Pytorch版本的Ernie Health源码详解
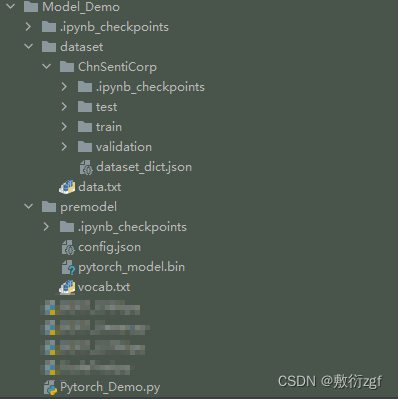
一、目录架构
二、尝试使用Ernie Health
import torch
# 查看torch版本
torch.__version__
'1.12.0+cpu'
# 查看设备是否有GPU资源
# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('device=', device)
# device= cpu
from transformers import AutoModel, AutoTokenizer,AutoConfig
# config配置模型的参数 从本地文件或URL加载预训练模型的配置文件
# 设置output_hidden_states=True 获取模型的所有隐藏状态 返回元组,第一个元素是最终的输出结果,后面的元素是每一层的隐藏状态。
config = AutoConfig.from_pretrained("premodel/", output_hidden_states=True)
# 根据给定的模型名称或路径自动选择对应的 tokenizer AutoTokenizer.from_pretrained("model_name_or_path")
# model_name:bert-base-uncased、roberta-large path:my_model
tokenizer = AutoTokenizer.from_pretrained("premodel/")
# 配置模型 利用config参数初始化
model = AutoModel.from_pretrained("premodel/", config=config)
# input_ids = torch.tensor([tokenizer.encode(text="welcome to ernie pytorch project", add_special_tokens=True)])
model.eval()
token = tokenizer.tokenize('我感觉头晕眼花')
input = tokenizer.encode('我感觉头晕眼花')
print(token)

三、使用Ernie Health完成文本分类
备注:这里只是想学习Ernie Health做文本分类的过程,数据集采用ChnSentiCorp,与医疗方向无关,后续将会分享Ernie Health在NLP医疗文本上的应用。
1.定义数据集(二分类)
# 加载数据
# load_dataset从数据集中心或本地文件系统中加载数据集。
# load_from_disk用于从本地磁盘中加载已经序列化的数据集,通常是使用 dataset.save_to_disk() 方法序列化后的数据集。
from datasets import load_dataset, load_from_disk
# 1. 定义数据集 二分类
class Dataset(torch.utils.data.Dataset):
def __init__(self, split):
#self.dataset = load_dataset(path='seamew/ChnSentiCorp', split=split)
self.dataset = load_from_disk('./dataset/ChnSentiCorp')[split]
def __len__(self):
return len(self.dataset)
def __getitem__(self, i):
text = self.dataset[i]['text']
label = self.dataset[i]['label']
return text, label
dataset = Dataset('train')
print('长度:', len(dataset))
print('dataset[0]:', dataset[0])

train中包含两个字段:text文本内容;label文本标签
2.加载字典和分词工具
from transformers import AutoTokenizer
# 2. 加载字典和分词工具
token = AutoTokenizer.from_pretrained('premodel')
3.定义批处理函数
# 3.定义批处理函数
def collate_fn(data):
sents = [i[0] for i in data]
labels = [i[1] for i in data]
#编码
data = token.batch_encode_plus(batch_text_or_text_pairs=sents,
truncation=True, # 当句子长度大于max_length时截断操作
padding='max_length',
max_length=500,
return_tensors='pt', # 返回pt类型可取值tf、pt、np分别对应tensorflow pytorch numpy张量,默认None为list
return_length=True)
print(data)
#input_ids:编码之后的数字
#attention_mask:是补零的位置是0,其他位置是1
input_ids = data['input_ids'].to(device)
attention_mask = data['attention_mask'].to(device)
token_type_ids = data['token_type_ids'].to(device)
labels = torch.LongTensor(labels).to(device)
#print(data['length'], data['length'].max())
# token_type_id 第一个句子和特殊符号为0,第二个句子为1
# special_tokens_mask 特殊符号为1,其他位置为0
return input_ids, attention_mask, token_type_ids, labels
4.数据加载器
# 4.数据加载器
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=16, # 每一次批次中包含16条数据
collate_fn=collate_fn,
shuffle=True,
drop_last=True)
for i, (input_ids, attention_mask, token_type_ids,
labels) in enumerate(loader):
break
print(len(loader))
input_ids.shape, attention_mask.shape, token_type_ids.shape, labels
5.加载预训练模型
from transformers import AutoModel
# 5.加载预训练模型
pretrained = AutoModel.from_pretrained('premodel')
#需要移动到cuda上
pretrained.to(device)
#不训练,不需要计算梯度
for param in pretrained.parameters():
param.requires_grad_(False)
6.定义下游任务模型
# 6.定义下游任务模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(768, 2) # 单层神经网络模型
def forward(self, input_ids, attention_mask, token_type_ids):
with torch.no_grad():
out = pretrained(input_ids=input_ids, # 利用预训练模型抽取文本特征
attention_mask=attention_mask,
token_type_ids=token_type_ids)
out = self.fc(out.last_hidden_state[:, 0]) # 抽取的文本特征放入全连接层中
out = out.softmax(dim=1)
return out
model = Model()
#同样要移动到cuda
model.to(device)
#虚拟一批数据,需要把所有的数据都移动到cuda上
input_ids = torch.ones(16, 100).long().to(device)
attention_mask = torch.ones(16, 100).long().to(device)
token_type_ids = torch.ones(16, 100).long().to(device)
labels = torch.ones(16).long().to(device)
#试算
model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids).shape
# torch.Size([16, 500, 768]) batch_size,max_length,词编码的维度
# 后面的计算和中文分类完全一样,只是放在了cuda上计算
7.训练
from transformers import AdamW
######### 7.训练
optimizer = AdamW(model.parameters(), lr=5e-4)
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失
model.train()
for i, (input_ids, attention_mask, token_type_ids,
labels) in enumerate(loader):
out = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
loss = criterion(out, labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if i % 5 == 0:
out = out.argmax(dim=1)
accuracy = (out == labels).sum().item() / len(labels)
print(i, loss.item(), accuracy)
if i == 100:
break
8.测试
def test():
model.eval()
correct = 0
total = 0
loader_test = torch.utils.data.DataLoader(dataset=Dataset('validation'),
batch_size=32,
collate_fn=collate_fn,
shuffle=True,
drop_last=True)
for i, (input_ids, attention_mask, token_type_ids,
labels) in enumerate(loader_test):
if i == 5:
break
print(i)
with torch.no_grad():
out = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
out = out.argmax(dim=1)
correct += (out == labels).sum().item()
total += len(labels)
print(correct / total)
test()
9.结果
0 0.6799753904342651 0.625
5 0.6905879974365234 0.4375
10 0.6816931366920471 0.5625
15 0.6723385453224182 0.625
20 0.6595535278320312 0.6875
25 0.6725921630859375 0.5
30 0.6362007856369019 0.8125
35 0.6231661438941956 0.9375
40 0.6399248242378235 0.625
45 0.6061363220214844 0.8125
50 0.6639376878738403 0.6875
55 0.6553252339363098 0.625
60 0.5932612419128418 0.9375
65 0.6260586380958557 0.625
70 0.6162962317466736 0.6875
75 0.6004247665405273 0.75
80 0.5238915681838989 0.9375
85 0.5489521622657776 0.875
90 0.5986231565475464 0.8125
95 0.5415515899658203 0.9375
100 0.6254498362541199 0.6875
0
1
2
3
4
测试准确率:0.75625