前言:学习《简明 Python 教程》Swaroop, C. H. 著 沈洁元 译 www.byteofpython.info 摘录,方便以后使用查阅。
基础概念
常量
Python中有4种类型的数——整数、长整数、浮点数和复数。
- 2是一个整数的例子。
- 长整数不过是大一些的整数。
- 3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
- (-5+4j)和(2.3-4.6j)是复数的例子。
字符串
字符串是 字符的序列 。字符串基本上就是一组单词。
(1)使用单引号(‘)
如同’Quote me on this’这样。所有的空白,即空格和制表符都照原样保留。
(2)使用双引号(“)
在双引号中的字符串与单引号中的字符串的使用完全相同,例如"What’s your name?”。
(3)使用三引号(’''或"“”)
利用三引号,可以指示一个多行的字符串。可以在三引号中自由的使用单引号和双引号。例如:
'''This is a multi-line string. This is the first line.
This is the second line.
"What's your name?," I asked.
He said "Bond, James Bond."
'''
(4)转义符
在一个字符串中包含一个单引号(‘),可以通过 转义符 来完成这个任务。用’来指示单引号——注意这个反斜杠。现在可以把字符串表示为’What’s your name?’。
另一个表示这个特别的字符串的方法是"What’s your name?",即用双引号。类似地,要在双引号字符串中使用双引号本身的时候,也可以借助于转义符。另外,你可以用转义符\来指示反斜杠本身。
(5)换行
在一个字符串中,行末的单独一个反斜杠表示字符串在下一行继续,而不是开始一个新的行。例如:
"This is the first sentence.\
This is the second sentence."
(6)自然字符串
指示某些不需要如转义符那样的特别处理的字符串,需要指定一个自然字符串。自然字符串通过给字符串加上前缀r或R来指定。例如r"Newlines are indicated by \n"。
(7)Unicode字符串
Unicode是书写国际文本的标准方法。如果用如北印度语或阿拉伯语写文本,那么需要有一个支持Unicode的编辑器。类似地,Python允许处理Unicode文本——只需要在字符串前加上前缀u或U。例如,u"This is a Unicode string.“。
处理文本文件的时候使用Unicode字符串,特别是当知道这个文件含有用非英语的语言写的文本。
(8)字符串是不可变的
一旦你创造了一个字符串,就不能再改变它了。
(9)按字面意义级连字符串
如果把两个字符串按字面意义相邻放着,他们会被Python自动级连。例如,‘What’s’ 'your name?'会被自动转为"What’s your name?”。
(10)给C/C++程序员的注释
在Python中没有专门的char数据类型。确实没有需要有这个类型。
变量
标识符的命名
变量是标识符的例子。 标识符 是用来标识 某样东西 的名字。命名规则:
- 标识符的第一个字符必须是字母表中的字母(大写或小写)或者一个下划线(‘ _ ’)。
- 标识符名称的其他部分可以由字母(大写或小写)、下划线(‘ _ ’)或数字(0-9)组成。
- 标识符名称是对大小写敏感的。例如,myname和myName不是一个标识符。注意前者中的小写n和 后者中的大写N。
- 有效标识符名称的例子有i、__my_name、name_23和a1b2_c3。
- 无效 标识符名称的例子有2things、this is spaced out和my-name。
数据类型
变量可以处理不同类型的值,称为数据类型。基本的类型是数和字符串,可以用类创造我们自己的类型。
对象
Python把在程序中用到的任何东西都称为 对象 。这是从广义上说的。因此不会说“某某 东西”,会说“某个 对象 ”。
给面向对象编程用户的注释
就每一个东西包括数、字符串甚至函数都是对象这一点来说,Python是极其完全地面向对象的。
例子:看一下如何使用变量和字面意义上的常量
如何编写Python程序
下面是保存和运行Python程序的标准流程。
- 打开最喜欢的编辑器。
- 输入例子中的程序代码。
- 用注释中给出的文件名把它保存为一个文件。按照惯例把所有的Python程序都以扩展名.py保存。
- 运行解释器命令python program.py或者使用IDLE运行程序。也可以使用先前介绍的可执行的方法。
//例 使用变量和字面意义上的常量
# Filename : var.py
i = 5
print i
i = i + 1
print i
s = '''This is a multi-line string.
This is the second line.'''
print s
//输出
$ python var.py
56
This is a multi-line string.
This is the second line.
使用赋值运算符(=)把一个字面意义上的常数5赋给变量i,这一行称为一个语句。用print语句打印i的值,就是把变量的值打印在屏幕上。类似地,把一个字面意义上的字符串赋给变量s然后打印它。
给C/C++程序员的注释
使用变量时只需要给它们赋一个值。不需要声明或定义数据类型。
逻辑行与物理行
物理行是在编写程序时所 看见 的。逻辑行是Python 看见 的单个语句。Python假定每个 物理行 对应一个 逻辑行 。
逻辑行的例子如print 'Hello World’这样的语句——如果它本身就是一行(就像在编辑器中看到的那样),那么它也是一个物理行。
默认地,Python希望每行都只使用一个语句,这样使得代码更加易读。
//如果想要在一个物理行中使用多于一个逻辑行,那么你需要使用分号(;)来特别地标明这种用法。分号表示一个逻辑行/语句的结束。例如:
i = 5
print i
//与下面这个相同:
i = 5;
print i;
//同样也可以写成:
i = 5; print i;
//甚至可以写成:
i = 5; print i
**强烈建议坚持在每个物理行只写一句逻辑行。**仅仅当逻辑行太长的时候,在多于一个物理行写一个逻辑行。尽可能避免使用分号,从而让代码更加易读。
# 下面是一个在多个物理行中写一个逻辑行的例子。它被称为**明确的行连接**。
s = 'This is a string. \
This continues the string.'
print s
//它的输出:
This is a string. This continues the string.
//类似地,
print \
i
//与如下写法效果相同:
print i
有一种暗示的假设,可以不需要使用反斜杠。这种情况出现在逻辑行中使用了圆括号、方括号或波形括号的时候。这被称为暗示的行连接。
缩进
空白在Python中是重要的。事实上行首的空白是重要的。它称为缩进。在逻辑行首的空白(空格和制表符)用来决定逻辑行的缩进层次,从而用来决定语句的分组。
同一层次的语句必须有相同的缩进。每一组这样的语句称为一个块。
# 错误的缩进会引发错误。例如:
i = 5
print 'Value is', i # Error! Notice a single space at the start of the line
print 'I repeat, the value is', i
# 运行这个程序的时候,会得到下面的错误:
File "whitespace.py", line 4
print 'Value is', i # Error! Notice a single space at the start of the line
^
SyntaxError: invalid syntax
注意,在第二行的行首有一个空格。Python指示的这个错误告诉我们程序的语法是无效的,即程序没有正确地编写。
如何缩进
不要混合使用制表符和空格来缩进,因为这在跨越不同的平台的时候,无法正常工作。强烈建议 在每个缩进层次使用 单个制表符 或 两个或四个空格 。 选择这三种缩进风格之一。更加重要的是,选择一种风格,然后一贯地使用它,即 只 使用这一种风格。
运算符与表达式
定义
一个简单的表达式例子如2 + 3。一个表达式可以分解为运算符和操作数。
运算符 的功能是完成某件事,它们由如+这样的符号或者其他特定的关键字表示。运算符需要数据来进行运算,这样的数据被称为 操作数 。在这个例子中,2和3是操作数。
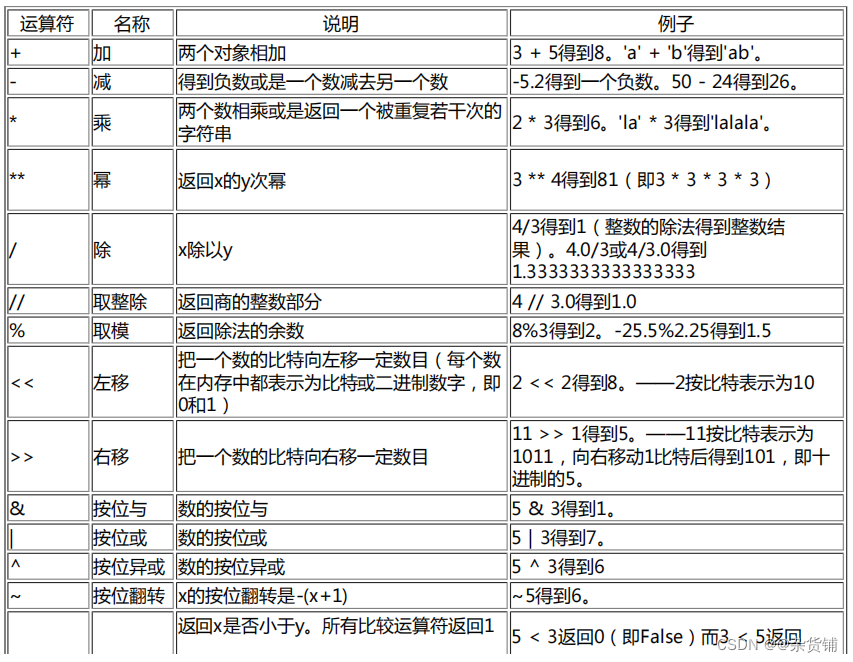
运算符
表 运算符与它们的用法

运算符优先级
使用圆括号来分组运算符和操作数,以便能够明确地指出运算的先后顺序,使程序尽可能地易读。
表 运算符优先级


计算顺序
运算符优先级表决定了哪个运算符在别的运算符之前计算。然而,如果想要改变它们的计算顺序,得使用圆括号。例如,想要在一个表达式中让加法在乘法之前计算,那么就得写成类似(2 +3) * 4的样子。
结合规律
运算符通常由左向右结合,即具有相同优先级的运算符按照从左向右的顺序计算。例如,2 + 3 + 4被计算成(2 + 3) + 4。一些如赋值运算符那样的运算符是由右向左结合的,即a = b = c被处理为a = (b = c)。
表达式
使用表达式的例子:
#例 使用表达式
#!/usr/bin/python
# Filename: expression.py
length = 5
breadth = 2
area = length * breadth
print 'Area is', area
print 'Perimeter is', 2 * (length + breadth)
# 输出
$ python expression.py
Area is 10
Perimeter is 14
表达式length * breadth的结果存储在变量area中,然后用print语句打印。在另一个打印语句中,直接使用表达式2 * (length + breadth)的值。
注意Python如何打印“漂亮的”输出。尽管没有在’Area is’和变量area之间指定空格,Python自动在那里放了一个空格,这样就可以得到一个清晰漂亮的输出,而程序也变得更加易读(因为不需要担心输出之间的空格问题)。
控制流
在Python中有三种控制流语句 ——if、for和while。
if语句
if语句用来检验一个条件, 如果 条件为真,运行一块语句(称为 if-块 ), 否则 处理另外一块语句(称为 else-块 )。 else 从句是可选的。
#例 使用if语句
#!/usr/bin/python
# Filename: if.py
number = 23
guess = int(raw_input('Enter an integer : '))
if guess == number:
print 'Congratulations, you guessed it.' # New block starts here
print "(but you do not win any prizes!)" # New block ends here
elif guess < number:
print 'No, it is a little higher than that' # Another block
# You can do whatever you want in a block ...
else:
print 'No, it is a little lower than that'
# you must have guess > number to reach here
print 'Done'
# This last statement is always executed, after the if statement is executed
# 输出
$ python if.py
Enter an integer : 50
No, it is a little lower than that
Done
$ python if.py
Enter an integer : 22
No, it is a little higher than that
Done
$ python if.py
Enter an integer : 23
Congratulations, you guessed it.
(but you do not win any prizes!)
Done
使用raw_input()函数取得用户猜测的数字。为内建的raw_input函数提供一个字符串,这个字符串被打印在屏幕上,然后等待用户的输入。一旦输入一些东西,然后按回车键之后,函数返回输入。 对于raw_input函数来说是一个字符串。通过int把这个字符串转换为整数,并把它存储在变量guess中。 事实上,int是一个类,不过在对它所需了解的只是它把一个字符串转换为一个整数(假设这个字符串含有一个有效的整数文本信息)。
elif和else部分是可选的。一个最简单的有效if语句是:
if True:
print ‘Yes, it is true’
在Python执行完一个完整的if语句以及与它相关联的elif和else从句之后,它移向if语句块的下一个语句。在这个例子中,这个语句块是主块。程序从主块开始执行,而下一个语句是print 'Done’语句。在这之后,Python看到程序的结尾,简单的结束运行。
给C/C++程序员的注释
在Python中没有switch语句。可以使用if…elif…else语句来完成同样的工作(在某些场合,使用字典会更加快捷。)
while语句
只要在一个条件为真的情况下,while语句允许你重复执行一块语句。while语句是所谓 循环 语句的一个例子。while语句有一个可选的else从句。
#例 使用while语句
#!/usr/bin/python
# Filename: while.py
number = 23
running = True
while running:
guess = int(raw_input('Enter an integer : '))
if guess == number:
print 'Congratulations, you guessed it.'
running = False # this causes the while loop to stop
elif guess < number:
print 'No, it is a little higher than that'
else:
print 'No, it is a little lower than that'
else:
print 'The while loop is over.'
# Do anything else you want to do here
print 'Done'
#输出
$ python while.py
Enter an integer : 50
No, it is a little lower than that.
Enter an integer : 22
No, it is a little higher than that.
Enter an integer : 23
Congratulations, you guessed it.
The while loop is over.
Done
把raw_input和if语句移到了while循环内,并且在while循环开始前把running变量设置为True。首先,检验变量running是否为True,然后执行后面的 while-块 。在执行了这块程序之后,再次检验条件,在这个例子中,条件是running变量。如果它是真的,再次执行while-块,否则,继续执行可选的else-块,并接着执行下一个语句。
当while循环条件变为False的时候,else块才被执行 ——这甚至也可能是在条件第一次被检验的时候。如果while循环有一个else从句,它将始终被执行,除非你的while循环将永远循环下去不会结束!
True和False被称为布尔类型。你可以分别把它们等效地理解为值1和0。在检验重要条件的时候,布尔类型十分重要,它们并不是真实的值1。
else块事实上是多余的,因为可以把其中的语句放在同一块(与while相同)中,跟在while语句之后,这样可以取得相同的效果。
给C/C++程序员的注释
记住,你可以在while循环中使用一个else从句。
for循环
for…in是另外一个循环语句,它在一序列的对象上 递归 即逐一使用队列中的每个项目。
#例 使用for语句
#!/usr/bin/python
# Filename: for.py
for i in range(1, 5):
print i
else:
print 'The for loop is over'
#输出
$ python for.py
1
2
3
4
The for loop is over
range返回一个序列的数。这个序列从第一个数开始到第二个数为止。例如,range(1,5)给出序列[1, 2, 3, 4]。默认地,range的步长为1。如果我们为range提供第三个数,那么它将成为步长。例如,range(1,5,2)给出[1,3]。记住,range 向上 延伸到第二个数,即它不包含第二个数。
记住,else部分是可选的。如果包含else,它总是在for循环结束后执行一次,除非遇到break语句。
记住,for…in循环对于任何序列都适用。这里使用的是一个由内建range函数生成的数的列表,但是广义说来可以使用任何种类的由任何对象组成的序列!
给C/C++程序员的注释
Python的for循环从根本上不同于C/C++的for循环。在C/C++中,如果想要写for (int i = 0; i < 5; i++),那么用Python,写成for i in range(0,5)。你会注意到,Python的for循环更加简单、明白、不易出错。
break语句
break语句是用来 终止 循环语句的,即哪怕循环条件没有称为False或序列还没有被完全递归,也停止执行循环语句。 一个重要的注释是,如果从for或while循环中 终止 ,任何对应的循环else块将不执行。
#例 使用break语句
#!/usr/bin/python
# Filename: break.py
while True:
s = raw_input('Enter something : ')
if s == 'quit':
break
print 'Length of the string is', len(s)
print 'Done'
#输出
$ python break.py
Enter something : Programming is fun
Length of the string is 18
Enter something : When the work is done
Length of the string is 21
Enter something : if you wanna make your work also fun:
Length of the string is 37
Enter something : use Python!
Length of the string is 12
Enter something : quit
Done
在这个程序中,反复地取得用户地输入,然后打印每次输入地长度。提供了一个特别的条件来停止程序,即检验用户的输入是否是’quit’。通过 终止 循环到达程序结尾来停止程序。输入字符串的长度通过内建的len函数取得。记住,break语句也可以在for循环中使用。
continue语
continue语句被用来告诉Python跳过当前循环块中的剩余语句,然后 继续 进行下一轮循环。
#例 使用continue语句
#!/usr/bin/python
# Filename: continue.py
while True:
s = raw_input('Enter something : ')
if s == 'quit':
break
if len(s) < 3:
continue
print 'Input is of sufficient length'
# Do other kinds of processing here...
#输出
$ python continue.py
Enter something : a
Enter something : 12
Enter something : abc
Input is of sufficient length
Enter something : quit
注意,continue语句对于for循环也有效。
函数
定义
函数是重用的程序段。允许给一块语句一个名称,然后可以在程序的任何地方使用这个名称任意多次地运行这个语句块。这被称为 调用 函数。
函数通过def关键字定义。def关键字后跟一个函数的 标识符 名称,然后跟一对圆括号。圆括号之中可以包括一些变量名,该行以冒号结尾。接下来是一块语句,它们是函数体。
#例 定义函数
#!/usr/bin/python
# Filename: function1.py
def sayHello():
print 'Hello World!' # block belonging to the function
sayHello() # call the function
#输出
$ python function1.py
Hello World!
定义了一个称为sayHello的函数。这个函数不使用任何参数,因此在圆括号中没有声明任何变量。参数对于函数而言,只是给函数的输入,以便于我们可以传递不同的值给函数,然后得到相应的结果。
函数形参
函数取得的参数是提供给函数的值,这样函数就可以利用这些值 做 一些事情。这些参数就像变量一样,只不过它们的值是在我们调用函数的时候定义的,而非在函数本身内赋值。
参数在函数定义的圆括号对内指定,用逗号分割。当调用函数的时候,以同样的方式提供值。注意使用过的术语——函数中的参数名称为 形参; 而提供给函数调用的值称为 实参 。
#例 使用函数形参
#!/usr/bin/python
# Filename: func_param.py
def printMax(a, b):
if a > b:
print a, 'is maximum'
else:
print b, 'is maximum'
printMax(3, 4) # directly give literal values
x = 5
y = 7
printMax(x, y) # give variables as arguments
#输出
$ python func_param.py
4 is maximum
7 is maximum
定义了一个称为printMax的函数,这个函数需要两个形参,叫做a和b。使用if…else语句找出两者之中较大的一个数,并且打印较大的那个数。在第一个printMax使用中,直接把数,即实参,提供给函数。在第二个使用中,使用变量调用函数。printMax(x, y)使实参x的值赋给形参a,实参y的值赋给形参b。在两次调用中,printMax函数的工作完全相同。
局部变量
在函数定义内声明变量的时候,它们与函数外具有相同名称的其他变量没有任何关系,即变量名称对于函数来说是 局部 的。这称为变量的 作用域 。所有变量的作用域是它们被定义的块,从它们的名称被定义的那点开始。
#例 使用局部变量
#!/usr/bin/python
# Filename: func_local.py
def func(x):
print 'x is', x
x = 2
print 'Changed local x to', x
x = 50
func(x)
print 'x is still', x
#输出
$ python func_local.py
x is 50
Changed local x to 2
x is still 50
在函数中,第一次使用x的 值 的时候,Python使用函数声明的形参的值。接下来,把值2赋给x。x是函数的局部变量。所以,当在函数内改变x的值的时候,在主块中定义的x不受影响。 在最后一个print语句中,证明了主块中的x的值确实没有受到影响。
使用global语句
如果想要为一个定义在函数外的变量赋值,那么就得告诉Python这个变量名不是局部的,而是 全局的。使用global语句完成这一功能。没有global语句,是不可能为定义在函数外的变量赋值的。
可以使用定义在函数外的变量的值(假设在函数内没有同名的变量)。然而,并不鼓励你这样做,并且你应该尽量避免这样做,因为这使得程序的读者会不清楚这个变量是在哪里定义的。使用global语句可以清楚地表明变量是在外面的块定义的。
#例 使用global语句
#!/usr/bin/python
# Filename: func_global.py
def func():
global x
print 'x is', x
x = 2
print 'Changed local x to', x
x = 50
func()
print 'Value of x is', x
#输出
$ python func_global.py
x is 50
Changed global x to 2
Value of x is 2
global语句被用来声明x是全局的——因此,当在函数内把值赋给x的时候,这个变化也反映在在主块中使用x的值的时候。可以使用同一个global语句指定多个全局变量。例如global x, y, z。
默认参数值
对于一些函数,可能希望它的一些参数是 可选 的,如果用户不想要为这些参数提供值的话,这些参数就使用默认值。这个功能借助于默认参数值完成。可以在函数定义的形参名后加上赋值运算符(=)和默认值,从而给形参指定默认参数值。
注意,默认参数值应该是一个参数。更加准确的说,默认参数值应该是不可变的。
#例 使用默认参数值
#!/usr/bin/python
# Filename: func_default.py
def say(message, times = 1):
print message * times
say('Hello')
say('World', 5)
#输出
$ python func_default.py
Hello
WorldWorldWorldWorldWorld
名为say的函数用来打印一个字符串任意所需的次数。如果不提供一个值,那么默认地,字符串将只被打印一遍。通过给形参times指定默认参数值1来实现这一功能。
在第一次使用say的时候,只提供一个字符串,函数只打印一次字符串。在第二次使用say的时候,提供了字符串和参数5,表明想要 说 这个字符串消息5遍。
重要
只有在形参表末尾的那些参数可以有默认参数值,即你不能在声明函数形参的时候,先声明有默认值的形参而后声明没有默认值的形参。
这是因为赋给形参的值是根据位置而赋值的。例如,def func(a, b=5)是有效的,但是def func(a=5, b)是 无效 的。
关键参数
如果某个函数有许多参数,而只想指定其中的一部分,那么可以通过命名来为这些参数赋值——这被称作 关键参数 ——使用名字(关键字)而不是位置(前面默认参数所使用的方法)来给函数指定实参。
有两个 优势 ——一,由于不必担心参数的顺序,使用函数变得更加简单了。二、假设其他参数都有默认值,可以只给想要的那些参数赋值。
#例 使用关键参数
#!/usr/bin/python
# Filename: func_key.py
def func(a, b=5, c=10):
print 'a is', a, 'and b is', b, 'and c is', c
func(3, 7)
func(25, c=24)
func(c=50, a=100)
#输出
$ python func_key.py
a is 3 and b is 7 and c is 10
a is 25 and b is 5 and c is 24
a is 100 and b is 5 and c is 50
名为func的函数有一个没有默认值的参数,和两个有默认值的参数。
在第一次使用函数的时候, func(3, 7),参数a得到值3,参数b得到值7,而参数c使用默认值10。
在第二次使用函数func(25, c=24)的时候,根据实参的位置变量a得到值25。根据命名,即关键参数,参数c得到值24。变量b根据默认值,为5。
在第三次使用func(c=50, a=100)的时候,使用关键参数来完全指定参数值。注意,尽管函数定义中,a在c之前定义,仍然可以在a之前指定参数c的值。
return语句
return语句用来从一个函数 返回 即跳出函数。也可选从函数 返回一个值 。
#例 使用字面意义上的语句
#!/usr/bin/python
# Filename: func_return.py
def maximum(x, y):
if x > y:
return x
else:
return y
print maximum(2, 3)
#输出
$ python func_return.py
3
maximum函数返回参数中的最大值,在这里是提供给函数的数。它使用简单的if…else语句来找出较大的值,然后 返回 那个值。
注意,没有返回值的return语句等价于return None。None是Python中表示没有任何东西的特殊类型。例如,如果一个变量的值为None,可以表示它没有值。
除非提供自己的return语句,每个函数都在结尾暗含有return None语句。通过运行printsomeFunction(),可以明白这一点,函数someFunction没有使用return语句,如同:
def someFunction():
pass
pass语句在Python中表示一个空的语句块。
DocStrings
Python有一个很奇妙的特性,称为 文档字符串 ,它通常被简称为 docstrings 。DocStrings是一个重要的工具,由于它帮助程序文档更加简单易懂,应该尽量使用它。甚至可以在程序运行的时候,从函数恢复文档字符串!
#例 使用DocStrings
#!/usr/bin/python
# Filename: func_doc.py
def printMax(x, y):
'''Prints the maximum of two numbers.
The two values must be integers.'''
x = int(x) # convert to integers, if possible
y = int(y)
if x > y:
print x, 'is maximum'
else:
print y, 'is maximum'
printMax(3, 5)
print printMax.__doc__
#输出
$ python func_doc.py
5 is maximum
Prints the maximum of two numbers.
The two values must be integers.
**在函数的第一个逻辑行的字符串是这个函数的 文档字符串 。**注意,DocStrings也适用于模块和类。
文档字符串的惯例是一个多行字符串,它的首行以大写字母开始,句号结尾。第二行是空行,从第三行开始是详细的描述。 强烈建议 你在你的函数中使用文档字符串时遵循这个惯例。
可以使用__doc__(注意双下划线)调用printMax函数的文档字符串属性(属于函数的名称)。 请记住Python把 每一样东西 都作为对象,包括这个函数。
模块
定义
在其他程序中重用很多函数,是使用模块。 模块基本上就是一个包含了所有定义的函数和变量的文件。为了在其他程序中重用模块,模块的文件名必须以.py为扩展名。
模块可以从其他程序 输入 以便利用它的功能。这也是使用Python标准库的方法。
#例 使用sys模块
#!/usr/bin/python
# Filename: using_sys.py
import sys
print 'The command line arguments are:'
for i in sys.argv:
print i
print '\n\nThe PYTHONPATH is', sys.path, '\n'
#输出
$ python using_sys.py we are arguments
The command line arguments are:
using_sys.py
we
are
arguments
The PYTHONPATH is ['/home/swaroop/byte/code',
'/usr/lib/python23.zip',
'/usr/lib/python2.3', '/usr/lib/python2.3/plat-linux2',
'/usr/lib/python2.3/lib-tk', '/usr/lib/python2.3/libdynload',
'/usr/lib/python2.3/site-packages',
'/usr/lib/python2.3/site-packages/gtk-2.0']
- 利用import语句 输入sys模块。基本上,这句语句告诉Python,想要使用这个模块。sys模块包含了与Python解释器和它的环境有关的函数。
- 当Python执行import sys语句的时候,它在sys.path变量中所列目录中寻找sys.py模块。如果找到了这个文件,这个模块的主块中的语句将被运行,然后这个模块将能够被使用 。注意,初始化过程仅在 第一次 输入模块的时候进行。另外,“sys”是“system”的缩写。
- sys模块中的argv变量通过使用点号指明——sys.argv——这种方法的一个优势是这个名称不会与任何在其他程序中使用的argv变量冲突。另外,它也清晰地表明了这个名称是sys模块的一部分。
- sys.argv变量是一个字符串的 列表 。特别地,sys.argv包含了 命令行参数 的列表,即使用命令行传递给程序的参数。
执行python using_sys.py we are arguments的时候,使用python命令运行using_sys.py模块,后面跟着的内容被作为参数传递给程序。Python把它存储在sys.argv变量中。记住,脚本的名称总是sys.argv列表的第一个参数。所以,在这里,'using_sys.py’是sys.argv[0]、'we’是sys.argv[1]、'are’是sys.argv[2]以 及’arguments’是sys.argv[3]。注意,Python从0开始计数,而非从1开始。
sys.path包含输入模块的目录名列表。 可以观察到sys.path的第一个字符串是空的——这个空的字符串表示当前目录也是sys.path的一部分,这与PYTHONPATH环境变量是相同的。这意味着可以直接输入位于当前目录的模块。否则,得把模块放在sys.path所列的目录之一。
字节编译的.pyc文件
作用:使输入模块更加快一些。 一种方法是创建 字节编译的文件 ,这些文件以.pyc作为扩展名。字节编译的文件与Python变换程序的中
间状态有关。在下次从别的程序输入这个模块的时候,.pyc文件是十分有用的——它会快得多,因为一部分输入模块所需的处理已经完成了。另外,这些字节编译的文件也是与平台无关的。
from…import语句
如果想要直接输入argv变量到程序中(避免在每次使用它时打sys.),那么可以使用fromsys import argv语句。
如果想要输入所有sys模块使用的名字,那么可以使用 from sys import * 语句。
一般说来,应该避免使用from…import而使用import语句,因为这样可以使程序更加易读,也可以避免名称的冲突。
模块的__name__
每个模块都有一个名称,在模块中可以通过语句来找出模块的名称。这在一个场合特别有用——就如前面所提到的,当一个模块被第一次输入的时候,这个模块的主块将被运行。
假如只想在程序本身被使用的时候运行主块,而在它被别的模块输入的时候不运行主块,该怎么做呢?这可以通过模块的__name__属性完成。
#例 使用模块的__name__
#!/usr/bin/python
# Filename: using_name.py
if __name__ == '__main__':
print 'This program is being run by itself'
else:
print 'I am being imported from another module'
#输出
$ python using_name.py
This program is being run by itself
$ python
>>> import using_name
I am being imported from another module
每个Python模块都有它的__name__,如果它是’main’,这说明这个模块被用户单独运行。
制造你自己的模块
创建自己的模块。每个Python程序也是一个模块。
#例 如何创建你自己的模块
#!/usr/bin/python
# Filename: mymodule.py
def sayhi():
print 'Hi, this is mymodule speaking.'
version = '0.1'
# End of mymodule.py
上面是一个 模块 的例子。它与普通的Python程序相比并没有什么特别之处。记住这个模块应该被放置在输入它的程序的同一个目录中,或者在sys.path所列目录之一。
如何在别的Python程序中使用这个模块??
#!/usr/bin/python
# Filename: mymodule_demo.py
import mymodule
mymodule.sayhi()
print 'Version', mymodule.version
#输出
$ python mymodule_demo.py
Hi, this is mymodule speaking.
Version 0.1
注意使用了相同的点号来使用模块的成员。Python很好地重用了相同的记号。
from…import
下面是一个使用from…import语法的版本。(不推荐,容易混淆函数名或变量名)
#!/usr/bin/python
# Filename: mymodule_demo2.py
from mymodule import sayhi, version
# Alternative:
# from mymodule import *
sayhi()
print 'Version', version
dir()函数
使用内建的dir函数来列出模块定义的标识符。标识符有函数、类和变量。
当为dir()提供一个模块名的时候,它返回模块定义的名称列表。如果不提供参数,它返回当前模块中定义的名称列表。
#例 使用dir函数
$ python
>>> import sys
>>> dir(sys) # get list of attributes for sys module
['__displayhook__', '__doc__', '__excepthook__',
'__name__', '__stderr__',
'__stdin__', '__stdout__', '_getframe', 'api_version',
'argv',
'builtin_module_names', 'byteorder', 'call_tracing',
'callstats',
'copyright', 'displayhook', 'exc_clear', 'exc_info',
'exc_type',
'excepthook', 'exec_prefix', 'executable', 'exit',
'getcheckinterval',
'getdefaultencoding', 'getdlopenflags',
'getfilesystemencoding',
'getrecursionlimit', 'getrefcount', 'hexversion',
'maxint', 'maxunicode',
'meta_path','modules', 'path', 'path_hooks',
'path_importer_cache',
'platform', 'prefix', 'ps1', 'ps2', 'setcheckinterval',
'setdlopenflags',
'setprofile', 'setrecursionlimit', 'settrace', 'stderr',
'stdin', 'stdout',
'version', 'version_info', 'warnoptions']
>>> dir() # get list of attributes for current module
['__builtins__', '__doc__', '__name__', 'sys']
>>> a = 5 # create a new variable 'a'
>>> dir()
['__builtins__', '__doc__', '__name__', 'a', 'sys']
>>> del a # delete/remove a name
>>> dir()
['__builtins__', '__doc__', '__name__', 'sys']
>>>
- 在输入的sys模块上使用dir。看到它包含一个庞大的属性列表。
- 不给dir函数传递参数而使用它——默认地,它返回当前模块的属性列表。注意,输入的模块同样是列表的一部分。
- 定义一个新的变量a并且给它赋一个值,然后检验dir,观察到在列表中增加了以上相同的值。
- 使用del语句删除当前模块中的变量/属性,这个变化再一次反映在dir的输出中。
关于del的一点注释——这个语句在运行后被用来 删除 一个变量/名称。在这个例子中,del a,你将无法再使用变量a——它就好像从来没有存在过一样。
小结
模块的用处在于它能在别的程序中重用它提供的服务和功能。 Python附带的标准库就是这样一组模块的例子。学习如何使用这些模块以及如何创造自己的模块。
解决问题——编写一个Python脚本
问题
提出问题: 要一个可以为所有重要文件创建备份的程序。
分析完问题,列一张表,表示程序应该如何工作。创建下面这个列表以说明如何让它工作:
- 需要备份的文件和目录由一个列表指定。
- 备份应该保存在主备份目录中。
- 文件备份成一个zip文件。
- zip存档的名称是当前的日期和时间。
- 使用标准的zip命令,它通常默认地随Linux/Unix发行版提供。Windows用户可以使用Info-Zip程序。注意可以使用任何地存档命令,只要它有命令行界面就可以了,那样的话可以从脚本中传递参数给它。
解决方案
版本一
#例.1 备份脚本——版本一
#!/usr/bin/python
# Filename: backup_ver1.py
import os
import time
# 1. The files and directories to be backed up are specified in a list.
source = ['/home/swaroop/byte', '/home/swaroop/bin']
# If you are using Windows, use source = [r'C:\Documents', r'D:\Work'] or something like that
# 2. The backup must be stored in a main backup directory
target_dir = '/mnt/e/backup/' # Remember to change this to what you will be using
# 3. The files are backed up into a zip file.
# 4. The name of the zip archive is the current date and time
target = target_dir + time.strftime('%Y%m%d%H%M%S') + '.zip'
# 5. We use the zip command (in Unix/Linux) to put the files in a zip archive
zip_command = "zip -qr '%s' %s" % (target, ' '.join(source))
# Run the backup
if os.system(zip_command) == 0:
print 'Successful backup to', target
else:
print 'Backup FAILED'
# 输出
$ python backup_ver1.py
Successful backup to /mnt/e/backup/20041208073244.zip
使用了os和time模块,导入它们。然后,在source列表中指定需要备份的文件和目录。目标目录是想要存储备份文件的地方,它由target_dir变量指定。zip归档的名称是目前的日期和时间,使用time.strftime()函数获得。它还包括.zip扩展名,将被保存在target_dir目录中。
time.strftime()函数 需要在上面的程序中使用的那种定制。%Y会被无世纪的年份所替代。%m会被01到12之间的一个十进制月份数替代,其他依次类推。这些定制的详细情况可以在《Python参考手册》中获得。注意这些定制与用于print语句的定制(%后跟一个元组)类似(但不完全相同)。
使用加法操作符来 级连 字符串,即把两个字符串连接在一起返回一个新的字符串。 通过这种方式,创建了目标zip文件的名称。接着创建了zip_command字符串,它包含将要执行的命令。可以在shell(Linux终端或者DOS提示符)中运行它,以检验它是否工作。
zip命令有一些选项和参数。-q选项用来表示zip命令安静地工作。-r选项表示zip命令对目录递归地工作,即它包括子目录以及子目录中的文件。两个选项可以组合成缩写形式-qr。选项后面跟着待创建的zip归档的名称,然后再是待备份的文件和目录列表。使用已经学习过的字符串join方法把source列表转换为字符串。
最后,使用os.system函数 运行 命令,利用这个函数就好像在 系统 中运行命令一样。即在shell中运行命令——如果命令成功运行,它返回0,否则它返回错误号。
给Windows用户的注释
可以把source列表和target目录设置成任何文件和目录名,但是在Windows中你得小心一些。问题是Windows把反斜杠(\)作为目录分隔符,而Python用反斜杠表示转义符!所以,得使用转义符来表示反斜杠本身或者使用自然字符串。例如,使用’C:\Documents’或r’C:\Documents’而不是’C:\Documents’——你在使用一个不知名的转义符\D!
软件的实施环节或开发环节 --> 不是与所期望的完全一样 --> 回到设计环节或者调试程序。
版本二
第一个版本的脚本可以工作。然而,可以对它做些优化以便让它在日常工作中变得更好。这称为软件的维护环节。
优化之一是采用更好的文件名机制——使用 时间 作为文件名,而当前的 日期 作为目录名,存放在主备份目录中。这样做的一个优势是备份会以等级结构存储,因此它就更加容易管理了。另外一个优势是文件名的长度也可以变短。还有一个优势是采用各自独立的文件夹可以帮助方便地检验你是否在每一天创建了备份,因为只有在创建了备份,才会出现那天的目录。
#例.2 备份脚本——版本二
#!/usr/bin/python
# Filename: backup_ver2.py
import os
import time
# 1. The files and directories to be backed up are specified in a list.
source = ['/home/swaroop/byte', '/home/swaroop/bin']
# If you are using Windows, use source = [r'C:\Documents', r'D:\Work'] or something like that
# 2. The backup must be stored in a main backup directory
target_dir = '/mnt/e/backup/' # Remember to change this to what you will be using
# 3. The files are backed up into a zip file.
# 4. The current day is the name of the subdirectory in the main directory
today = target_dir + time.strftime('%Y%m%d')
# The current time is the name of the zip archive
now = time.strftime('%H%M%S')
# Create the subdirectory if it isn't already there
if not os.path.exists(today):
os.mkdir(today) # make directory
print 'Successfully created directory', today
# The name of the zip file
target = today + os.sep + now + '.zip'
# 5. We use the zip command (in Unix/Linux) to put the files in a zip archive
zip_command = "zip -qr '%s' %s" % (target, ' '.join(source))
# Run the backup
if os.system(zip_command) == 0:
print 'Successful backup to', target
else:
print 'Backup FAILED'
#输出
$ python backup_ver2.py
Successfully created directory /mnt/e/backup/20041208
Successful backup to /mnt/e/backup/20041208/080020.zip
$ python backup_ver2.py
Successful backup to /mnt/e/backup/20041208/080428.zip
改变的部分主要是:
使用os.exists函数检验在主备份目录中是否有以当前日期作为名称的目录。如果没有,我们使用os.mkdir函数创建。
意os.sep变量的用法——这会根据操作系统给出目录分隔符,即在Linux、Unix下它是’/‘,在Windows下它是’\‘,而在Mac OS下它是’:'。使用os.sep而非直接使用字符,会使程序具有移植性,可以在上述这些系统下工作。
版本三
如果有极多备份的时候,发现要区分每个备份是干什么的,会变得十分困难!
例如,可能对程序或者演讲稿做了一些重要的改变,于是想要把这些改变与zip归档的名称联系起来。这可以通过在zip归档名上附带一个用户提供的注释来方便地实现。
#例.4 备份脚本——版本四
#!/usr/bin/python
# Filename: backup_ver4.py
import os
import time
# 1. The files and directories to be backed up are specified in a list.
source = ['/home/swaroop/byte', '/home/swaroop/bin']
# If you are using Windows, use source = [r'C:\Documents', r'D:\Work'] or something like that
# 2. The backup must be stored in a main backup directory
target_dir = '/mnt/e/backup/' # Remember to change this to what you will be using
# 3. The files are backed up into a zip file.
# 4. The current day is the name of the subdirectory in the main directory
today = target_dir + time.strftime('%Y%m%d')
# The current time is the name of the zip archive
now = time.strftime('%H%M%S')
# Take a comment from the user to create the name of the zip file
comment = raw_input('Enter a comment --> ')
if len(comment) == 0: # check if a comment was entered
target = today + os.sep + now + '.zip'
else:
target = today + os.sep + now + '_' + \
comment.replace(' ', '_') + '.zip'
# Notice the backslash!
# Create the subdirectory if it isn't already there
if not os.path.exists(today):
os.mkdir(today) # make directory
print 'Successfully created directory', today
# 5. We use the zip command (in Unix/Linux) to put the files in a zip archive
zip_command = "zip -qr '%s' %s" % (target, ' '.join(source))
# Run the backup
if os.system(zip_command) == 0:
print 'Successful backup to', target
else:
print 'Backup FAILED'
# 输出
$ python backup_ver4.py
Enter a comment --> added new examples
Successful backup to
/mnt/e/backup/20041208/082156_added_new_examples.zip
$ python backup_ver4.py
Enter a comment -->
Successful backup to /mnt/e/backup/20041208/082316.zip
使用raw_input函数得到用户的注释,然后通过len函数找出输入的长度以检验用户是否确实输入了什么东西。如果用户只是按了回 车(比如这只是一个惯例备份,没有做什么特别的修改),那么就如之前那样继续操作。然而,如果提供了注释,那么它会被附加到zip归档名,就在.zip扩展名之前。注意把注释中的空格替换成下划线——这是因为处理这样的文件名要容易得多。
进一步优化
第三个版本是一个满意的工作脚本了,但是它仍然有进一步改进的空间。比如,可以在程序中包含 交互 程度——可以用-v选项来使程序更具交互性。
另一个可能的改进是使文件和目录能够通过命令行直接传递给脚本。可以通过sys.argv列表来获取它们,然后可以使用list类提供的extend方法把它们加到source列表中去。
还希望有的一个优化是使用tar命令替代zip命令。 这样做的一个 优势是在结合使用tar和gzip命令的时候,备份会更快更小。如果想要在Windows中使用这些归档,WinZip也能方便地处理这些.tar.gz文件。tar命令在大多数Linux/Unix系统中都是默认可用的。 Windows用户也可以下载安装它。
命令字符串现在将称为:
tar = ‘tar -cvzf %s %s -X /home/swaroop/excludes.txt’ % (target, ’ '.join(srcdir))
选项解释如下:
-c表示创建一个归档。
-v表示交互,即命令更具交互性。
-z表示使用gzip滤波器。
-f表示强迫创建归档,即如果已经有一个同名文件,它会被替换。
-X表示含在指定文件名列表中的文件会被排除在备份之外。例如,可以在文件中指定*~, 从而不让备份包括所有以~ 结尾的文件。
重要
最理想的创建这些归档的方法是分别使用zipfile和tarfile。它们是Python标准库的一部分,可以供使用。使用这些库就避免了使用os.system这个不推荐使用的函数,它容易引发严重的错误。然而,在本节中使用os.system的方法来创建备份,这纯粹是为了教学的需要。这样的话,例子就可以简单到让每个人都能够理解,同时也已经足够用了。
软件开发过程
编写一个软件的各个环节可以概括如下:
- 什么(分析)
- 如何(设计)
- 编写(实施)
- 测试(测试与调试)
- 使用(实施或开发)
- 维护(优化)
重要
创建这个备份脚本的过程是编写程序的推荐方法——进行分析与设计。开始时实施一个简单的版本。对它进行测试与调试。使用它以确信它如预期那样地工作。再增加任何想要的特性,根据需要一次次重复这个编写-测试-使用的周期。记住“软件是长出来的,而不是建造的”。