Towards Blockchain-Based Reputation-Aware Federated Learning
- FINE-GRAINED FEDERATED LEARNING
- A. Problem Statement
- B. Definition
- C. Requirements
- BLOCKCHAIN-BASED REPUTATION-AWARE FL
论文地址:https://www.researchgate.net/profile/Muhammad-Habib-Ur-Rehman/publication/339297228_Towards_Blockchain-Based_Reputation-Aware_Federated_Learning/links/5e83b797299bf130796db972/Towards-Blockchain-Based-Reputation-Aware-Federated-Learning.pdf
FINE-GRAINED FEDERATED LEARNING
A. Problem Statement
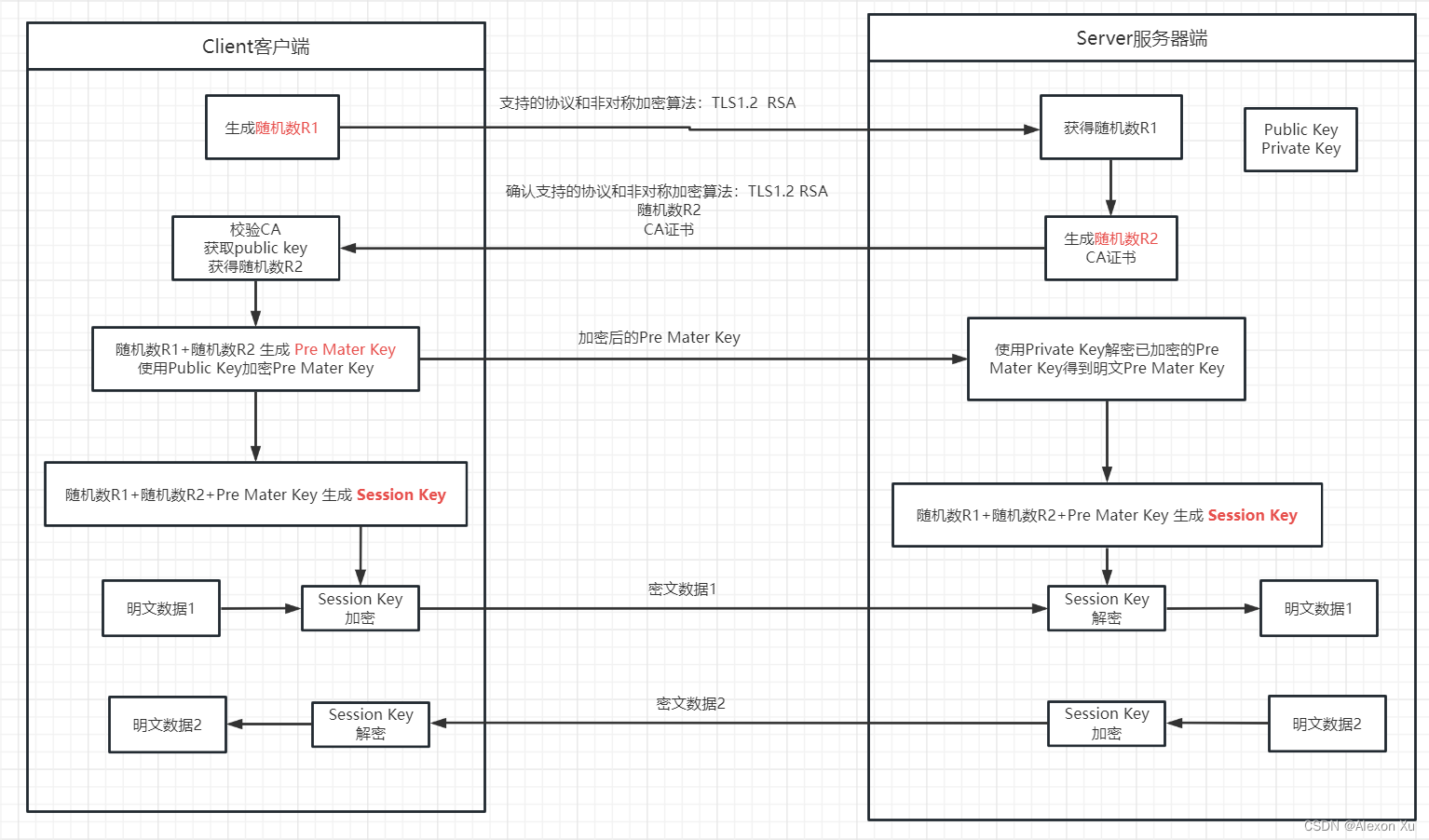
经典的联邦学习方案存在一些限制:(1) 设备和服务器的异质性。(2) 数据和模型更新的高维度。(3) 在数据、算法、数据源、数据预处理以及模型训练等方面存在偏差。(4) 模型训练的中心化。(5) 单点故障及纰漏。此外,传统的联邦学习方案引入了中心化的全局模型更新,有利于粗粒度(coarse-grained)应用的发展。例如,能够实现对手机用户一般活动的检测。然而,实际上每个用户有不同的行为模式,步幅、行走速度、坐姿、奔跑模型等各不相同,因此需要个性化定制。如Fig.1所示,细粒度的FL实现了更高的灵活性和知识可用性。

B. Definition
文章将经典的FL重新定义为细粒度(fine-grained)的FL,即在MEC(移动边缘计算)网络的所有三层(即边缘、雾和云)上执行保护隐私的协作学习过程。主要包含三个实体:(1) data-owners(边缘设备),(2) data-arbitrators(雾节点),(3) model-owners(云服务器)。Fig.2阐述了MEC网络中细粒度FL执行流程。给定一个包含 N N N个设备的集合 D = { 1 , . . . , N } D=\{1,...,N\} D={1,...,N},一个包含 n n n个雾节点的集合 F = { 1 , . . . , n } F=\{1,...,n\} F={1,...,n}和一个模型集合 L = { 1 , . . . , n } L=\{1,...,n\} L={1,...,n},任意设备 D i D_i Di必须与 F i F_i Fi相联系,并且能够运行 L i L_i Li。
Step_1 (Model Bootstrapping):
D
i
D_i
Di定期下载来自全局
L
i
L_i
Li的更新,并假设
D
i
D_i
Di拥有足够的资源来执行学习任务。
Step_2 (Global Task Initialization): 云服务器定期将更新后的模型推送给雾节点
F
i
F_i
Fi。此外,云服务器将学习任务(如超参数、学习率、期望的准确度、优化/半优化的SGD)委派给所有相连的的
F
i
F_i
Fi。
Step_3 (Local Task Initialization):
F
i
F_i
Fi定期将更新后的模型推送给相连的
D
i
D_i
Di。此外,
F
i
F_i
Fi将学习任务与他们的本地模型
L
i
L_i
Li匹配。在更新情况下,
L
i
L_i
Li执行Step_5 ,否则,它选择候选
D
i
D_i
Di并将学习任务委派给所有相连的
D
i
D_i
Di。
Step_4 (Local Model Aggregation): 云服务器请求多个
F
i
F_i
Fi来更新
L
i
L_i
Li参数,因此,MEC网络的延迟和后期的bootstrapping会导致细粒度FL过程中的模型更新不同步。因此,在执行他们的本地模型
L
i
L_i
Li之前,
D
i
D_i
Di需要匹配所有三个模型(**自己的模型、雾节点模型、服务器模型???)**的模型参数。在模型更新情况下,
D
i
D_i
Di从传感器和应用中收集数据,并通过
L
i
L_i
Li执行给定的学习任务
D
i
D_i
Di更新他们的本地
L
i
L_i
Li模型,对模型更新应用隐私保护技术,并将其发送给他们连接的
F
i
F_i
Fi进行本地聚合。
F
i
F_i
Fi运行本地模型聚合算法并相应地更新其本地模型
L
i
L_i
Li的参数,在添加隐私信息后,将更新的模型参数发送到云服务器。
Step_5 (Global Model Aggregation): 云服务器运行全局模型聚合方案并更新全局
L
i
L_i
Li。它将
L
i
L_i
Li的更新传播给底层MEC网络中所有连接的
F
i
F_i
Fi。
Step_6 (Global Model Update Requests):
D
i
D_i
Di周期性地产生更新全局模型的请求,以更新他们的本地
L
i
L_i
Li。
Step_7 (Global Model Updates): 云服务器定期将更新的模型参数推送给底层MEC网络中的所有
D
i
D_i
Di和
F
i
F_i
Fi。

C. Requirements
基于MEC系统中细粒度FL的目标和问题以及相关研究工作的缺陷,在本小节中定义了一些基本要求,如Fig.3所示。

Personalization: 数据拥有者根据他们的个人经验分享本地
L
i
L_i
Li更新,以增强雾节点和云服务器中的协作学习模型。然而,本地
L
i
L_i
Li被要求是个性化的,并能抵御数据和模型中毒攻击。
Decentralization: 在数据、数据所有者、
F
i
F_i
Fi和云服务器方面的中心化导致了non-IID数据和bias的FL模型。因此,在参与细粒度FL过程的所有参与者中,需要去中心化。
Fine-grained FL: 经典的FL模型提供了粗粒度的预测,通过这种预测可以跨所有
D
i
D_i
Di更新集中式全局
L
i
L_i
Li。然而,从本质上讲,数据集可以垂直划分以获得更好的洞察力。MEC支持多级数据管理,因此它可以促进
D
i
D_i
Di、
F
i
F_i
Fi和云级别的垂直数据分区。多层次划分的数据集产生更细粒度的FL训练。
Incentivization: 需要新的激励机制来招募具有高质量数据源的
D
i
D_i
Di。
Trust: 多个数据所有者、数据仲裁者和模型所有者需要提供一个值得信赖、保护隐私和安全的环境。
Active Monitoring: 由于有限的电池功率和移动性限制,
D
i
D_i
Di在MEC环境中的参与是不稳定的。因此,需要细粒度的FL系统来持续监测被丢弃的参与者,以确保高质量的数据收集。
Heterogeneity and Context-Awareness: 细粒度FL需要处理MEC中由于
D
i
D_i
Di、
F
i
F_i
Fi、数据类型、数据源和
L
i
L_i
Li而可能产生的异构性。此外,
D
i
D_i
Di和
F
i
F_i
Fi必须能够推断不同的情况,并在当时情况下建立正确的context来执行
L
i
L_i
Li。
Communication and Bandwidth-Efficiency: 相邻的
D
i
D_i
Di在相同的环境下,具有相同的学习任务,产生相同的模型更新。因此,需要复杂的数据约简、模型压缩和自适应模型聚合技术。此外,
F
i
F_i
Fi应确保最小的延迟,以提高通信效率。
Fine-grained Model Synchronization:
D
i
D_i
Di和
F
i
F_i
Fi中资源的变化导致参与者丢失和执行时间变化,从而导致不同细粒度FL环境。因此,细粒度FL系统需要最小化所有通信路径上的延迟,以确保MEC系统中三个层面的最大同步。
BLOCKCHAIN-BASED REPUTATION-AWARE FL
恶意、错误的 D i D_i Di的存在可能成为实现细粒度FL需求的主要瓶颈,然而,关于 D i D_i Di的apriori声誉信息可以克服这一瓶颈。基于区块链的细粒度FL信誉系统如Fig.4所示。

通过前端DApps向FL系统的所有参与者提供对声誉信息的访问,这些DApps使用以太坊的公共区块链和智能合约技术来计算和确定声誉分数的可信聚合。 D i D_i Di可以请求、访问和比较来自云服务器和 F i F_i Fi的链下模型参数,并对它们的性能进行评估,将它们进行hash并存储在MEC网络中的分散存储(如IPFS)中。他们将声誉分数的哈希值报告给链上智能合约。智能合约聚合并计算每个 F i F_i Fi和云服务器的信誉。同样的, F i F_i Fi可以根据数据丰富度、context-awareness、在异构设置中提供具有代表性的非冗余模型更新的能力、掉线参与方的比例、模型更新的质量、模型更新中的统计变化等对相连 D i D_i Di的性能进行评分。类似地,云服务器可以根据参与协作模型开发过程的积极性、共享模型更新的意愿、模型更新的频率和其他性能参数对 D i D_i Di和 F i F_i Fi进行评分。