目录
- Problems with Word Vectors/Embeddings 词向量/嵌入的问题
- RNN 语言模型
- Bidirectional RNN 双向 RNN
- Embeddings from Language Models 基于语言模型的嵌入
- ELMo 架构
- Downstream Task: POS Tagging 下游任务:词性标注
- ELMo 的表现如何?
- Other Findings
- 上下文 vs. 上下文无关
- Disadvantages of EMLo EMLo的缺点
- Disadvantages of RNNs RNN 的缺点
- BERT: Bidrectional Encoder Representations from Transformers
- Transformers
- Self-attention via Query, Key, Value 自注意力机制:实现
- Transformer Block
- 总结
Problems with Word Vectors/Embeddings 词向量/嵌入的问题
在之前的章节中,我们已经学习过 词向量/嵌入(Word Vectors/Embeddings),我们还学习了如何通过基于计数的方法来得到词向量。
-
Each word type has one representation 每个单词 type 都有一个表示。Word2Vec
-
Always the same representation regardless of the context of the word 无论单词的上下文是什么,我们得到的单词表示都是相同的。通过这种方式,无论这些单词在句子中是如何被使用的或者出现在句子中的哪个地方,以及它们的相邻单词是什么,模型学习到的每个单词 type 的词向量/嵌入都只有一种表示。我们称之为 上下文无关词向量/嵌入(Contextual Independent Word Vectors/Embeddings)。
-
Does not capture multiple senses of words 这种上下文无关词向量没有捕获到 单词的多义性(multiple senses of words)。例如:对于单词 “duck”,其既可以表示鸭子这种动物,也可以表示躲避这一动作。而我们之前的词向量没有办法捕获到这两种含义之间的差异,因为对于同一单词我们只有一种向量表示。
-
Contextual representation: Representation of words based on context 上下文表示(Contextual representation)= 基于上下文的单词表示 如果一个单词在两个句子中的含义不同,那么我们将得到该单词的两种不同的上下文表示。
-
Pretrained contextual representations works very well for downstream applications 但是,更重要的是,我们发现预训练的上下文表示在大部分下游任务中的表现都 相当出色。这种基于上下文的单词表示已经在目前的 NLP 系统中充当着基石的角色。
RNN 语言模型

所以,我们应当如何学习到这种上下文表示呢?
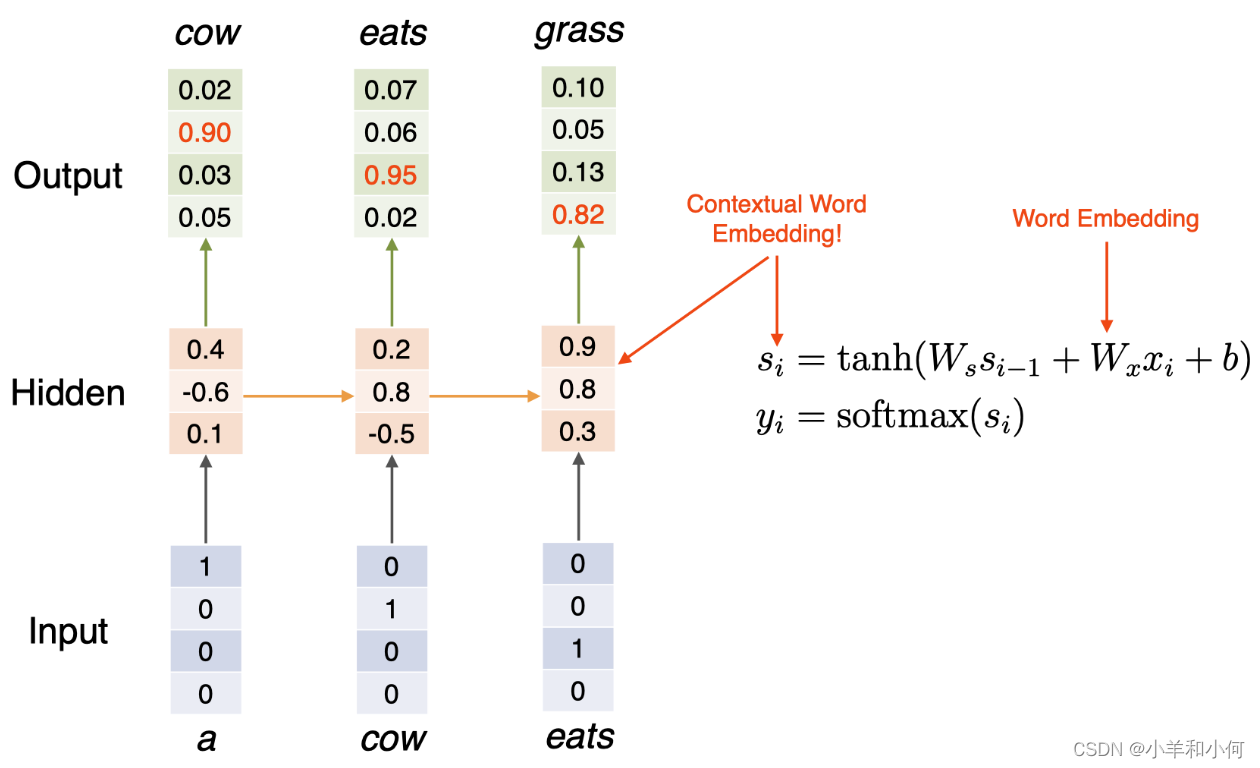
这里,我们有一个 RNN 语言模型:“a cow eats grass“。这里,RNN 模型试图预测下一个单词:绐定单词“a”,RNN 模型试图预测下一个单词 “cow”;给定单词“cow”,它试图预测下一个单词“eats” 等等。
下面是一个简单的 RNN 语言模型:


Bidirectional RNN 双向 RNN
现在,我们来看一下如何利用双向 RNN 模型来捕获当前单词左右两侧的上下文信息,从而得到当前单词的上下文表示。


ELMo
双向 RNN 这种思路也启发了 ELMo 模型:它是一种非常流畅自然的单词上下文表示模型,并且在大部分的 NLP 任务中都取得了非常好的效果。Embeddings from Language Models 基于语言模型的嵌入
ELMo 表示 基于语言模型的嵌入(Embeddings from Language Models)。
-
Trains a bidirectional, multi-layer LSTM language model over 1 billion word corpus ELMo 在一个包含 1B(10 亿)单词的语料库上训练了一个双向多层 LSTM 语言模型。
-
Combine hidden states from multiple layers of LSTM for downstream tasks 它结合了来自 LSTM 的 多层(multiple layers)的隐藏状态,并用于下游任务中。
- Prior studies use only top layer information 这是 ELMo 的创新点之一:因为之前关于预训练模型的上下文表示研究只使用了顶层的信息,因此并没有在性能上获得太大提升。而对于 ELMo,假如我们使用了一个 2 层的 LSTM,那么我们将同时使用第一层和第二层的 LSTM 的输出。
-
Improves task performance significantly 最重要的是,研究发现,仅仅通过增加一些预训练的上下文词嵌入,就能在大部分的 NLP 任务中取得较大提升。
ELMo 架构
-
Number of LSTM layers LSTM 层数 = 2
-
LSTM hidden dimension LSTM 隐藏层维度 = 4096
-
Character convolutional networks to create word embeddings. No unknown words 使用 字符级的卷积神经网络(Character CNN)来创建词嵌入。没有未知单词


-
Extracting Contextual Representation: 提取上下文表示
当我们在 10 亿单词语料库上对该双向 LSTM 模型进行预训练之后,我们如何提从中提取单词的上下文表示呢?我们又该如何将我们提取到的上下文表示用于下游任务呢?


Downstream Task: POS Tagging 下游任务:词性标注


ELMo 的表现如何?
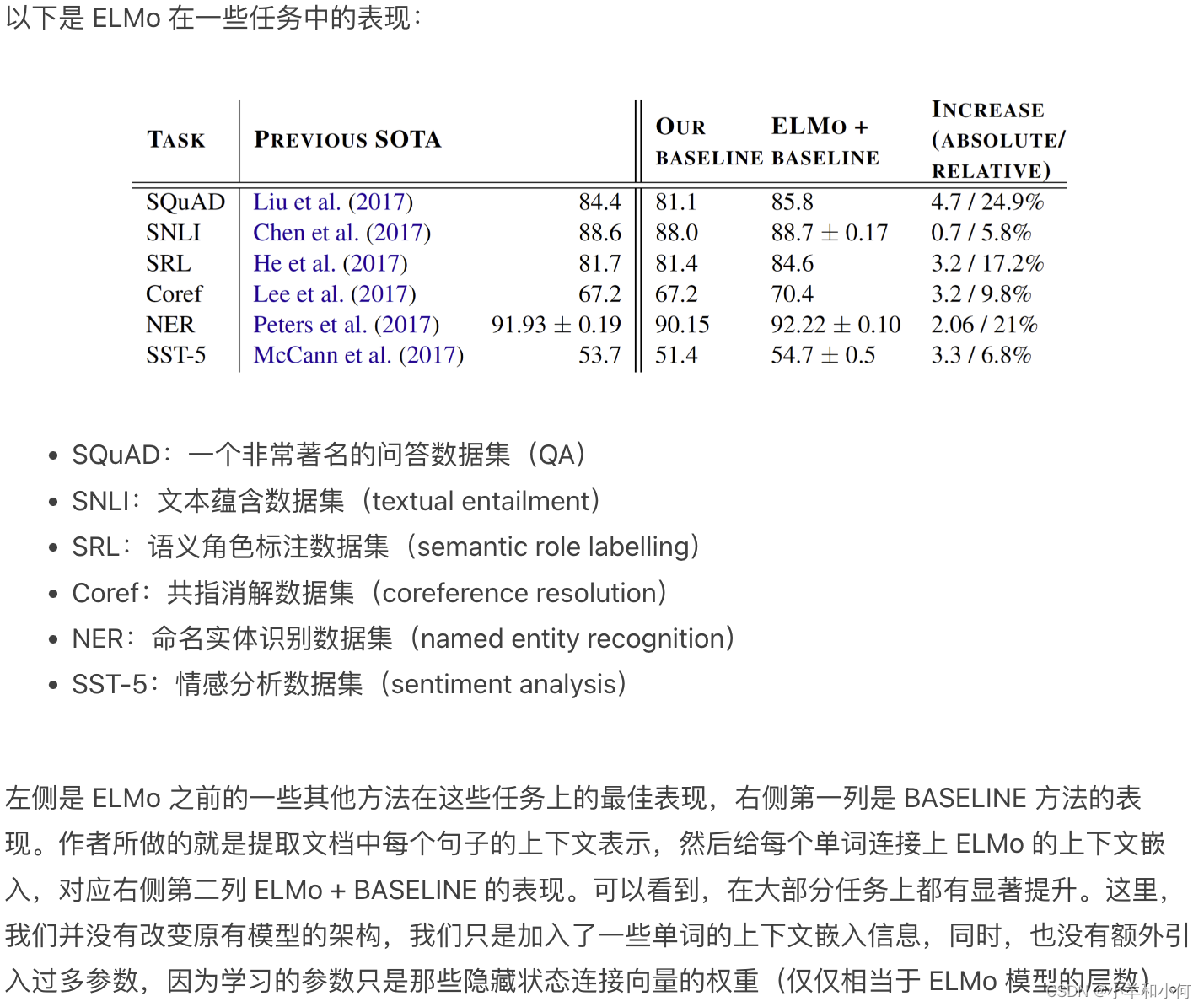
Other Findings
-
Lower layer representation -> captures syntax 低层表示 = 捕获句法(syntax)信息
- good for POS tagging, NER 一个有趣的发现是低层的表示(例如:第一层 LSTM 中的隐藏状态)倾向于捕获更多关于该单词的句法信息。因此,非常适用于 词性标注 (POS tagging) 、命名实体识别 (NER) 等任务。
-
Higher layer representation -> captures semantics 高层表示 = 捕获语义(semantics)信息
- good for QA, textual entailment, sentiment analysis 第二层 LSTM 中的隐藏状态捕获到的更多是关于单词语义方面的信息,因此,更适用于一些理解相关任务,例如:问答系统 (QA) 、文本蕴含 (textual entailment) 、情感分析 (sentiment analysis) 等等。
-
那么,这些特性是如何被发现的呢?
- 很简单,只需要观察一下如何解释从文本中学习到的关于隐藏状态连接向量的权重。例如:当下游任务是词性标注时,我们会发现第一层 LSTM 学习到的隐藏状态连接向量的权重值往往非常大;而在下游任务是情感分析时,我们会发现第二层 LSTM 学习到的隐藏状态连接向量的权重值非常大。
上下文 vs. 上下文无关

Disadvantages of EMLo EMLo的缺点
- Difficult to do intrinsic evaluation 难以做内在的评价
- Not very interpretable 可解释性不强
- Computationally expensive to train large-scale contextual embeddings 训练大规模语境嵌入的计算成本很高
- All languages can be trained, but the performance is very related to the scale of corpus 所有的语言都可以被训练,但性能与语料库的规模有很大关系
BERT
Disadvantages of RNNs RNN 的缺点
-
Sequential processing: difficult to scale to very large corpus or models 序列处理(Sequential processing):难以扩展到非常大的语料库和模型上。由于使用 RNN,序列处理是不可避免的步骤。当我们想要计算句子中最后一个单词的上下文表示时,我们无法立即直接进行计算,我们需要先计算句子中倒数第二个单词的上下文表示,而这又需要我们先计算句子中倒数第三个单词的上下文表示。所以,由于 RNN 的特性,我们必须从句子的第一个单词开始依次计算单词的上下文表示。因此,基于 RNN 的方法很难扩展到非常大的语料库和模型上。
-
RNN language models run left to right, which just captures only one side of context RNN 模型是从左向右运行的(只能捕获到单侧的上下文信息)。原始的 RNN 模型是单向的,因此我们只能捕获到目标单词左侧的上下文信息。RNN 的这种设计理念是基于我们希望得到一个格式正确的句子概率,我们希望计算得到的所有可能句子的概率之和为 1,因此 RNN 被设计为从左向右的单向语言模型。但这样带来的问题是我们无法捕获目标单词另一侧的上下文信息。
-
Bidirectional RNNs help, but they ony capture surface bidirectional representations 双向 RNN(Bidirectional RNN)可以在一定程度上解决这个问题,但是它只能捕获到表面的双向表示的交互信息。因为在处理单词的时候,ELMo 中的前向 RNN 模型和后向 RNN 模型彼此之间并不存在交互。我们只是对这两个独立的 RNN 的输出进行了简单地连接操作。
-
ELMo: Two RNNs are run independently. Information is aggregated after they have separately produced their hidden representations
因此,我们将继续介绍一种更加高效的上下文表示的学习模型:BERT,它是目前为止表现最好的模型之一。
BERT: Bidrectional Encoder Representations from Transformers
BERT 意为 基于 Transformers 的双向编码器表示(Bidirectional Encoder Representations from Transformers)。
-
Use self-attention networks (Transformers) to capture dependencies between words. No sequential preocessing 使用自我注意网络(Transformers)来捕捉单词之间的依赖关系。无顺序预处理
- 这种方式的主要优点在于无需进行序列处理。
- 不同于基于 RNN 模型的 ELMo,我们可以使用 BERT 直接计算句子中某个单词的上下文嵌入而不必先计算其前面单词的嵌入。因此,可以很容易扩展到非常大的语料库上。
- 这种方式的主要优点在于无需进行序列处理。
-
Masked language model objective to capture deep bidirectional representations BERT 还使用 掩码语言模型(masked language model) 来捕获深度双向表示。
- 在之前的 ELMo 中,我们看到其只捕获了表面的双向表示,因为前向和后向语言模型之间是相互独立的。而在 BERT 中,我们稍后将看到 Transformers 使用单个模型同时捕获两个方向的上下文信息。
-
Loses the ability to generate language 失去了生成语言的能力
- BERT 无法单独进行语言生成任务,它无法计算有效的句子概率,也无法从左至右生成句子。
-
Not an issue if the goal is to learn contextual representations 但是,这不是一个很大的问题,如果我们的目标只是学习单词的上下文表示。
- 如果我们的目标只是高效地生成单词的双向上下文表示,那么 BERT 无法生成语言并非一个很大的问题,因为我们可以将其与其他语言模型结合来实现语言生成。
-
ELMo vs. BERT 架构对比
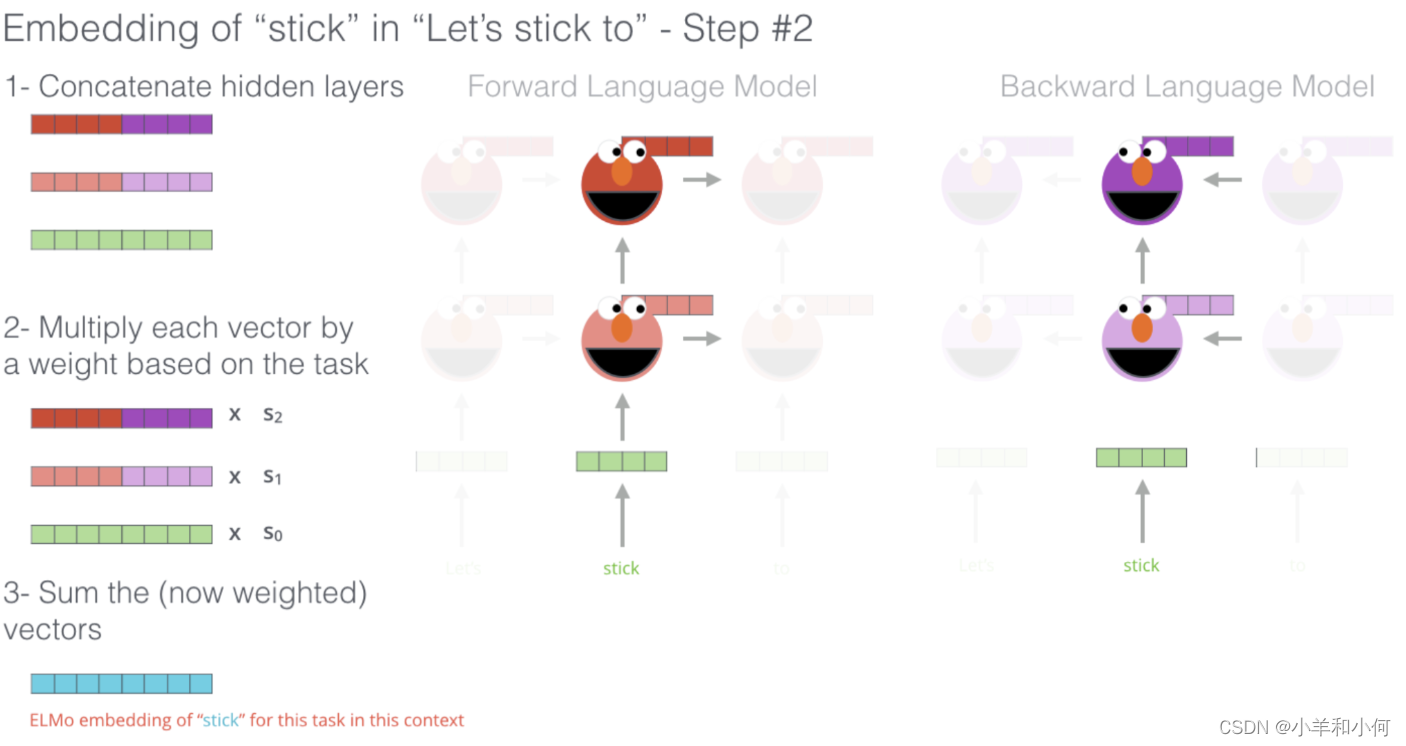
这里是 ELMo 和 BERT 的架构图表示:

上面是 ELMo 的架构图,其中下面的黄色方块表示输入单词。可以看到,ELMo 具有一个从左至右的 LSTM 和一个从右至左的 LSTM 模型,我们将单词序列分别输入给这两个 RNN 语言模型,然后我们将两个模型输出的隐藏状态向量进行连接得到双向的上下文信息。但是,这两个 LSTM 语言模型在处理单词的过程中并没有任何交互。

上面是 BERT 的架构,其中每个蓝色椭圆表示 Transformer。假设现在我们要计算第二个单词 E2 的上下文表示,Transformer 会查看单词 E2 周围的所有上下文单词,即从 E1 到 EN 的整个单词序列,然后计算一个集合表示(aggregate representation)作为单词 E2 的上下文表示。然后我们会经过一系列的 Transformers,每一层都执行类似的操作,例如:第二层的 Transformers 会将所有第一层 Transformers 的输出作为输入,并将它们结合起来,计算得到最终的上下文表示 T2。由于这里我们使用单个模型来捕获两个方向的上下文信息,模型可以捕获到不同的两侧上下文单词之间更深层次的关系。
-
Objective 1: Masked Language Model 目标 1:掩码语言模型
我们前面提到过 BERT 使用了 掩码语言模型(Masked Language Model)。- Mask out k% of tokens at random 随机 “掩去(mask)” k% 的 tokens。
- Objective: predict the masked words BERT 的目标:正确预测出被掩去的单词(masked words)。
例如,现在我们有以下句子:


-
Objective 2: Next Sentence Prediction 目标 2:预测下一个句子
BERT 的第二个目标是预测接下来的句子。- Learn relationships between sentences 这使得 BERT 可以学习句子之间的关系。
- Predicts whether sentence
Bfollows sentence A BERT 的目标是预测句子 B 是否紧跟在句子 A 后面。 - Useful pre-training objective for downstream applications that analyze sentence pairs 这个预训练目标对于需要分析句子对的下游应用(例如:文本蕴含、句子相似度)非常有用。


-
Training/Model Details: 训练/模型细节
- WordPiece Tokenization BERT 使用 WordPiece (subword) Tokenisation
- 类似之前在文本预处理中学过的 BPE(Byte-Pair Encoding) 算法,不同点在于,WordPiece 基于概率生成新的 subword 而不是下一最高频字节对。
- Multiple layers of transformers to learn contextual representations BERT 使用多层 Transformers 来学习上下文表示。
- BERT is pretrained on Wikipedia + BookCorpus 模型训练在 Wikipedia+BookCorpus 上完成。
- Training takes multiple GPUs over several days 训练需要在多个 GPU 上运行好几天。
- WordPiece Tokenization BERT 使用 WordPiece (subword) Tokenisation
-
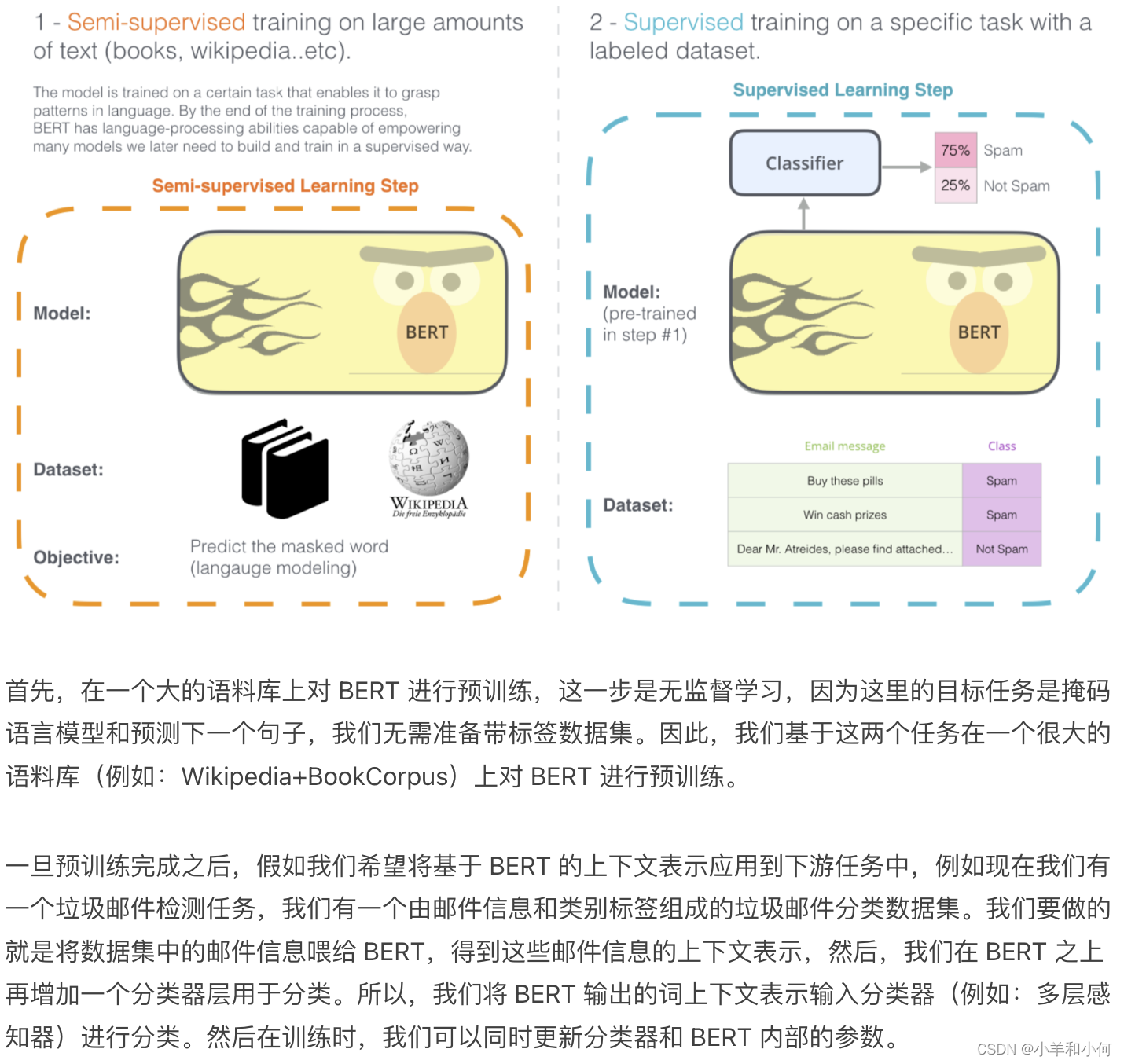
BERT 微调(Fine-Tuning)
-
-
How to use BERT:
- Given a pretrained BERT, continue training (fine-tune) it on downstream tasks 给定一个预训练的BERT,在下游任务上继续训练(微调)它
- Add a classification layer on top of the contextual representations 在上下文表征的基础上增加一个分类层
- E.g.

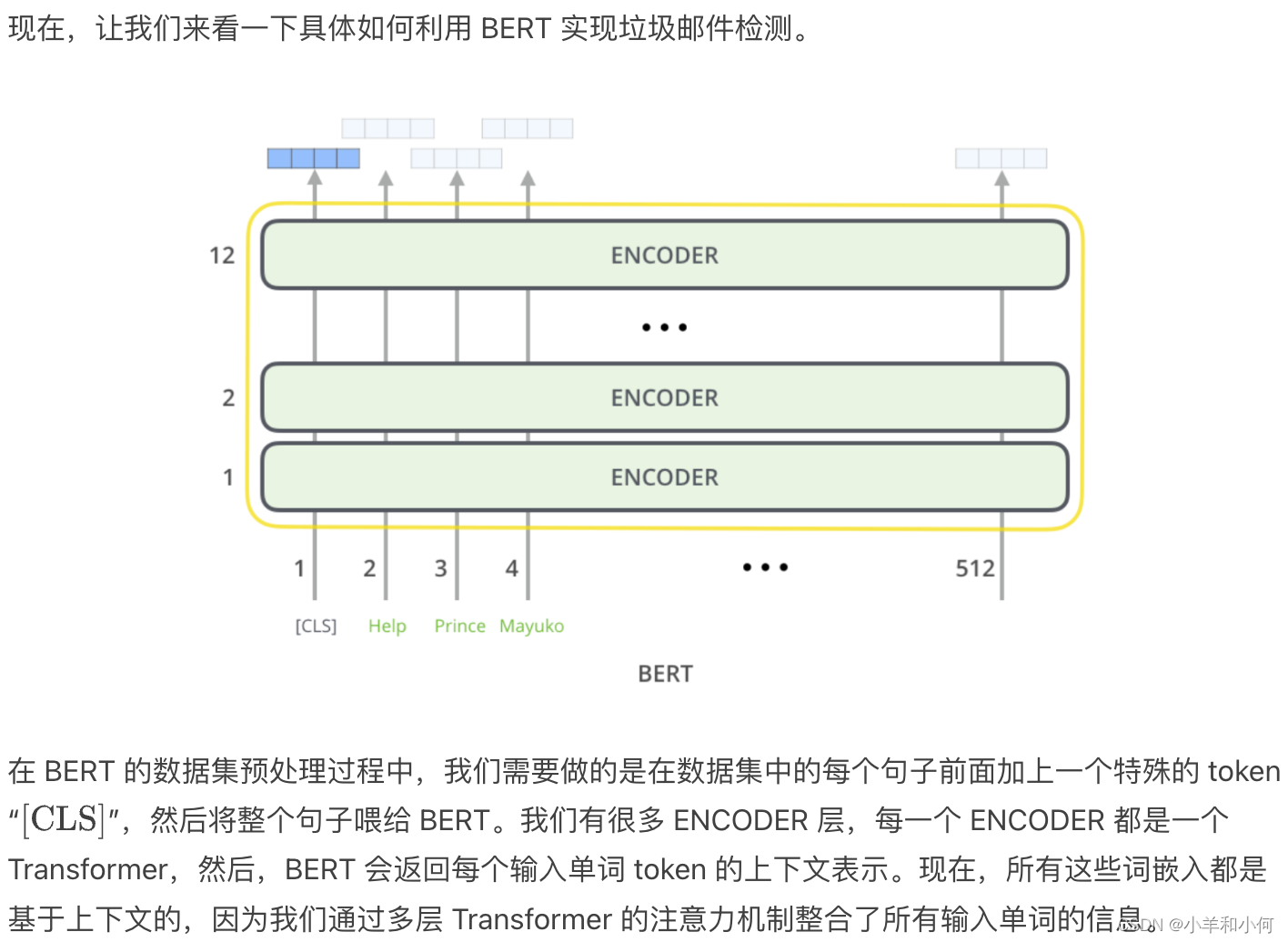
-
BERT vs ELMo
那么,BERT 和 ELMo 到底在哪些方面存在差异呢?- ELMo provides only the contextual representations ELMo 只能提供单词的上下文表示。两者都可以提供单词的上下文表示,但是 ELMo 只能提供单词的上下文表示,ELMo 需要另外提供下游应用的神经网络架构。回忆一下之前 ELMo 的例子,我们有单独的 baseline 模型(有自己的神经网络架构),ELMo 仅仅提供单词的上下文表示,我们还需要提供用于下游任务的单独的神经网络架构。
- Downstream applications has their own architecture 当应用于下游应用时,ELMo 的上下文表示是固定的。
- ELMo parameters are fixed when applied to downstream applications. Only the weights to combine states from different LSTM layers are learned 另一个主要区别是,当我们利用下游任务进行训练/微调时,ELMo 中用于学习上下文表示的语言模型的参数是固定的(没有训练),这个过程中,唯一得到训练的参数是赋予来自不同 LSTM 层隐藏状态连接向量的权重(例如:S2, S1, S0)。我们并不会对 ELMo 中的 LSTM 层的参数进行更新。

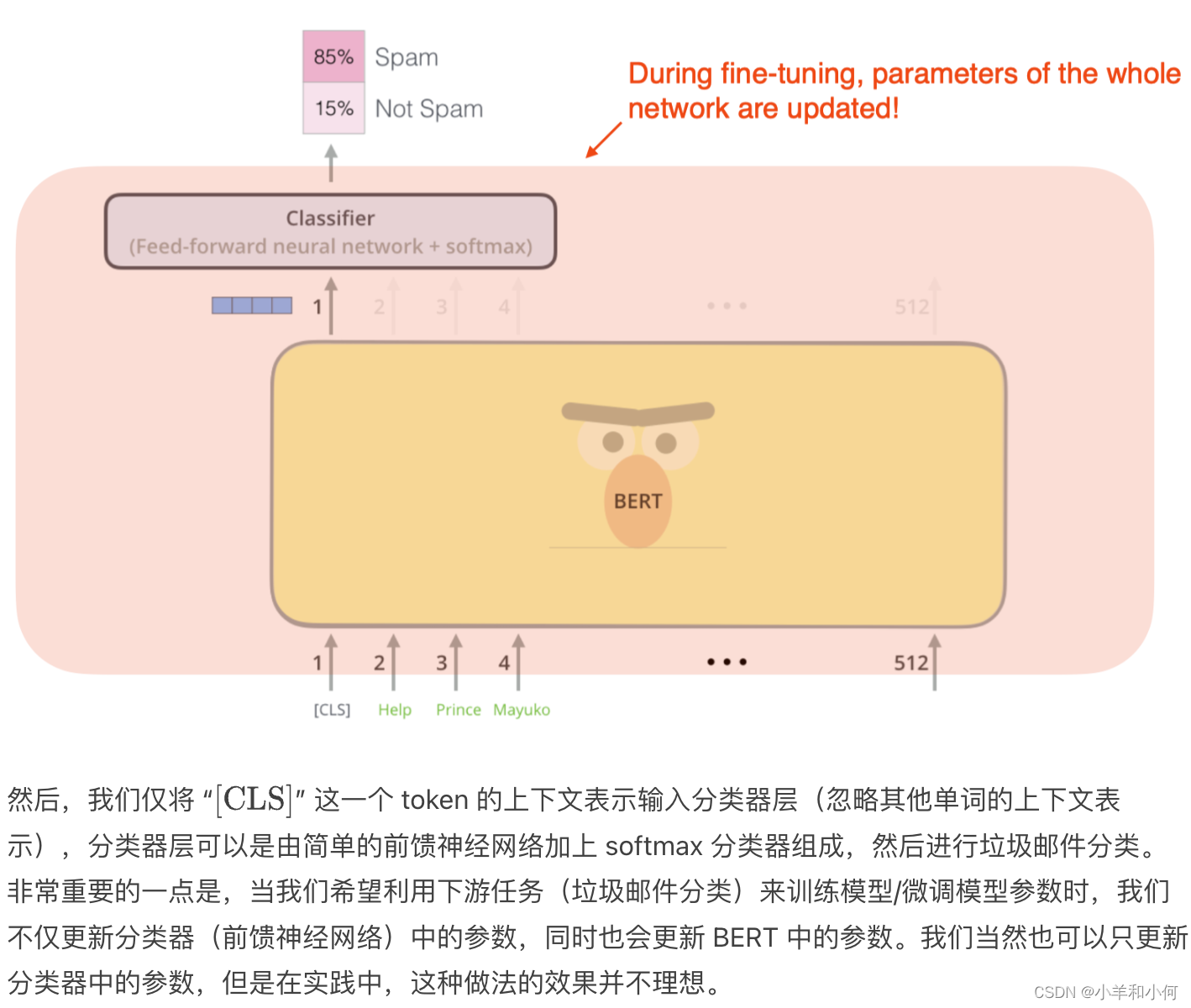
- BERT adds a classification layer for downstream tasks. No task-specific model needed BERT为下游任务增加了一个分类层。不需要特定的任务模型
- BERT 不需要另外单独的下游任务模型。BERT 提供了单词的上下文表示,我们要做的只是为下游任务增加一个分类层。
- BERT updates all parameters during fine-tuning BERT在微调期间更新所有参数
-
BERT 的表现如何?
-

Transformers
Transformers
我们已经见过了 BERT 中的 Transformers,那么,到底什么是 Transformers?它们又是如何工作的呢?
-
Use attention instead of using RNNs to capture dependencies between words Transformers 使用 注意力机制(attention)替代 RNN(或者 CNN)来捕获单词之间的依赖关系。
这里是一个如何利用注意力机制捕获单词之间依赖关系的例子:


-
Architecture:

Self-attention via Query, Key, Value 自注意力机制:实现
我们这里进一步介绍这种 自注意力机制(Self-Attention)的实现。
-
Input:
- query
qE.g. made - key
kand valuevE.g. her -

- query
-
Query, key, and value are all vectors, linearly projected from embeddings
-
Comparison between query vector of target word
madeand key vectors of context words to compute weights -
Contextual representation of target word = weighted sum of value vectors of context words and target word:
-
Self-Attention:
-
Multiple queries, stack them in a matrix:
-
Uses scaled dot-product to prevent values from growing too large:
-
-
Only one attention for each word pair
-


-
多头注意力机制
- Use multi-head attention to allow multiple interactions:


- Use multi-head attention to allow multiple interactions:
Transformer Block


总结
- 我们学习了基于 ELMo 和 BERT 的单词上下文表示,以及它们在下游任务中的表现,并且也学习了如何将它们应用到下游任务中。
- 这些模型都是在非常大的语料库上训练的。
- 因此,它们构建了一些语言相关的知识。
- 使用无监督目标,模型训练无需专门提供带标签数据集。
- 由于模型是在非常大的语料库上训练的,因此,当我们将它们用于下游任务时,我们不再是从零开始(“scratch”)的状态,因为模型在某种程度上已经理解了一些单词含义相关的信息,以及单词之间的关系。所以,现在模型需要做的只是将这些理解带入下游任务的模型中进行训练。这也是这类上下文表示模型非常有用的原因之一。并且,正如 BERT 中提到的,基于大量语料库得到的预训练词嵌入在一定程度上缓解了下游任务对于数据量的需求。