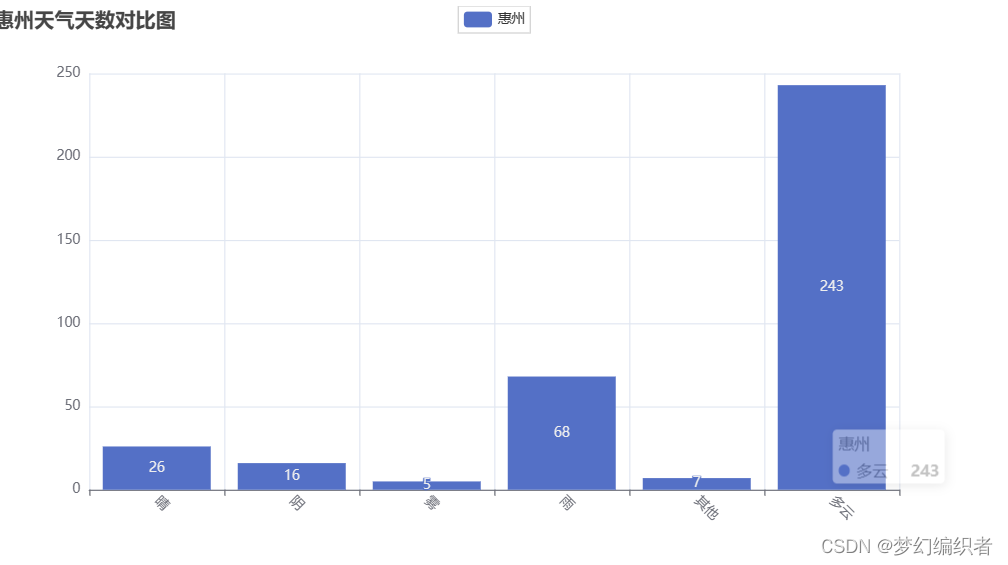
numpy
基本介绍
ufunc
接口方法的基础
reduce,聚合方法
accumulate,累计聚合
reduceat,按指定轴向、指定切片聚合
outer:外积
ndarray
数据结构的基础
数组的创建
特定的函数结构
从特定库函数创建 random系列
特定的结构创建数组
arange:类似于range函数,但可以制定任意起始、终止和步长,不限于整数
linspace:现行均匀分布,与arange类似,但第三个参数为个数
logspace:对数均匀分布
ones,ones_like 全1数组
zeros,zeros_like 全0数组
empty,empty_like 空数组
full,full_like 制定数值数组,等价于val ones()
identity:生成单位矩阵
eye:对角线是1,可以设置向上偏或向下偏
diag:接受一个数组,返回其对角线上的元素
分支主题 11
普通结构创建数组
array,从已知结构创建数组
数组增删
append,在某个维度之后追加一个或多个切片
insert:在某一维度的制定位置插入一个或多个
delete:删除某一维度的一个或多个切片
数组变形
reshape返回数组重塑形后的新数组,且元素个数必须一致
也可以通过制定shape形状来进行变形,相当于inplace操作
x.resize对数组x进行inplace操作,大小根据情况进行截断或填充0
np.resize(x)返回重塑型后的新数组,原数组x不变,元素不足时以原数组填充
返回数组的异位表示:revel()方法,flat属性
返回数组的转置形式,transpose()方法,T属性
np.title(*,reps):对数组进行复制,按数组重复
np.repeat():对数组进行复制,按元素进行重复
数组的拼接
concatenate:对多个数组沿某一轴进行拼接,要求拼接轴必须存在(即不能升维)默认是0,即行拼接,当axis=None时,先展平伟向量后执行拼接,向量的拼接是行拼接
hstack:对多个数组水平堆叠,即按照axis=1堆叠,除该列外要求其它维度相同如果是异位数组(向量),按照axis=0堆叠,此时结果仍然是一维。
column_stack:与hstack类似,只是在处理俩个一维数组堆叠时,按列向量堆叠
vstack:对于多个数组垂直堆叠,即按照axis=0堆叠,出该列外要求其它维度相同,如果是一维数组(向量),会自动reshape成1xN后执行堆叠。堆叠后至少是2维
row_stack:与vatack一致,在处理一维数组时会首先将其升至二维处理
dsack:对多个数组执行行纵深堆叠,即按照axis=2堆叠,除该列外要求其它维度相同
stack:进行升维堆叠,接受一个axis参数插入新的维度,默认为0,。与hstack和vstack不同
r_[ ]:按行堆叠,魔法方法(不是函数),效果类似于vstack
c_[ ]:按列堆叠,魔法方法(不是函数),效果类似hstack
数组的拆分
hsplit:水平切分,要求切分后大小相等,维数不变,可以切分一维数组
vsplit:垂直切分,要求切分后大小相等,维数不变,要求至少二维以上
dsplit:纵深切分,要求切分后大小相等,维数不变,至少三维数组
split:通过接收一个axis参数实现任意切分,默认axis=0,若设置axis=1或2则可分别实现vstack和dstack
array_split:前面4个方法均要求实现相同大小的子数组切分,当切分份数无法实现整除时会报错。array_split则可以适用于近似相等条件下的切分,也接受一个axis参数实现指定轴向
基本统计量
max,argmax分别返回最大值和最大值对应索引,可接收一个axis参数,指定轴线的聚合统计。对于二维及以上数组,若不指定axis,即axis=None,此时对数组所有数值求聚合统计
min,argmin,与最大一致
mean、std,分别求均值和标准差,也可接收一个缺省参数axis实现特定轴向聚合统计或全局聚合
var、cov,分别求方差和协方差,与均值标准差类似
sort、argsort,分别返回排序后的数组和相应索引,接收一个axis参数,默认为axis=-1,按最后一个轴向,若axis=None表示先展平成一维数组后再排序;另外可设置排序算法,如快排、堆排或归并等
视图和拷贝
直接赋值:无靠背,简单引用(id(a)==id(b))
view:建立视图,浅拷贝,数据公用
数据切片实质上即为建立视图
copy:实现深拷贝,完全独立
特殊常量
inf/Inf/Infinity/PINF:正无穷
NINF:负无穷
NAN/NaN/nan:非数字
pi:π
e:自然常数
np.newaxis:None的别名,一般用于数组升维
随机数包
random:返回制定个数的0-1间均匀分布的随机数
rand:接受参数作为维数,返回0-1间均匀分布随机数
uniform:接受上下界参数,返回制定大小的均匀随机数
randn:返回标准正太分布的一个随机数(均值为0,方差为1)
normal:接受期望和方差,返回制定大小的正态分布随机数(可以设定loc均值和scale方差)
permutation:返回序列的随机排列结果
shuffle:对数组进行inplace随机排列(打乱顺序,重新排列)
choice:随机从输入序列选择一个元素
seed:生成随机数种子,固化后随机结果
线性代数包
dot:全局可用,矩阵点积
vdot:无论输入维度,均按一维执行点积
linalg.qr:QR分界
linalg.svd:SVD分界
linalg.eig:求解特征值和特征向量
linalg.norm:求解范数
linalg.det:求解行列式
linalg.solve:求解Ax=b的方程
linalg.inv:求矩阵的逆
理解
理解numpy的axis
广播机制ufunc


![Ai前沿技术汇总[1]:Quivr非结构化信息搜索、Drag Your GAN AI修图、MiniGPT-4、Falcon-40B、localGPT](https://img-blog.csdnimg.cn/3e92fdb984da4305b63fda31393a70ff.png)