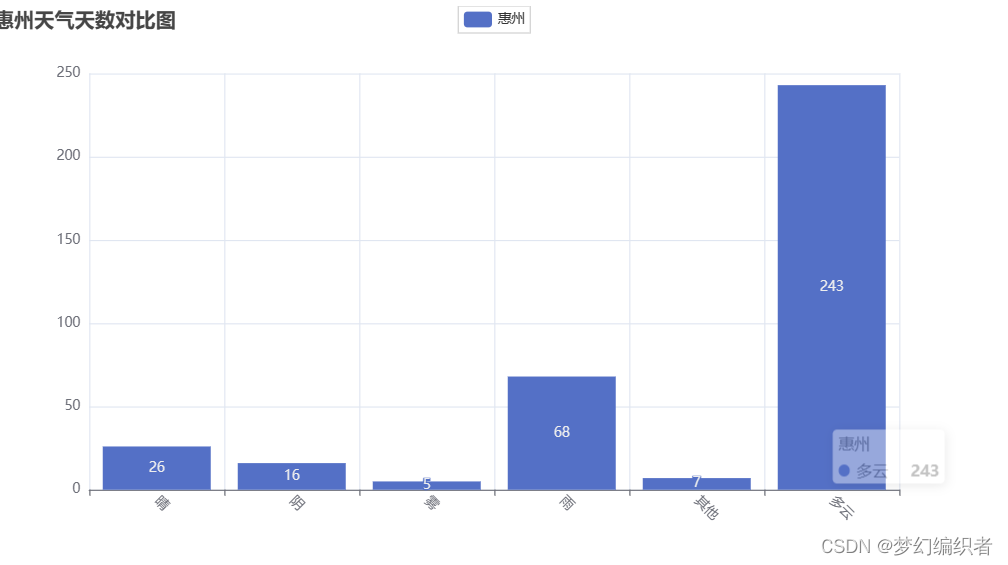
9.1 优化目标
在逻辑回归中做一些小改动变成支持向量机。
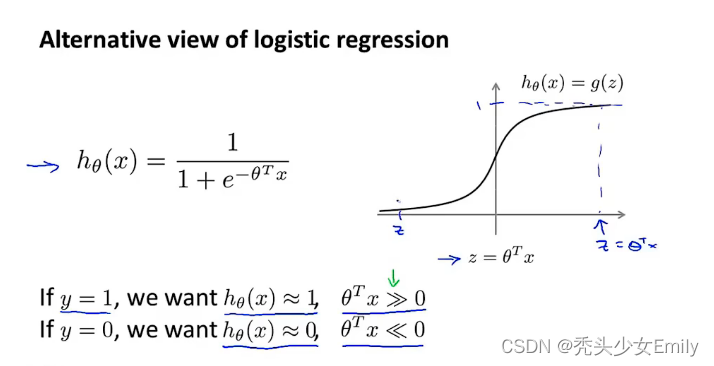
如果观察逻辑回归的代价函数,会发现每个样本(x,y)都会为总的代价函数增加如下图这一项。因此对于总的代价函数,我们通常对所有的训练样本从第1项到第m项进行求和。
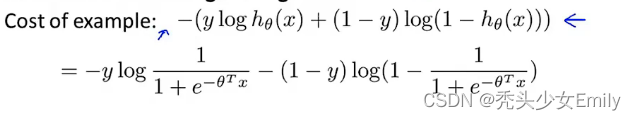
图中的这一表达式就代表每个单独的训练样本对逻辑回归的总体目标函数所作的贡献。

本部分就是把逻辑回归中的损失函数变为更简单的cost1、cost0,经过变换形成了SVM的代价函数。支持向量机在逻辑回归的基础上简化了代价函数,逻辑回归使用正则项来权衡θ的大小,以此解决过拟合的问题。SVM也是类似,它是在代价函数上添加系数C,效果等价。
代价函数:

SVM的假设函数:

可以这么理解:logistics预测的输出值是(z),是通过拟合theta获得的概率。但是SVM,优化代价函数得到theta,再直接通过theta和x的积来做分类。
9.2 直观上对最大间隔的理解
SVM又叫做最大边界分类问题,观察代价函数可以得到
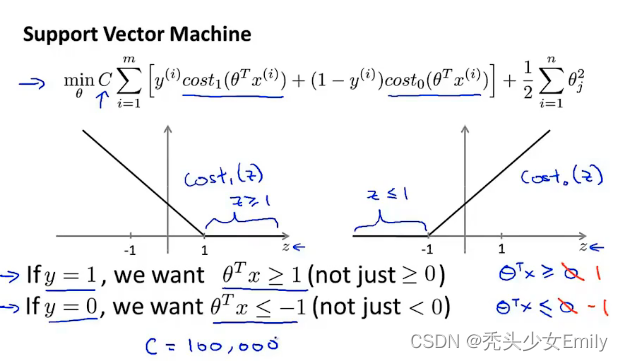
最小化代价函数,就是让左侧代价函数的和尽可能等于0,即对应,另外还有右侧的
的和最小,即向量的模尽可能小。
SVM决策边界:
当你有一个标签为y=1的训练样本,如果你要使第一项为0,那么你需要找到一个值,使得
。类似地,如果有一个标签为y=0的样本,为了使代价函数cost0(z)为0,要使
。因此我们要把优化问题看作是:通过选择参数来使得第一项等于0,那么优化问题就变成了
,它受以下条件限制:

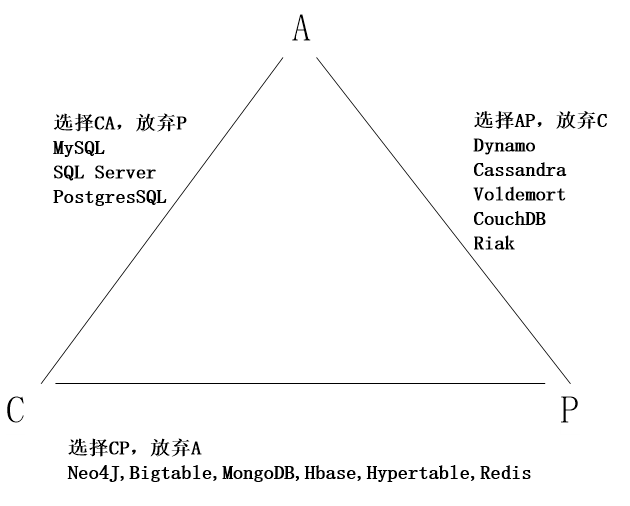
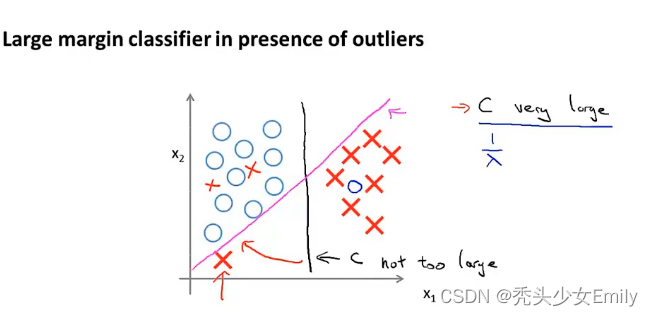
分类问题的界限有多种可能,SVM对于如下二分类的问题,往往会得到黑色的那条分界线,这条线恰好对应着最大的边界,因此也叫做最大边界分类问题。

从上图中可以发现黑色的决策边界和训练样本的最小距离要更大一些,相比之下红线和绿线它们与训练样本的间距就非常地近。在分离样本时,它们的表现会比黑线更差。因此这个距离叫做支持向量机(SVM)的间距(margin),这使得支持向量机具有鲁棒性。因为它在分离数据时会尽量用大的间距去分离。有些时候SVM被称为大间距分类器。
代价函数中的C决定了边界的划分,如果C很大对应逻辑回归的λ很小,模型过拟合,这样就会的到紫色的分界线,通过C的取值,我们可以决定边界的划分。
9.3 SVM的数学原理
向量的内积,等价于投影长度的乘积。
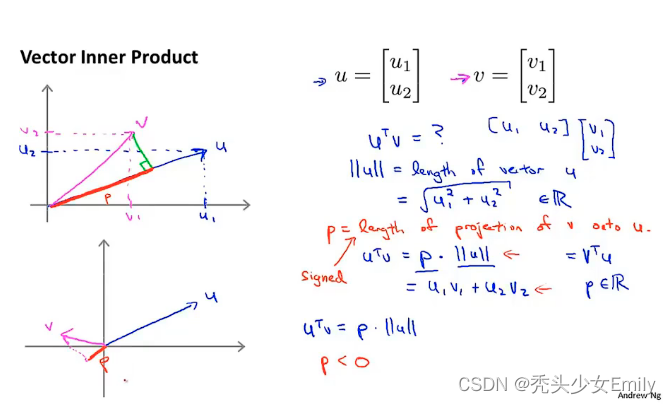
因此,可以写成
一方面优化目标促使theta变小,而另一方面约束条件又约束内积不能小于一个常数,所以theta就被迫转向能够同时满足两个条件的方向!
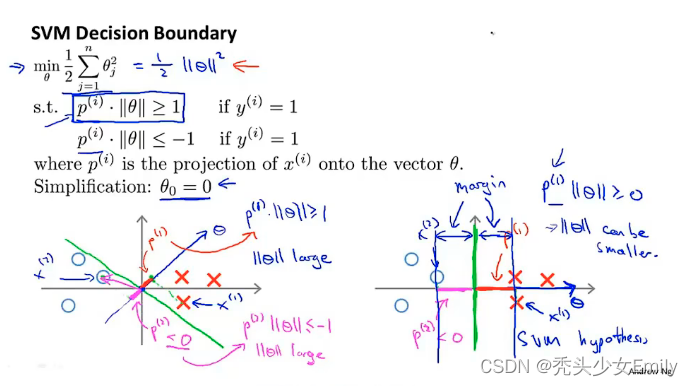
对于左侧的,每个x向量在
上的投影距离很小,要满足条件那么
就要增大,这样最小化代价函数的值就不是最优的,可能发生过拟合,所以SVM会得到类似右侧的边界,这样
尽可能小些,因为投影距离都比左侧的要大,这也是最大边界的原因。要让代价最小,那就得theta范数小,只有让p尽可能大的时候,theta范数才会最小,代价才最小,最根本还是想要最小化代价函数。
优化目标是要尽量小,所以在满足条件也就是cost函数的条件下,进行
最小化选择在这里决策边界是一条直线,
到
是这个直线的系数,这些系数所在的向量为这条直线的法向量,这些系数所在的法向量与直线垂直,推广到n维空间是一样的,不过直线变成了平面或者立体。
9.4 核函数
对于一个非线性决策边界问题,我们可能使用高阶的函数进行拟合,但是是否存在比当前特征刚好的表达形式呢?

我们可以将每种特征表示为,使用高斯核函数来做相似度分析。随机选择三个点作为标记,通过核函数可以得到x对应的新特征。

使用高斯函数的特点:如果相似度很高,即对应的欧几里得距离≈0对应,相反如果相似度低对应
。

例子:
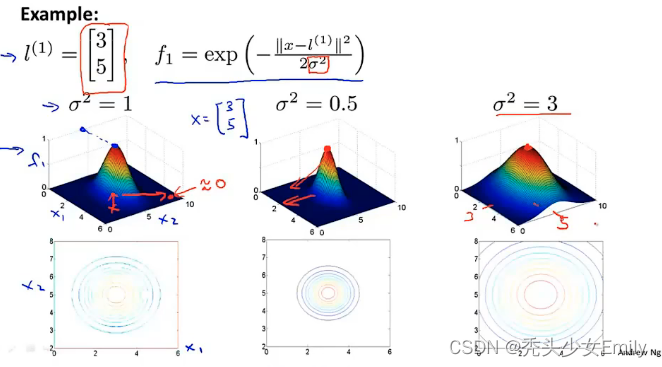
假设我们已经训练好参数,那么就可以通过
来进行预测,即对应红色的决策边界。
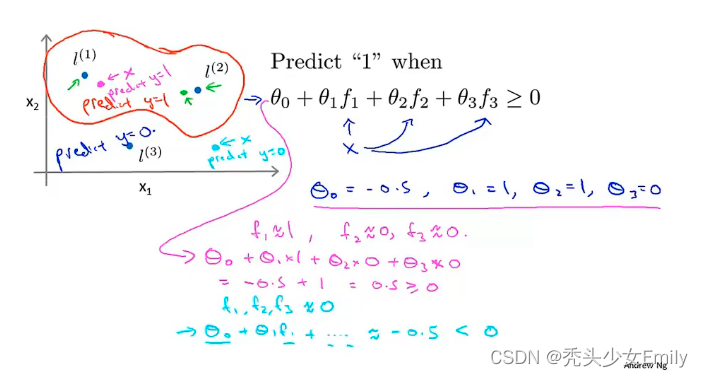
可以直接将训练集中的作为核函数中的
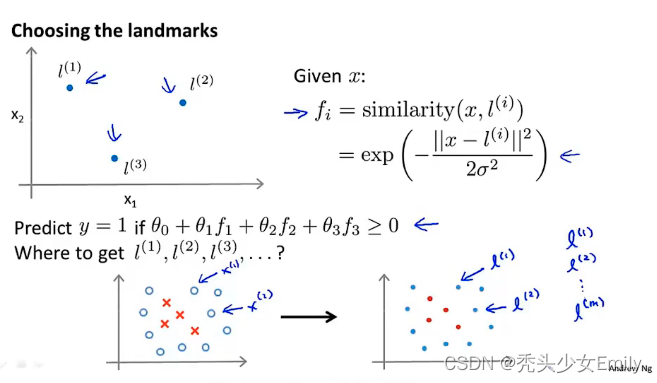
整个过程的大纲如下:
- 给定m个训练样本,选取与m个训练样本完全一样的位置作为我的标记点。当给定样本x(样本x属于训练集也可以属于交叉验证集或者属于测试集)我们来计算特征
,
等等,然后给了我们一个特征向量。
- 如果我们有一个训练样本
,对这个样本要计算的特征是这样的。给定
,将其映射到
、
、...、
。在这列表中,第i个元素实际上有一个特征元素写作
,接下来将这个列表合并为一个特征向量。

SVM在使用核函数的时候,对应代价函数就可以替换为:
 在使用支持向量机时,怎样选择支持向量机中的参数?
在使用支持向量机时,怎样选择支持向量机中的参数?
支持向量机中的偏差-方差折中。在使用支持向量机时,其中要选择的事情是优化目标中的参数C,C的作用与类似,
是逻辑回归算法中的正则化参数。所以大的C参数对应着之前逻辑回归问题中的小的
,这意味着不使用正则化就有可能得到一个低偏差高方差(过拟合)的模型;而小的C参数应着之前逻辑回归问题中的大的
,这意味着不使用正则化就有可能得到一个高偏差低方差(欠拟合)的模型。
另外一个要选择的参数是高斯核函数中的。当高斯核函数中的
偏大时,那么对应的相似度函数为
,变化缓慢,对应的高斯核函数的图像倾向于变得相对平滑,由于函数平滑且变化的比较缓慢,这会给模型带来较高的偏差和较低的方差。相反,如果高斯核函数中的
偏小时,对应的相似度函数变化剧烈,对应的高斯核函数的图像倾向于变得不平滑,会有较大的斜率和较大的导数,在这种情况下,会给模型带来较低的偏差和较高的方差。

9.5 使用SVM
可以使用软件库来算,但是也需要做几件事:首先是提出参数C的选择,不论是逻辑回归还是不带核函数的SVM通常都会做相似的事情,并给出相似的结果。但是根据实际的情况,其中一个可能会比另一个更加有效。但是在其中一个算法应用的地方,逻辑回归或不带核函数的SVM,另一个也很可能很有效。随着SVM的复杂度增加,当你使用不同的内核函数来学习复杂的非线性函数时,SVM的表现会非常突出。
最后什么时候用神经网络呢?对于不同的设计,设计良好的神经网络可能会非常有效,有一个缺点就是,有时可能不会使用神经网络的原因是对于有些问题来说,神经网络训练起来可能会特别慢。但是如果你有一个非常好的SVM实现包可能会运行的比较快。


![Ai前沿技术汇总[1]:Quivr非结构化信息搜索、Drag Your GAN AI修图、MiniGPT-4、Falcon-40B、localGPT](https://img-blog.csdnimg.cn/3e92fdb984da4305b63fda31393a70ff.png)