should fill (1 << <TYPE>) and same
* should be checked by controller as well
* @cmd_pause: true, if pause and thereby resume is supported
* @cmd_terminate: true, if terminate cmd is supported
* @residue_granularity: granularity of the reported transfer residue
*/
struct dma_slave_caps {
u32 src_addr_widths;
u32 dstn_addr_widths;
u32 directions;
bool cmd_pause;
bool cmd_terminate;
enum dma_residue_granularity residue_granularity;
};
static inline const char *dma_chan_name(struct dma_chan *chan)
{
return dev_name(&chan->dev->device);
}
void dma_chan_cleanup(struct kref *kref);
/**
* typedef dma_filter_fn - callback filter for dma_request_channel
* @chan: channel to be reviewed
* @filter_param: opaque parameter passed through dma_request_channel
*
* When this optional parameter is specified in a call to dma_request_channel a
* suitable channel is passed to this routine for further dispositioning before
* being returned. Where 'suitable' indicates a non-busy channel that
* satisfies the given capability mask. It returns 'true' to indicate that the
* channel is suitable.
*/
typedef bool (*dma_filter_fn)(struct dma_chan *chan, void *filter_param);
typedef void (*dma_async_tx_callback)(void *dma_async_param);
struct dmaengine_unmap_data {
u8 to_cnt;
u8 from_cnt;
u8 bidi_cnt;
struct device *dev;
struct kref kref;
size_t len;
dma_addr_t addr[0];
};
/**
* struct dma_async_tx_descriptor - async transaction descriptor
* ---dma generic offload fields---
* @cookie: tracking cookie for this transaction, set to -EBUSY if
* this tx is sitting on a dependency list
* @flags: flags to augment operation preparation, control completion, and
* communicate status
* @phys: physical address of the descriptor
* @chan: target channel for this operation
* @tx_submit: set the prepared descriptor(s) to be executed by the engine
* @callback: routine to call after this operation is complete
* @callback_param: general parameter to pass to the callback routine
* ---async_tx api specific fields---
* @next: at completion submit this descriptor
* @parent: pointer to the next level up in the dependency chain
* @lock: protect the parent and next pointers
*/
struct dma_async_tx_descriptor {
dma_cookie_t cookie;
enum dma_ctrl_flags flags; /* not a 'long' to pack with cookie */
dma_addr_t phys;
struct dma_chan *chan;
dma_cookie_t (*tx_submit)(struct dma_async_tx_descriptor *tx);
dma_async_tx_callback callback;
void *callback_param;
struct dmaengine_unmap_data *unmap;
#ifdef CONFIG_ASYNC_TX_ENABLE_CHANNEL_SWITCH
struct dma_async_tx_descriptor *next;
struct dma_async_tx_descriptor *parent;
spinlock_t lock;
#endif
};
#ifdef CONFIG_DMA_ENGINE
static inline void dma_set_unmap(struct dma_async_tx_descriptor *tx,
struct dmaengine_unmap_data *unmap)
{
kref_get(&unmap->kref);
tx->unmap = unmap;
}
struct dmaengine_unmap_data *
dmaengine_get_unmap_data(struct device *dev, int nr, gfp_t flags);
void dmaengine_unmap_put(struct dmaengine_unmap_data *unmap);
#else
static inline void dma_set_unmap(struct dma_async_tx_descriptor *tx,
struct dmaengine_unmap_data *unmap)
{
}
static inline struct dmaengine_unmap_data *
dmaengine_get_unmap_data(struct device *dev, int nr, gfp_t flags)
{
return NULL;
}
static inline void dmaengine_unmap_put(struct dmaengine_unmap_data *unmap)
{
}
#endif
static inline void dma_descriptor_unmap(struct dma_async_tx_descriptor *tx)
{
if (tx->unmap) {
dmaengine_unmap_put(tx->unmap);
tx->unmap = NULL;
}
}
#ifndef CONFIG_ASYNC_TX_ENABLE_CHANNEL_SWITCH
static inline void txd_lock(struct dma_async_tx_descriptor *txd)
{
}
static inline void txd_unlock(struct dma_async_tx_descriptor *txd)
{
}
static inline void txd_chain(struct dma_async_tx_descriptor *txd, struct dma_async_tx_descriptor *next)
{
BUG();
}
static inline void txd_clear_parent(struct dma_async_tx_descriptor *txd)
{
}
static inline void txd_clear_next(struct dma_async_tx_descriptor *txd)
{
}
static inline struct dma_async_tx_descriptor *txd_next(struct dma_async_tx_descriptor *txd)
{
return NULL;
}
static inline struct dma_async_tx_descriptor *txd_parent(struct dma_async_tx_descriptor *txd)
{
return NULL;
}
#else
static inline void txd_lock(struct dma_async_tx_descriptor *txd)
{
spin_lock_bh(&txd->lock);
}
static inline void txd_unlock(struct dma_async_tx_descriptor *txd)
{
spin_unlock_bh(&txd->lock);
}
static inline void txd_chain(struct dma_async_tx_descriptor *txd, struct dma_async_tx_descriptor *next)
{
txd->next = next;
next->parent = txd;
}
static inline void txd_clear_parent(struct dma_async_tx_descriptor *txd)
{
txd->parent = NULL;
}
static inline void txd_clear_next(struct dma_async_tx_descriptor *txd)
{
txd->next = NULL;
}
static inline struct dma_async_tx_descriptor *txd_parent(struct dma_async_tx_descriptor *txd)
{
return txd->parent;
}
static inline struct dma_async_tx_descriptor *txd_next(struct dma_async_tx_descriptor *txd)
{
return txd->next;
}
#endif
/**
* struct dma_tx_state - filled in to report the status of
* a transfer.
* @last: last completed DMA cookie
* @used: last issued DMA cookie (i.e. the one in progress)
* @residue: the remaining number of bytes left to transmit
* on the selected transfer for states DMA_IN_PROGRESS and
* DMA_PAUSED if this is implemented in the driver, else 0
*/
struct dma_tx_state {
dma_cookie_t last;
dma_cookie_t used;
u32 residue;
};
/**
* struct dma_device - info on the entity supplying DMA services
* @chancnt: how many DMA channels are supported
* @privatecnt: how many DMA channels are requested by dma_request_channel
* @channels: the list of struct dma_chan
* @global_node: list_head for global dma_device_list
* @cap_mask: one or more dma_capability flags
* @max_xor: maximum number of xor sources, 0 if no capability
* @max_pq: maximum number of PQ sources and PQ-continue capability
* @copy_align: alignment shift for memcpy operations
* @xor_align: alignment shift for xor operations
* @pq_align: alignment shift for pq operations
* @fill_align: alignment shift for memset operations
* @dev_id: unique device ID
* @dev: struct device reference for dma mapping api
* @device_alloc_chan_resources: allocate resources and return the
* number of allocated descriptors
* @device_free_chan_resources: release DMA channel's resources
* @device_prep_dma_memcpy: prepares a memcpy operation
* @device_prep_dma_xor: prepares a xor operation
* @device_prep_dma_xor_val: prepares a xor validation operation
* @device_prep_dma_pq: prepares a pq operation
* @device_prep_dma_pq_val: prepares a pqzero_sum operation
* @device_prep_dma_interrupt: prepares an end of chain interrupt operation
* @device_prep_slave_sg: prepares a slave dma operation
* @device_prep_dma_cyclic: prepare a cyclic dma operation suitable for audio.
* The function takes a buffer of size buf_len. The callback function will
* be called after period_len bytes have been transferred.
* @device_prep_interleaved_dma: Transfer expression in a generic way.
* @device_control: manipulate all pending operations on a channel, returns
* zero or error code
* @device_tx_status: poll for transaction completion, the optional
* txstate parameter can be supplied with a pointer to get a
* struct with auxiliary transfer status information, otherwise the call
* will just return a simple status code
* @device_issue_pending: push pending transactions to hardware
* @device_slave_caps: return the slave channel capabilities
*/
struct dma_device {
unsigned int chancnt;
unsigned int privatecnt;
struct list_head channels;
struct list_head global_node;
dma_cap_mask_t cap_mask;
unsigned short max_xor;
unsigned short max_pq;
u8 copy_align;
u8 xor_align;
u8 pq_align;
u8 fill_align;
#define DMA_HAS_PQ_CONTINUE (1 << 15)
int dev_id;
struct device *dev;
int (*device_alloc_chan_resources)(struct dma_chan *chan);
void (*device_free_chan_resources)(struct dma_chan *chan);
struct dma_async_tx_descriptor *(*device_prep_dma_memcpy)(
struct dma_chan *chan, dma_addr_t dest, dma_addr_t src,
size_t len, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_xor)(
struct dma_chan *chan, dma_addr_t dest, dma_addr_t *src,
unsigned int src_cnt, size_t len, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_xor_val)(
struct dma_chan *chan, dma_addr_t *src, unsigned int src_cnt,
size_t len, enum sum_check_flags *result, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_pq)(
struct dma_chan *chan, dma_addr_t *dst, dma_addr_t *src,
unsigned int src_cnt, const unsigned char *scf,
size_t len, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_pq_val)(
struct dma_chan *chan, dma_addr_t *pq, dma_addr_t *src,
unsigned int src_cnt, const unsigned char *scf, size_t len,
enum sum_check_flags *pqres, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_interrupt)(
struct dma_chan *chan, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_sg)(
struct dma_chan *chan,
struct scatterlist *dst_sg, unsigned int dst_nents,
struct scatterlist *src_sg, unsigned int src_nents,
unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_slave_sg)(
struct dma_chan *chan, struct scatterlist *sgl,
unsigned int sg_len, enum dma_transfer_direction direction,
unsigned long flags, void *context);
struct dma_async_tx_descriptor *(*device_prep_dma_cyclic)(
struct dma_chan *chan, dma_addr_t buf_addr, size_t buf_len,
size_t period_len, enum dma_transfer_direction direction,
unsigned long flags, void *context);
struct dma_async_tx_descriptor *(*device_prep_interleaved_dma)(
struct dma_chan *chan, struct dma_interleaved_template *xt,
unsigned long flags);
int (*device_control)(struct dma_chan *chan, enum dma_ctrl_cmd cmd,
unsigned long arg);
enum dma_status (*device_tx_status)(struct dma_chan *chan,
dma_cookie_t cookie,
struct dma_tx_state *txstate);
void (*device_issue_pending)(struct dma_chan *chan);
int (*device_slave_caps)(struct dma_chan *chan, struct dma_slave_caps *caps);
};
static inline int dmaengine_device_control(struct dma_chan *chan,
enum dma_ctrl_cmd cmd,
unsigned long arg)
{
if (chan->device->device_control)
return chan->device->device_control(chan, cmd, arg);
return -ENOSYS;
}
static inline int dmaengine_slave_config(struct dma_chan *chan,
struct dma_slave_config *config)
{
return dmaengine_device_control(chan, DMA_SLAVE_CONFIG,
(unsigned long)config);
}
static inline bool is_slave_direction(enum dma_transfer_direction direction)
{
return (direction == DMA_MEM_TO_DEV) || (direction == DMA_DEV_TO_MEM);
}
static inline struct dma_async_tx_descriptor *dmaengine_prep_slave_single(
struct dma_chan *chan, dma_addr_t buf, size_t len,
enum dma_transfer_direction dir, unsigned long flags)
{
struct scatterlist sg;
sg_init_table(&sg, 1);
sg_dma_address(&sg) = buf;
sg_dma_len(&sg) = len;
return chan->device->device_prep_slave_sg(chan, &sg, 1,
dir, flags, NULL);
}
static inline struct dma_async_tx_descriptor *dmaengine_prep_slave_sg(
struct dma_chan *chan, struct scatterlist *sgl, unsigned int sg_len,
enum dma_transfer_direction dir, unsigned long flags)
{
return chan->device->device_prep_slave_sg(chan, sgl, sg_len,
dir, flags, NULL);
}
#ifdef CONFIG_RAPIDIO_DMA_ENGINE
struct rio_dma_ext;
static inline struct dma_async_tx_descriptor *dmaengine_prep_rio_sg(
struct dma_chan *chan, struct scatterlist *sgl, unsigned int sg_len,
enum dma_transfer_direction dir, unsigned long flags,
struct rio_dma_ext *rio_ext)
{
return chan->device->device_prep_slave_sg(chan, sgl, sg_len,
dir, flags, rio_ext);
}
#endif
static inline struct dma_async_tx_descriptor *dmaengine_prep_dma_cyclic(
struct dma_chan *chan, dma_addr_t buf_addr, size_t buf_len,
size_t period_len, enum dma_transfer_direction dir,
unsigned long flags)
{
return chan->device->device_prep_dma_cyclic(chan, buf_addr, buf_len,
period_len, dir, flags, NULL);
}
static inline struct dma_async_tx_descriptor *dmaengine_prep_interleaved_dma(
struct dma_chan *chan, struct dma_interleaved_template *xt,
unsigned long flags)
{
return chan->device->device_prep_interleaved_dma(chan, xt, flags);
}
static inline int dma_get_slave_caps(struct dma_chan *chan, struct dma_slave_caps *caps)
{
if (!chan || !caps)
return -EINVAL;
/* check if the channel supports slave transactions */
if (!test_bit(DMA_SLAVE, chan->device->cap_mask.bits))
return -ENXIO;
if (chan->device->device_slave_caps)
return chan->device->device_slave_caps(chan, caps);
return -ENXIO;
}
static inline int dmaengine_terminate_all(struct dma_chan *chan)
{
return dmaengine_device_control(chan, DMA_TERMINATE_ALL, 0);
}
static inline int dmaengine_pause(struct dma_chan *chan)
{
return dmaengine_device_control(chan, DMA_PAUSE, 0);
}
static inline int dmaengine_resume(struct dma_chan *chan)
{
return dmaengine_device_control(chan, DMA_RESUME, 0);
}
static inline enum dma_status dmaengine_tx_status(struct dma_chan *chan,
dma_cookie_t cookie, struct dma_tx_state *state)
{
return chan->device->device_tx_status(chan, cookie, state);
}
static inline dma_cookie_t dmaengine_submit(struct dma_async_tx_descriptor *desc)
{
return desc->tx_submit(desc);
}
static inline bool dmaengine_check_align(u8 align, size_t off1, size_t off2, size_t len)
{
size_t mask;
if (!align)
return true;
mask = (1 << align) - 1;
if (mask & (off1 | off2 | len))
return false;
return true;
}
static inline bool is_dma_copy_aligned(struct dma_device *dev, size_t off1,
size_t off2, size_t len)
{
return dmaengine_check_align(dev->copy_align, off1, off2, len);
}
static inline bool is_dma_xor_aligned(struct dma_device *dev, size_t off1,
size_t off2, size_t len)
{
return dmaengine_check_align(dev->xor_align, off1, off2, len);
}
static inline bool is_dma_pq_aligned(struct dma_device *dev, size_t off1,
size_t off2, size_t len)
{
return dmaengine_check_align(dev->pq_align, off1, off2, len);
}
static inline bool is_dma_fill_aligned(struct dma_device *dev, size_t off1,
size_t off2, size_t len)
{
return dmaengine_check_align(dev->fill_align, off1, off2, len);
}
static inline void
dma_set_maxpq(struct dma_device *dma, int maxpq, int has_pq_continue)
{
dma->max_pq = maxpq;
if (has_pq_continue)
dma->max_pq |= DMA_HAS_PQ_CONTINUE;
}
static inline bool dmaf_continue(enum dma_ctrl_flags flags)
{
return (flags & DMA_PREP_CONTINUE) == DMA_PREP_CONTINUE;
}
static inline bool dmaf_p_disabled_continue(enum dma_ctrl_flags flags)
{
enum dma_ctrl_flags mask = DMA_PREP_CONTINUE | DMA_PREP_PQ_DISABLE_P;
return (flags & mask) == mask;
}
static inline bool dma_dev_has_pq_continue(struct dma_device *dma)
{
return (dma->max_pq & DMA_HAS_PQ_CONTINUE) == DMA_HAS_PQ_CONTINUE;
}
static inline unsigned short dma_dev_to_maxpq(struct dma_device *dma)
{
return dma->max_pq & ~DMA_HAS_PQ_CONTINUE;
}
/* dma_maxpq - reduce maxpq in the face of continued operations
* @dma - dma device with PQ capability
* @flags - to check if DMA_PREP_CONTINUE and DMA_PREP_PQ_DISABLE_P are set
*
* When an engine does not support native continuation we need 3 extra
* source slots to reuse P and Q with the following coefficients:
* 1/ {00} * P : remove P from Q', but use it as a source for P'
* 2/ {01} * Q : use Q to continue Q' calculation
* 3/ {00} * Q : subtract Q from P' to cancel (2)
*
* In the case where P is disabled we only need 1 extra source:
* 1/ {01} * Q : use Q to continue Q' calculation
*/
static inline int dma_maxpq(struct dma_device *dma, enum dma_ctrl_flags flags)
{
if (dma_dev_has_pq_continue(dma) || !dmaf_continue(flags))
return dma_dev_to_maxpq(dma);
else if (dmaf_p_disabled_continue(flags))
return dma_dev_to_maxpq(dma) - 1;
else if (dmaf_continue(flags))
return dma_dev_to_maxpq(dma) - 3;
BUG();
}
/* --- public DMA engine API --- */
#ifdef CONFIG_DMA_ENGINE
void dmaengine_get(void);
void dmaengine_put(void);
#else
static inline void dmaengine_get(void)
{
}
static inline void dmaengine_put(void)
{
}
#endif
#ifdef CONFIG_NET_DMA
#define net_dmaengine_get() dmaengine_get()
#define net_dmaengine_put() dmaengine_put()
#else
static inline void net_dmaengine_get(void)
{
}
static inline void net_dmaengine_put(void)
{
}
#endif
#ifdef CONFIG_ASYNC_TX_DMA
#define async_dmaengine_get() dmaengine_get()
#define async_dmaengine_put() dmaengine_put()
#ifndef CONFIG_ASYNC_TX_ENABLE_CHANNEL_SWITCH
#define async_dma_find_channel(type) dma_find_channel(DMA_ASYNC_TX)
#else
#define async_dma_find_channel(type) dma_find_channel(type)
#endif /* CONFIG_ASYNC_TX_ENABLE_CHANNEL_SWITCH */
#else
static inline void async_dmaengine_get(void)
{
}
static inline void async_dmaengine_put(void)
{
}
static inline struct dma_chan *
async_dma_find_channel(enum dma_transaction_type type)
{
return NULL;
}
#endif /* CONFIG_ASYNC_TX_DMA */
dma_cookie_t dma_async_memcpy_buf_to_buf(struct dma_chan *chan,
void *dest, void *src, size_t len);
dma_cookie_t dma_async_memcpy_buf_to_pg(struct dma_chan *chan,
struct page *page, unsigned int offset, void *kdata, size_t len);
dma_cookie_t dma_async_memcpy_pg_to_pg(struct dma_chan *chan,
struct page *dest_pg, unsigned int dest_off, struct page *src_pg,
unsigned int src_off, size_t len);
void dma_async_tx_descriptor_init(struct dma_async_tx_descriptor *tx,
struct dma_chan *chan);
static inline void async_tx_ack(struct dma_async_tx_descriptor *tx)
{
tx->flags |= DMA_CTRL_ACK;
}
static inline void async_tx_clear_ack(struct dma_async_tx_descriptor *tx)
{
tx->flags &= ~DMA_CTRL_ACK;
}
static inline bool async_tx_test_ack(struct dma_async_tx_descriptor *tx)
{
return (tx->flags & DMA_CTRL_ACK) == DMA_CTRL_ACK;
}
#define dma_cap_set(tx, mask) __dma_cap_set((tx), &(mask))
static inline void
__dma_cap_set(enum dma_transaction_type tx_type, dma_cap_mask_t *dstp)
{
set_bit(tx_type, dstp->bits);
}
#define dma_cap_clear(tx, mask) __dma_cap_clear((tx), &(mask))
static inline void
__dma_cap_clear(enum dma_transaction_type tx_type, dma_cap_mask_t *dstp)
{
clear_bit(tx_type, dstp->bits);
}
#define dma_cap_zero(mask) __dma_cap_zero(&(mask))
static inline void __dma_cap_zero(dma_cap_mask_t *dstp)
{
bitmap_zero(dstp->bits, DMA_TX_TYPE_END);
}
#define dma_has_cap(tx, mask) __dma_has_cap((tx), &(mask))
static inline int
__dma_has_cap(enum dma_transaction_type tx_type, dma_cap_mask_t *srcp)
{
return test_bit(tx_type, srcp->bits);
}
#define for_each_dma_cap_mask(cap, mask) \
for_each_set_bit(cap, mask.bits, DMA_TX_TYPE_END)
/**
* dma_async_issue_pending - flush pending transactions to HW
* @chan: target DMA channel
*
* This allows drivers to push copies to HW in batches,
* reducing MMIO writes where possible.
*/
static inline void dma_async_issue_pending(struct dma_chan *chan)
{
chan->device->device_issue_pending(chan);
}
/**
* dma_async_is_tx_complete - poll for transaction completion
* @chan: DMA channel
* @cookie: transaction identifier to check status of
* @last: returns last completed cookie, can be NULL
* @used: returns last issued cookie, can be NULL
*
* If @last and @used are passed in, upon return they reflect the driver
* internal state and can be used with dma_async_is_complete() to check
* the status of multiple cookies without re-checking hardware state.
*/
static inline enum dma_status dma_async_is_tx_complete(struct dma_chan *chan,
dma_cookie_t cookie, dma_cookie_t *last, dma_cookie_t *used)
{
struct dma_tx_state state;
enum dma_status status;
status = chan->device->device_tx_status(chan, cookie, &state);
if (last)
*last = state.last;
if (used)
*used = state.used;
return status;
}
/**
* dma_async_is_complete - test a cookie against chan state
* @cookie: transaction identifier to test status of
* @last_complete: last know completed transaction
* @last_used: last cookie value handed out
*
* dma_async_is_complete() is used in dma_async_is_tx_complete()
* the test logic is separated for lightweight testing of multiple cookies
*/
static inline enum dma_status dma_async_is_complete(dma_cookie_t cookie,
dma_cookie_t last_complete, dma_cookie_t last_used)
{
if (last_complete <= last_used) {
if ((cookie <= last_complete) || (cookie > last_used))
return DMA_COMPLETE;
} else {
if ((cookie <= last_complete) && (cookie > last_used))
return DMA_COMPLETE;
}
return DMA_IN_PROGRESS;
}
static inline void
dma_set_tx_state(struct dma_tx_state *st, dma_cookie_t last, dma_cookie_t used, u32 residue)
{
if (st) {
st->last = last;
st->used = used;
st->residue = residue;
}
}
#ifdef CONFIG_DMA_ENGINE
struct dma_chan *dma_find_channel(enum dma_transaction_type tx_type);
enum dma_status dma_sync_wait(struct dma_chan *chan, dma_cookie_t cookie);
enum dma_status dma_wait_for_async_tx(struct dma_async_tx_descriptor *tx);
void dma_issue_pending_all(void);
struct dma_chan *__dma_request_channel(const dma_cap_mask_t *mask,
dma_filter_fn fn, void *fn_param);
struct dma_chan *dma_request_slave_channel_reason(struct device *dev,
const char *name);
struct dma_chan *dma_request_slave_channel(struct device *dev, const char *name);
void dma_release_channel(struct dma_chan *chan);
#else
static inline struct dma_chan *dma_find_channel(enum dma_transaction_type tx_type)
{
return NULL;
}
static inline enum dma_status dma_sync_wait(struct dma_chan *chan, dma_cookie_t cookie)
{
return DMA_COMPLETE;
}
static inline enum dma_status dma_wait_for_async_tx(struct dma_async_tx_descriptor *tx)
{
return DMA_COMPLETE;
}
static inline void dma_issue_pending_all(void)
{
}
static inline struct dma_chan *__dma_request_channel(const dma_cap_mask_t *mask,
dma_filter_fn fn, void *fn_param)
{
return NULL;
}
static inline struct dma_chan *dma_request_slave_channel_reason(
struct device *dev, const char *name)
{
return ERR_PTR(-ENODEV);
}
static inline struct dma_chan *dma_request_slave_channel(struct device *dev,
const char *name)
{
return NULL;
}
static inline void dma_release_channel(struct dma_chan *chan)
{
}
#endif
/* --- DMA device --- */
int dma_async_device_register(struct dma_device *device);
void dma_async_device_unregister(struct dma_device *device);
void dma_run_dependencies(struct dma_async_tx_descriptor *tx);
struct dma_chan *dma_get_slave_channel(struct dma_chan *chan);
struct dma_chan *dma_get_any_slave_channel(struct dma_device *device);
struct dma_chan *net_dma_find_channel(void);
#define dma_request_channel(mask, x, y) __dma_request_channel(&(mask), x, y)
#define dma_request_slave_channel_compat(mask, x, y, dev, name) \
__dma_request_slave_channel_compat(&(mask), x, y, dev, name)
static inline struct dma_chan
*__dma_request_slave_channel_compat(const dma_cap_mask_t *mask,
dma_filter_fn fn, void *fn_param,
struct device *dev, char *name)
{
struct dma_chan *chan;
chan = dma_request_slave_channel(dev, name);
if (chan)
return chan;
return __dma_request_channel(mask, fn, fn_param);
}
/* --- Helper iov-locking functions --- */
struct dma_page_list {
char __user *base_address;
int nr_pages;
struct page **pages;
};
struct dma_pinned_list {
int nr_iovecs;
struct dma_page_list page_list[0];
};
struct dma_pinned_list *dma_pin_iovec_pages(struct iovec *iov, size_t len);
void dma_unpin_iovec_pages(struct dma_pinned_list* pinned_list);
dma_cookie_t dma_memcpy_to_iovec(struct dma_chan *chan, struct iovec *iov,
struct dma_pinned_list *pinned_list, unsigned char *kdata, size_t len);
dma_cookie_t dma_memcpy_pg_to_iovec(struct dma_chan *chan, struct iovec *iov,
struct dma_pinned_list *pinned_list, struct page *page,
unsigned int offset, size_t len);
#endif /* DMAENGINE_H */
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/dmaengine.h>
#include <linux/dma-mapping.h>
#include <linux/slab.h>
struct dma_chan *chan;
unsigned int *txbuf;
unsigned int *rxbuf;
dma_addr_t txaddr;
dma_addr_t rxaddr;
static void dma_callback(void *data)
{
int i;
unsigned int *p = rxbuf;
printk("dma complete\n");
for (i = 0; i < PAGE_SIZE / sizeof(unsigned int); i++)
printk("%d ", *p++);
printk("\n");
}
static bool filter(struct dma_chan *chan, void *filter_param)
{
printk("%s\n", dma_chan_name(chan));
return strcmp(dma_chan_name(chan), filter_param) == 0;
}
static int __init memcpy_init(void)
{
int i;
dma_cap_mask_t mask;
struct dma_async_tx_descriptor *desc;
char name[] = "dma2chan0";
unsigned int *p;
dma_cap_zero(mask);
dma_cap_set(DMA_MEMCPY, mask);
chan = dma_request_channel(mask, filter, name);
if (!chan) {
printk("dma_request_channel failure\n");
return -ENODEV;
}
txbuf = dma_alloc_coherent(chan->device->dev, PAGE_SIZE, &txaddr, GFP_KERNEL);
if (!txbuf) {
printk("dma_alloc_coherent failure\n");
dma_release_channel(chan);
return -ENOMEM;
}
rxbuf = dma_alloc_coherent(chan->device->dev, PAGE_SIZE, &rxaddr, GFP_KERNEL);
if (!rxbuf) {
printk("dma_alloc_coherent failure\n");
dma_free_coherent(chan->device->dev, PAGE_SIZE, txbuf, txaddr);
dma_release_channel(chan);
return -ENOMEM;
}
for (i = 0, p = txbuf; i < PAGE_SIZE / sizeof(unsigned int); i++)
*p++ = i;
for (i = 0, p = txbuf; i < PAGE_SIZE / sizeof(unsigned int); i++)
printk("%d ", *p++);
printk("\n");
memset(rxbuf, 0, PAGE_SIZE);
for (i = 0, p = rxbuf; i < PAGE_SIZE / sizeof(unsigned int); i++)
printk("%d ", *p++);
printk("\n");
desc = chan->device->device_prep_dma_memcpy(chan, rxaddr, txaddr, PAGE_SIZE, DMA_CTRL_ACK | DMA_PREP_INTERRUPT);
desc->callback = dma_callback;
desc->callback_param = NULL;
dmaengine_submit(desc);
dma_async_issue_pending(chan);
return 0;
}
static void __exit memcpy_exit(void)
{
dma_free_coherent(chan->device->dev, PAGE_SIZE, txbuf, txaddr);
dma_free_coherent(chan->device->dev, PAGE_SIZE, rxbuf, rxaddr);
dma_release_channel(chan);
}
module_init(memcpy_init);
module_exit(memcpy_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("name e-mail");
MODULE_DESCRIPTION("simple driver using dmaengine");
代码第40行和第 41 行先将掩码清零,然后设置掩码为 DMA_MEMCPY,表示要获得一个能完成内存到内存传输的 DMA 通道。代码第 42 行调用 dma_request_chamnel 来获取一个DMA 通道,filter 是通道过滤函数,name 是通道的名字。
在fiter 函数中,通过对比通道的名字来确定一个通道,驱动指定要获取 dma2chan()这个通道。因为 Exynos4412总共有 3个 DMA,其中 dma2专门用于内存到内存的传输如图7.8所示。
代码第 48行至第61行,使用dma_alloc_coherent建立了两个DMA 缓冲区的一致性映射,每个缓冲区为一页。txbuf、rxbuf 用于保存虚拟地址,txaddr、rxaddr 用于保存总线地址。代码第 63 行至第 73 行则是初始化这两片内存,用于传输完成后的验证。
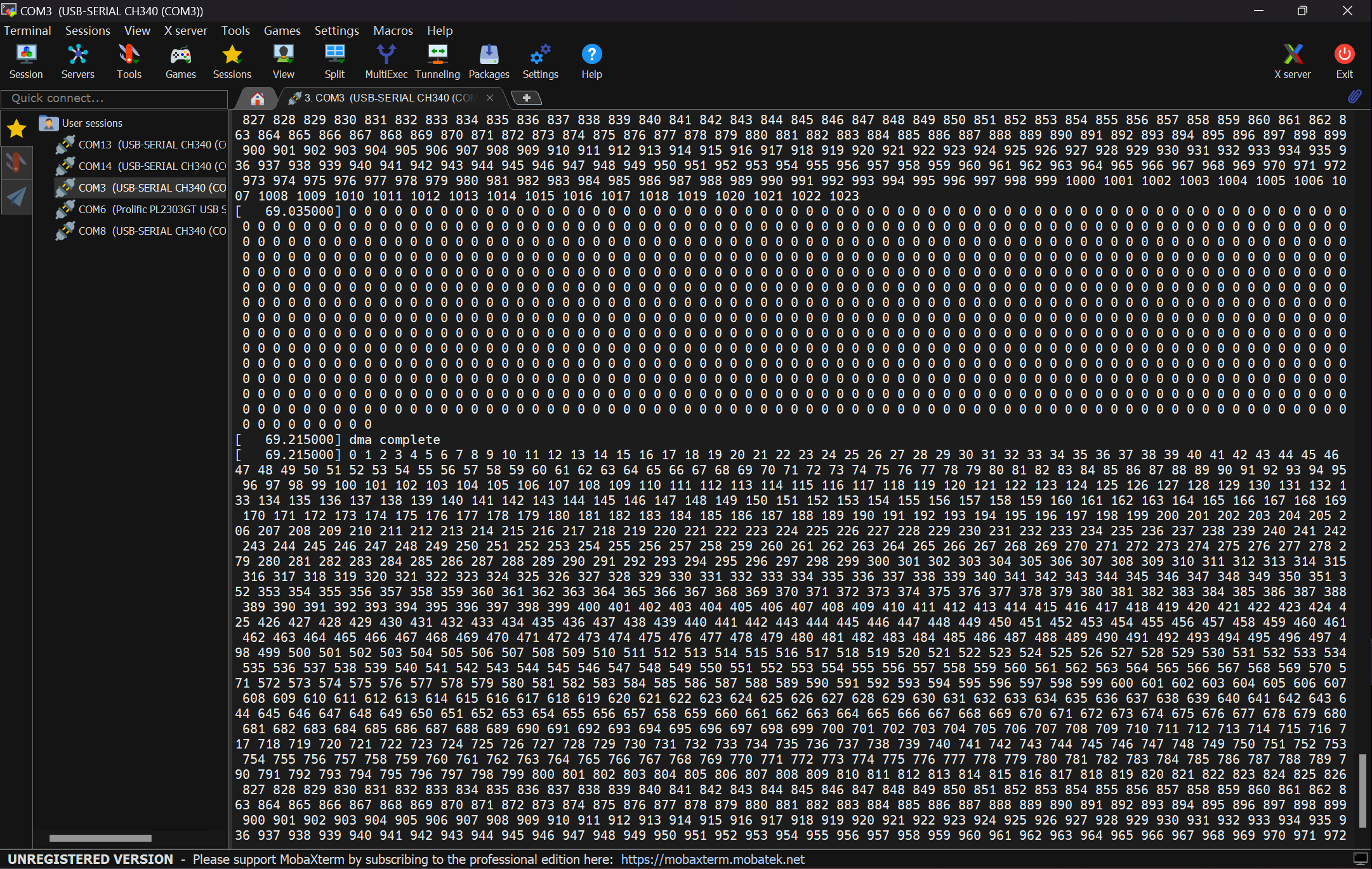
代码第 74 行至第 76 行创建了一个内存到内存的传输描述符,指定了目的地址、源地址(都是总线地址)、传输大小和一些标志,并制定了回调函数为 dma_callback,在传输完成后自动被调用。代码第 78 行和第 79 行分别是提交传输并发起传输。dma_callback在传输结束后被调用,打印了目的内存里面的内容,如果传输成功,那么目的内存的内容和源内存内容一样。
在这个例子中并没有进行传输参数设置,因为是内存到内存传输,这些参数是可以自动得到的。编译和测试的命令如下。

十、习题
1.Linux 的内存区域有 ( )。
[B]ZONE NORMAL[A]ZONE DMA[C] ZONE HIGHMEM
2. alloc_pages 函数的 order 参数表示 ( )。
[A]分配的页数为 order
[B] 分配的页数为2的order 次方
3.如果指定了 GFP HIGHMEM,表示可以在哪些区域分配内存 ()。
[A]ZONE DMAB]ZONE NORMAL [C]ZONE HIGHMEM
4.用于永映射的函数是( )
[A] kmap
[B] kmap_atomic
5.用于临时映射的函数是( )
[A] kmap
[B] kmap_atomic
6.在内核中如果要分配 128 个字节,使用下面哪个函数比较合适()。
[A] alloc_page
[B]__get_free_pages
[C] malloc
[D] kmalloc
7.能分配大块内存,但物理地址空间不一定连续的函数是( )。
[A] vmalloc
[B]_get_free_pages
[C] malloc
[D] kmalloc
8.per-CPU变量指的是()。
[A] 每个 CPU有一个变量的副本
[B]多个CPU公用一个变量
9.映射I/0内存的函数是( )。
[B] ioremap
[A) kmap
10.DMA 的传输方向有 ( )。
[A] 内存到内存[B] 内存到外设 [C] 外设到内存[D] 外设到外设
11.DMA 内存有哪几种形式()。
[B]流式DMA映射
[A] 一致性 DMA 映射
[C]分散/聚集映射
[D]DMA池
[E]回弹缓冲区
12.使用 dmaengine 完成DMA 数据传输,一般需要哪些步骤(
[A]分配一个DMA 通道[C] 获取一个传输描述符
[B] 设置一些传输参数
[D] 提交传输
[E] 启动所有挂起的传输,传输完成后回调函数被调用
------------------------------------------------------------------------------------------------------------------------------
答案: 1、ABC 2、B 3、ABC 4、A 5、B 6、D 7、A 8、A 9、B 10、ABCD
11、 ABCDE 12、ABCDE